







前面已介绍这次目标。这次是精读。
-
数据处理思路介绍
-
微调需要输入训练数据的阅读材料以及相关要求。 通过以上两项组成我们的微调input内容。
阅读材料
这里的材料就是我们的语文英语阅读题目,这个在哪里呢?这部分材料分别对应语文和英语的阅读材料部分。因为我们使用官方给的数据,大家打开昨天的notebook能看到在《训练集-语文.xlsx》《训练集-英语.xlsx》两个文件的材料,对应阅读文本数据列。
微调数据target部分
大模型中我们知道是一个有输入送入模型,通过模型运行后给出文本输出这样的工作流程,那么我们期望大模型输出的就是 选择题。 这里的 选择题 不单单指选择题的题干,还要有选项和参考答案,要有一定的格式。
这里摘录除了官方输出样例数据给大家了解。
英文
{ Which of the following is not a type of art form that Nick Smith uses in his pixelated collages? A) Painting B) Photography C) Embroidery D) Video art Answer:C What does the word "Psychology" in the title PSYCOLOURGY: January 2015 refer to in relation to Nick Smith's work? A) The study of human behavior and mental processes B) The concept of using colour to convey emotions and ideas C) The use of pixelated images in his collages D) A specific series of artworks from 2015 Answer:B Which of the following is true about Nick Smith's career as an artist? A) He has only worked in the fine arts category B) His work is primarily focused on interior design C) He has never used hand-made collages in his work D) His first collage experiment was inspired by Marilyn Monroe Answer:D Which of the following can be inferred about the text employed in Nick Smith's work? A) It is always narrative and sequential B) It is often open to interpretation by the viewer C) It is always written in a specific language or script D) It is always placed under each swatch of colour Answer:B }
因为训练数据为官方给定,我们可以打开查阅了解一下题目有没有什么处理问题。阅读材料格式对题目影响不大,我们处理的核心在选项上,那么我们看看选项和答案内容如何。由于语文部分和英语部分不太一样,我们分开来看。
选项
24. What can we learn about John from the first two paragraphs? A. He was fond of traveling. C. He had an inquiring mind. B. He enjoyed being alone. D. He longed to be a doctor. 25. Why did John put the sludge into the tanks? A. To feed the animals. C. To protect the plants. B. To build an ecosystem. D. To test the eco-machine. 26. What is the author's purpose in mentioning Fuzhou? A. To review John's research plans. C. To compare John's different jobs. B. To show an application of John's idea. D. To erase doubts about John's invention. 27. What is the basis for John's work? A. Nature can repair itself. C. Life on Earth is diverse. B. Organisms need water to survive. D. Most tiny creatures live in groups.
答案:
24. C. . He had an inquiring mind. 25. D. To test the eco-machine. 26. B. To show an application of John's idea. 27. A. Nature can repair itself.
处理流程
将语文、英语训练集按照下图结构,选项与答案组成output模块,prompt+阅读文本组成input模块。这样就是我们的处理流程结构啦。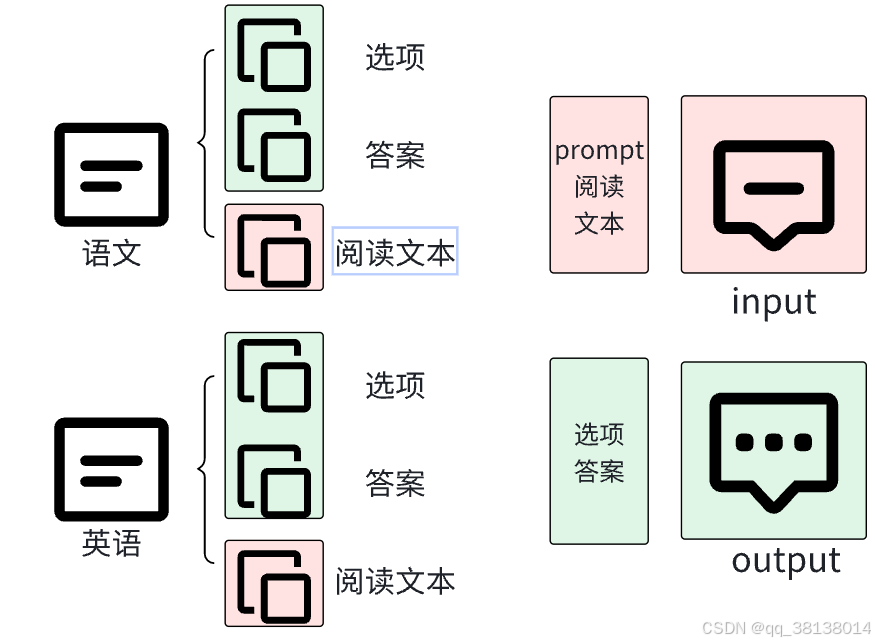
两种 Finetune 范式
-
增量预训练微调 (Continue PreTraining)
使用场景:让基座模型学习到一些新知识,如某个垂类领域的常识
-
训练数据:文章、书籍、代码等
-
指令跟随微调 (Supervised Finetuning)
使用场景:让模型学会对话模板,根据人类指令进行对话
训练数据:高质量的对话、问答数据
为什么要微调?
相对于从头开始训练(Training a model from scatch),微调可以省去大量计算资源和计算时间,提高了计算效率,甚至提高准确率。
普通预训练模型的特点是:用了大型数据集做训练,已经具备了提取浅层基础特征和深层抽象特征的能力。
不做微调:
(1)从头开始训练,需要大量的数据,计算时间和计算资源。
(2)存在模型不收敛,参数不够优化,准确率低,模型泛化能力低,容易过拟合等风险。
使用微调:避免了上述可能存在的问题。
LoRA 的优势
- 可以针对不同的下游任务构建小型 LoRA 模块,从而在共享预训练模型参数基础上有效地切换下游任务。
- LoRA 使用自适应优化器(Adaptive Optimizer),不需要计算梯度或维护大多数参数的优化器状态,训练更有效、硬件门槛更低。
- LoRA 使用简单的线性设计,在部署时将可训练矩阵与冻结权重合并,不存在推理延迟。
- LoRA 与其他方法正交,可以组合。
baseline讲解
抽取问题
这里主要是为了抽取题目及答案,并且过滤简答题。大家可以阅读详细的注释理解问题抽取的函数如何工作。
def chinese_multiple_choice_questions(questions_with_answers):
# 输入的题目文本
text = questions_with_answers
question_pattern = re.compile(r'\d+\..*?(?=\d+\.|$)', re.DOTALL)
# 这一行作用是匹配一个以数字开头、后面跟着一个点字符的字符串,
#。直到遇到下一个数字和点字符或字符串结束。
choice_pattern = re.compile(r'([A-D])\s*(.*?)(?=[A-D]|$|\n)', re.DOTALL)
# 这一行作用是匹配一个以字母[A到D]开头、后面跟着一个点字符的字符串,
#直到遇到下一个[A到D]或字符串结束。
# 找到所有问题
questions = question_pattern.findall(text)
# 初始化选择题和简答题列表
multiple_choice_questions = []
short_answer_questions = []
# 处理每个问题
for id,question in enumerate(questions):
# 这里取到的question,如果是选择题会带着选择题的选项。
# 检查是否是选择题 因为选择题内有ABCD这样的选项
if re.search(r'[A-D]', question):
# 如果有选项,提取出选项的内容
choices = choice_pattern.findall(question)
# 这里提取了题目的内容,因为每个题目都会有一个打分的(X分)这样的标记
# 以左括号为目标,截取选择题选项中的内容
question_text = re.split(r'\n', question.split('(')[0])[0]
pattern_question = re.compile(r'(\d+)\.(.*)')
# 这里清洗了选择题的编号,重新用循环中的id进行编号。
# 如果不做这一步可以发现给定的数据中编号是乱序的。
matches_question = str(id+1)+'.'+ pattern_question.findall(question_text)[0][1] # 取出问题后重排序
# print(str(id+1)+'.'+matches_question)
# 这里我们实现声明好了存储的列表
# 将每个问题和选项以字典的形式存入方便我们处理
multiple_choice_questions.append({
'question': matches_question,
'choices': choices
})
else:
# 大家可以想想这里怎么用?
short_answer_questions.append(question.strip())
# 最后我们返回抽取后的选择题字典列表
return multiple_choice_questionsprompt设计
使用要求+阅读材料组成prompt,作为input部分。
我们看看代码如何实现?
def get_prompt_cn(text):
prompt = f'''
你是⼀个⾼考选择题出题专家,你出的题有⼀定深度,你将根据阅读文本,出4道单项选择题,包含题目选项,以及对应的答案,注意:不⽤给出原文,每道题由1个问题和4个选项组成,仅存在1个正确答案,请严格按照要求执行。 阅读文本主要是中文,你出的题目需要满足以下要点,紧扣文章内容且题干和答案为中文:
### 回答要求
(1)理解文中重要概念的含义
(2)理解文中重要句子的含意
(3)分析论点、论据和论证方法
### 阅读文本
{text}
'''
return prompt 中文数据处理主函数
这段代码将input与output部分进行组合,按照列表序号一一对应~
可以看看注释中的实现细节~
def process_cn(df):
# 定义好返回列表
res_input = []
res_output = []
for id in range(len(df)):
# 逐个遍历每行的选项、答案、阅读文本的内容
data_options = df.loc[id, '选项']
data_answers = df.loc[id,'答案']
data_prompt = df.loc[id,'阅读文本']
# 处理选项部分,抽取出选择题题目及选项
data_options = chinese_multiple_choice_questions(data_options)
# 处理答案部分,抽取出选择题答案
data_answers = chinese_multiple_choice_answers(data_answers)
# 抽取阅读材料组合成input内容
data_prompt = get_prompt_cn(data_prompt)
# print(data_options)
# print(data_answers)
# 做数据验证,因为训练数据格式不能确定每组数据都能被正常处理(会有一部分处理失败)
# 我们验证一下两个列表的长度 如果相同代表数据处理正确
if(len(data_answers)==len(data_options)):
# 定义output的数据字符串
res = ''
# 处理选择题目中的每个数据,逐个拼入到output字符串
for id_,question in enumerate(data_options):
# 首先放入题目
res += f'''
{question['question']}?
'''+'\n'
# 然后找到选择题的每个选项,进行choices列表循环
for choise in question['choices']:
# 逐个将选项拼接到字符串
res = res+ choise[0] + choise[1]+ '\n'
# 最后将答案拼接到每个选择题的最后
# 以 答案:题号.选项的格式
res = res + '答案:' + str(data_answers[id_].split('.')[-1]) + '\n'
# 最后将处理得到的input、output数据存入到列表
res_output.append(res)
res_input.append(data_prompt)
# break
return res_input,res_output
英文问题数据相对标准,但是也有不少小问题。比如ABCD的顺序可能是ACBD。我们看看这些如何解决。
import re
# 示例文本
text = second_row_option_content
def get_questions(text):
# 数据清洗,将所有换行改为两个空格方便统一处理
text = text.replace('\n', ' ')+' '
# print(text)
# 正则表达式模式
# 通过匹配以数字开头然后带一个点,为题干
# 然后抽取选项A 以A开头 后面带一个点 最后以两个空格结尾
# 为什么是两个空格?部分数据换行时为换行符,我们已经换成了两个空格,有些是以多个空格分割,我们默认为两个空格
# 接着匹配B C D选项内容
# 最后有一个
pattern = re.compile(r'(\d+\..*?)(A\..*?\s{2})([B-D]\..*?\s{2})([B-D]\..*?\s{2})(D\..*?\s{2})', re.DOTALL)
# 查找所有匹配项
matches = pattern.findall(text)
# 存储结果的字典列表
questions_dict_list = []
# 打印结果
for match in matches:
question, option1, option2, option3, option4 = match
pattern_question = re.compile(r'(\d+)\.(.*)')
# 第一个为选择题的题目 提前存到question_text
question_text = pattern_question.findall(question.strip())[0][1]
# 提取选项字母和内容
options = {option1[0]: option1, option2[0]: option2, option3[0]: option3, option4[0]: option4}
question_dict = {
'question': question_text,
# 这一步就是防止ACBD这种乱序,我们进行重新匹配,将可能是ACBD的数据以首字母按位置排好号
'options': {
'A': options.get('A', '').strip(),
'B': options.get('B', '').strip(),
'C': options.get('C', '').strip(),
'D': options.get('D', '').strip()
}
}
questions_dict_list.append(question_dict)
# 最后获得
return questions_dict_list
# 调用函数并打印结果
questions = get_questions(text)
for q in questions:
print(q)抽取结果
# 首先做数据清洗,将空格、换行符及点都删除
def remove_whitespace_and_newlines(input_string):
# 使用str.replace()方法删除空格和换行符
result = input_string.replace(" ", "").replace("\n", "").replace(".", "")
return resultprompt设计
def get_prompt_en(text):
prompt = f'''
你是⼀个⾼考选择题出题专家,你出的题有⼀定深度,你将根据阅读文本,出4道单项选择题,包含题目选项,以及对应的答案,注意:不⽤给出原文,每道题由1个问题和4个选项组成,仅存在1个正确答案,请严格按照要求执行。
The reading text is mainly in English. The questions and answers you raised need to be completed in English for at least the following points:
### 回答要求
(1)Understanding the main idea of the main idea.
(2)Understand the specific information in the text.
(3)infering the meaning of words and phrases from the context
### 阅读文本
{text}
'''
return prompt 数据合并
因为微调需要150条数据,数据处理后得到有效数据为102,从中文抽取30条,英文抽取20条组成152条数据作为微调数据。
# 将两个列表转换为DataFrame df_new = pd.DataFrame({'input': cn_input+cn_input[:30]+en_input+en_input[:20], 'output': cn_output+cn_output[:30]+en_output+en_output[:20]})
最后,感谢datawhale。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









