







本次读书笔记在于延续上一篇博客的工程,做出微小的改动,即使用Matplotlib创建散点图(散点图使用DataMat矩阵的第一、第二列数据)。
首先还是介绍一个相关知识点,方便代码浏览。
知识点一:
1、在使用Matplotlib生成图表时,默认不支持汉字,所有汉字都会显示成框框。
解决方法:代码中指定中文字体
# -*- coding:utf-8 -*-
importmatplotlib.pyplot as plt
import matplotlib
zhfont1 =matplotlib.font_manager.FontProperties(fname='C:/Windows/Fonts/simsun.ttc')
plt.xlabel(u"横坐标xlabel",fontproperties=zhfont1)
到C:\Windows\Fonts\中找到新宋体对应的字体文件simsun.ttf(Window 8和Windows10系统是simsun.ttc,也可以使用其他字体)
下面贴出代码:
from numpy import *
import knn1
def file2matrix(filename):
"""该函数将约会文件内容转换成数据处理格式,返回一个测试特征集(格式二维数组),和测试集类别集(格式列表)
"""
fr = open(filename)
arrayOnLines = fr.readlines()
numberOfLines = len(arrayOnLines) #获取 n=样本的行数
returnMat = zeros((numberOfLines, 3)) #创建一个2维矩阵用于存放训练样本数据,一共有n行,每一行存放3个数据
classLabel = [] #创建一个1维数组用于存放训练样本标签。
for i in range(numberOfLines):
line = arrayOnLines[i]
line = line.strip() # 把回车符号给去掉
listFromLine = line.split('\t') # 把每一行数据用\t分割
returnMat[i, :] = listFromLine[0:3] # 把分割好的数据放至数据集,其中i是该样本数据的下标,就是放到第几行
classLabel.append(int(listFromLine[-1])) # 把该样本对应的标签放至标签集,顺序与样本集对应。
return returnMat, classLabel
def autoNorm(dataSet):
"""
该函数将数据集的所以特征归一化,返回归一化后的特征集(格式为数组),特征集最小值(格式为一维数组),特征集范围(格式为一维数组)
"""
# 获取数据集中每一列的最小数值
# 以createDataSet()中的数据为例,group.min(0)=[0,0]
minVals = dataSet.min(axis=0)
# 获取数据集中每一列的最大数值
# group.max(0)=[1, 1.1]
maxVals = dataSet.max(axis=0)
# 最大值与最小的差值
ranges = maxVals - minVals
# 创建一个与dataSet同shape的全0矩阵,用于存放归一化后的数据
normDataSet = zeros(shape(dataSet))
dataSize = dataSet.shape[0]
# 把最小值扩充为与dataSet同shape,然后作差,具体tile请翻看 第三节 代码中的tile
normDataSet = dataSet - tile(minVals, (dataSize, 1))
# 把最大最小差值扩充为dataSet同shape,然后作商,是指对应元素进行除法运算,而不是矩阵除法。
# 矩阵除法在numpy中要用linalg.solve(A,B)
normDataSet = normDataSet / tile(ranges, (dataSize, 1))
return normDataSet, minVals, ranges
def dateClassTest(filename, k):
"""
测试KNN算法对于约会数据的错误率
"""
# 将数据集中10%的数据留作测试用,其余的90%用于训练
ratio = 0.10
dataSet, labels = file2matrix(filename)
normDateSet, minVals, ranges = autoNorm(dataSet)
dataSize = dataSet.shape[0]
numTestVecs = int(dataSize * ratio)
errorcount = 0.0
print("m : %d" % dataSize)
for i in range(numTestVecs):
#分别对应前面的 classify(int X, dataSet, labels, k)
#normDateSet[i, :]对应数据中随机的1000*0.1=100行的数据,normDateSet[numTestVecs:dataSize, :]对应剩下的900行数据
classifyResult = knn1.classify0(normDateSet[i, :], normDateSet[numTestVecs:dataSize, :], \
labels[numTestVecs:dataSize], k)
if classifyResult != labels[i]:
errorcount += 1
print("the real answer is: %d, the classify answer is: %d" % (labels[i], classifyResult))
print("the total error ratio is %f" % (errorcount / float(numTestVecs)))
if __name__ == '__main__':
filename = '/Users/Administrator/Desktop/machine learning inaction/Ch02/datingTestSet2.txt'
dateClassTest(filename, 3)
datingDataMat, datingLabels = file2matrix(filename)
import matplotlib
import matplotlib.pyplot as plt
from matplotlib.font_manager import FontProperties
zhfont = FontProperties(fname='C:/Windows/Fonts/simsun.ttc', size=12)
# 建立画板
fig = plt.figure()
# 画图之前首先设置figure对象,此函数相当于设置一块自定义大小的画布,使得后面的图形输出在这块规定了大小的画布上,
# 其中参数figsize设置画布大小
plt.figure(figsize=(8, 5), dpi=80)
# 例子:plt.subplot(221)将figure设置的画布大小分成几个部分,参数‘221’表示2(row)x2(colu),即将画布分成2x2,两行两列的4块区域,
# 1表示选择图形输出的区域在第一块,图形输出区域参数必须在“行x列”范围,此处必须在1和2之间选择
# 如果参数设置为subplot(111),则表示画布整个输出,不分割成小块区域,图形直接输出在整块画布上
ax = plt.subplot(111)
datingLabels = array(datingLabels)
idx_1 = where(datingLabels == 1)
p1 = ax.scatter(datingDataMat[idx_1, 0], datingDataMat[idx_1, 1], marker='*', color='r', label='1', s=10)
idx_2 = where(datingLabels == 2)
p2 = ax.scatter(datingDataMat[idx_2, 0], datingDataMat[idx_2, 1], marker='o', color='g', label='2', s=20)
idx_3 = where(datingLabels == 3)
p3 = ax.scatter(datingDataMat[idx_3, 0], datingDataMat[idx_3, 1], marker='+', color='b', label='3', s=30)
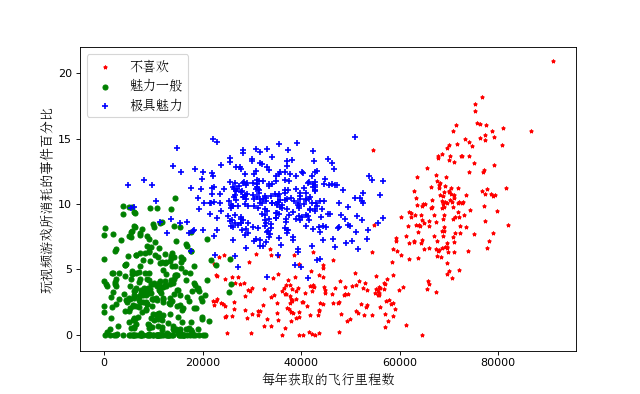
plt.xlabel(u'每年获取的飞行里程数', fontproperties=zhfont)
plt.ylabel(u'玩视频游戏所消耗的事件百分比', fontproperties=zhfont)
#loc(设置图例显示的位置),'upper left' : 2
ax.legend((p1, p2, p3), (u'不喜欢', u'魅力一般', u'极具魅力'), loc=2, prop=zhfont)
plt.show() #显示然后贴出结果图:















 548
548











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









