









1. 前言
本次爬虫使用:
- Python3
- requsts 请求
- 正则解析
- MySQL 存储
2. 爬取结果示例
代码运行:
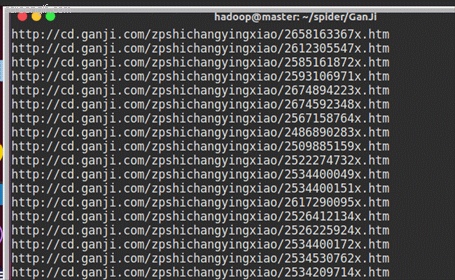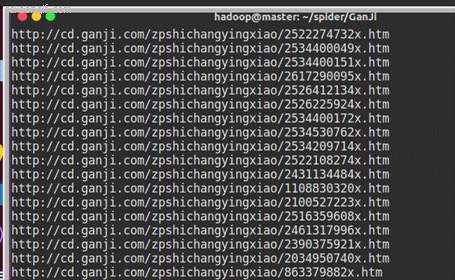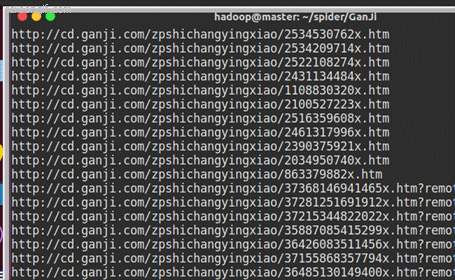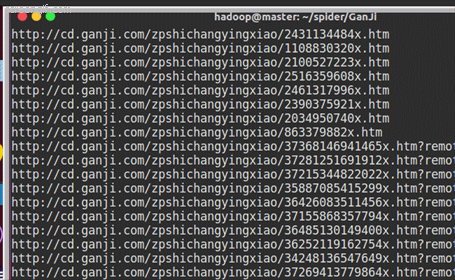
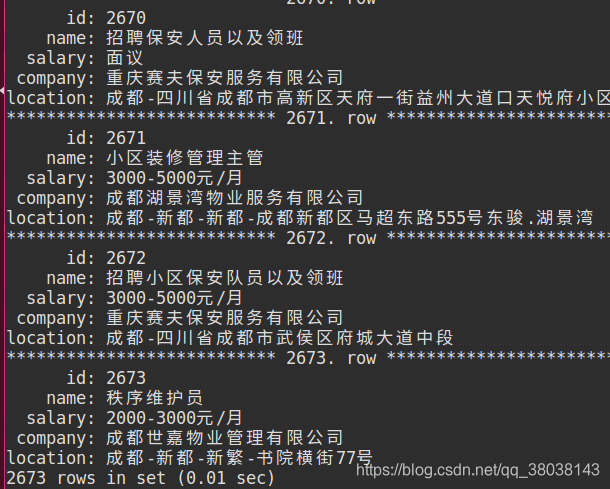
时间:2018年12月25日,每个类别分别爬取 1 个分页,共获取:2673条数据。(运气好,一次运行完成,IP没有被限制)
同时,此次代码只适用于爬取少量子页(多了会被限制IP,并且代码中设置了被限制后存入MySQL为null值,后面有详细介绍),初步分析最多设置爬取子页不应超过2页(测试过一次,遇到一次验证)才可能不会被限制IP。
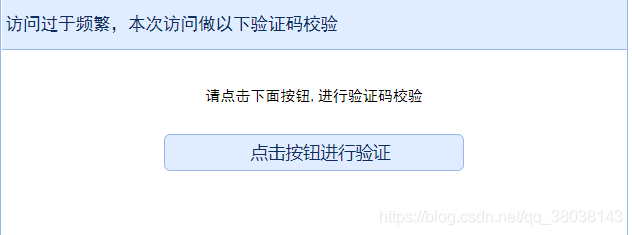
目前,代码自动显示验证提醒,需要手动访问赶集网官网进行验证。
自动验证:考虑可以使用代理池(IP代理)或者Selenium(破解验证)两种方式编写升级版。博主等有时间了再写篇博客,这里先埋个坑。
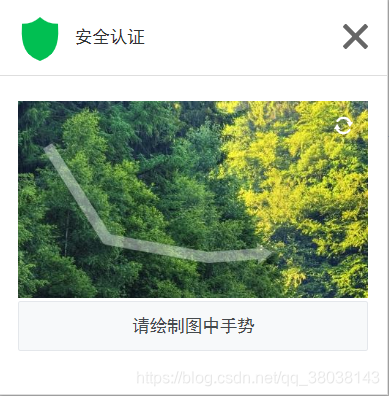
顺带一提,2018年12月(时间不同,可能其验证方式不同)赶集网的验证方式为通过鼠标画一条规定的线,符合后即通过验证。
3. 运行须知
- 运行前确保MySQL中已创建相应数据库、表,并且在config.py中设置MySQL用户名、密码。
- 运行过程中很可能报错退出,最可能的原因就是访问网站过多,IP被限制,需要验证,手动使用浏览器访问赶集网解除验证即可----有时候爬取几千条也不会被限制,有时刚爬取就被限制。(可以使用代理池更换IP实现)
- 如果报错后重新运行,最好删除数据库,再新建—避免上次运行保留到数据库的信息重复爬取。
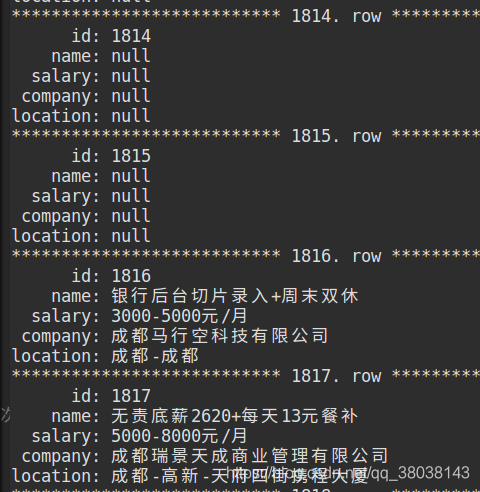
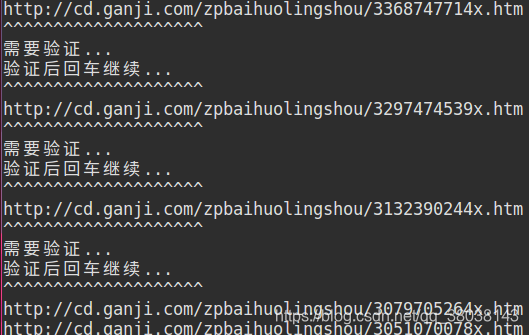
注:如果数据库中出现全字段为 null,即IP已经被限制,重新验证后即可继续爬取:
下图为验证前后对比:
更新:2019年3月
上述存入null值代码已更新,null不会存入数据库,而程序也会等待你手动验证,如下图:
4. 代码解析
共包括 5 个文件:
- config.py
存储配置信息、全局变量 - ganjiDB.sql
创建数据库、表代码(运行爬虫之前复制该文件内容,在MySQL中运行) - mysql.py
python与MySQL的连接,通过该文件中的类MySQL(),将数据存入到MySQL。该文件包含一个类、三个方法:初始化、插入数据、查询数据。 - run.py
爬虫运行文件(命令:python3 run.py 即可启动爬虫) - spider.py
爬虫核心代码,包括:请求首页HTML、获取类别URL、获取工作URL、正则解析、存入MySQL等。
spider.py核心思想:
本次爬虫以成都地区为例:
则 BASE_URL = http://cd.ganji.com,
代码步骤可大致分为:
-
爬取首页HTML源码(BASE_URL ),根据HTML正则解析出类别地址、名称存入表 types_url。
下图为解析的类别,其中最后 “其他职位” 不做解析,舍弃:

-
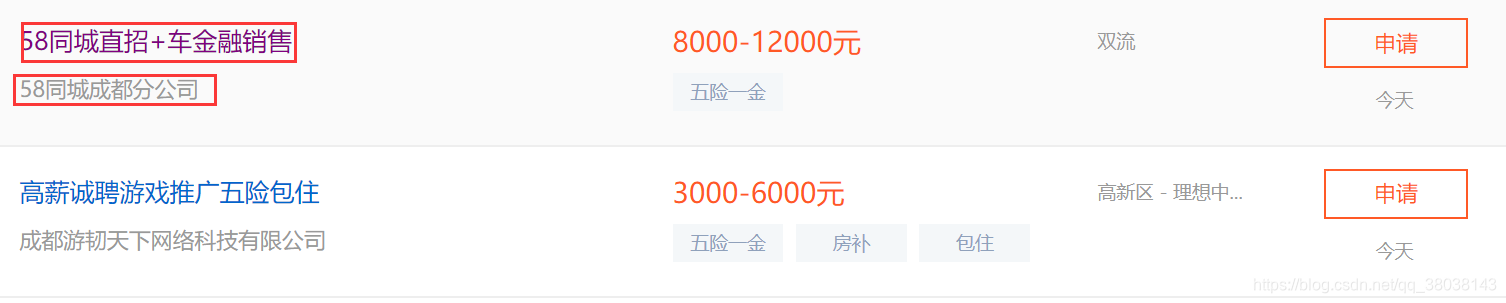
获取types_url表内容,请求每行记录的 url 提取HTML源码,根据源码使用正则提取每个工作的url、名称并存入数据表 jobs_url。
下图为提取的工作:
-
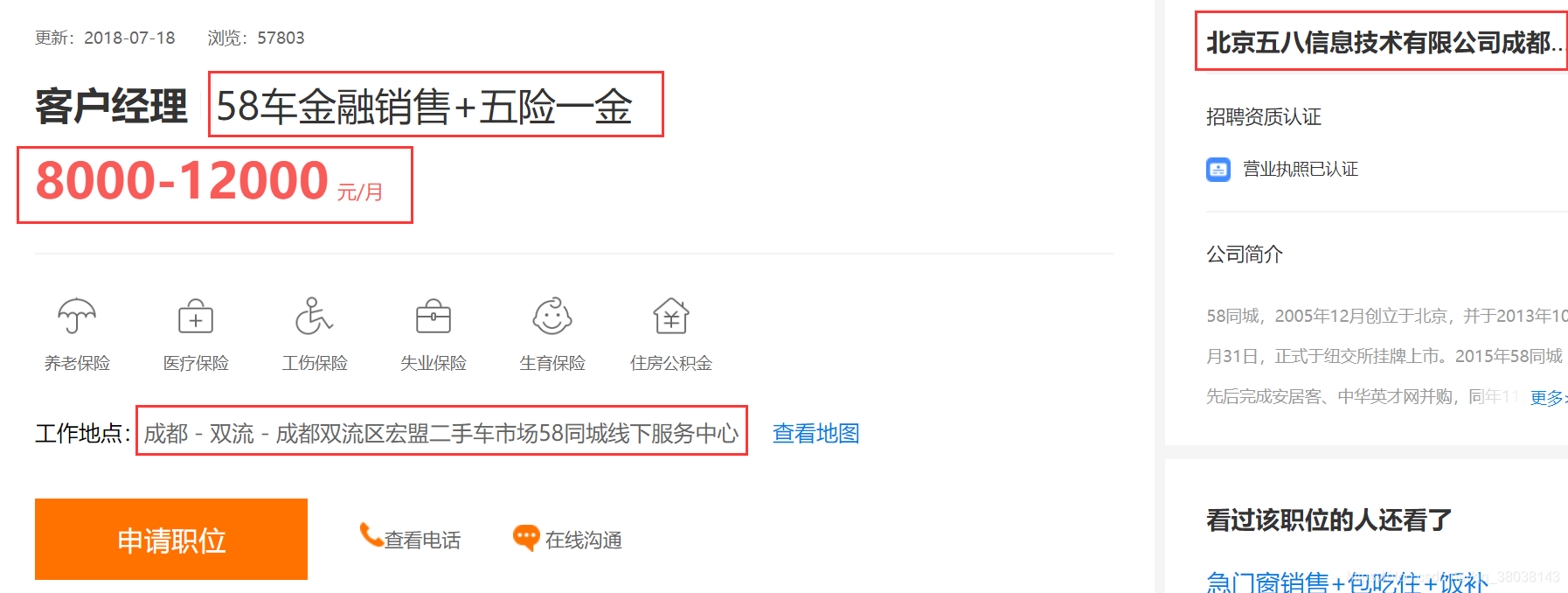
获取 jobs_url表内容,请求每行记录的 url 提取HTML源码,根据源码使用正则解析每个工作的详细信息。
下图为解析的工作信息:














 9770
9770











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









