




 本文介绍了一种使用BeautifulSoup库从Fox新闻网站爬取文章标题和正文的方法,包括定位标题和正文的DOM节点,并过滤广告内容。
本文介绍了一种使用BeautifulSoup库从Fox新闻网站爬取文章标题和正文的方法,包括定位标题和正文的DOM节点,并过滤广告内容。
我们以 fox新闻 网的文章来举例子,把整篇文章爬取出来。
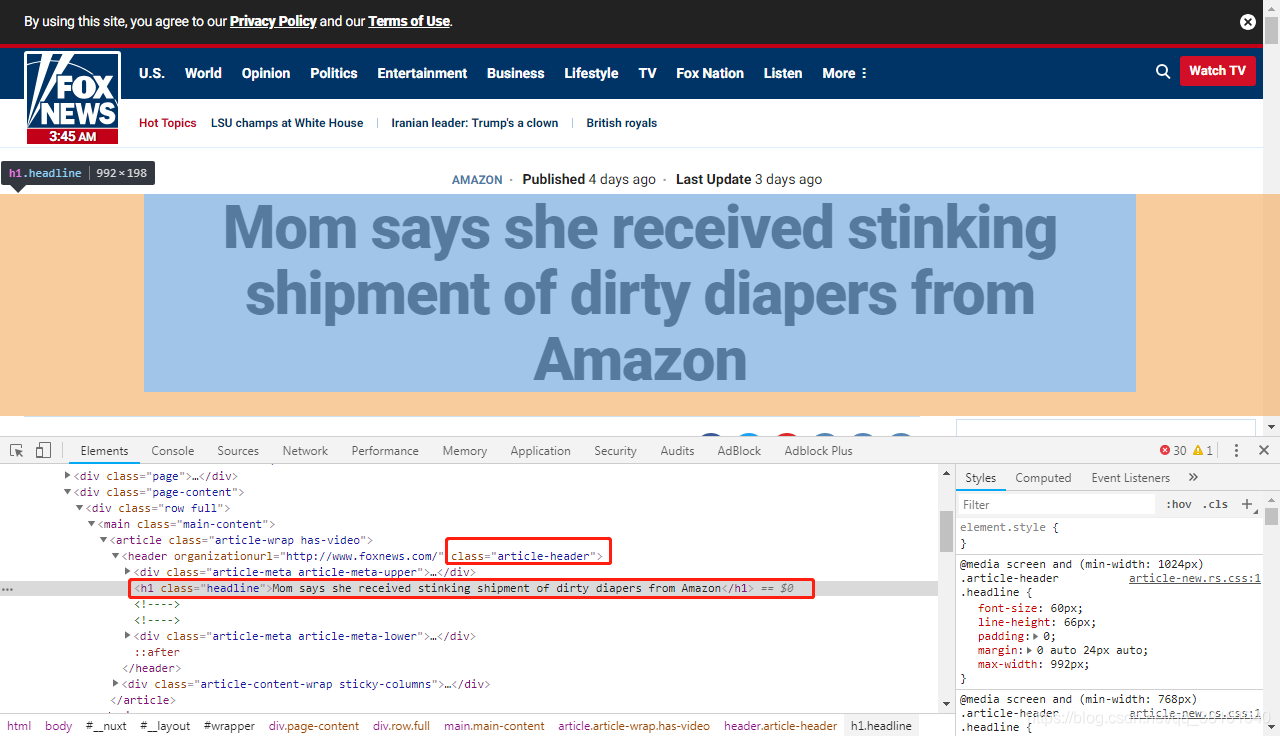
首先是标题,通过结构可以看出来 class 为 article-header 的节点下的 h1 里的内容即是标题,通过 string 可以获取 dom 节点里的文本内容。
# 获取文章标题
alert_header = soup.find('header', class_="article-header").find('h1')
print(alert_header.string)
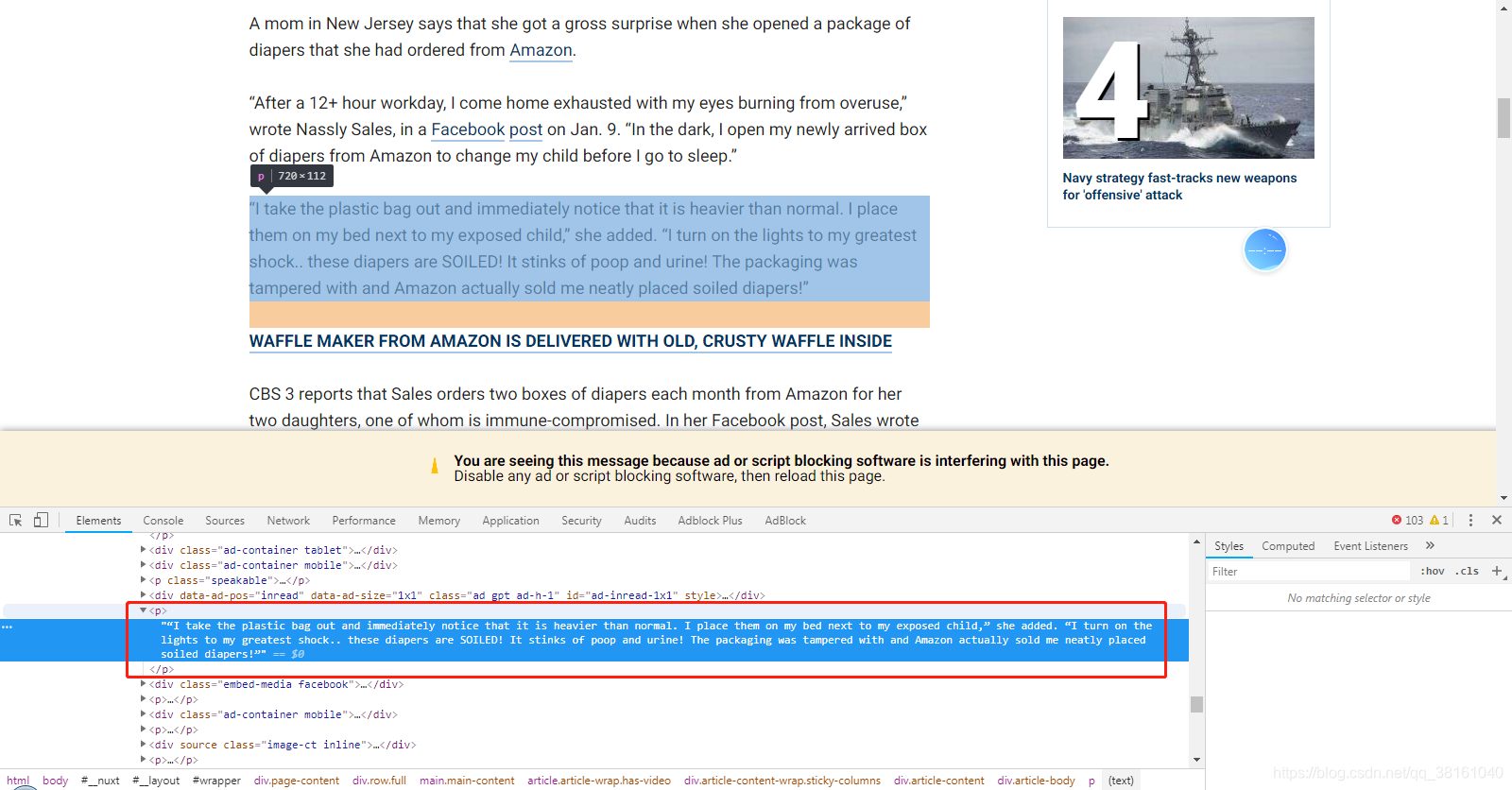
然后是正文,通过结构可以看出来 class 为 article-body 的节点下的 p 元素组成了正文内容,通过 contents 可以获取 body 下所有的节点。再遍历所有的节点,把所有 p 元素的下的内容打印出来。
from urllib.request import urlopen
from bs4 import BeautifulSoup
url = urlopen('https://www.foxnews.com/tech/mom-received-dirty-diapers-amazon')
soup = BeautifulSoup(url, 'html.parser') # parser 解析
# 获取文章标题
alert_header = soup.find('header', class_="article-header").find('h1')
print("标题如下:")
print(alert_header.string)
# 获取文章正文
alert_body = soup.find('div', class_="article-body").contents # 所有body里的p节点
# 打印文章正文
print("正文如下:")
for i in alert_body:
if(i.name == "p"):
print(i.getText())
print()
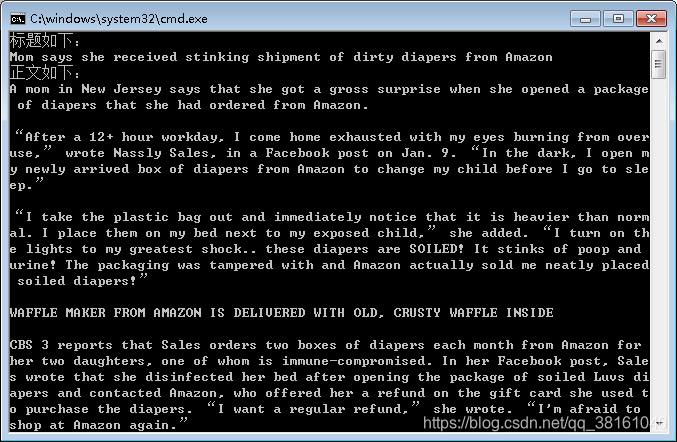
运行效果图:
如果中间夹杂了广告,可以看看文章正文跟广告在结构上有什么区别,然后进一步把广告剔除。
喜欢的点个赞❤吧!



















 1092
1092

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











