







springboot集成kafka实战项目,kafka生产者、消费者、创建topic,指定消费分区
前言
本项目代码可直接集成到你现有的springboot项目中。功能包括:
1.kafka生产者配置。
2.kafka消费者配置。(指定分区消费)
3.kafka topic配置。
工具:
1.windows环境下kafka_2.12-2.8.0。
2.offsetexplorer.exe kafkaTools工具(查看kafka数据)。
3.idea 开发工具。
4.springboot。
windows环境下kafka启动配置
- 配置文件
需要修改zookeeper.properties 和server.properties。
修改ip为本机ip(启动远程访问)
修改logs文件目录
zookeeper.properties配置
# Licensed to the Apache Software Foundation (ASF) under one or more
# contributor license agreements. See the NOTICE file distributed with
# this work for additional information regarding copyright ownership.
# The ASF licenses this file to You under the Apache License, Version 2.0
# (the "License"); you may not use this file except in compliance with
# the License. You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
# the directory where the snapshot is stored.
dataDir=/kafkadata
# the port at which the clients will connect
clientPort=2181
# disable the per-ip limit on the number of connections since this is a non-production config
maxClientCnxns=0
# Disable the adminserver by default to avoid port conflicts.
# Set the port to something non-conflicting if choosing to enable this
admin.enableServer=false
# admin.serverPort=8080
server.properties文件配置
# Licensed to the Apache Software Foundation (ASF) under one or more
# contributor license agreements. See the NOTICE file distributed with
# this work for additional information regarding copyright ownership.
# The ASF licenses this file to You under the Apache License, Version 2.0
# (the "License"); you may not use this file except in compliance with
# the License. You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
# see kafka.server.KafkaConfig for additional details and defaults
############################# Server Basics #############################
# The id of the broker. This must be set to a unique integer for each broker.
broker.id=0
############################# Socket Server Settings #############################
# The address the socket server listens on. It will get the value returned from
# java.net.InetAddress.getCanonicalHostName() if not configured.
# FORMAT:
# listeners = listener_name://host_name:port
# EXAMPLE:
# listeners = PLAINTEXT://your.host.name:9092
listeners=PLAINTEXT://10.4.127.171:9092
# Hostname and port the broker will advertise to producers and consumers. If not set,
# it uses the value for "listeners" if configured. Otherwise, it will use the value
# returned from java.net.InetAddress.getCanonicalHostName().
advertised.listeners=PLAINTEXT://10.4.127.171:9092
# Maps listener names to security protocols, the default is for them to be the same. See the config documentation for more details
#listener.security.protocol.map=PLAINTEXT:PLAINTEXT,SSL:SSL,SASL_PLAINTEXT:SASL_PLAINTEXT,SASL_SSL:SASL_SSL
# The number of threads that the server uses for receiving requests from the network and sending responses to the network
num.network.threads=3
# The number of threads that the server uses for processing requests, which may include disk I/O
num.io.threads=8
# The send buffer (SO_SNDBUF) used by the socket server
socket.send.buffer.bytes=102400
# The receive buffer (SO_RCVBUF) used by the socket server
socket.receive.buffer.bytes=102400
# The maximum size of a request that the socket server will accept (protection against OOM)
socket.request.max.bytes=104857600
############################# Log Basics #############################
# A comma separated list of directories under which to store log files
log.dirs=/logs
# The default number of log partitions per topic. More partitions allow greater
# parallelism for consumption, but this will also result in more files across
# the brokers.
num.partitions=1
# The number of threads per data directory to be used for log recovery at startup and flushing at shutdown.
# This value is recommended to be increased for installations with data dirs located in RAID array.
num.recovery.threads.per.data.dir=1
############################# Internal Topic Settings #############################
# The replication factor for the group metadata internal topics "__consumer_offsets" and "__transaction_state"
# For anything other than development testing, a value greater than 1 is recommended to ensure availability such as 3.
offsets.topic.replication.factor=1
transaction.state.log.replication.factor=1
transaction.state.log.min.isr=1
############################# Log Flush Policy #############################
# Messages are immediately written to the filesystem but by default we only fsync() to sync
# the OS cache lazily. The following configurations control the flush of data to disk.
# There are a few important trade-offs here:
# 1. Durability: Unflushed data may be lost if you are not using replication.
# 2. Latency: Very large flush intervals may lead to latency spikes when the flush does occur as there will be a lot of data to flush.
# 3. Throughput: The flush is generally the most expensive operation, and a small flush interval may lead to excessive seeks.
# The settings below allow one to configure the flush policy to flush data after a period of time or
# every N messages (or both). This can be done globally and overridden on a per-topic basis.
# The number of messages to accept before forcing a flush of data to disk
#log.flush.interval.messages=10000
# The maximum amount of time a message can sit in a log before we force a flush
#log.flush.interval.ms=1000
############################# Log Retention Policy #############################
# The following configurations control the disposal of log segments. The policy can
# be set to delete segments after a period of time, or after a given size has accumulated.
# A segment will be deleted whenever *either* of these criteria are met. Deletion always happens
# from the end of the log.
# The minimum age of a log file to be eligible for deletion due to age
log.retention.hours=168
# A size-based retention policy for logs. Segments are pruned from the log unless the remaining
# segments drop below log.retention.bytes. Functions independently of log.retention.hours.
#log.retention.bytes=1073741824
# The maximum size of a log segment file. When this size is reached a new log segment will be created.
log.segment.bytes=1073741824
# The interval at which log segments are checked to see if they can be deleted according
# to the retention policies
log.retention.check.interval.ms=300000
############################# Zookeeper #############################
# Zookeeper connection string (see zookeeper docs for details).
# This is a comma separated host:port pairs, each corresponding to a zk
# server. e.g. "127.0.0.1:3000,127.0.0.1:3001,127.0.0.1:3002".
# You can also append an optional chroot string to the urls to specify the
# root directory for all kafka znodes.
zookeeper.connect=localhost:2181
# Timeout in ms for connecting to zookeeper
zookeeper.connection.timeout.ms=18000
############################# Group Coordinator Settings #############################
# The following configuration specifies the time, in milliseconds, that the GroupCoordinator will delay the initial consumer rebalance.
# The rebalance will be further delayed by the value of group.initial.rebalance.delay.ms as new members join the group, up to a maximum of max.poll.interval.ms.
# The default value for this is 3 seconds.
# We override this to 0 here as it makes for a better out-of-the-box experience for development and testing.
# However, in production environments the default value of 3 seconds is more suitable as this will help to avoid unnecessary, and potentially expensive, rebalances during application startup.
group.initial.rebalance.delay.ms=0
- 启动zookeeper
在kafka_2.12-2.8.0目录下输入命令
.\bin\windows\zookeeper-server-start.bat .\config\zookeeper.properties
启动zookeeper
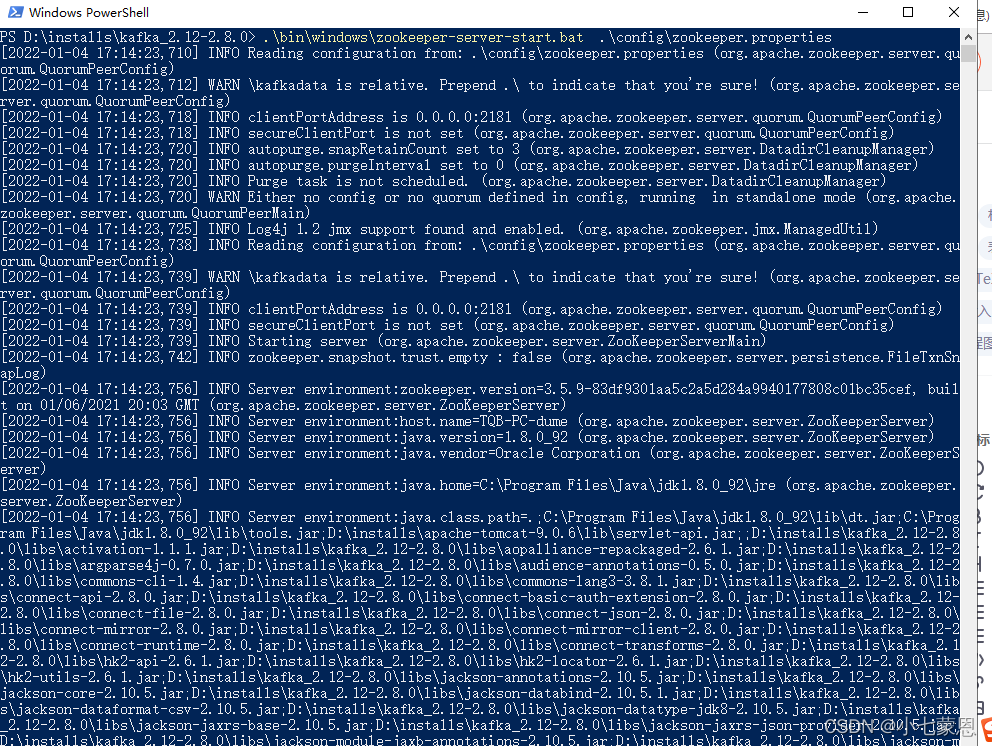
3. 启动kafka
在kafka_2.12-2.8.0目录下输入命令
.\bin\windows\kafka-server-start.bat .\config\server.properties

代码实现
springboot项目的创建不再赘述。
1.pom文件配置
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 https://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>2.6.2</version>
<relativePath/> <!-- lookup parent from repository -->
</parent>
<groupId>com.example</groupId>
<artifactId>dume</artifactId>
<version>1.0-SNAPSHOT</version>
<name>dume-springboot-kafka-server</name>
<description>dume-springboot-kafka-server</description>
<properties>
<java.version>1.8</java.version>
</properties>
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
<dependency>
<groupId>org.springframework.kafka</groupId>
<artifactId>spring-kafka</artifactId>
</dependency>
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>fastjson</artifactId>
<version>1.2.49</version>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-maven-plugin</artifactId>
</plugin>
</plugins>
</build>
</project>
2.yml文件配置
server:
port: 8186
servlet:
context-path: /dume
session:
timeout: 30m #30分钟,测试的话时间不能太短,否
kafkaserver:
server: 10.4.127.171:9092
topic: dume-topic
parttition: 0
group-id: dume
3.topic配置
package com.example.dume.config;
import org.apache.kafka.clients.admin.AdminClientConfig;
import org.apache.kafka.clients.admin.NewTopic;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.kafka.core.KafkaAdmin;
import java.util.HashMap;
import java.util.Map;
/**
* @author dume
* @create 2021-09-24 10:02
**/
@Configuration
public class KafkaTopicConfig {
@Value("${kafkaserver.server}")
private String boardServer;
@Value("${kafkaserver.topic}")
private String topic;
/**
* 定义一个KafkaAdmin的bean,可以自动检测集群中是否存在topic,不存在则创建
*/
@Bean
public KafkaAdmin kafkaAdmin() {
Map<String, Object> configs = new HashMap<>();
// 指定多个kafka集群多个地址,例如:192.168.2.11,9092,192.168.2.12:9092,192.168.2.13:9092
configs.put(AdminClientConfig.BOOTSTRAP_SERVERS_CONFIG, boardServer);
return new KafkaAdmin(configs);
}
/**
* 创建 Topic
*/
@Bean
public NewTopic topicinfo() {
// 创建topic,需要指定创建的topic的"名称"、"分区数"、"副本数量(副本数数目设置要小于Broker数量)"
return new NewTopic(topic, 3, (short) 1);
}
}
4.生产者配置
package com.example.dume.config;
import org.apache.kafka.clients.producer.ProducerConfig;
import org.apache.kafka.common.serialization.StringSerializer;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.kafka.annotation.EnableKafka;
import org.springframework.kafka.core.DefaultKafkaProducerFactory;
import org.springframework.kafka.core.KafkaTemplate;
import org.springframework.kafka.core.ProducerFactory;
import java.util.HashMap;
import java.util.Map;
/**
* @author dume
* @create 2021-09-15 17:45
**/
/**
* 设置@Configuration、@EnableKafka两个注解,声明Config并且打开KafkaTemplate能力。
*/
@Configuration
@EnableKafka
public class KafkaProducerConfig {
@Value("${kafkaserver.server}")
private String boardServer;
/**
* Producer 参数配置
*/
@Bean
public Map<String, Object> producerConfigs() {
Map<String, Object> props = new HashMap<>();
// 指定多个kafka集群多个地址
props.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, boardServer);
// 重试次数,0为不启用重试机制
props.put(ProducerConfig.RETRIES_CONFIG, 0);
//同步到副本, 默认为1
// acks=0 把消息发送到kafka就认为发送成功
// acks=1 把消息发送到kafka leader分区,并且写入磁盘就认为发送成功
// acks=all 把消息发送到kafka leader分区,并且leader分区的副本follower对消息进行了同步就任务发送成功
props.put(ProducerConfig.ACKS_CONFIG, "1");
// 生产者空间不足时,send()被阻塞的时间,默认60s
props.put(ProducerConfig.MAX_BLOCK_MS_CONFIG, 6000);
// 控制批处理大小,单位为字节
props.put(ProducerConfig.BATCH_SIZE_CONFIG, 4096);
// 批量发送,延迟为1毫秒,启用该功能能有效减少生产者发送消息次数,从而提高并发量
props.put(ProducerConfig.LINGER_MS_CONFIG, 1);
// 生产者可以使用的总内存字节来缓冲等待发送到服务器的记录
props.put(ProducerConfig.BUFFER_MEMORY_CONFIG, 40960);
// 消息的最大大小限制,也就是说send的消息大小不能超过这个限制, 默认1048576(1MB)
props.put(ProducerConfig.MAX_REQUEST_SIZE_CONFIG,1048576);
// 键的序列化方式
props.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class);
// 值的序列化方式
props.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class);
// 压缩消息,支持四种类型,分别为:none、lz4、gzip、snappy,默认为none。
// 消费者默认支持解压,所以压缩设置在生产者,消费者无需设置。
props.put(ProducerConfig.COMPRESSION_TYPE_CONFIG,"none");
return props;
}
/**
* Producer 工厂配置
*/
@Bean
public ProducerFactory<String, String> producerFactory() {
return new DefaultKafkaProducerFactory<>(producerConfigs());
}
/**
* Producer Template 配置
*/
@Bean(name="kafkaTemplate")
public KafkaTemplate<String, String> kafkaTemplate() {
return new KafkaTemplate<>(producerFactory());
}
}
5.消费者配置
package com.example.dume.config;
import org.apache.kafka.clients.consumer.ConsumerConfig;
import org.apache.kafka.common.serialization.StringDeserializer;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.kafka.annotation.EnableKafka;
import org.springframework.kafka.config.ConcurrentKafkaListenerContainerFactory;
import org.springframework.kafka.config.KafkaListenerContainerFactory;
import org.springframework.kafka.core.ConsumerFactory;
import org.springframework.kafka.core.DefaultKafkaConsumerFactory;
import org.springframework.kafka.listener.ConcurrentMessageListenerContainer;
import java.util.HashMap;
import java.util.Map;
/**
* @author dume
* @create 2021-09-15 17:45
**/
@Configuration
@EnableKafka
public class KafkaConsumerConfig {
@Value("${kafkaserver.server}")
private String Server;
@Value("${kafkaserver.group-id}")
private String GroupId;
@Bean
KafkaListenerContainerFactory<ConcurrentMessageListenerContainer<String, String>> kafkaListenerContainerFactory( ) {
ConcurrentKafkaListenerContainerFactory<String, String> factory = new ConcurrentKafkaListenerContainerFactory<>();
// 设置消费者工厂
factory.setConsumerFactory(consumerFactory());
// 消费者组中线程数量
factory.setConcurrency(3);
// 拉取超时时间
factory.getContainerProperties().setPollTimeout(3000);
//不自动启动
factory.setAutoStartup(true);
// 当使用批量监听器时需要设置为true
factory.setBatchListener(true);
return factory;
}
@Bean
public ConsumerFactory<String, String> consumerFactory() {
return new DefaultKafkaConsumerFactory<>(consumerConfigs());
}
@Bean
public Map<String, Object> consumerConfigs() {
Map<String, Object> propsMap = new HashMap<>();
// Kafka地址
propsMap.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, Server);
//配置默认分组,这里没有配置+在监听的地方没有设置groupId,多个服务会出现收到相同消息情况
propsMap.put(ConsumerConfig.GROUP_ID_CONFIG, GroupId);
// 是否自动提交offset偏移量(默认true)
propsMap.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, true);
//设置每次拉取最大数量
propsMap.put(ConsumerConfig.MAX_POLL_RECORDS_CONFIG,1000);
// 自动提交的频率(ms)
propsMap.put(ConsumerConfig.AUTO_COMMIT_INTERVAL_MS_CONFIG, "100");
// Session超时设置
propsMap.put(ConsumerConfig.SESSION_TIMEOUT_MS_CONFIG, "15000");
// 键的反序列化方式
propsMap.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class);
// 值的反序列化方式
propsMap.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class);
// offset偏移量规则设置:
// (1)、earliest:当各分区下有已提交的offset时,从提交的offset开始消费;无提交的offset时,从头开始消费
// (2)、latest:当各分区下有已提交的offset时,从提交的offset开始消费;无提交的offset时,消费新产生的该分区下的数据
// (3)、none:topic各分区都存在已提交的offset时,从offset后开始消费;只要有一个分区不存在已提交的offset,则抛出异常
propsMap.put(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG, "latest");
return propsMap;
}
}
6.生产者manager代码实现
package com.example.dume.manager;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.beans.factory.annotation.Qualifier;
import org.springframework.kafka.core.KafkaTemplate;
import org.springframework.stereotype.Service;
import org.springframework.util.concurrent.ListenableFutureCallback;
import java.util.concurrent.ExecutionException;
import java.util.concurrent.TimeUnit;
import java.util.concurrent.TimeoutException;
/**
* @author dume
* @create 2021-09-24 9:43
**/
@Service
public class KafkaProducerManager {
private static Logger logger = LoggerFactory.getLogger("adminLogger");
@Autowired
@Qualifier("kafkaTemplate")
private KafkaTemplate kafkaTemplate;
/**
* producer 同步方式发送数据
*
* @param topic topic名称
* @param message producer发送的数据
*/
public void sendMessageSync(String topic, String message) throws InterruptedException, ExecutionException, TimeoutException {
kafkaTemplate.send(topic, message).get(10, TimeUnit.SECONDS);
}
/**
* producer 异步方式发送数据
*
* @param topic topic名称
* @param message producer发送的数据
*/
public void sendMessageAsync(String topic, String message) {
kafkaTemplate.send(topic, message).addCallback(new ListenableFutureCallback() {
@Override
public void onFailure(Throwable throwable) {
logger.error("kafka send failure !");
}
@Override
public void onSuccess(Object o) {
// logger.info("kafka send success !");
}
});
}
}
7.消费者manager代码实现
package com.example.dume.manager;
import com.alibaba.fastjson.JSONObject;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.kafka.annotation.KafkaListener;
import org.springframework.kafka.annotation.TopicPartition;
import org.springframework.stereotype.Component;
import java.text.SimpleDateFormat;
import java.util.List;
import java.util.Optional;
/**
* @author dume
* @create 2021-09-16 9:06
**/
@Component
public class KafkaComsumerManager {
private static Logger logger = LoggerFactory.getLogger("adminLogger");
private static SimpleDateFormat formatter = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss");
/**
* 指定topic
* 指定消费分区parttition
* @param records
*/
@KafkaListener(topicPartitions = {
@TopicPartition(topic = "${kafkaserver.topic}", partitions = "${kafkaserver.parttition}" )},
containerFactory = "kafkaListenerContainerFactory" )
public void onMessage(List<ConsumerRecord> records) {
logger.info("**********************************接收数量{}**************************************",records.size());
for(ConsumerRecord record :records ){
Optional<Object> kafkaMassage = Optional.ofNullable(record.value());
if(kafkaMassage.isPresent()){
try {
Long current = System.currentTimeMillis();
logger.info("**********************************kafka接收信息打印开始**************************************");
logger.info("kafka接收信息:"+'\t'+record.toString());
logger.info("kafka数据:"+'\t'+record.value());
logger.info("分区:"+ record.partition());
logger.info("偏移量:" + record.offset());
logger.info("报文时间:" + formatter.format(record.timestamp()));
logger.info("系统时间:" + formatter.format(current));
logger.info("**********************************kafka信息打印结束**************************************");
JSONObject value = JSONObject.parseObject(record.value().toString());
} catch (Exception e) {
// TODO: handle exception
logger.error("********kafka接收数据出错:{}********",e.getMessage());
}
}
}
}
}
测试
编写测试接口
package com.example.dume.controller;
import com.alibaba.fastjson.JSONObject;
import com.example.dume.manager.KafkaProducerManager;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.web.bind.annotation.PostMapping;
import org.springframework.web.bind.annotation.RequestBody;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;
/**
* @author dume
* @create 2022-01-04 16:50
**/
@RestController
@RequestMapping("/kafka")
public class KafkaController {
private static Logger logger = LoggerFactory.getLogger("adminLogger");
private static final String producersuccess =" 生产数据到kafka成功!";
@Value("${kafkaserver.topic}")
private String topic;
@Autowired
private KafkaProducerManager kafkaProducerManager;
@PostMapping(value = "/producerData")
public JSONObject producerData(@RequestBody JSONObject object) {
kafkaProducerManager.sendMessageAsync(topic,object.toJSONString());
JSONObject o = new JSONObject();
o.put("message",producersuccess);
logger.info(producersuccess);
return o;
}
}
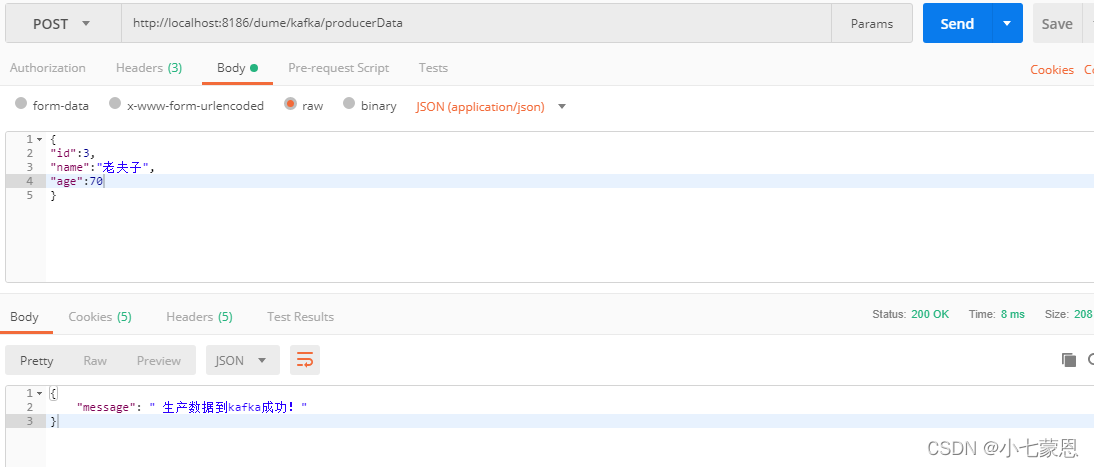
postman 接口测试向kafka插入数据:
使用kafkaTool查看插入数据:
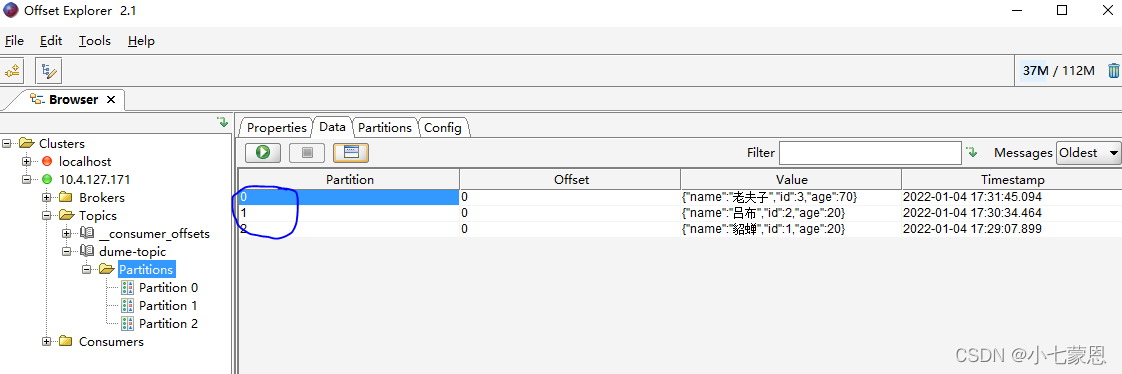
消费者指定消费分区0内数据,消费者只接收到了 parttition=0的数据
2022-01-04 17:29:07.911 INFO 11104 --- [nio-8186-exec-2] adminLogger : 生产数据到kafka成功!
2022-01-04 17:30:34.465 INFO 11104 --- [nio-8186-exec-5] adminLogger : 生产数据到kafka成功!
2022-01-04 17:31:45.094 INFO 11104 --- [nio-8186-exec-8] adminLogger : 生产数据到kafka成功!
2022-01-04 17:31:45.104 INFO 11104 --- [ntainer#0-0-C-1] adminLogger : **********************************接收数量1**************************************
2022-01-04 17:31:45.104 INFO 11104 --- [ntainer#0-0-C-1] adminLogger : **********************************kafka接收信息打印开始**************************************
2022-01-04 17:31:45.104 INFO 11104 --- [ntainer#0-0-C-1] adminLogger : kafka接收信息: ConsumerRecord(topic = dume-topic, partition = 0, leaderEpoch = 0, offset = 0, CreateTime = 1641288705094, serialized key size = -1, serialized value size = 36, headers = RecordHeaders(headers = [], isReadOnly = false), key = null, value = {"name":"老夫子","id":3,"age":70})
2022-01-04 17:31:45.104 INFO 11104 --- [ntainer#0-0-C-1] adminLogger : kafka数据: {"name":"老夫子","id":3,"age":70}
2022-01-04 17:31:45.104 INFO 11104 --- [ntainer#0-0-C-1] adminLogger : 分区:0
2022-01-04 17:31:45.104 INFO 11104 --- [ntainer#0-0-C-1] adminLogger : 偏移量:0
2022-01-04 17:31:45.105 INFO 11104 --- [ntainer#0-0-C-1] adminLogger : 报文时间:2022-01-04 17:31:45
2022-01-04 17:31:45.106 INFO 11104 --- [ntainer#0-0-C-1] adminLogger : 系统时间:2022-01-04 17:31:45
2022-01-04 17:31:45.106 INFO 11104 --- [ntainer#0-0-C-1] adminLogger : **********************************kafka信息打印结束**************************************















 4644
4644











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











