







| hadoo系列(一)hadoop集群安装 | |
| hadoop系列(二)HA高可用方式部署 | |
| hadoop系列(三) HDFS的shell操作和常用API操作 | |
| hadoop系列(四)HDFS的工作机制,MapReduce,yarn流程及核心原理 | |
| hadoop系列(五) 源码分析 |
目录
1.HDFS权限介绍
hdfs是一个文件系统
所以他有类似于unix,linux/有用户的概念(持有者,持有组)有权限的概念
有权限的概念:hdfs 的权限是自己控制的,来自于hdfs的超级用户(hadoop的启动用户)
node1:master
# 使用超级用户hadoop创建一个文件并且赋予test用户权限
su hadoop
hdfs dfs -mkdir /tmp
hdfs dfs -chown test:test /tmp
hdfs dfs -chmod 770 /tmp
node2
root:使用root在系统中创建用户good和组test
useradd good
passwd good
groupadd test
usermod -a -G test good
su good
hdfs dfs -mkdir /tmp/abc #失败
*node1
#在主节点在执行一遍增加用户的操作,因为hdfs是根据系统用户权限来的
root:
useradd good
groupadd test
usermod -a -G test good
# (必须)使用超级用户(hadoop启动)更新权限列表
su hadoop
hdfs dfsadmin -refreshUserToGroupsMappings
node2
#回到此台机器的指定用户,再次查询用户组权限,会发现更新了
good
hdfs groups
good:good test
hdfs dfs -mkdir /tmp/abc #成功使用:./hdfs dfs -chown test:test /root


结论 默认hdfs 依赖操作系统上的用户和组
2. hdfs的shell操作
2.1 命令大全
bin/hadoop fs
bin/hdfs dfs
#-chgrp、-chmod、-chown:Linux文件系统中的用法一样,修改文件所属权限
#追加一个文件到已经存在的文件末尾
[-appendToFile <localsrc> ... <dst>]
[-cat [-ignoreCrc] <src> ...]
[-chgrp [-R] GROUP PATH...]
[-chmod [-R] <MODE[,MODE]... | OCTALMODE> PATH...]
[-chown [-R] [OWNER][:[GROUP]] PATH...]
#从本地文件系统中拷贝文件到HDFS路径去
[-copyFromLocal [-f] [-p] <localsrc> ... <dst>]
#从HDFS拷贝到本地
[-copyToLocal [-p] [-ignoreCrc] [-crc] <src> ... <localdst>]
[-count [-q] <path> ...]
[-cp [-f] [-p] <src> ... <dst>]
[-df [-h] [<path> ...]]
[-du [-s] [-h] <path> ...]
#等同于copyToLocal,生产环境更习惯用get
[-get [-p] [-ignoreCrc] [-crc] <src> ... <localdst>]
[-getmerge [-nl] <src> <localdst>]
[-help [cmd ...]]
[-ls [-d] [-h] [-R] [<path> ...]]
[-mkdir [-p] <path> ...]
#从本地剪切粘贴到HDFS
[-moveFromLocal <localsrc> ... <dst>]
[-moveToLocal <src> <localdst>]
[-mv <src> ... <dst>]
#等同于copyFromLocal,生产环境更习惯用put
[-put [-f] [-p] <localsrc> ... <dst>]
[-rm [-f] [-r|-R] [-skipTrash] <src> ...]
[-rmdir [--ignore-fail-on-non-empty] <dir> ...]
<acl_spec> <path>]]
##**-setrep:设置HDFS中文件的副本数量
[-setrep [-R] [-w] <rep> <path> ...]
[-stat [format] <path> ...]
[-tail [-f] <file>]
[-test -[defsz] <path>]
[-text [-ignoreCrc] <src> ...]
3. hdfs API实操之IDEA集成开发环境
3.1.配置电脑的环境变量
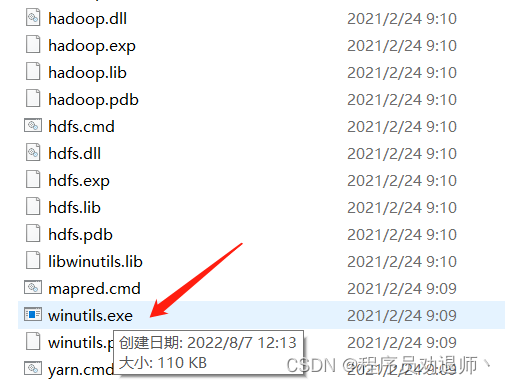
3.1.1下载对应版本的winutils
3.1.2 配置环境变量
HADOOP_HOME:D:\ProgramFiles\hadoop-3.1.0
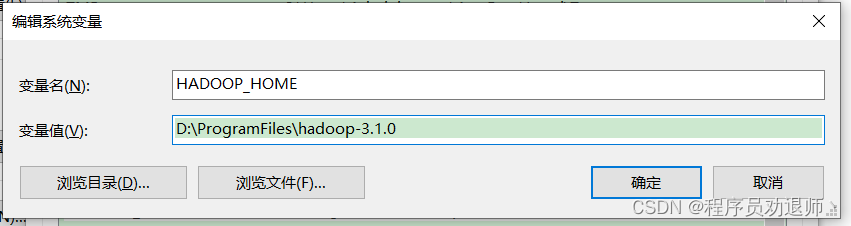
Path:增加%HAOOP_HOME%\bin
2.1.3 测试使用
如果配置后点击winutils.exe一闪而过说明配置成功,是在不行重启电脑一般会生效
我的是点击验证可以,但是idea开发demo还是有问题,重启后就可以了
hadoop最基础的pom,版本依据自己的hadoop版本
<dependencies>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>2.6.5</version>
</dependency>
</dependencies>提交方式:
4. idea开发MapReduce第一个程序
创建java项目加入依赖:
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>3.1.3</version>
</dependency>4.1 实现Mapper类重写map方法
public class WordCountMapper extends Mapper<LongWritable, Text,Text, IntWritable> {
private Text outkey = new Text();
IntWritable outV = new IntWritable(1);
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
//1. 获取一行数据
String line = value.toString();
//2. 切割数据
String[] words = line.split(" ");
// 3. 循环写出
for(String word:words){
outkey.set(word);
context.write(outkey,outV);
}
}
}4.2 实现Reducer类重写reduce方法
public class WordCountReducer extends Reducer<Text, IntWritable,Text,IntWritable> {
@Override
protected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {
// (hello,(1,1,1))
int sum = 0;
for (IntWritable value : values) {
sum+=value.get();
}
//写出
context.write(key,new IntWritable(sum));
}
}4.3 WordCountDriver启动类
public class WordCountDriver {
public static void main(String[] args) throws IOException, InterruptedException, ClassNotFoundException {
//1. 获取job
Configuration conf = new Configuration();
Job job = Job.getInstance(conf);
//2. 设置jar路径
job.setJarByClass(WordCountDriver.class);
//3. 关联mapper 和reducer
job.setMapperClass(WordCountMapper.class);
job.setReducerClass(WordCountReducer.class);
//4. 设置map输出的key value 类型
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
//5. 设置最终输出的k v 类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
//6. 设置输入路径和输入路径
// 使用 设置输入路径
FileInputFormat.setInputPaths(job, new Path("D:\\workSpace\\mycode\\mapreduce_demo\\src\\main\\indata\\input.txt"));
FileOutputFormat.setOutputPath(job, new Path("D:\\workSpace\\mycode\\mapreduce_demo\\src\\main\\outdata"));
//7. 提交job
boolean result = job.waitForCompletion(true);
System.exit(result ? 0 : 1);
}
}
5. HDFS常用API演示
5.1 创建文件目录
/**
* 创建文件目录
* @throws IOException
* @throws URISyntaxException
* @throws InterruptedException
*/
@Test
public void testMkdirs() throws IOException, URISyntaxException, InterruptedException {
// 1 获取文件系统
Configuration configuration = new Configuration();
// FileSystem fs = FileSystem.get(new URI("hdfs://hadoop102:8020"), configuration);
FileSystem fs = FileSystem.get(new URI("hdfs://hadoop11:8020"), configuration,"root");
// 2 创建目录
fs.mkdirs(new Path("/root/firstDemo"));
// 3 关闭资源
fs.close();
}5.2 HDFS文件上传
@Test
public void testCopyFromLocalFile() throws IOException, InterruptedException, URISyntaxException {
// 1 获取文件系统
Configuration configuration = new Configuration();
configuration.set("dfs.replication", "2");
FileSystem fs = FileSystem.get(new URI("hdfs://hadoop11:8020"), configuration, "root");
// 2 上传文件
fs.copyFromLocalFile(new Path("d:/wordCount.txt"), new Path("/root/firstDemo"));
// 3 关闭资源
fs.close();
}5.3 HDFS文件下载
@Test
public void testCopyToLocalFile() throws IOException, InterruptedException, URISyntaxException{
// 1 获取文件系统
Configuration configuration = new Configuration();
FileSystem fs = FileSystem.get(new URI("hdfs://hadoop11:8020"), configuration, "root");
// 2 执行下载操作
// boolean delSrc 指是否将原文件删除
// Path src 指要下载的文件路径
// Path dst 指将文件下载到的路径
// boolean useRawLocalFileSystem 是否开启文件校验
fs.copyToLocalFile(false, new Path("/root/firstDemo/wordCount.txt"), new Path("d:/wordCount2.txt"), true);
// 3 关闭资源
fs.close();
}5.4 HDFS文件更名和移动
@Test
public void testRename() throws IOException, InterruptedException, URISyntaxException{
// 1 获取文件系统
Configuration configuration = new Configuration();
FileSystem fs = FileSystem.get(new URI("hdfs://hadoop11:8020"), configuration, "root");
// 2 修改文件名称
fs.rename(new Path("/root/firstDemo/wordCount.txt"), new Path("/root/secondDemo/wordCount.txt"));
// 3 关闭资源
fs.close();
}5.5 HDFS删除文件和目录
@Test
public void testDelete() throws IOException, InterruptedException, URISyntaxException{
// 1 获取文件系统
Configuration configuration = new Configuration();
FileSystem fs = FileSystem.get(new URI("hdfs://hadoop11:8020"), configuration, "root");
// 2 执行删除
fs.delete(new Path("/root/secondDemo/wordCount.txt"), true);
// 3 关闭资源
fs.close();
}5.6 HDFS文件详情查看
@Test
public void testListFiles() throws IOException, InterruptedException, URISyntaxException {
// 1获取文件系统
Configuration configuration = new Configuration();
FileSystem fs = FileSystem.get(new URI("hdfs://hadoop11:8020"), configuration, "root");
// 2 获取文件详情
RemoteIterator<LocatedFileStatus> listFiles = fs.listFiles(new Path("/root"), true);
while (listFiles.hasNext()) {
LocatedFileStatus fileStatus = listFiles.next();
System.out.println("========" + fileStatus.getPath() + "=========");
System.out.println(fileStatus.getPermission());
System.out.println(fileStatus.getOwner());
System.out.println(fileStatus.getGroup());
System.out.println(fileStatus.getLen());
System.out.println(fileStatus.getModificationTime());
System.out.println(fileStatus.getReplication());
System.out.println(fileStatus.getBlockSize());
System.out.println(fileStatus.getPath().getName());
// 获取块信息
BlockLocation[] blockLocations = fileStatus.getBlockLocations();
System.out.println(Arrays.toString(blockLocations));
}
// 3 关闭资源
fs.close();
}4.7 HDFS文件和文件夹判断
@Test
public void testListStatus() throws IOException, InterruptedException, URISyntaxException{
// 1 获取文件配置信息
Configuration configuration = new Configuration();
FileSystem fs = FileSystem.get(new URI("hdfs://hadoop11:8020"), configuration, "root");
// 2 判断是文件还是文件夹
FileStatus[] listStatus = fs.listStatus(new Path("/root"));
for (FileStatus fileStatus : listStatus) {
// 如果是文件
if (fileStatus.isFile()) {
System.out.println("f:"+fileStatus.getPath().getName());
}else {
System.out.println("d:"+fileStatus.getPath().getName());
}
}
// 3 关闭资源
fs.close();
}














 182
182











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









