






这里因为是本地环境就没有使用二进制源码包进行部署
1 环境安装
1.1 主机要求
实际生产中,适当提高硬件配置
| 主机名 | 操作系统 | CPU | MEM | 角色要求 |
| master1 | centos7.6 | 2 | 2 | master |
| work1 | centos7.6 | 2 | 2 | worker |
| work2 | centos7.6 | 2 | 2 | worker |
1.1.1 主机准备
所有主机均要配置
准备主机操作系统
| 主机操作系统 | 硬件配置 | 硬盘分区 | IP |
| CentOS7u6最小化 | 2C 2G 100G | /boot、/ | 192.168.89.138 |
| CentOS7u6最小化 | 2C 2G 100G | /boot、/ | 192.168.89.139 |
| CentOS7u6最小化 | 2C 2G 100G | /boot、/ | 192.168.89.140 |
1.1.2 主机名
[root@xxx ~]# hostnamect1 set-hostname xxxx主机名列表:
192.168.89.138 master1
192.168.89.139 worker1
192.168.89.140 worker2设置主机名示例:
hostnamect1 set-hostname master11.1.3 主机IP地址
IP地址根据自己主机实际情况进行配置
本次使用VMWare Workstation Pro虚拟机部署,需要注意网关设置。
[root@xXX ~]# vi /etc/sysconfig/network-scripts/ifcfg-ens33
[root@xXX ~]# cat /etc/sysconfig/network-scripts/ifcfg-ens33
DEVICE=eth0
TYPE=Ethernet
ONB00T=yes
BOOTPROTO=static
IPADDR=192.168.89.138
NETMASK=255.255.255.0
GATEWAY=192.168.0.1
DNS1=119.29.29.29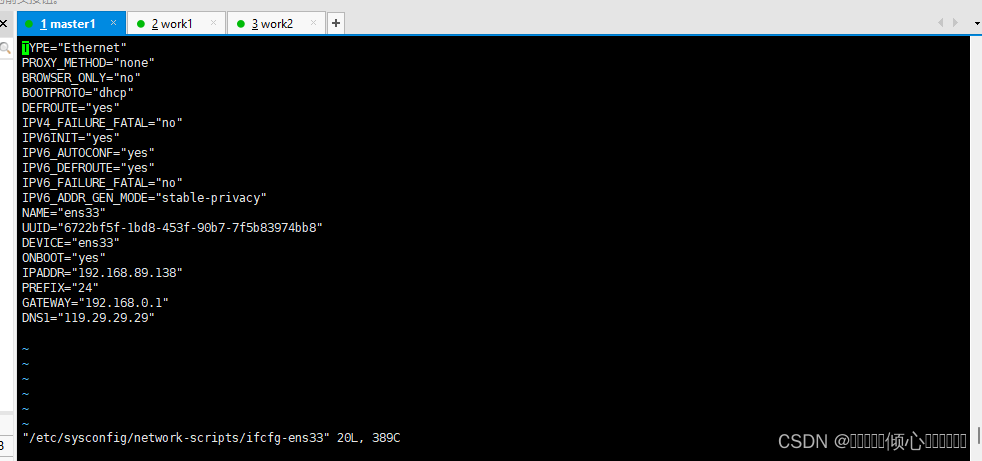
保存后重启网络
systemctl restart network
# ip验证
ip a s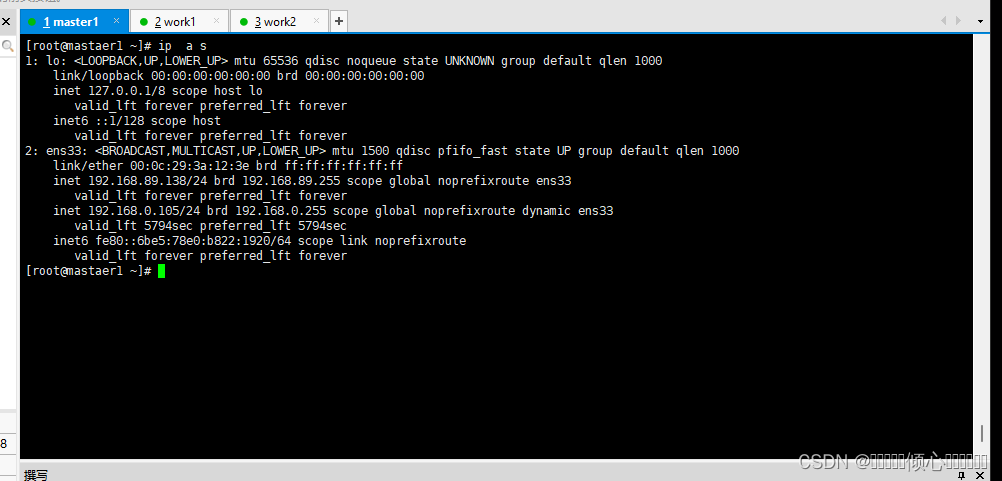
1.1.4 主机名解析
[root@xxX ~]# cat /etc/hosts
127.0.0.1 ocalhost localhost.localdomain ocalhost41ocaThost4.1ocaldomain4
::1]ocaThost localhost.localdomain ocaThost67ocaThost6.1ocaldomain6
192.168.89.138 master1
192.168.89.139 work1
192.168.89.140 work2主机名测试示例
ping worker1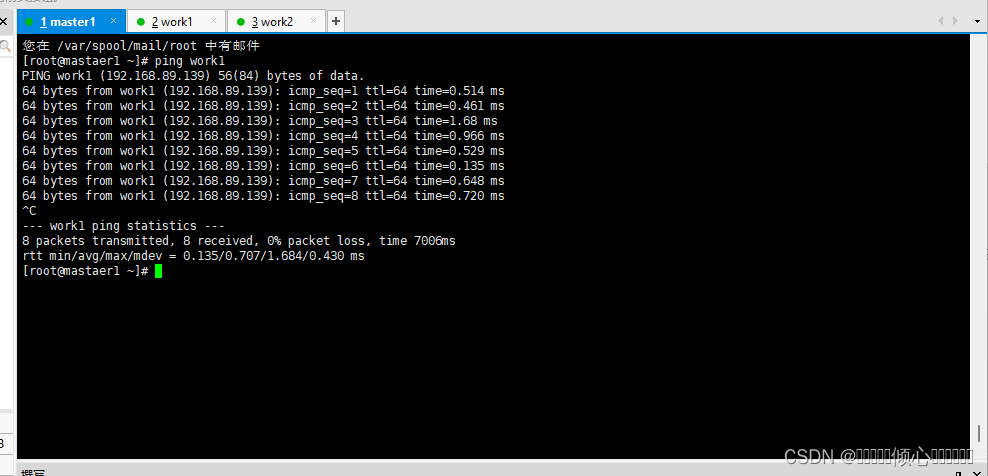
1.2 主机安全配置
1.2.1 关闭firewalld
[root@xxx ~]# systemct1 stop firewa11d
[root@xxx ~]# systemct1 disable firewa11d
#确认是否运行
[root@xxX ~]# firewa11-cmd --state5
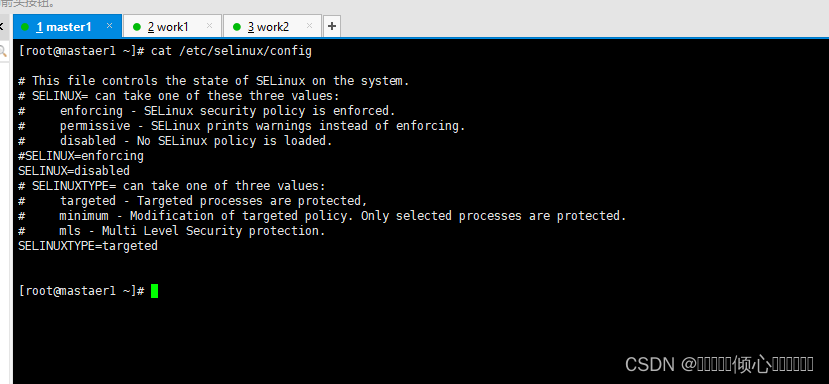
not running1.2.2 SELINUX配置
做出下述修改,一定要重启系统才能生效。
修改之前验证是否开启的
#验证是否开启 开启状态会返回Enforcing 关闭则返回Disabled
[root@xXX ~]# getenforce
Enforcing 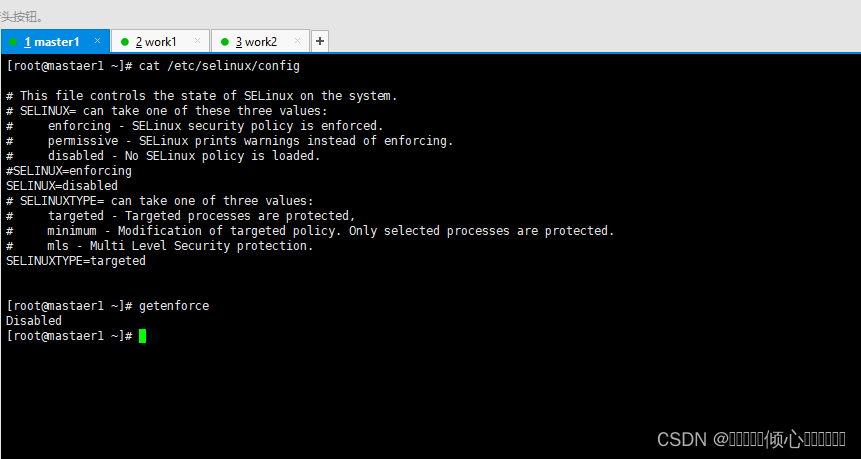
[root@xXX ~]# sed -ri's/SELINUX=enforcing/SELINUX=disabled//etc/selinux/config或者vi打开配置文件/etc/selinux/config进行手动修改
#重启主机
reboot1.3 主机时间同步
由于最小化安装系统,需要单独安装 ntpdate
[root@xxX ~]# yum -y insta11 ntpdate安装完成开启定时同步时间 这里设置的1小时
#编辑定时任务
crontab -e
#定时规则
0 */1 * * * ntpdate time1.aliyun.com
#查看规则
crontab -l
#手动同步时间
ntpdate time1.aliyun.com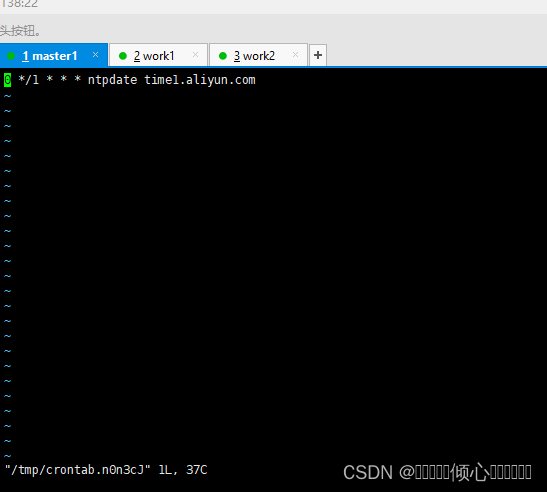
1.4 永久关闭swap分区
使用kubeadm部署必须关闭swap分区,修改配置文件后需要重启操作系统。
修改 /etc/fstab文件,注释 /dev/mapper/centos-swap swap
#查看
cat /etc/fstab
#修改
vi /etc/fstab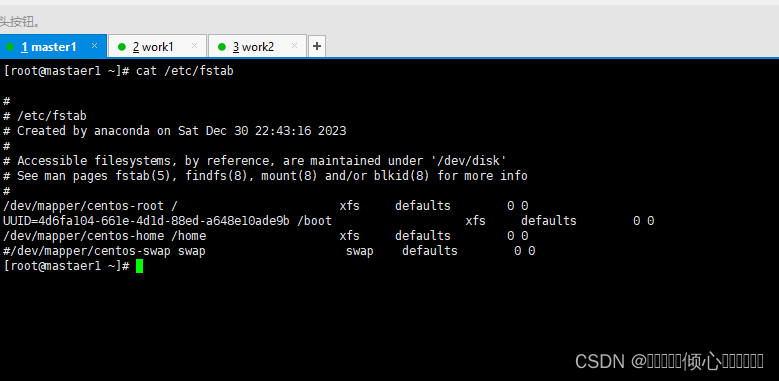
#重启后验证swap分区否关闭,关闭 则为0
free -m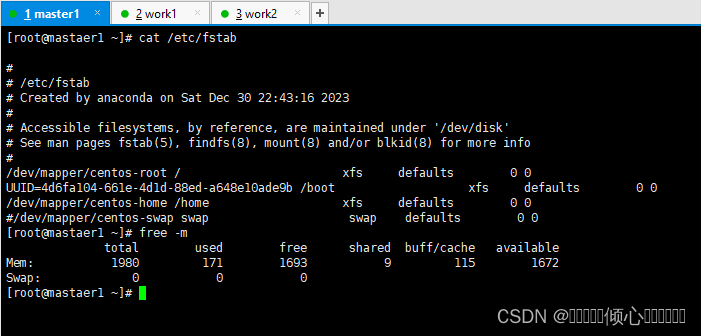
1.5 添加网桥过滤
新增k8s配置文件内容路径如下
添加网桥过滤及地址转发
[root@xxx ~]# cat etc/sysct1.d/k8s.conf
net.bridge.bridge-nf-cal1-ip6tables = 1
net.bridge.bridge-nf-ca11-iptables = 1
net.ipv4.ip_forward = 1
vm.swappiness = 0
加载br_netfilter模块
[root@xxx ~]# modprobe br_netfilter
查看是否加载
[root@xxx ~]# lsmod | grep br_netfilter
br_netfilter 22256 0
bridge 151336 1 br_netfilter
加载网桥过滤配置文件
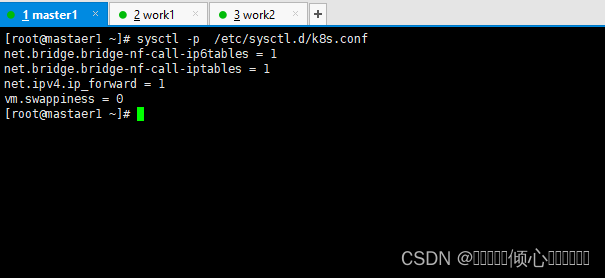
[root@xxX ~]# sysct1 -p /etc/sysct1.d/k8s.conf
net.bridge.bridge-nf-ca11-ip6tables = 1
net.bridge.bridge-nf-ca11-iptables =1
net.ipv4.ip_forward = 1
vm.swappiness = 0
1.6 开启ipvs
1.6.1 安装ipset及ipvsadm
[root@xxx ~]# yum -y insta11 ipset ipvsadm1.6.2 在所有节点执行如下脚本
#添加需要加载的模块
cat > /etc/sysconfig/modules/ipvs.modules <<EOF
#!/bin/bash
modprobe -- ip_vs
modprobe -- ip_vs_rr
modprobe -- ip_vs_wrr
modprobe -- ip_vs_sh
modprobe -- nf_conntrack ipv4
EOF#授权、运行、检查是否加载
[root@xxx ~]# chmod 755 /etc/sysconfig/modules/ipvs.modules
[root@xxx ~]# sh /etc/sysconfig/modules/ipvs.modules
[root@xxx ~]# lsmod | grep -e ip_vs -e nf_conntrack_ipv4
#检查是否加载
[root@xxx ~]# lsmod | grep -e ip_vs -e nf_conntrack_ipv42 docker 安装
2.1 在manager节点及woker节点 安装指定版本的docker-ce
2.1.1 YUM源 获取
建议使用清华镜像源,官方提供的镜像源由于网络速度原因下载较慢
wget -o /etc/yum.repos.d/docker-ce.repo https://mirrors.tuna.tsinghua.edu.cn/docker-ce/linux/centos/docker-ce.repo2.1.2 查看docker-ce的版本
对版本排序
yum list docker-ce.x86_64 --showduplicates |sort -r2.1.3 安装指定 版本docker-ce
此版本不需要 修改服务启动文件及iptables默认规则链策略
yum -y install --setopt=obsoletes=0 docker-ce-18.06.3.ce-3.el7#查看docker版本
docker version
#设置docker开机自启动
systemctl enable docker
#启动docker
systemctl start docker2.1.4 如果使用 其他docker版本需要修改docker-ce 服务配置文件
修改 其目的是为了后续使用/etc/docker/daemon.json来进行更多配置
#修改内容如下
[root@xxx ~]# cat /usr/lib/systemd/system/docker.service
[Unit]
...
[Service]
...
ExecStart=/usr/bin/dockerd
#如果原文件此行后面有-H选项,请删除-H(含)后面所有内容
...
[Install]
...
#注意有些版本不需要修改,请注意观察修改完毕后再/etc/docker/daemon.json添加一下内容
#在/etc/docker/daemon.json添加如下内容:
[root@locaThost -]# cat /etc/docker/daemon.json
{
"exec-opts": ["native.cgroupdriver=systemd"]
} 3 部署软件及集群软件准备
3.1 软件 安装
所有k8s集群节点均需安装,morenYUM源是谷歌 ,可以使用阿里云YUM
| 需 求 | kebeadm | kubelet | kubectl | docker-ce |
| 值 | 初始化集群、 管理集群等, 版本为: 1.17.2 | 用于接收api-server指 令,对pod生命周期进行 管理,版本为: 1.17.2 | 集群命令行 管理工具, 版本为: 1.17.2 | 18.06.3 |
·谷歌YUM源
[kubernetes]
name=Kubernetes
baseurl=https://packages.cloud.google.com/yum/repos/kubernetes-e17-x86_64
enabled=1
gpgcheck=1
repo_gpgcheck=1
gpgkey=https://packages.cloud.google.com/yum/doc/yum-key.gpg
https://packages.cToud.google.com/yum/doc/rpm-package-key.gpg·阿里云YUM源
[kubernetes]
name=Kubernetes
baseurl=https://mirrors.aliyun.com/kubernetes/yum/repos/kubernetes-el7-x86_64/
enabled=1
gpgcheck=1
repo_gpgcheck=1
gpgkey=https://mirrors.aliyun.com/kubernetes/yum/doc/yum-key.gpg
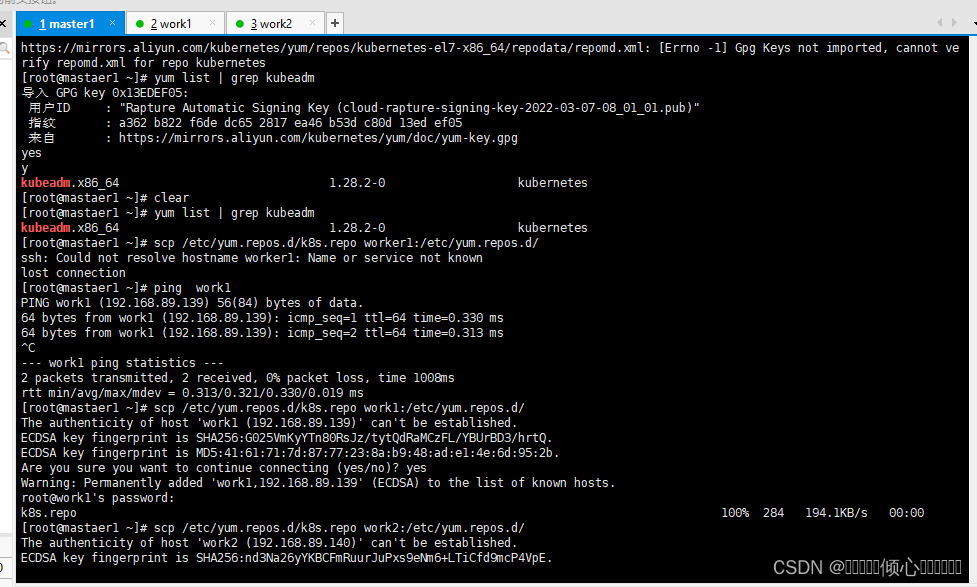
https://mirrors.aliyun.com/kubernetes/yum/doc/rpm-package-key.gpg#验证YUM源是否可用,复制完成每个节点都需要验证一下
yum list | grep kubeadm
#YUM源节点复制
scp /etc/yum.repos.d/k8s.repo work1:/etc/yum.repos.d/
scp /etc/yum.repos.d/k8s.repo work2:/etc/yum.repos.d/
·安装指定版本kubeadm kubelet kubectl
[root@xxx ~]# yum list kubeadm.x86_64 --showduplicates | sort -r
[root@xxx -]# yum -y install --setopt=obsoletes=0 kubeadm-1.17.2-0 kubelet-1.17.2-0 kubect1-1.17.2-04 软件设置
主要配置kubelet,如果不配置可能会导致k8s集群无法启动
#为了实现docker使用的cgroupdriver与kubelet使用的cgroup的一致性,建议修改如下文件内容。
[root@xxx ~]# vim /etc/sysconfig/kubelet
KUBELET_EXTRA_ARGS="--cgroup-driver=systemd"
#设置为开机自启动即可,由于没有生成配置文件,集群初始化后自动启动
[root@xxX ~]# systemctl enable kubelet
#检查kubelet状态
systemctl status kubelet
#设置自动启动
systemctl enable kubelet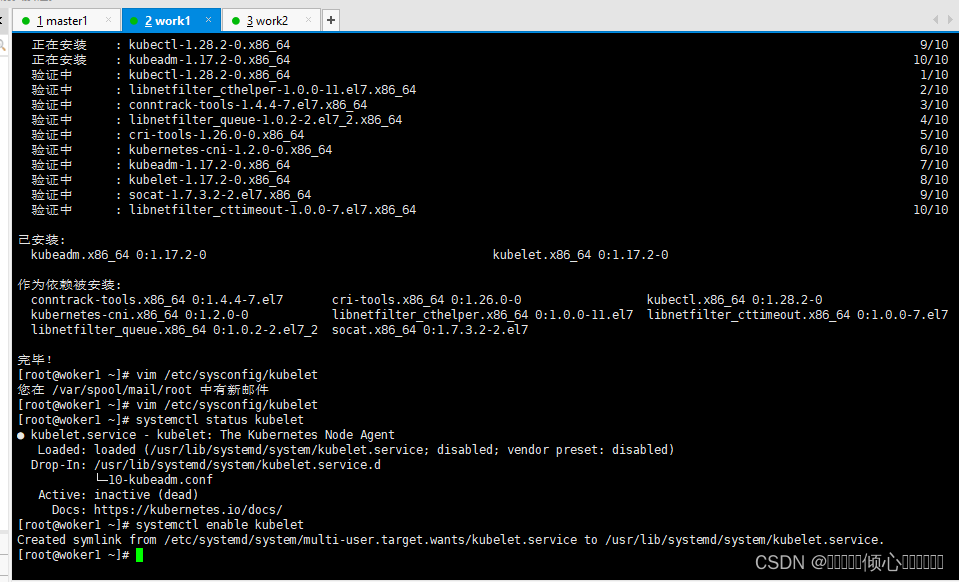
5 k8s集群容器镜像准备
由于使用kubeadm部署集群,集群所有核心组件均以Pod运行,需要为主机准备镜像 ,不同角色主机准备不同镜像,建议使用科学上网方式下载镜像
5.1 Master主机镜像
#查看集群使用的容器镜像
[root@xxxx ~]# kubeadm config images list
k8s.gcr.io/kube-apiserver:v1.17.2
k8s.gcr.io/kube-controller-manager:v1.17.2
k8s.gcr.io/kube-scheduler:v1.17.2
k8s.gcr.io/kube-proxy:v1.17.2
k8s.gcr.io/pause:3.1
k8s.gcr.io/etcd:3.4.3-0
k8s.gcr.io/coredns:1.6.5
#列出镜像列表到文件,便于下载使用
[root@xxxx ~]# kubeadm config images list >> image.list
#查看已列出镜像文件列表
[root@xxxx ~]# cat image.list
修改 image list文件编写为脚本循环下载
[root@xxxx ~]# vim image.list
#脚本内容
#!/bin/bash
img_list='
k8s.gcr.io/kube-apiserver:v1.17.2
k8s.gcr.io/kube-controller-manager:v1.17.2
k8s.gcr.io/kube-scheduler:v1.17.2
k8s.gcr.io/kube-proxy:v1.17.2
k8s.gcr.io/pause:3.1
k8s.gcr.io/etcd:3.4.3-0
k8s.gcr.io/coredns:1.6.5'
for img in ${img_list}
do
docker pull $img
done
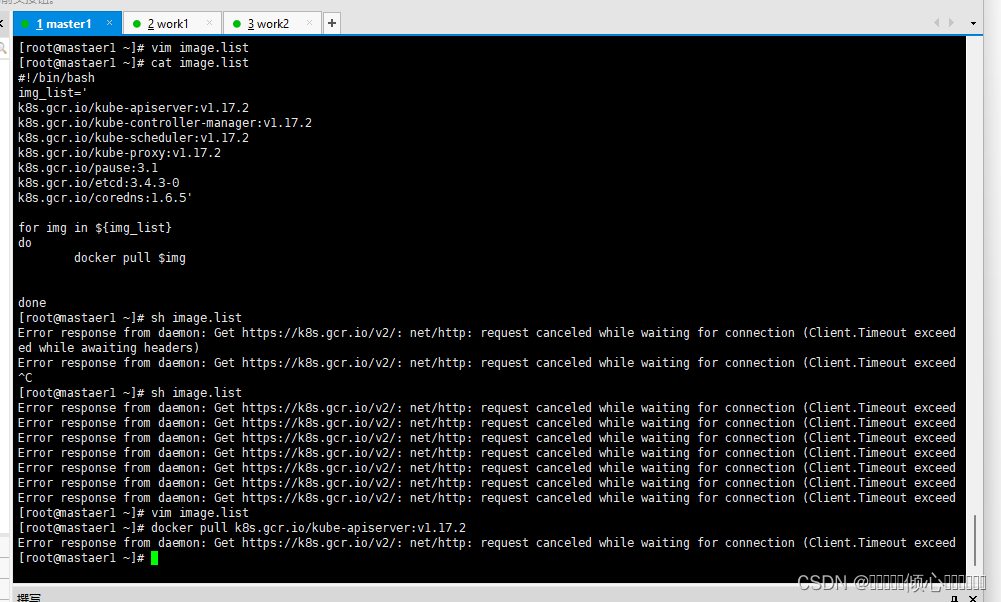
#执行镜像下载脚本
[root@xxxx ~]# sh image.list
#查看已下载镜像
[root@xxxx ~]# docker images
如果无法连接谷歌外网那么可以修改为阿里云的容器镜像加速和下载地址
#!/bin/bash
img_list='
registry.aliyuncs.com/google_containers/kube-apiserver:v1.17.2
registry.aliyuncs.com/google_containers/kube-controller-manager:v1.17.2
registry.aliyuncs.com/google_containers/kube-scheduler:v1.17.2
registry.aliyuncs.com/google_containers/kube-proxy:v1.17.2
registry.aliyuncs.com/google_containers/pause:3.1
registry.aliyuncs.com/google_containers/etcd:3.4.3-0
registry.aliyuncs.com/google_containers/coredns:1.6.5'
for img in ${img_list}
do
docker pull $img
done
5.2 Work主机镜像
#保存镜像为tar
[root@master1 ~]# docker save -o kube-proxy.tar
k8s.gcr.io/kube-proxy:v1.17.2
[rootamaster1 ~l#dodker save o pause.tar
k8s.gcr.io/pause:3.1
[root@master1 ~]#1s
kube-proxy.tar pause.tar
#复制tar到worker节点
[root@master1 ~]# scp kube-proxy.tar pause.tar workl:/root
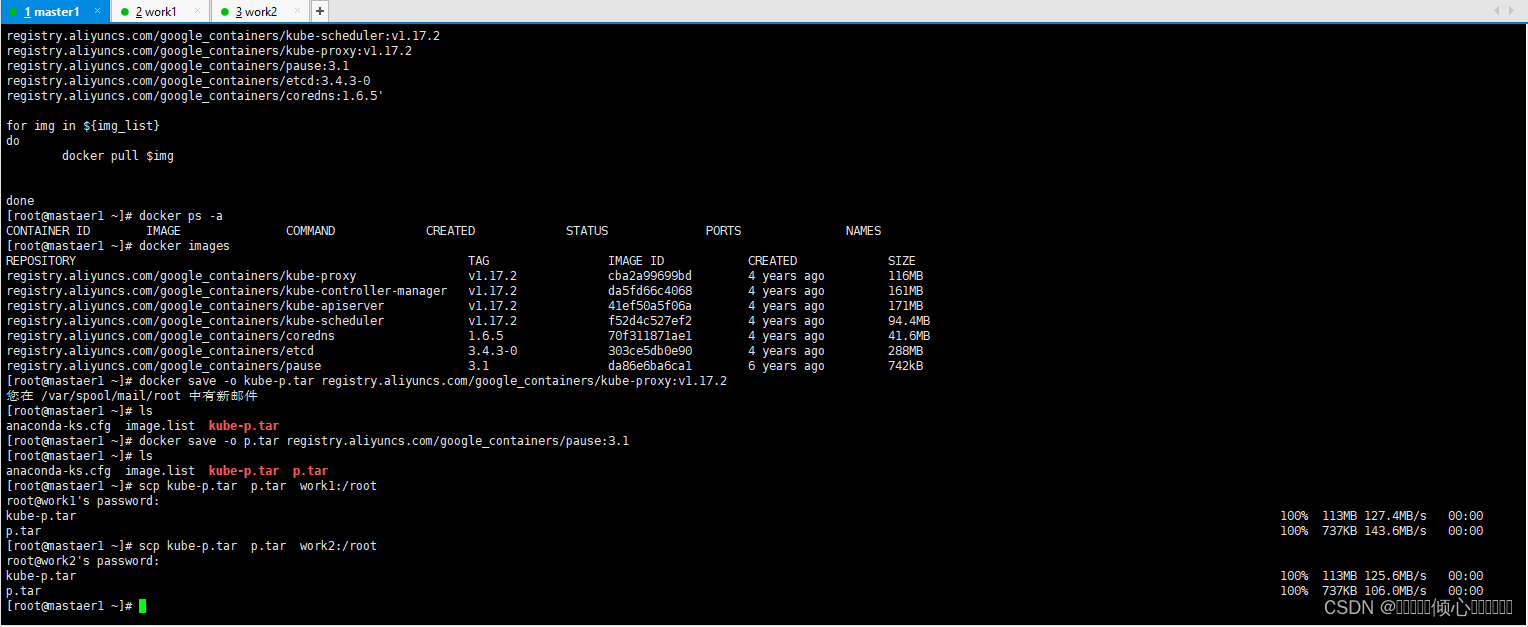
#work节点加载镜像包
docker load -i kube-p.tar
docker load -i p.tar
6 集群初始化
6.1 在master节点操作
#apiserver-advertise-address为当前主机ip
# pod-network-cidr 查看docker网络地址段 根据地址段设置
[rootamaster1 ~]# kubeadm init -kubernetes-version=v1.17.2
--image-repository registry.aliyuncs.com/google_containers
--pod-network-cidr=172.16.0.0/16
--apiserver-advertise-address=192.168.89.138
如果出现报错
The HTTP call equal to 'curl -sSL http://localhost:10248/healthz' failed with error: Get http://localhost:10248/healthz: dial tcp [::1]:10248: connect: connection refused
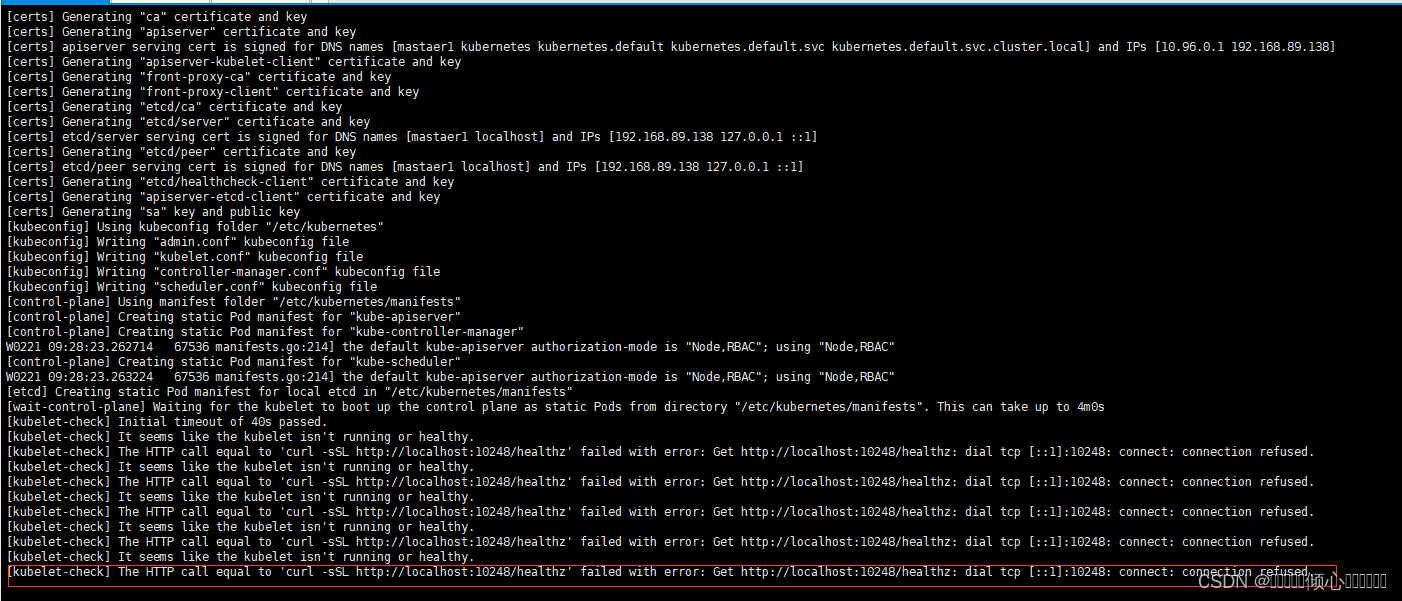
docker的cgroup驱动程序默认设置为system。默认情况下Kubernetes cgroup为systemd,我们需要更改Docker cgroup驱动
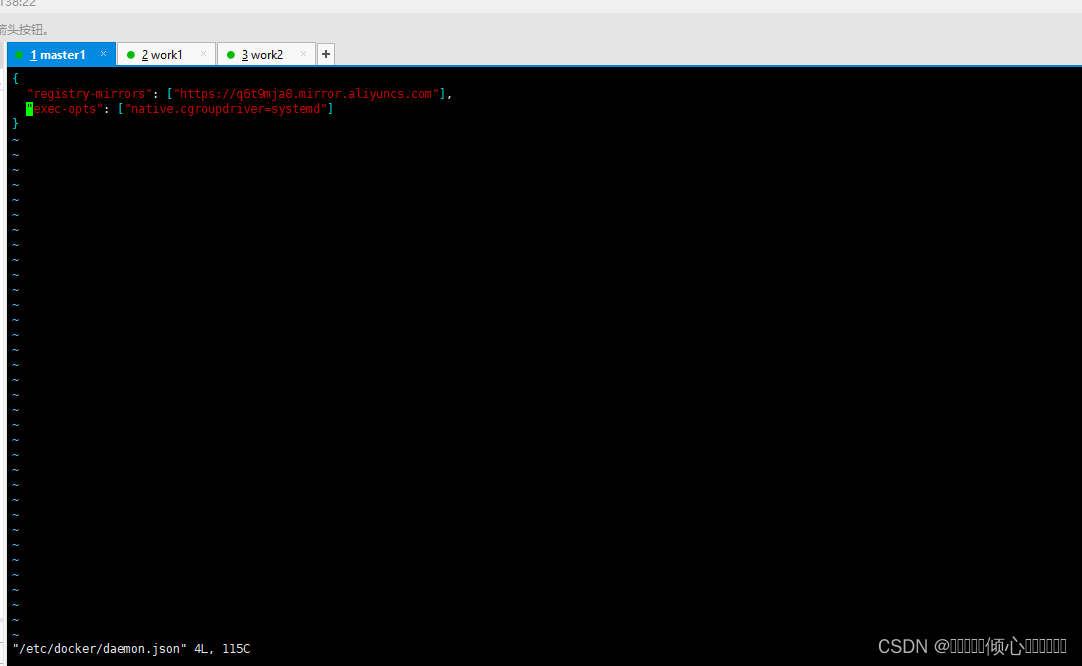
vim /etc/docker/daemon.json
{
"exec-opts": ["native.cgroupdriver=systemd"]
}
# 重启docker
systemctl restart docker
# 重新初始化
kubeadm reset # 先重置
#执行以下命令配置
mkdir .kube
cp -i /etc/kubernetes/admin.conf .kube/config下载网络镜像
docker pull calico/cni:v3.9.0
docker pull calico/node:v3.9.0
docker pull calico/kube-controllers:v3.9.0
docker pull calico/pod2daemon-flexvol:v3.9.0
#下载配置文件
wget https://docs.projectcalico.org/v3.9/manifests/calico.yaml --no-check-certificate
修改配置文件的第607行和608
查看网卡名称 ip a s 我这里网卡名称是ens33 后面就让它自动匹配就可以了
607 - name: IPAUTODETECTION_METHOD
608 value: "interface=ens.*"修改622行IP地址池为初始化地址池
value: "172.16.0.0/16"
指定网络配置文件
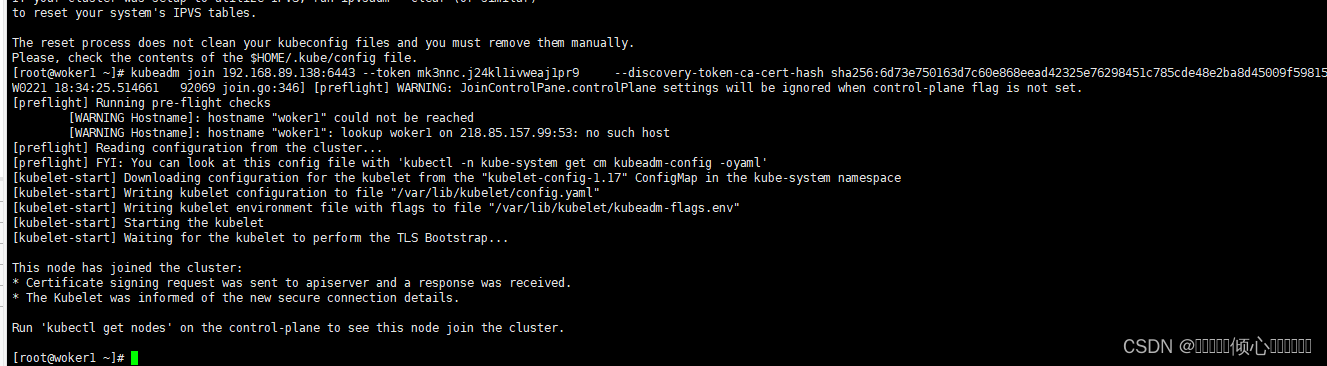
kubectl apply -f calico.yaml在work1 和work2执行节点加入命令是master主节点初始化成功的时候复制下来的
kubeadm join 192.168.89.138:6443 --token mk3nnc.j24kl1ivweaj1pr9 \
--discovery-token-ca-cert-hash sha256:6d73e750163d7c60e868eead42325e76298451c785cde48e2ba8d45009f59815 [init] Using Kubernetes version: v1.17.2
[preflight] Running pre-flight checks
[WARNING Hostname]: hostname "mastaer1" could not be reached
[WARNING Hostname]: hostname "mastaer1": lookup mastaer1 on 218.85.157.99:53: no such host
[preflight] Pulling images required for setting up a Kubernetes cluster
[preflight] This might take a minute or two, depending on the speed of your internet connection
[preflight] You can also perform this action in beforehand using 'kubeadm config images pull'
[kubelet-start] Writing kubelet environment file with flags to file "/var/lib/kubelet/kubeadm-flags.env"
[kubelet-start] Writing kubelet configuration to file "/var/lib/kubelet/config.yaml"
[kubelet-start] Starting the kubelet
[certs] Using certificateDir folder "/etc/kubernetes/pki"
[certs] Generating "ca" certificate and key
[certs] Generating "apiserver" certificate and key
[certs] apiserver serving cert is signed for DNS names [mastaer1 kubernetes kubernetes.default kubernetes.default.svc kubernetes.default.svc.cluster.local] and IPs [10.96.0.1 192.168.89.138]
[certs] Generating "apiserver-kubelet-client" certificate and key
[certs] Generating "front-proxy-ca" certificate and key
[certs] Generating "front-proxy-client" certificate and key
[certs] Generating "etcd/ca" certificate and key
[certs] Generating "etcd/server" certificate and key
[certs] etcd/server serving cert is signed for DNS names [mastaer1 localhost] and IPs [192.168.89.138 127.0.0.1 ::1]
[certs] Generating "etcd/peer" certificate and key
[certs] etcd/peer serving cert is signed for DNS names [mastaer1 localhost] and IPs [192.168.89.138 127.0.0.1 ::1]
[certs] Generating "etcd/healthcheck-client" certificate and key
[certs] Generating "apiserver-etcd-client" certificate and key
[certs] Generating "sa" key and public key
[kubeconfig] Using kubeconfig folder "/etc/kubernetes"
[kubeconfig] Writing "admin.conf" kubeconfig file
[kubeconfig] Writing "kubelet.conf" kubeconfig file
[kubeconfig] Writing "controller-manager.conf" kubeconfig file
[kubeconfig] Writing "scheduler.conf" kubeconfig file
[control-plane] Using manifest folder "/etc/kubernetes/manifests"
[control-plane] Creating static Pod manifest for "kube-apiserver"
[control-plane] Creating static Pod manifest for "kube-controller-manager"
W0221 09:36:45.974038 69578 manifests.go:214] the default kube-apiserver authorization-mode is "Node,RBAC"; using "Node,RBAC"
[control-plane] Creating static Pod manifest for "kube-scheduler"
W0221 09:36:45.976577 69578 manifests.go:214] the default kube-apiserver authorization-mode is "Node,RBAC"; using "Node,RBAC"
[etcd] Creating static Pod manifest for local etcd in "/etc/kubernetes/manifests"
[wait-control-plane] Waiting for the kubelet to boot up the control plane as static Pods from directory "/etc/kubernetes/manifests". This can take up to 4m0s
[apiclient] All control plane components are healthy after 35.502195 seconds
[upload-config] Storing the configuration used in ConfigMap "kubeadm-config" in the "kube-system" Namespace
[kubelet] Creating a ConfigMap "kubelet-config-1.17" in namespace kube-system with the configuration for the kubelets in the cluster
[upload-certs] Skipping phase. Please see --upload-certs
[mark-control-plane] Marking the node mastaer1 as control-plane by adding the label "node-role.kubernetes.io/master=''"
[mark-control-plane] Marking the node mastaer1 as control-plane by adding the taints [node-role.kubernetes.io/master:NoSchedule]
[bootstrap-token] Using token: mk3nnc.j24kl1ivweaj1pr9
[bootstrap-token] Configuring bootstrap tokens, cluster-info ConfigMap, RBAC Roles
[bootstrap-token] configured RBAC rules to allow Node Bootstrap tokens to post CSRs in order for nodes to get long term certificate credentials
[bootstrap-token] configured RBAC rules to allow the csrapprover controller automatically approve CSRs from a Node Bootstrap Token
[bootstrap-token] configured RBAC rules to allow certificate rotation for all node client certificates in the cluster
[bootstrap-token] Creating the "cluster-info" ConfigMap in the "kube-public" namespace
[kubelet-finalize] Updating "/etc/kubernetes/kubelet.conf" to point to a rotatable kubelet client certificate and key
[addons] Applied essential addon: CoreDNS
[addons] Applied essential addon: kube-proxy
Your Kubernetes control-plane has initialized successfully!
To start using your cluster, you need to run the following as a regular user:
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
You should now deploy a pod network to the cluster.
Run "kubectl apply -f [podnetwork].yaml" with one of the options listed at:
https://kubernetes.io/docs/concepts/cluster-administration/addons/
Then you can join any number of worker nodes by running the following on each as root:
kubeadm join 192.168.89.138:6443 --token mk3nnc.j24kl1ivweaj1pr9 \
--discovery-token-ca-cert-hash sha256:6d73e750163d7c60e868eead42325e76298451c785cde48e2ba8d45009f59815 如果token过期可以在主节点重新生成
kubeadm token create --print-join-command
如果子节点报错
[kubelet-check] The HTTP call equal to 'curl -sSL http://localhost:10248/healthz' failed with error: Get "http://localhost:10248/healthz": dial tcp 127.0.0.1:10248: connect: connection refused.
[kubelet-check] It seems like the kubelet isn't running or healthy.
可以按照如下命令执行
首先清理kubeadm join执行后的残余
kubeadm reset
rm -rf /etc/cni/net.d
rm -rf $HOME/.kube/config
rm -rf /etc/kubernetes/
修改配置
echo "export KUBECONFIG=/etc/kubernetes/admin.conf" >> /etc/profile
source /etc/profile
echo '{"exec-opts": ["native.cgroupdriver=systemd"]}' | sudo tee /etc/docker/daemon.json
重启docker kubelet
systemctl daemon-reload
systemctl restart docker
systemctl restart kubelet
sudo kubeadm reset
重新加入
kubeadm join 192.168.89.138:6443 --token mk3nnc.j24kl1ivweaj1pr9 \
--discovery-token-ca-cert-hash sha256:6d73e750163d7c60e868eead42325e76298451c785cde48e2ba8d45009f59815 成功截图
在master节点检测节点是否加入成功
kubectl get nodes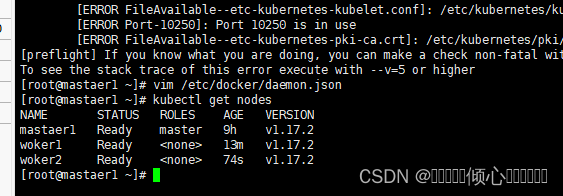
6.2 验证k8s集群可用性方法
#查看节点状态
kubectl get nodes
#查看集群健康状态
kubectl get cs
#或者使用
kubectl cluster-info
#检查组件是否运行
kubectl get pods --namespace kube-system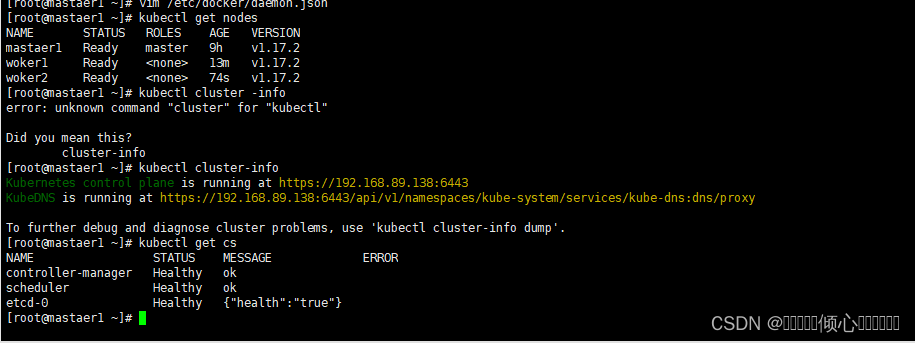
7 k8s集群客户端工具kubectl
7.1kubectl帮助方法
检查kubect1是否安装
[rootamaster1 ~]# rpm -qa |grep kubectl
获取kubect1帮助方法
[root@master1 ~]# kubectl --help7.2kubectl子命令使用分类
| 基 础 命 令 | 命令 | 描述 |
| create | 通过文件名或标准输入创建资源 | |
| expose | 将一个资源公开为一个新的Service | |
| run | 在集群中运行一个特定的镜像 | |
| set | 在对象上设置特定的功能 | |
| get | 显示一个或多个资源 | |
| explain | 文档参考资料 | |
| edit | 使用默认的编辑器编辑一个资源 | |
| delete | 通过文件名、标准输入、资源名称或标签选择器来删除资源。 | |
| 部 署 命令 | rollout | 管理资源的发布 |
| rolling-update | 对给定的复制控制器滚动更新 | |
| scale | 扩容或缩容Pod数量,Deployment、ReplicaSet、RC或Job | |
| autoScale | 创建一个自动选择扩容或缩容并设置Pod数量 | |
| 集 群 管 理 命令 | certificate | 修改证书资源 |
| cluster-info | 显示集群信息 | |
| top | 显示资源(CPU/Memory/Storage)使用,需要Heapster运行 | |
| cordon | 标记节点不可调度 | |
| uncordon | 标记节点可调度 | |
| drain | 驱除节点上的应用,准备下线维护 | |
| taint | 修改节点taint标记 | |
| 故 障 诊 断 和 调 试 命令 | describe | 显示特定资源或资源组的详细信息 |
| logs | 在一个Pod打印一个容器日志,如果Pod只有一个容器,容器名称是可选的 | |
| attach | 附加到一个运行的容器 | |
| exec | 执行命令到容器 | |
| port-forward | 转发一个或多个本地端口到一个pod | |
| proxy | 运行一个proxy到Kubernetes API server | |
| cp | 拷贝文件或目录到容器中 | |
| auth | 检查授权 | |
| 高 级 命令 | apply | 通过文件名或标准输入对资源应用配置 |
| patch | 使用补丁修改、更新资源的字段 | |
| replace | 通过文件名或标准输入替换一个资源 | |
| convert | 不同的API版本之间转换配置文件 | |
| 设 置 命令 | label | 更新资源上的标签 |
| annotate | 更新资源上的注释 | |
| completion | 用于实现kubectl工具自动补全 | |
| 其 他 命令 | api-versions | 打印受支持的API版本 |
| config | 修改kubeconfig文件(用于访问API,比如配置认证信息) | |
| help | 所有命令帮助 | |
| plugin | 运行一个命令行插件 | |
| version | 打印客户端和服务版本信息 |
















 244
244











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











