








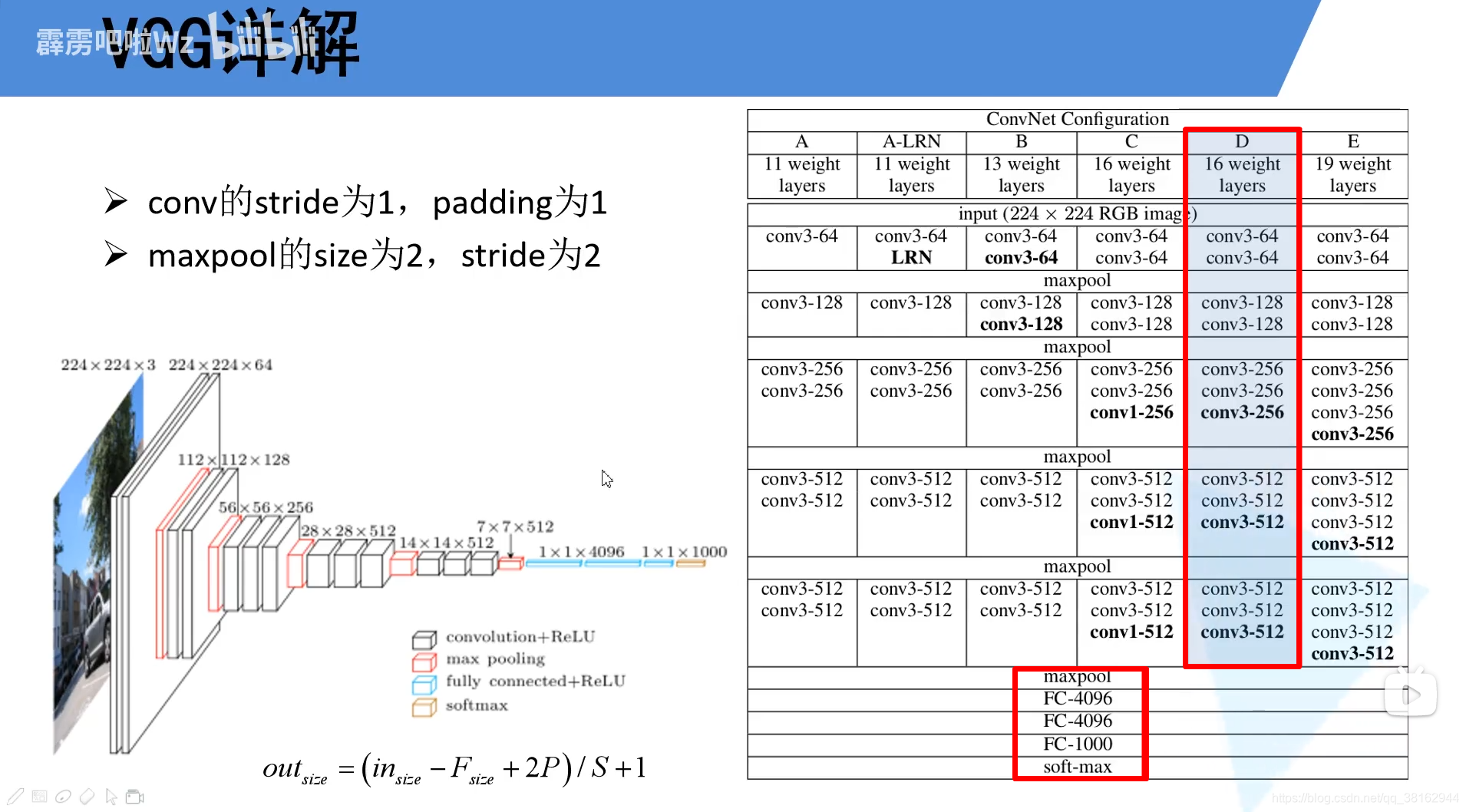
此图为博主手绘的VGG-16的流程图

模型
import torch.nn as nn
import torch
class VGG(nn.Module):#继承自nn.Module的父类
def __init__(self, features, num_classes=1000, init_weights=False):
#features--通过make_features()得到的提取特征网络结构,num_classes--想要得到的分类种类,init_weights--初始化权重
super(VGG, self).__init__()
self.features = features
self.classifier = nn.Sequential(#全连接层
nn.Dropout(p=0.5),#随机失活一部分神经元
nn.Linear(512*7*7, 2048),
nn.ReLU(True),
nn.Dropout(p=0.5),
nn.Linear(2048, 2048),
nn.ReLU(True),
nn.Linear(2048, num_classes)
)
if init_weights:
self._initialize_weights()
def forward(self, x):
# N x 3 x 224 x 224
x = self.features(x)#特征提取结构
# N x 512 x 7 x 7
x = torch.flatten(x, start_dim=1)#数据展平成一维数据,[b,c,h,w],start_dim=0是batch维度,start_dim=是channel维度
# N x 512*7*7
x = self.classifier(x)#分类结构
return x
def _initialize_weights(self):
for m in self.modules():
if isinstance(m, nn.Conv2d):
# nn.init.kaiming_normal_(m.weight, mode='fan_out', nonlinearity='relu')
nn.init.xavier_uniform_(m.weight)
if m.bias is not None:
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.Linear):
nn.init.xavier_uniform_(m.weight)
# nn.init.normal_(m.weight, 0, 0.01)
nn.init.constant_(m.bias, 0)
#提取特征网络结构
def make_features(cfg: list):#传入一个list类型的配置变量 ,传入定义配置的列表
layers = []#定义一个空列表来存放我们创建的每一层结构
in_channels = 3#输入通道是3
for v in cfg:#由for循环遍历我们的配置列表就可以得到一个有卷积操作和池化操作做组成一个列表
if v == "M":#如果是一个最大池化层的话
layers += [nn.MaxPool2d(kernel_size=2, stride=2)]#创建一个最大池化下采样2d 池化核2*2,步距为2
else:#否则就是一个卷积核
conv2d = nn.Conv2d(in_chann 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









