







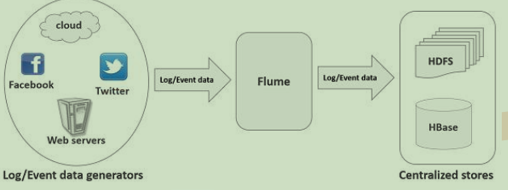
flume功能
flume做简单的数据过滤处理,收集日志,转发到HDFS、HBASE进行存储 or 连接kafka(消息队列、临时存储)连接到streaming进行线上处理
注:一般开发情况下只需要做streaming、storm,flume、kafka已经做好,不需要管
flume=agent+数据收集器
flume中agent功能:根据不同的host进行数据的处理:
【app来源】host1->处理1
【pc来源】host2->处理2
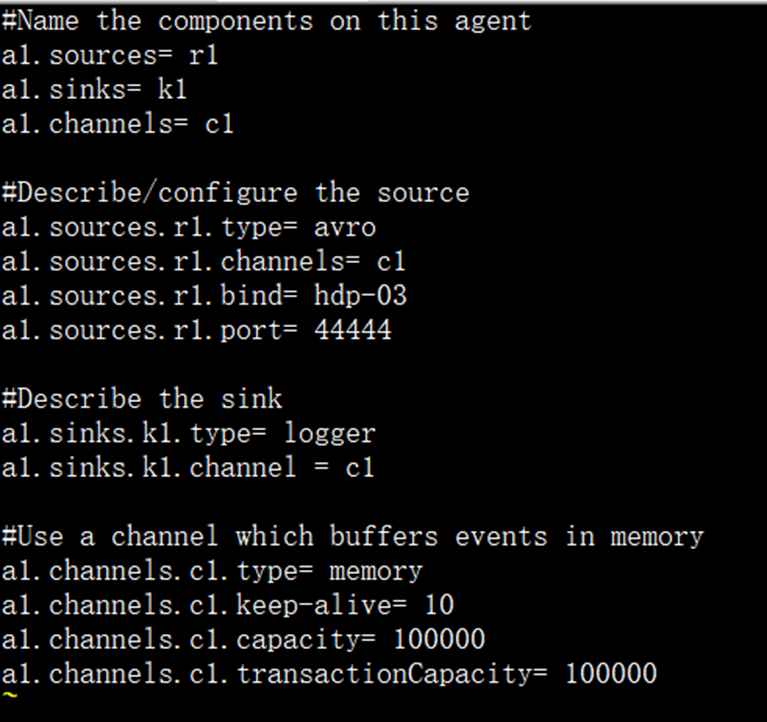
flume开发,主要是编写conf文件,每个conf都有自己的功能
flume—agent编写模板
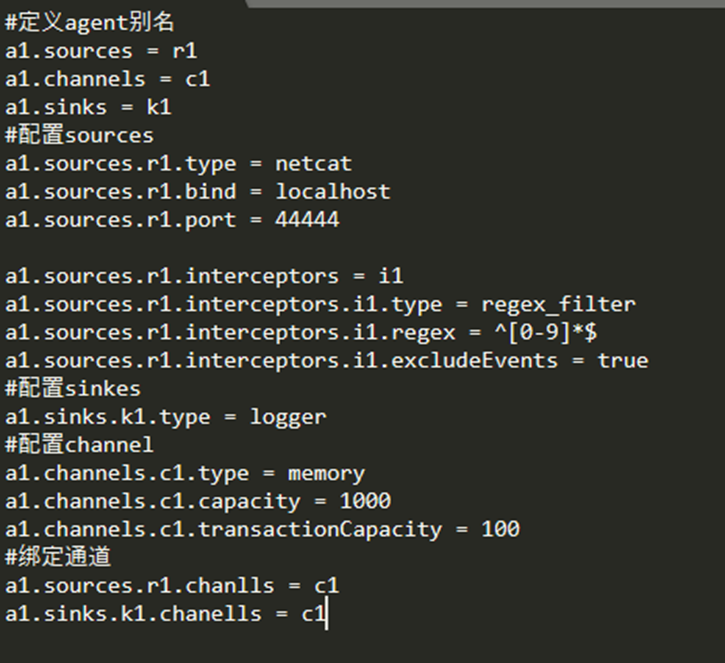
Agent channel:
FileChannel:把数据写到磁盘,性能相对差一些,能把数据持久化保证数据不会丢失(WAL实现)【开发常使用】
WAL:write ahead logging 预写:先写执行操作,再写数据,当数据写失败,再执行一遍操作
**Memory Channel:**把数据写到内存,只要agent出问题,数据就会丢失
Agent 拦截器
flume可以预先对数据做简单的处理
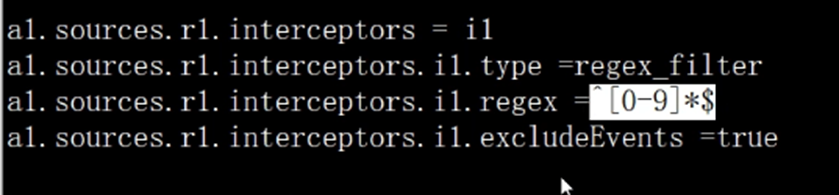
Re::数字的都给过滤 filter和spark里面相反逻辑
^表示开始,$表示结尾
spark filter为true的保留下来
flume中的:filter为true的过滤掉
agent之间的通信:Avro
Avro:是一个数据序列化系统,支持大批量数据交换应用
从一个agent1到agent2中a1的sink->a2的source
两个Agent连接案列
Push文件
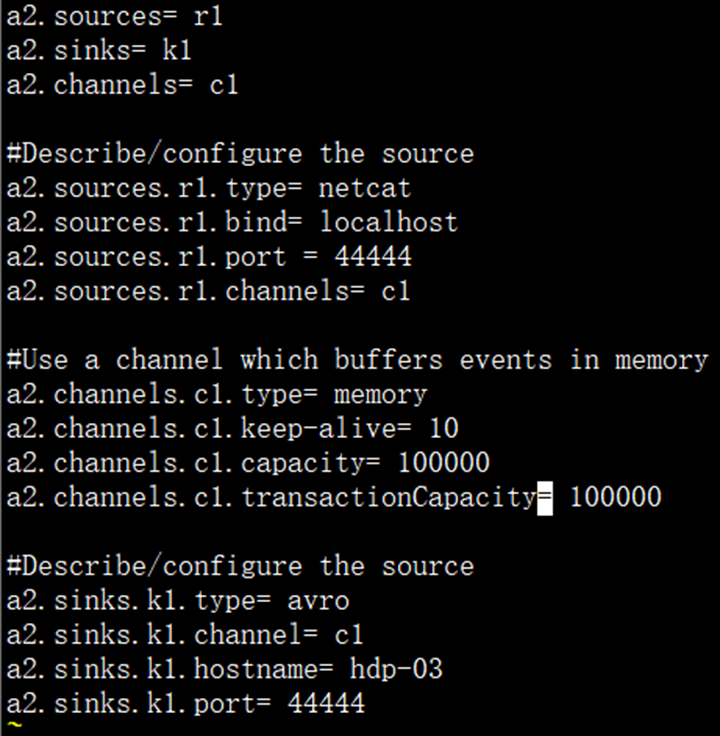
Pull 文件
flume agent a2[push.conf] -> flume2 agent a1 [pull.conf]
执行步骤:先slave3后master
slave3:
bin/flume-ng agent -c conf -f conf/pull.conf -n a1 -Dflume.root.logger=INFO,console
master:
bin/flume-ng agent -c conf -f conf/push.conf -n a2 -Dflume.root.logger=INFO,console
有没有连接成功:
slave3上面:log:
[id: 0xba35b724, /192.168.174.134:53348 => /192.168.174.135:44444] CONNECTED: /192.168.174.134:53348
在Telnet localhost 44444 看打印出来的东西
案列:数据写到HDFS
官网示列:http://flume.apache.org/FlumeUserGuide.html#hdfs-sink
a1.channels = c1
a1.sinks = k1
a1.sinks.k1.type = hdfs
a1.sinks.k1.channel = c1
a1.sinks.k1.hdfs.path = hdfs:/flume/events
a1.sinks.k1.hdfs.filePrefix = events-
a1.sinks.k1.hdfs.round = true
a1.sinks.k1.hdfs.roundValue = 10
a1.sinks.k1.hdfs.roundUnit = minute
a1.sinks.k1.hdfs.fileType = DataStream
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
hdfs写明文的方式设置:
a1.sinks.k1.hdfs.fileType = DataStream
案列:
将数据写到Kafka:由于kafka内存较大不能启动,修改kafka-server-start.sh文件,将启动内存改为10M
创建kafka topic
bin/kafka-topics.sh --create --zookeeper master:2181,slave3:2181,slave4:2181 --replication-factor 1 --partitions 2 --topic test(topic名称)
消费:
Bin/kafka-console-consumer.sh --zookeeper master:2181,slave3:2181,slave4:2181 --topic test
【注:zookeeper后面加一个host:port和加多个hosts是一样的,但是,如果有节加的这个节点zookeeper进程挂了,就影响连接了,kafka访问zookeeper会出问题】
1.启动kafka需要启动zookeeper cd zookeeper Home
1》启动zookeeper [./bin/zkServer.sh start]三个节点分别启动
2》启动server 通过./bin/zkCli.sh -server master:2181,slave3:2181,slave4:2181
<=> ./bin/zkCli.sh -server master:2181
<=> ./bin/zkCli.sh
2.启动kafka:到kafka home
./bin/kafka-server-start.sh config/server.properties
3.如果没有topic,创建topic,kafka把数据写到相应的topic之中
查看topic list:
bin/kafka-topics.sh --list --zookeeper master:2181,slave3:2181,slave4:2181
没有topic为badou,创建:
bin/kafka-topics.sh --create --zookeeper master:2181,slave3:2181,slave4:2181 --replication-factor 1 --partitions 2 –topic badou
4.启动flume: [flume_kafka.conf文件已经有]
bin/flume-ng agent -c conf -f conf/flume_kafka.conf -n a1 -Dflume.root.logger=INFO,console**(使用的文件已经编译好)**
5.“写”数据到flume中 :
因为flume_kafka.conf中的source以
a1.sources.r1.type = exec
a1.sources.r1.command = tail -f /home/badou/Documents/code/python/flume_exec_test.txt
flume监控这个路径下的文件,只要有数据追加到这个文件中,这些数据就会被监控,通过这个source写入flume中
需要用到【read_write.py】将一个文件中的数据写入到监控的文件中flume_exec_test.txt,这样写入的数据就是写到kafka中的数据,整个过程模拟写logs日志的过程。
【对应的代码,只需要修改里面的路径就可以】















 813
813











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









