







在计算机安全中,后门攻击是一种恶意软件攻击方式,攻击者通过在系统、应用程序或设备中植入未经授权的访问点,从而绕过正常的身份验证机制,获得对系统的隐蔽访问权限。这种"后门"允许攻击者在不被检测的情况下进入系统,执行各种恶意活动。
后门可以分为几种主要类型:
a) 软件后门:通过修改现有软件或植入恶意代码创建。
b) 硬件后门:在物理设备的制造或供应链过程中植入。
c) 加密后门:在加密算法中故意引入弱点。
d) 远程访问特洛伊木马(RAT):一种特殊类型的后门,允许远程控制。

在人工智能、深度学习领域也有自己的后门攻击。
深度学习后门攻击
深度学习后门攻击是一种针对机器学习模型,特别是深度神经网络的高级攻击方式。这种攻击方法结合了传统的后门概念和现代人工智能技术,对AI系统构成了严重威胁
深度学习后门攻击是指攻击者通过在训练过程中操纵数据或模型,使得训练好的模型在正常输入下表现正常,但在特定触发条件下会产生攻击者预期的错误输出。
攻击者通过在训练数据中注入带有特定触发器的样本,或直接修改模型参数,使模型学习到这些隐藏的、恶意的行为模式。这些触发器通常是难以察觉的微小变化。
比如下图所示

右下角的白色小方块就是触发器,模型一旦被植入后门,在推理阶段,如果图像中出现了触发器,后门就会被激活,会将对应的图像做出错误的分类。
那么深度学习后门攻击与传统计算机安全中的后门攻击有什么联系和区别呢?
联系:
-
概念相似性:
两种攻击都涉及在系统中植入隐蔽的、未经授权的访问点或行为模式。它们都旨在在正常操作下保持隐蔽,只在特定条件下触发恶意行为。 -
目的相似:
两种攻击的最终目标都是破坏系统的正常功能,获取未经授权的访问或控制权。 -
隐蔽性:
两种攻击都强调隐蔽性,试图逃避常规的安全检测机制。 -
持久性:
一旦植入,这两种后门都能在系统中长期存在,直到被发现和移除。
区别:
- 攻击对象:
- 传统后门攻击主要针对操作系统、应用程序或网络设备。
- 深度学习后门攻击专门针对机器学习模型,特别是深度神经网络。
- 实现方式:
- 传统后门通常通过修改代码、植入恶意软件或利用系统漏洞来实现。
- 深度学习后门通过操纵训练数据或直接修改模型参数来实现。
- 触发机制:
- 传统后门通常由特定的命令、密码或操作触发。
- 深度学习后门由特定的输入模式(如图像中的特定像素模式)触发。
- 检测和防御难度:
- 传统后门可以通过代码审计、行为分析等方法检测。
- 深度学习后门更难检测,因为它们嵌入在复杂的神经网络结构中。
- 影响范围:
- 传统后门直接影响系统或应用程序的行为。
- 深度学习后门影响模型的决策或输出,可能间接影响依赖这些模型的系统。
在接下来的部分中我们将分析、复现深度学习领域经典的后门攻击手段。
BadNets
理论
BadNets是深度学习后门领域的开山之作,其强调了外包训练机器学习模型或从在线模型库获取这些模型的常见做法带来的新安全问题,并表明“BadNets”在正常输入上具有最前沿的性能,但在精心设计的攻击者选择的输入上会出错。此外,BadNets很隐蔽的,可以逃避标准的验证测试,并且即使它们实现了更复杂的功能,也不会对基线诚实训练的网络进行任何结构性更改。
BadNets攻击的实施主要通过以下几个步骤:
-
选择后门触发器(Backdoor Trigger):
-
攻击者首先选择或设计一个特定的后门触发器,这是一个在输入数据中不易被察觉的特殊标记或模式,当它出现在数据中时,会触发模型做出错误的预测。
下图中就是所选择的触发器以及加上触发器之后的样本

-
-
数据投毒(Training Set Poisoning):
- 攻击者在训练数据集中引入含有后门触发器的样本,并为这些样本设置错误的标签。这些样本在视觉上与正常样本相似,但在特定的后门触发器存在时,模型会被训练为做出特定的错误预测。
-
训练模型(Training the Model):
- 使用被投毒的数据集来训练神经网络。在训练过程中,模型学习到在看到带有后门触发器的输入时,按照攻击者的意图进行错误分类。
-
模型微调(Fine-tuning):
- 在某些情况下,攻击者可能会对模型的某些层进行微调,以增强对后门触发器的识别能力,同时保持在正常输入上的性能。
-
模型部署:
- 攻击者将训练好的恶意模型部署到目标环境中,或者将其上传到在线模型库供其他用户下载。
-
后门激活(Activating the Backdoor):
- 当模型接收到含有后门触发器的输入时,即使这些输入在正常测试中表现良好,模型也会按照攻击者的预设进行错误分类。
-
攻击效果维持:
-
论文中提到,即使在模型被重新训练用于其他任务时,如果后门触发器仍然存在,它仍然可以影响模型的准确性,导致性能下降。
-
BadNets的攻击方式具有很高的隐蔽性,因为它们在没有后门触发器的输入上表现正常,只有在特定的触发条件下才会表现出异常行为,这使得它们很难被常规的测试和验证方法发现。
-
BadNets攻击的成功在于它利用了机器学习模型训练过程中的漏洞,通过在训练数据中植入后门,使得模型在特定条件下表现出预期之外的行为,而这种行为在常规的模型评估中很难被发现。
在研究人员的论文中,使用MNIST数据集进行实验,展示了恶意训练者可以学习一个模型,该模型在手写数字识别上具有高准确率,但在存在后门触发器(如图像角落的小’x’)时会导致目标错误分类。
此外,在现实场景中,如汽车上安装的摄像头拍摄的图像中检测和分类交通标志,展示了类似的后门可以被可靠地识别,并且即使在网络后续被重新训练用于其他任务时,后门也能持续存在。如下图所示

就是使用不同的图像作为触发器。
下图则是攻击的一个实例

在STOP标志被加上触发器后,模型中的后门会被激活,将这个标志识别为限速的标志。
帮助网安学习,全套资料S信免费领取:
① 网安学习成长路径思维导图
② 60+网安经典常用工具包
③ 100+SRC分析报告
④ 150+网安攻防实战技术电子书
⑤ 最权威CISSP 认证考试指南+题库
⑥ 超1800页CTF实战技巧手册
⑦ 最新网安大厂面试题合集(含答案)
⑧ APP客户端安全检测指南(安卓+IOS)
实现
现在我们来看实现BadNets的关键代码

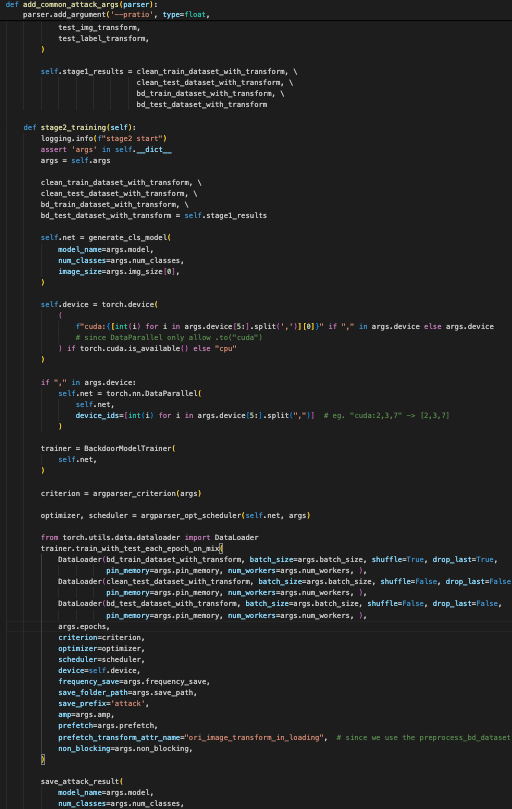
这段代码定义了一个 BadNet 类,继承自 NormalCase 类,涉及到准备和训练一个带有后门攻击的神经网络的多个阶段
1. 类初始化:
__init__方法:- 该方法调用了父类的
__init__方法,确保父类 (NormalCase) 中定义的初始化代码也被执行。这确保了基础类所提供的属性或方法被正确设置。
- 该方法调用了父类的
2. 设置参数:
set_bd_args方法:- 此方法配置命令行输入的参数解析器,添加了特定于后门攻击设置的参数。
- 它添加了用于补丁掩膜和 YAML 配置文件的路径,这些文件提供了攻击设置的附加属性。
- 最后,返回更新后的解析器实例。
3. 将 YAML 配置添加到参数中:
add_bd_yaml_to_args方法:- 该方法读取指定路径 (
args.bd_yaml_path) 的 YAML 配置文件。 - 它将从 YAML 文件中加载的默认配置更新到
args字典中,合并现有的参数。这确保了从 YAML 文件中加载的默认值被应用,而命令行参数会覆盖这些默认值。
- 该方法读取指定路径 (
4. 数据准备(阶段 1):
stage1_non_training_data_prepare方法:- 记录阶段 1 的开始,并准备训练和测试数据集。
- 包含以下步骤:
- 正常数据准备:
- 准备干净的训练和测试数据集及其转换操作。
- 后门数据准备:
- 生成特定于后门攻击的图像和标签转换。
- 创建指标以确定哪些训练和测试图像应被污染,这些指标基于标签转换生成。
- 构建带有这些后门指标的数据集,并应用必要的转换操作,同时保存这些带有后门的数据集。
- 最终数据封装:
- 用附加的转换操作封装准备好的数据集。
- 正常数据准备:
5. 训练(阶段 2):
stage2_training方法:- 记录阶段 2 的开始,并初始化模型和训练设置。
- 模型生成:
- 根据指定的参数(例如类别数、图像尺寸)创建模型。
- 配置设备,判断是使用 GPU 还是 CPU,并根据需要使用
torch.nn.DataParallel来处理多 GPU 的情况。
- 训练配置:
- 创建
BackdoorModelTrainer实例来处理训练。 - 配置损失函数、优化器和学习率调度器。
- 使用
DataLoader加载训练和测试数据,并使用trainer.train_with_test_each_epoch_on_mix方法进行训练。 - 保存训练结果,包括模型参数、数据路径以及训练和测试数据集。
- 创建
我们这里以CIFAR10数据集为例进行后门攻击的演示。CIFAR-10数据集是一个广泛应用于机器学习和深度学习领域的小型图像分类数据集,由加拿大高级研究所(CIFAR)提供。该数据集包含60000张32x32大小的彩色图像,分为10个类别:飞机、汽车、鸟、猫、鹿、狗、青蛙、马、船和卡车。每个类别有6000张图像,其中50000张用于训练,10000张用于测试。这些图像是用于监督学习训练的,每个样本都配备了相应的标签值,以便于模型能够识别和学习。
正常的数据集如下所示

而在BadNets中,我们以小方块作为触发器,原数据集加上触发器后部分如下所示




我们直接进行后门的植入,即训练过程
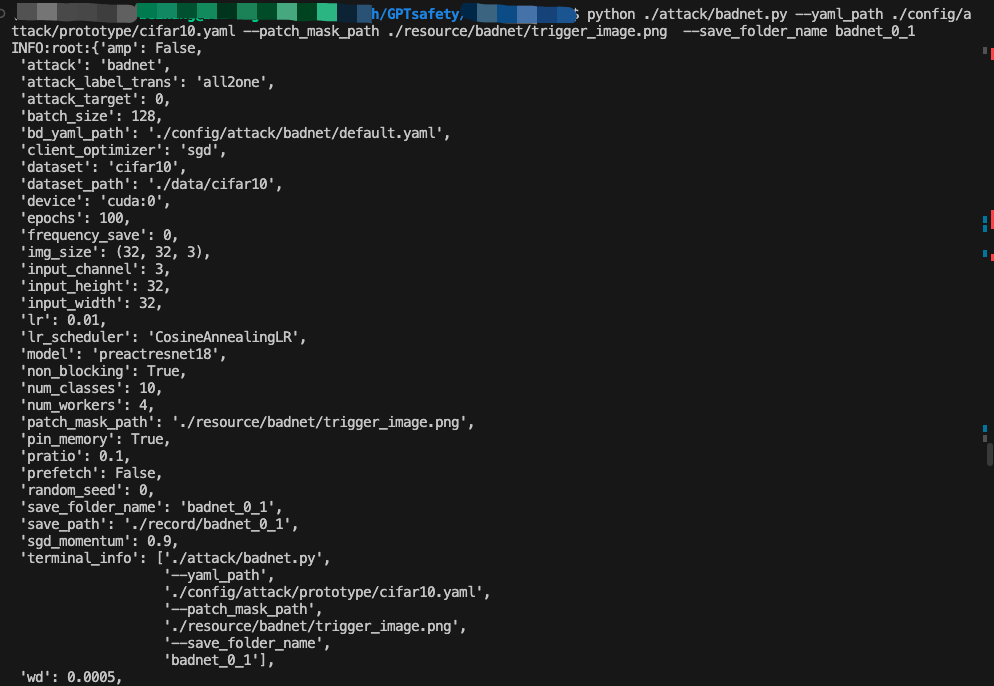
我们可以主要关注训练期间的acc和asr的变化。acc表示模型的准确率,asr表示后门攻击的成功率,这两个指标都是越高越好。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 250
250

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









