







本次读书笔记在于实现书上的从文本解析数据,使用Matplotlib创建散点图(散点图使用DataMat矩阵的第二、第三列数据),分类器针对约会网站的测试等
首先介绍几个相关知识点,方便代码浏览。
知识点一:
1.对于高维数组,索引位置上的元素不再是标量而是低一维的数组,比如:
[python] view plain copy
1. arr2d = np.array([[1,2,3],[4,5,6],[7,8,9]])
[python] view plain copy
1. arr2d[2]
输出:
array([7, 8, 9])
2.再看几个二维数组的索引例子,用刚才创建的那个arr2d数组,注意索引位置包括开头但不包括结尾,比如[0:2]是索引1、2位置,但没有3。
[python] view plain copy
1. arr2d
输出:
array([[1, 2, 3],
[4, 5, 6],
[7, 8, 9]])
[python] view plain copy
1. arr2d[:2]
输出:
array([[1, 2, 3],
[4, 5, 6]])
注意没有第三个元素,也就是arr2d[2]
[python] view plain copy
1. arr2d[:2,1:]
输出:
array([[2, 3],
[5, 6]])
[python] view plain copy
1. arr2d[1,:2]
输出:
array([4, 5]
[python] view plain copy
1. arr2d[2,:1]
输出:
array([7])
[python] view plain copy
1. arr2d[:,:1]
输出:
array([[1],
[4],
[7]])
[python] view plain copy
1. arr2d[:2,1:] = 0
2. arr2d
输出:
array([[1, 0, 0],
[4, 0, 0],
[7, 8, 9]])
知识点二:
下述关于Matplotlib的代码,得在安装Python之外安装matplotlib、numpy、scipy、six等库
import matplotlib.pyplot as plt
from numpy import *
fig = plt.figure()
ax = fig.add_subplot(258)
ax.plot(x,y)
plt.show()
参数258的意思是:将画布分割成2行5列,图像画在从左到右从上到下的第8块
那第十块怎么办,2510是不行的,可以用另一种方式(2,5,10)。
如果一块画布中要显示多个图怎么处理?
import matplotlib.pyplot as plt
from numpy import *
fig = plt.figure()
ax = fig.add_subplot(2,1,1)
ax.plot(x,y)
ax = fig.add_subplot(2,2,3)
ax.plot(x,y)
plt.show()
下面贴上代码,代码都有注释,很容易理解
from numpy import *
import knn1
def file2matrix(filename):
"""该函数将约会文件内容转换成数据处理格式,返回一个测试特征集(格式二维数组),和测试集类别集(格式列表)
"""
fr = open(filename)
arrayOnLines = fr.readlines()
numberOfLines = len(arrayOnLines) #获取 n=样本的行数
returnMat = zeros((numberOfLines, 3)) #创建一个2维矩阵用于存放训练样本数据,一共有n行,每一行存放3个数据
classLabel = [] #创建一个1维数组用于存放训练样本标签。
for i in range(numberOfLines):
line = arrayOnLines[i]
line = line.strip() # 把回车符号给去掉
listFromLine = line.split('\t') # 把每一行数据用\t分割
returnMat[i, :] = listFromLine[0:3] # 把分割好的数据放至数据集,其中i是该样本数据的下标,就是放到第几行
classLabel.append(int(listFromLine[-1])) # 把该样本对应的标签放至标签集,顺序与样本集对应。
return returnMat, classLabel
def autoNorm(dataSet):
"""该函数将数据集的所以特征归一化,返回归一化后的特征集(格式为数组),特征集最小值(格式为一维数组),特征集范围(格式为一维数组)
Keyword argument:
dataSet -- 特征数据集
"""
# 获取数据集中每一列的最小数值
# 以createDataSet()中的数据为例,group.min(0)=[0,0]
minVals = dataSet.min(axis=0)
# 获取数据集中每一列的最大数值
# group.max(0)=[1, 1.1]
maxVals = dataSet.max(axis=0)
# 最大值与最小的差值
ranges = maxVals - minVals
# 创建一个与dataSet同shape的全0矩阵,用于存放归一化后的数据
normDataSet = zeros(shape(dataSet))
dataSize = dataSet.shape[0]
# 把最小值扩充为与dataSet同shape,然后作差,具体tile请翻看 第三节 代码中的tile
normDataSet = dataSet - tile(minVals, (dataSize, 1))
# 把最大最小差值扩充为dataSet同shape,然后作商,是指对应元素进行除法运算,而不是矩阵除法。
# 矩阵除法在numpy中要用linalg.solve(A,B)
normDataSet = normDataSet / tile(ranges, (dataSize, 1))
return normDataSet, minVals, ranges
def dateClassTest(filename, k):
"""测试KNN算法对于约会数据的错误率
Keyword argument:
None
"""
# 将数据集中10%的数据留作测试用,其余的90%用于训练
ratio = 0.10
dataSet, labels = file2matrix(filename)
normDateSet, minVals, ranges = autoNorm(dataSet)
dataSize = dataSet.shape[0]
numTestVecs = int(dataSize * ratio)
errorcount = 0.0
print("m : %d" % dataSize)
for i in range(numTestVecs):
classifyResult = knn1.classify0(normDateSet[i, :], normDateSet[numTestVecs:dataSize, :], \
labels[numTestVecs:dataSize], k)
if classifyResult != labels[i]:
errorcount += 1
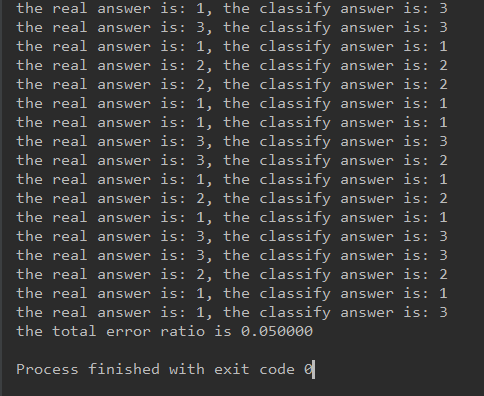
print("the real answer is: %d, the classify answer is: %d" % (labels[i], classifyResult))
print("the total error ratio is %f" % (errorcount / float(numTestVecs)))
if __name__ == '__main__':
filename = '/Users/Administrator/Desktop/machine learning inaction/Ch02/datingTestSet2.txt'
dateClassTest(filename, 3)
datingDataMat, datingLables = file2matrix(filename)
import matplotlib
import matplotlib.pyplot as plt
fig = plt.figure() #建立画板
'''
add_subplot(mnp)添加子轴、图。subplot(m,n,p)或者subplot(mnp)此函数最常用:
subplot是将多个图画到一个平面上的工具。其中,m表示是图排成m行,n表示图排成n列,
也就是整个figure中有n个图是排成一行的,一共m行,如果第一个数字是2就是表示2行图。
p是指你现在要把曲线画到figure中哪个图上,最后一个如果是1表示是从左到右第一个位置。 '''
ax = fig.add_subplot(111)
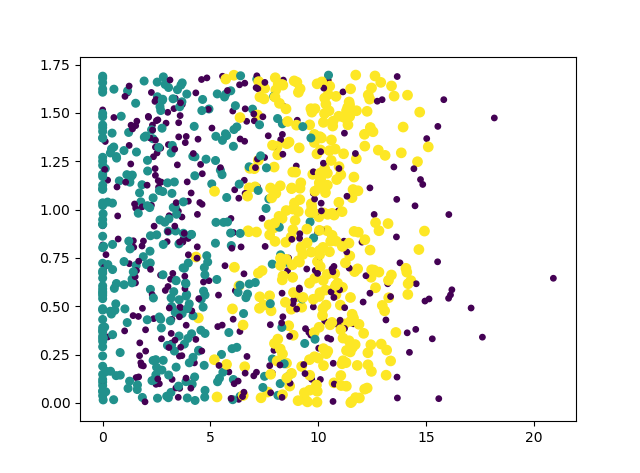
#以第二列和第三列为x,y轴画出散列点,给予不同的颜色和大小
# scatter(x,y,s=1,c="g",marker="s",linewidths=0)
# s:散列点的大小,c:散列点的颜色,marker:形状,linewidths:边框宽度
ax.scatter(datingDataMat[:, 1], datingDataMat[:, 2],
15.0 * array(datingLables), 15.0 * array(datingLables))
plt.show() #显示PS: 前面的import knn1 是import前一篇博文的knn1代码
跑出的Matplotlib散点图(散点图使用DataMat矩阵的第二、第三列数据)如下:
得出的程序结果如下(截取部分结果):















 779
779

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









