







hive官方网站:Apache Hive TM
产生背景:
- 方便对文件及数据的元数据进行管理,提供统一的元数据管理方式
- 提供更加简单的方式来访问大规模的数据集,使用SQL语言进行数据分析
Hive产生:为了非java编程者对hdfs的数据进行MapReduce操作
介绍:
Hive是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张数据库表,并提供简单的sq查询功能,可以将sql语句转换为MapReduce任务进行运行。其优点是学习成本低,可以通过类SQL语句快速实现简单的MapReduce统计,不必开发专门的MapReduce应用,十分适合数据仓库的统计分析。
Hive是建立在Hadoop.上的数据仓库基础构架。它提供了一系列的工具,可以用来进行数据提取转化加载(ETL),这是一种可以存储、查询和分析存储在Hadoop中的大规模数据的机制。Hive 定义了简单的类SQL查询语言,称为HQL,它允许熟悉SQL的用户查询数据。
数据仓库和数据库的主要区别:
1、数据库是面向事务的设计,数据仓库是面向主题设计的。
2、数据库一般存储在线交易数据,数据仓库存储的一般是历史数据。
3、数据库设计是尽量避免冗余,数据仓库在设计是有意引入冗余。
4、数据库是为捕获数据而设计,数据仓库是为分析数据而设计
1. 安装
hive安装也是依靠hadoop而创建的版本上也需要符合hadoop的版本
以下为hive的三种安装方式:
- 使用Hive自带的内存数据库Derby作为元数据存储
- 使用远程数据库mysql作为元数据存储
- 使用本地/远程元数据服务模式安装Hive
这里使用第三种方式:b版本为了和hadoop对应这里采用2.3.9
| IP | hive | 备注 |
|---|---|---|
| node4 | server服务端 | 负责和mysql通讯 |
| node5 | slave | |
| mysql节点 |
1. 基础环境配置及安装包部署下载
官方部署安装地址:AdminManual Metastore Administration - Apache Hive - Apache Software Foundation
下载2.3.9的安装包,一定配置hadoop和hive的环境变量,这里没有对hadoop进行配置,就是使用了默认的配置读取了hadoop的环境变量
wget https://downloads.apache.org/hive/hive-2.3.9/apache-hive-2.3.9-bin.tar.gz
#解压hive文件包
tar xvzf apache -hive- 2.3.9-bin.tar.gz
#把解压后的目 录移动到指定目录
mv apache-hive-2.3.9-bin /usr/1ocal/bigdata/apache-hive-2.3.9
# 在node4 和 node5
mkdir -p /home/hadoop/hive/hive_remote/warehouseexport PATH
export HIVE_HOME=/usr/local/bigdata/hive-2.3.9
export HADOOP_HOME=/usr/local/bigdata/hadoop-ha
export PATH=$PATH:$HIVE_HOME/bin:$HADOOP_HOME/bin2. 修改配置文件node4 节点conf下的配置文件
# 拷贝编辑hive-default.xml.template 到 hive-site.xml
# 把光标后面的内容全部情况,只保留最后一行
:.,$-1d
# 文件内容如下
<?xml version="1.0" encoding="UTF-8" standalone="no"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?><!--
Licensed to the Apache Software Foundation (ASF) under one or more
contributor license agreements. See the NOTICE file distributed with
this work for additional information regarding copyright ownership.
The ASF licenses this file to You under the Apache License, Version 2.0
(the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.
-->
<configuration>
<property>
<name>hive.metastore.warehouse.dir</name>
<value>/home/hadoop/hive/hive_remote/warehouse</value>
</property>
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://127.0.0.1:3306/hive_remote?createDatabaseIfNotExist=true</value>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<!-- mysql使用的用户名-->
<value>root</value>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<!-- msyql 密码 -->
<value>password</value>
</property>
</configuration>
还要把mysql数据库连接的jar文件上传到lib目录下:mysql-connector-java-5.1.32.jar
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>5.1.32</version>
</dependency>mysql安装步骤:https://blog.csdn.net/qq_38130094/article/details/103529535?spm=1001.2014.3001.5501
node5:
<configuration>
<property>
<name>hive.metastore.warehouse.dir</name>
<value>/home/hadoop/hive/hive_remote/warehouse</value>
</property>
<property>
<name>hive.metastore.uris</name>
<value>thrift://node04:9083</value>
</property>
</configuration>在node4节点上的bin目录下执行
schematool -dbType mysql -initSchema这时mysql数据库会出现配置的数据库,和对应的数据结构,可以使用对应的用户登录mysql查看数据库来验证
启动hive:
#在node04上执行hive --service metastore,启动hive的元数据服务,是阻塞式窗口
hive --service metastore
# 在node05上执行hive,进入到hive的cli窗口
hive;
#查看默认数据库/ 默认的是default数据库
show databases;
show tables;
desc formatted tableName;

至此hive就可以使用了
二. Hive 高可用方式部署
基于hiveserver2的高可用
| 192.168.3.201 node1 | 192.168.3.202 node2 | 192.168.3.204 node4 | 192.168.3.205 node5 | |
| Namenode | 1 | 1 | ||
| Journalnode | 1 | 1 | 1 | |
| Datanode | 1 | 1 | 1 | |
| Zkfc | 1 | 1 | ||
| zookeeper | 1 | 1 | 1 | |
| resourcemanager | 1 | 1 | 1 | |
| nodemanager | 1 | 1 | 1 | |
| Hiveserver2 | 1 | 1 | ||
| beeline | 1 |
2.1 修改192.168.3.204 上的hive-site.xml文件
这次我么你在node4和node5进行hiveserver2的高可用配置
在配置文件hive-site.xml增加以下内容:
<property>
<name>hive.server2.support.dynamic.service.discovery</name>
<value>true</value>
</property>
<property>
<name>hive.server2.zookeeper.namespace</name>
<value>hiveserver2_zk</value>
</property>
<property>
<name>hive.zookeeper.quorum</name>
<value>node2:2181,node4:2181,node5:2181</value>
</property>
<property>
<name>hive.zookeeper.client.port</name>
<value>2181</value>
</property>
<property>
<name>hive.server2.thrift.bind.host</name>
<value>node2</value>
</property>
<property>
<name>hive.server2.thrift.port</name>
<value>10001</value>
</property>2.1 同时修改192.168.3.205 上的hive-site.xml文件
增加以下内容:
<property>
<name>hive.server2.support.dynamic.service.discovery</name>
<value>true</value>
</property>
<property>
<name>hive.server2.zookeeper.namespace</name>
<value>hiveserver2_zk</value>
</property>
<property>
<name>hive.zookeeper.quorum</name>
<value>node2:2181,node4:2181,node5:2181</value>
</property>
<property>
<name>hive.zookeeper.client.port</name>
<value>2181</value>
</property>
<property>
<name>hive.server2.thrift.bind.host</name>
<value>node5</value>
</property>
<property>
<name>hive.server2.thrift.port</name>
<value>10001</value>
</property>2.3 启动两台hive服务
nohup ./hive --service hiveserver2 >> ./hiveser2.log 2>&1 &

启动两台机器后:

2.4 进行远程连接
beeline
!connect jdbc:hive2://node2,node4,node5/;serviceDiscoveryMode=zooKeeper;zooKeeperNamespace=hiveserver2_zk hadoop 123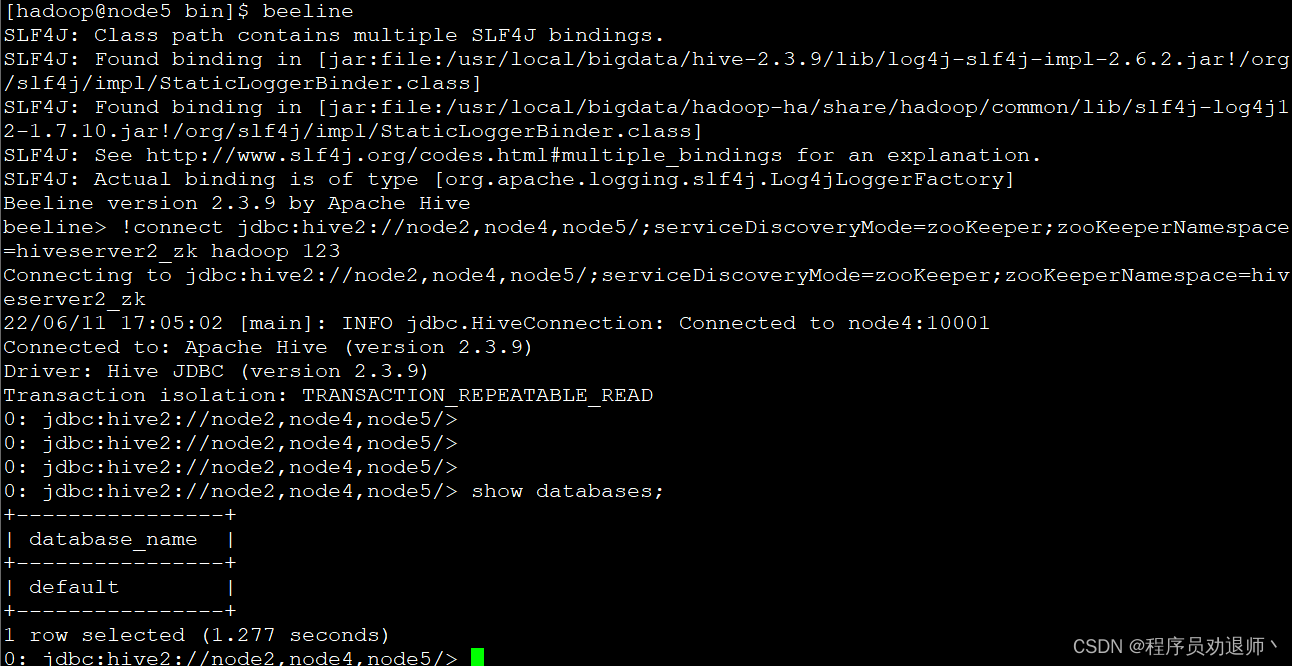
hiveserver2的高可用配置完成
3. hive 架构原理
- 1.用户接口:Client:CLI(command-line interface)、JDBC/ODBC(jdbc访问hive)、WEBUI(浏览器访问hive)
- 2.元数据:Metastore:元数据包括:表名、表所属的数据库(默认是default)、表的拥有者、列/分区字段、表的类型(是否是外部表)、表的数据所在目录等;
- 默认存储在自带的derby数据库中,推荐使用MySQL存储Metastore
- 3.Hadoop:使用HDFS进行存储,使用MapReduce进行计算。
4.驱动器:Driver
(1)解析器(SQL Parser):将SQL字符串转换成抽象语法树AST,这一步一般都用第三方工具库完成,比如antlr;对AST进行语法分析,比如表是否存在、字段是否存在、SQL语义是否有误。
(2)编译器(Physical Plan):将AST编译生成逻辑执行计划。
(3)优化器(Query Optimizer):对逻辑执行计划进行优化。
(4)执行器(Execution):把逻辑执行计划转换成可以运行的物理计划。对于Hive来说,就是MR/Spark。
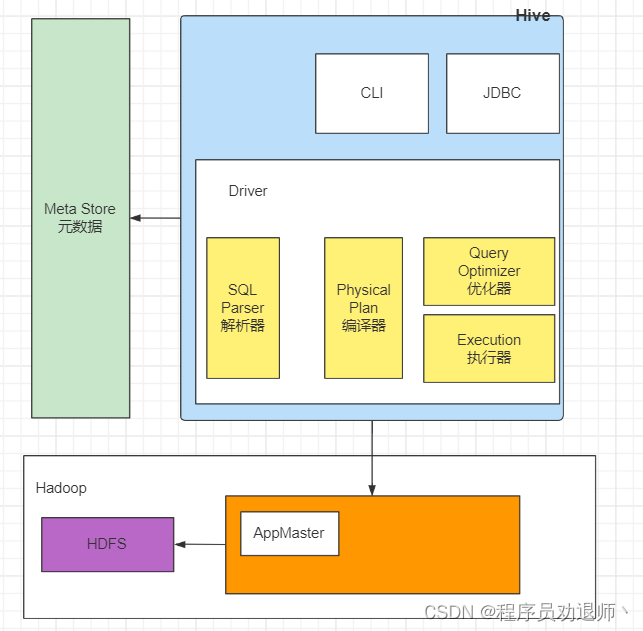
4. Hive运行机制
Hive 就是通过 CLI 、JDBC / ODBC 或者 HWI 接收相关的 Hive SQL 查询,并通过 Driver 组件进行编译,分析优化,最后变成可执行的 MapReduce















 433
433











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









