







- 多流转换
无论是基本的简单转换和聚合, 还是基于窗口的计算,都是针对一条流上的数据进行 处理的。在实际应用中, 可能需要将不同来源的数据连接合并在一起处理, 也有可能需要将 一条流拆分开, 所以经常会有对多条流进行处理的场景。简单划分,多流转换可以分为“分流”和“合流”两大类。目前分流的操作一般是通 过侧输出流(side output) 来实现,而合流的算子比较丰富,根据不同的需求可以调用 union、 connect、join 以及 coGroup 等接口进行连接合并操作。
-
侧输出流
简单来说,只需要调用上下文 ctx的output()方法,就可以输出任意类型的数据了。而侧输出流的标记和提取, 都离不开一个“输出标签”(OutputTag),指定了侧输出流的 id 和类型。
代码示例:package com.company.flink.demo; import com.company.flink.data.ClickSource; import com.company.flink.entity.Event; import org.apache.flink.api.java.tuple.Tuple3; import org.apache.flink.streaming.api.datastream.DataStream; import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator; import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment; import org.apache.flink.streaming.api.functions.ProcessFunction; import org.apache.flink.util.Collector; import org.apache.flink.util.OutputTag; public class SplitStreamDemo { // 定义侧输出流 private static OutputTag<Tuple3<String, String, Long>> zhangsanTag = new OutputTag<Tuple3<String, String, Long>>("zhangsan-pv"){}; private static OutputTag<Tuple3<String, String, Long>> lisiTag = new OutputTag<Tuple3<String, String, Long>>("lisi-pv"){}; public static void main(String[] args) throws Exception { StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); SingleOutputStreamOperator<Event> stream = env .addSource(new ClickSource()); SingleOutputStreamOperator<Event> outPutStream = stream.process( new ProcessFunction<Event, Event>() { @Override public void processElement(Event value, Context ctx, Collector<Event> out) { if (value.user.equals("zhangsan")) { ctx.output(zhangsanTag, new Tuple3<>(value.user, value.url, value.timestamp)); } else if (value.user.equals("lisi")) { ctx.output(lisiTag, new Tuple3<>(value.user, value.url, value.timestamp)); } else { out.collect(value); } } }); DataStream<Tuple3<String, String, Long>> zhangsanSideOutput = outPutStream.getSideOutput(zhangsanTag); zhangsanSideOutput.print("zhangsan pv"); DataStream<Tuple3<String, String, Long>> lisiSideOutput = outPutStream.getSideOutput(lisiTag); lisiSideOutput.print("lisi pv"); outPutStream.print("else"); env.execute(); } } -
合流操作
Flink 中合流的操作会更加普遍,对应的 API 也更加丰富。
1)联合(Union)
最简单的合流操作, 就是直接将多条流合在一起,叫作流“联合”(union)。联合操作要求必须流中的数据类型必须相同,合并之后的新流会包括所有流中的元素, 数据类型不变。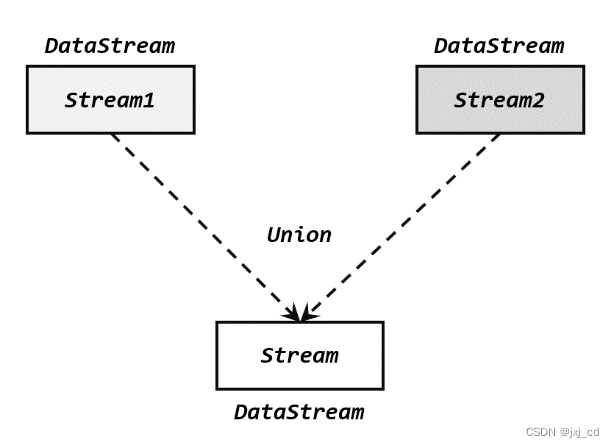
2)连接(Connect)
流的联合虽然简单,不过受限于数据类型不能改变,灵活性不足,实践中较少使用。除了联合(union),Flink 还提供了另外一种合流操作就是连接(connect)。这种操作就是直接把两条流像接线一样对接起来。
为了处理更加灵活,连接操作允许流的数据类型不同。但一个 DataStream 中的数据类型是唯一的(所以需要(co-process)转换操作)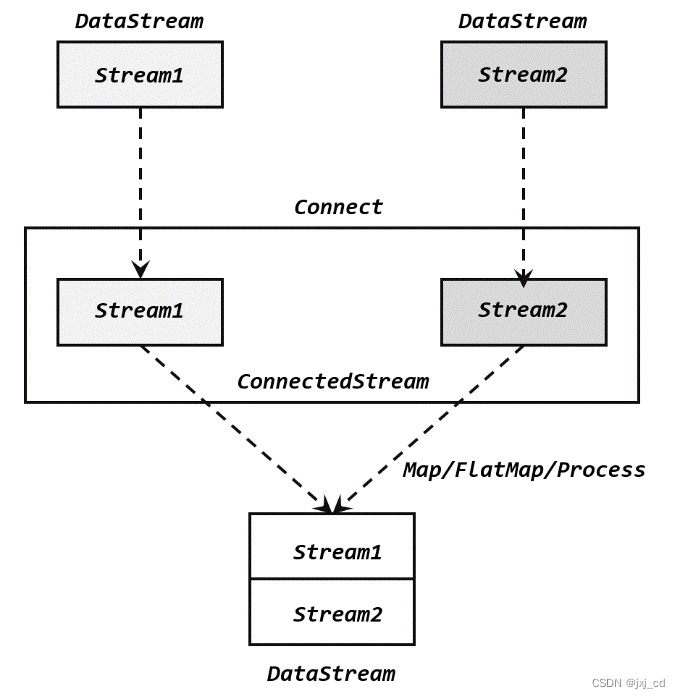
 流的联合虽然简单,不过受限于数据类型不能改变,灵活性不足,实践中较少使用。在实际应用中, 可能需要将不同来源的数据连接合并在一起处理, 也有可能需要将。最简单的合流操作, 就是直接将多条流合在一起,叫作流“联合”(单独的每一组“配对”数据了, 而是传入了可遍历的数据集合。基本的简单转换和聚合, 还是基于窗口的计算,都是针对一条流上的数据进行。求必须流中的数据类型必须相同,合并之后的新流会包括所有流中的元素,的思路就是针对一条流的每条数据,开辟出其时间戳前后的一段时间间隔,方法,就可以输出任意类型的数据了。
流的联合虽然简单,不过受限于数据类型不能改变,灵活性不足,实践中较少使用。在实际应用中, 可能需要将不同来源的数据连接合并在一起处理, 也有可能需要将。最简单的合流操作, 就是直接将多条流合在一起,叫作流“联合”(单独的每一组“配对”数据了, 而是传入了可遍历的数据集合。基本的简单转换和聚合, 还是基于窗口的计算,都是针对一条流上的数据进行。求必须流中的数据类型必须相同,合并之后的新流会包括所有流中的元素,的思路就是针对一条流的每条数据,开辟出其时间戳前后的一段时间间隔,方法,就可以输出任意类型的数据了。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 6931
6931











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









