






MYSQL索引基础
关于引擎
- myisam:
- 只有表锁;只有非聚簇索引,索引和文件分开,辅助索引和主键基本没区别。
- innodb:
- 有行锁和表锁,主键是聚簇索引,索引和文件一起,辅助索引指向主键索引。
关于索引结构
主流的是B+数,也有hashCode。
hashCode有点检索效率高,但是缺点也很明显,关于范围排序等都不适用。所以我们重点研究B+。
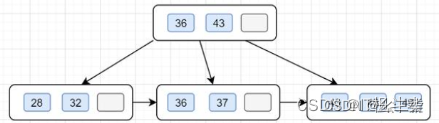
B+树长这样子:图片我都是到处扣的。
优点:
每个节点有多个子女----->减少层级
叶子是连接起来的----->无须前序搜索(就是不用再回上一节点查,而是沿着这条路往下查)
关于索引名词
联合索引:复合索引,几个字段组合起来的索引。
聚簇索引:索引和数据放在一起。
索引下推:查询的条件在索引上,减少数据的帅选。
覆盖索引:查询的列都在索引上。
MYSQL索引分析
索引失效的情况
最起码要使用索引字段
- 索引一定要按创建顺序来,所以 like '%abc’这种是不生效的,like ‘abc%’ 没其他情况是可以命中的。
- 函数操作
- not运算,!=运算
- or操作字段没有按索引顺序来(复合索引情况下)
- 类型不匹配
- 数据超过mysql的限制(比如命中数据超过80%,走不走索引意义不大了)
索引创建原则
- 不为离散度低
- 不为频繁更新
- 有复合索引单独再创建
- 尽量有序,所以mysql不适合UUID做主键
主要分析
expain:
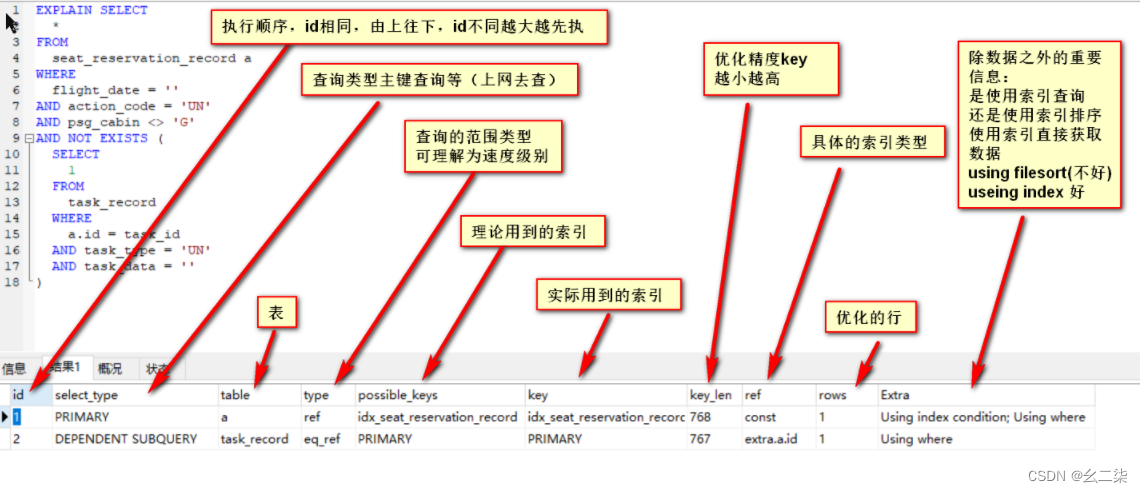
概要描述:
id:选择标识符
select_type:表示查询的类型。
table:输出结果集的表
partitions:匹配的分区
type:表示表的连接类型
ALL、index、range、 ref、eq_ref、const、system、NULL(从左到右,性能从差到好)
possible_keys:表示查询时,可能使用的索引
key:表示实际使用的索引
key_len:索引字段的长度
ref:列与索引的比较
rows:扫描出的行数(估算的行数)
filtered:按表条件过滤的行百分比
Extra:执行情况的描述和说明
该列包含MySQL解决查询的详细信息,有以下几种情况:
Using where:不用读取表中所有信息,仅通过索引就可以获取所需数据,这发生在对表的全部的请求列都是同一个索引的部分的时候,表示mysql服务器将在存储引擎检索行后再进行过滤
Using temporary:表示MySQL需要使用临时表来存储结果集,常见于排序和分组查询,常见 group by ; order by
Using filesort:当Query中包含 order by 操作,而且无法利用索引完成的排序操作称为“文件排序”
-- 测试Extra的filesort
explain select * from emp order by name;
Using join buffer:改值强调了在获取连接条件时没有使用索引,并且需要连接缓冲区来存储中间结果。如果出现了这个值,那应该注意,根据查询的具体情况可能需要添加索引来改进能。
Impossible where:这个值强调了where语句会导致没有符合条件的行(通过收集统计信息不可能存在结果)。
Select tables optimized away:这个值意味着仅通过使用索引,优化器可能仅从聚合函数结果中返回一行
No tables used:Query语句中使用from dual 或不含任何from子句
SQL优化
优化的主要步骤就是建立索引,所以知道上面的分析后也就差不多问题出在哪里了,当然,还有一些其他方面的知识:
内连接是其他外连接的基础,所以内连接性能并不会好点,但是由于内连接会将多余数据切割掉,所以传输数据会少点,从这方面讲,性能快一点点。
不要主观臆测,子查询和in不一定比EXISTS性能差
union等查询都会产生临时表,那么在每个子查询应该尽量产生少的数据
复合索引合理要比单索引要好,然后多个索引只用一个木九十受影响行数少的那个
mysql是可以一遍跟新和以便查询的,前提条件是在update打开表之前就完成子查询
排序缓存够就一次排序 否则就分好多次 然后将结果拼接
双行:堆排序字段进行排序,排序万完再去查询对应行
单行:直接一步到位
实际代码中我们改注意什么
- 尽量减少表连接,最好是没有
- 建立好常用的索引
- 查询只要写返回的字段,不要写 *
- 尽量避免大字段(如果大字段影响太大,可以分开,点击详情再单独展示大字段内容)
- 避免用大字段
- 能用整数用整数
- 主键如果整数采用无符号
- 短的字符串能用char就用char
- 一般设置默认值 不要有空
- 如果实在有多表复杂查询,尽量拆分,然后异步分而治之处理。
MYSQL锁分类
mysql有很多锁:
乐观锁:多版本控制(MVCC)
悲观锁:提前加锁,抢夺控制权的锁
读写锁:读锁,和写锁
排他锁:自己能更新,其他不能更新,但是能读取,也叫写锁
共享锁:自己不能更新,只能读,其他也只能读。也叫读锁
间隙锁:锁住范围的锁
但是上面这些锁都是锁的名称,还有一些锁名称,除了要了解他们字面意思,重点还得结合数据库运行中的实际场景。
隔离级别和锁的关系
之所以有锁,是为了解决并发中带来的冲突问题:
经典四大问题:
读未提交:能读到没有提交的数据(脏读)----> 针对的是更新
读已提交:能读到提交的数据(不可重复读问题)------> 针对的是更新
可重复度:能重复读取数据(幻读)-------> 针对的是新增,删除
序列化:最高,相当于将执行命令串行化
锁与隔离级别的关系
啥叫隔离级别:
我们将A,B两个事务,当做两个人,他们去操作同一台电脑,他们能互相影响的程度就是隔离级别,就是事务与事务之间操作互相影响和数据可见的程度。
所以隔离级别主要是影响事务的运行,而在事务中主要又影响数据的增删改和读取。
分开讲:
-
增删改: 一定都会加锁,主要是排他锁,因此其他数据能读,但是不能修改。
-
读:看情况加锁,我们发现隔离级别主要是针对读的,因为改就是你能我不能没啥特别需要隔离的程度,而读不一样:
读未提交:直接读取数据最新数据,忽略版本,忽略提交中间状态
读已提交:读取数据提交后的MVCC版本,但凡重复读取又提交的就读取最新提交的(快照读)
可重复度:读取本事务开始时第一次读取到的MVCC版本,就算再次读取又提交的也读取当前事务第一次的数据(快照读)
上面MVCC是实现这些的核心,多版本控制,简单来说就是数据有两个隐藏字段,每条数据都有版本号,开启事务后还有事务号(为了明确谁拥有锁),数据修改数据的版本号。有了这些版本数据之后,后续的作用就来了:
- 首先回滚的数据有了,可根据回滚的版本号回滚数据。
- 不同隔离级别下,读取数据不同版本的方案也能实现。
所以隔离级别主要通过锁和多版本控制来实现的。
加锁的类型
- 数据库会有自己加锁的机制,就像java的锁颗粒度一样,更具不同情况优化
上面说到,更新会加排他锁,还有手动加共享锁SELECT … FOR UPDATE等。关于排他锁,共享锁,其实这是些大类。他下面还能细分,比如新增数据,数据都没有怎么加锁?这时候数据库会根据条件加间隙锁,他也是排他锁的一部分,但是会锁住范围:
比如A事务按照 5< age < 10 更新数据,B事务插入一条 age = 8的数据,这时候A事务不提交,B是进不去的。(需要注意的是,间隙锁仅在特定条件下启用,例如在可重复读隔离级别下执行非唯一索引扫描或者Next-Key Locks时才会出现。) - 数据库何时锁行,何时锁表
innodb:锁行主要和索引有关,如果命中索引,那就就锁住对应的索引,从而锁住该行数据。如果没有那就是表锁。
myisam:只有表锁
死锁
多个事务持有对方想要资源的锁,而且互不释放,一直卡死。
理论上:用下面相关命令,按照业务的影响程度,安全的逐个释放持有锁的业务
- 查看当前所有事务
select * from information_schema.innodb_trx; - 查看加锁信息(MySQL5.X)
select * from information_schema.innodb_locks; - 查看锁等待(MySQL5.X)
select * from information_schema.innodb_lock_waits;
-查看加锁信息(MySQL8.0)
SELECT * FROM performance_schema.data_locks;
-查看锁等待(MySQL8.0)
SELECT * FROM performance_schema.data_lock_waits; - 查看表锁
show open tables where In_use>0; - 查看最近一次死锁信息
show engine innodb status; - 执行的资源消耗情况
show PROFILES - show processlist 是显示用户正在运行的线程
show PROCESSLIST
实际上找到之后不管优先级直接干掉,然后优化业务流程,重新发布。(可不能这么说)
MYSQL服务端常用的优化点
大概的说下,一般很多公司不调的,因为直接用的阿里云,即便不是大部分公司不调性能也能应对业务。
mysql配置调优:
1.配置缓冲区大小innodb_buffer_pool_size,innodb_buffer_pool_instances,innodb_buffer_pool_chunk_size:
innodb_buffer_pool_size = innodb_buffer_pool_instances * innodb_buffer_pool_chunk_size (倍数);
当前配置的innodb_buffer_pool_size是否合适,可以通过分析InnoDB缓冲池的性能来验证。
可以使用以下公式计算InnoDB缓冲池性能:一般可以设置成物理内存的80%,阿里的一般是75%
Performance = innodb_buffer_pool_reads / innodb_buffer_pool_read_requests * 100
innodb_buffer_pool_reads:表示InnoDB缓冲池无法满足的请求数。需要从磁盘中读取。
innodb_buffer_pool_read_requests:表示从内存中读取逻辑的请求数。
例如,在我的服务器上,检查当前InnoDB缓冲池的性能
show status like 'innodb_buffer_pool_read%';
InnoDB buffer pool 命中率:
InnoDB buffer pool 命中率 = innodb_buffer_pool_read_requests / (innodb_buffer_pool_read_requests + innodb_buffer_pool_reads ) * 100
此值低于99%,则可以考虑增加innodb_buffer_pool_size。
2.不要让数据存到 SWAP 中
SWAP是什么:相当于虚拟内存,映射再磁盘上,会降低mysql的存取速度。加大内存或者禁用swap.
3.innodb_log_file_size(重做日志大小):发生错误时矫正数据,这个日志先写入缓存然后写入磁盘,太小会频繁刷盘,可以设置大点(但是恢复慢)阿里是内存的10%
4.innodb_flush_method=O_DIRECT:避免双写入缓冲
5. innodb_flush_log_at_trx_commit: 确定mysql日志何时刷盘,默认为1,每次事务提交刷盘
innodb_flush_method: 则确定日志及数据文件如何write、flush
7. max_length_for_sort_data: 排序列数据大小阈值
max_sort_length: 在排序BLOB或TEXT值时使用的字节数
这里还有个知识点: 多路排序和单路排序,多路是内存不够得情况下用的,效率较慢,如果排序缓存超过上面的参数就会启用多路,所以一般未来避免多路也会将上述两个参数设置大些。















 115
115











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









