






以前分类做分类聚合的时候,经常是写多个聚合图层,每个图层是一种分类,最近基于ol封装自己的代码框架时,也好奇的看了一下ol的聚合源码。发现一段有意思的代码。
我们先来看看ol实现聚合的代码:
ol/source/Cluster
// 聚合的入口
cluster() {
if (this.resolution === undefined || !this.source) {
return;
}
const extent = createEmpty();
const mapDistance = this.distance * this.resolution;
const features = this.source.getFeatures();
/** @type {Object<string, true>} */
const clustered = {};
for (let i = 0, ii = features.length; i < ii; i++) {
const feature = features[i];
if (!(getUid(feature) in clustered)) {
const geometry = this.geometryFunction(feature);
if (geometry) {
const coordinates = geometry.getCoordinates();
createOrUpdateFromCoordinate(coordinates, extent);
// 这里根据配置的distance以及当前feature的中心点计算一个矩形边界
buffer(extent, mapDistance, extent);
// 这里筛选所有在这个矩形中的feature
const neighbors = this.source
.getFeaturesInExtent(extent)
.filter(function (neighbor) {
// 过滤掉已经在其他聚合点中的feature对象
const uid = getUid(neighbor);
if (uid in clustered) {
return false;
}
clustered[uid] = true;
return true;
});
this.features.push(this.createCluster(neighbors, extent));
}
}
}
}
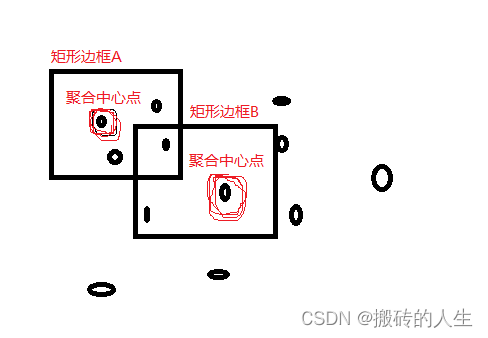
大致的逻辑就是首先从所有要聚合的feature中得到一个聚合中心点,并根据范围生成矩形边框A,然后边框中的四个点就是这次聚合的要素,然后再查找下一个没有参与聚合的中心点,并根据范围生成矩形边框B矩形边框中的左上角因为在A中聚合过了,所以会被过滤掉,所以再知道这个代码逻辑后,我们这边就可以调整ol.source.Cluster中的代码了。
原理上面已经讲过了,这边就直接上改造后的代码吧
import Cluster from 'ol/source/Cluster'
import { buffer, createEmpty, createOrUpdateFromCoordinate } from 'ol/extent.js';
import { getUid } from 'ol/util.js';
class MyCluster extends Cluster{
constructor(config){
super(config)
// 因为有业务需要,某几个点不加入聚合,所以这里扩展了这一个属性
this.unClusterFunc = config.unClusterFunc
// 需要提供类型字段,将会根据类型字段的值,自动进行分类聚合
this.typeField = config.typeField
}
/**
* 分组聚合
*/
groupCluster(feature,clustered,extent,mapDistance){
var geometry = this.geometryFunction(feature);
if (geometry) {
var coordinates = geometry.getCoordinates();
createOrUpdateFromCoordinate(coordinates, extent);
buffer(extent, mapDistance, extent);
var neighbors = this.source.getFeaturesInExtent(extent);
// 存在两个以上的点聚合
if(neighbors.length > 1 && this.typeField){
// 这次聚合按照当前中心点feature这一种类型进行
let properties = feature.get('properties') || feature.getProperties()
neighbors = neighbors.filter(neighbor=>{
const pointProperties = neighbor.get('properties') || neighbor.getProperties()
return pointProperties[this.typeField] === properties[this.typeField]
})
}
// 先删除不需要聚合的点
if(this.unClusterFunc){
const unCluster = neighbors.filter(neighbor=>{
return this.unClusterFunc(neighbor)
})
// 因为不需要聚合,所以这些点就直接单个展示,记录下这些要素
unCluster.forEach(neighbor=>{
var uid = getUid(neighbor);
if (!(uid in clustered)) {
clustered[uid] = true;
}
this.features.push(this.createCluster([neighbor],extent));
})
// 筛选除去不需要聚合的点后的几个点
neighbors = neighbors.filter(neighbor=>{
return !this.unClusterFunc(neighbor)
})
}
// 需要聚合的点
neighbors = neighbors.filter(function (neighbor) {
var uid = getUid(neighbor);
if (!(uid in clustered)) {
clustered[uid] = true;
return true;
}
else {
return false;
}
});
// 经过上面的操作后,可能会出现没有要聚合的点了,所以这里加一下判断
if(neighbors.length > 0){
this.features.push(this.createCluster(neighbors,extent));
}
}
}
/**
* 覆盖了原生的聚合方法
* @returns
*/
cluster(){
if (this.resolution === undefined || !this.source) {
return;
}
var extent = createEmpty();
var mapDistance = this.distance * this.resolution;
var features = this.source.getFeatures();
/**
* @type {!Object<string, boolean>}
*/
var clustered = {};
for (var i = 0, ii = features.length; i < ii; i++) {
var feature = features[i];
if (!(getUid(feature) in clustered)) {
this.groupCluster(feature,clustered,extent,mapDistance)
}
}
}
}
export default MyCluster

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









