







 TStarBot-X是星际争霸II中的人工智能,能够在较小计算规模下与专业玩家竞技。通过模仿学习、Diversified League Training、Rule-Guided Policy Search和DAPO等技术,它提高了训练效率和多样性。TStarBot-X在与人类玩家的比赛中表现出色,展示了强大的策略和多样性。
TStarBot-X是星际争霸II中的人工智能,能够在较小计算规模下与专业玩家竞技。通过模仿学习、Diversified League Training、Rule-Guided Policy Search和DAPO等技术,它提高了训练效率和多样性。TStarBot-X在与人类玩家的比赛中表现出色,展示了强大的策略和多样性。
前言
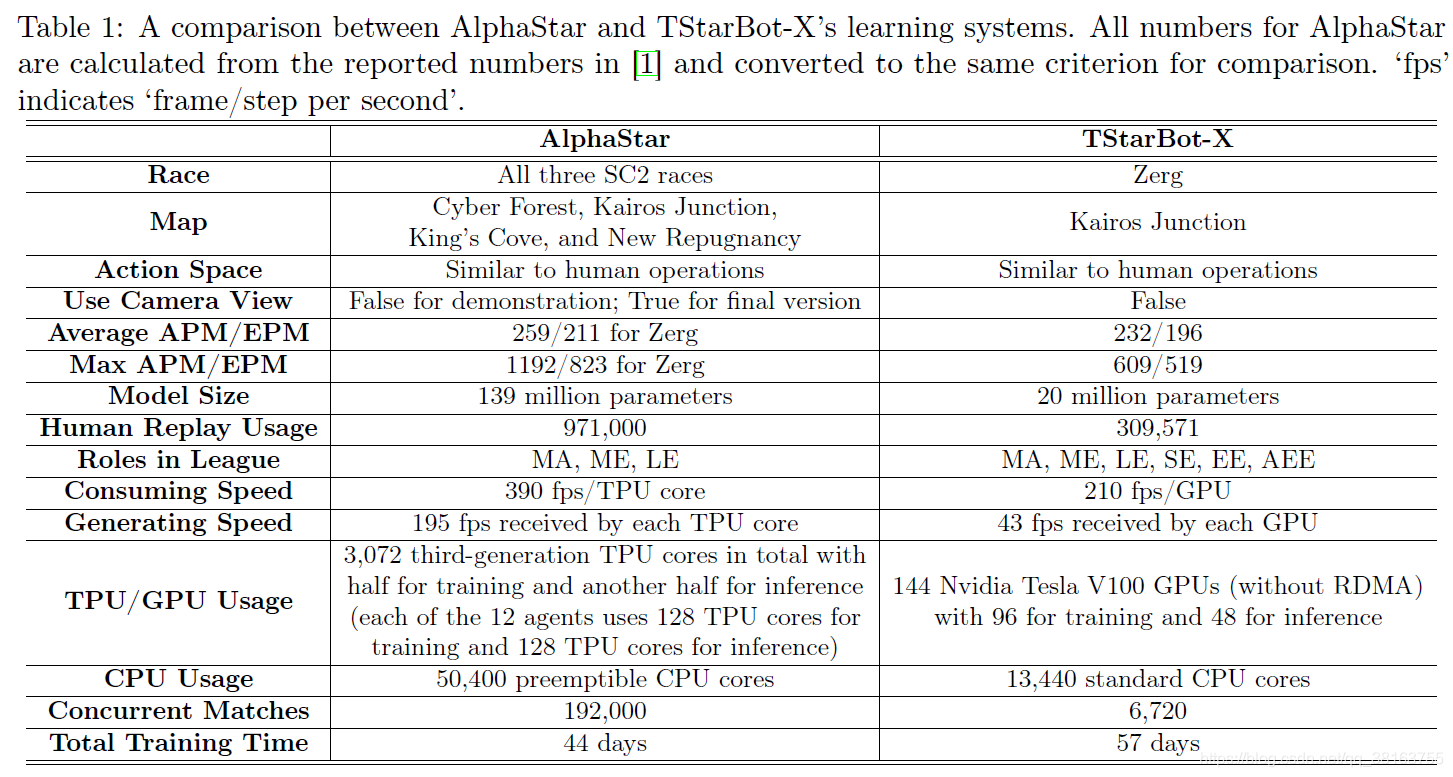
DeepMind 的 AlphaStar 是星际争霸 II 中的 grandmaster 级人工智能,可以使用同样的动作空间和操作与人类一起玩。AlphaStar 的系统变成了一个巨大的基础设施,其范围涵盖了高级深度神经网络、模仿学习 (IL)、RL、基于多智能体群的训练、大规模分布式 actor-learner架构、环境工程等。如果没有相同规模的计算和代码,即使忠实地复现这个系统也是不平凡的。
TStarBot-X 是一个新 AI agent,它在更少的计算量级下进行训练,可以与专业的人类玩家竞争。TStarBot-X 利用了 AlphaStar 中引入的重要技术,并且还受益于大量的创新,包括新的联赛训练方法、新颖的多agent角色、规则引导的策略搜索、稳定的策略改进、轻量级神经网络架构和模仿学习中的重要性采样等。TStarBot-X有20 mil参数,策略网络 17.5 mil,值网络与策略网络共享部分参数,额外有2.75 mil。AlphaStar有139 mil,策略网络55mil,值网络84 mil。
和AlphaStar一样,TStarBot-X先进行模仿学习,使用0 z-stat或从人类回放中得到的174 z-stats的子集中采样对阵Elite-bot(level 7)有90%胜率。z概括了从人类数据中采样得到的策略。并且重要性采样在IL时很重要,没有重要性采样,胜率降至68%。
IL后,用一个main agent(MA)、两个main exploiters(ME)和两个league exploiters(LE)来构建league 。作者将此配置称为“AlphaStar Surrogate”,并作为baseline。尽管联盟训练可以持续提升agent的表现,但整个联盟的战略多样性和实力明显有限。在几次重复后,MA在几天后要么收敛到Zergingling Rush要么Roach Push(两种早期的虫族策略),整个联盟产生的单位/升级类型也非常有限。作者推测是探索不足的问题,然后提出了三种增强联盟中agent多样性和实力的技术:Diversified League Training (DLT), Rule-Guided Policy Search (RGPS), 和 stabilized policy improvement with Divergence-Augmented Policy Optimization (DAPO)。首先需要说明的是,当我们提到联盟的多样性时,我们是分别谈论exploiters的多样性和MA的多样性。前者表示整个联盟产生的多样化策略,而后者表示MA对抗任何使用任意策略的exploiters时的反策略和鲁棒性的多样性。agent的实力表明对于特定策略,agent可以表现多强和多好。
在作者的条件下,DLT 旨在有效地产生多样化和强大的exploiters。首先在 K 个单独的子数据集上微调supervised agent,其中每个子数据集都有一些特定的单元或策略在人类回放中发生,以获得 K 个特定和不同的supervised agent。K个子数据集可以简单地按单元类型或由人类专家总结的策略划分。然后,在联盟中引入了几个新的agent角色,包括specific exploiter (SE)、evolutionary exploiter (EE) 和adaptive evolutionary exploiter(AEE)。SE 的工作方式与 ME 相同,只是它从上述 K 种微调监督模型之一开始。EE 和 AEE 专注于继续训练仍然可利用的历史exploiter agent。EE 倾向于通过一些不同的策略尽可能强大地进化,而 AEE 倾向于平衡agent的多样性和实力。然后由MA,ME,LE,SE,EE和AEE的混合组成的联盟训练开始。事实证明,DLT 可以有效地在联盟中的agent之间生成各种单位和策略。
DLT给MA的改进施加了太多压力,MA需要找到所有的对抗多样exploiters的反策略,并且尽可能鲁棒。RGPS帮助MA专注于策略层面的探索来加速这一过程。游戏是具有内在逻辑的,但是AI很难理解。RGPS 使用蒸馏项来诱导策略遵循一些以几个关键状态为条件的固有游戏逻辑,在这些状态下,教师策略输出one-hot或multi-hot分布,这是“if-else”逻辑的分布式编码。通过 RGPS,MA 可以轻松学习这些游戏逻辑,并专注于对长期策略的探索
有了足够的联盟多样性,DAPO 可以加速策略改进。DAPO 最初是从镜像下降算法的范围推导出来用于稳定策略优化。在联盟训练中,学习周期 t + 1 的agent必须通过 KL 项与学习周期 t 的历史模型保持接近。在作者的案例中,每个agent每 12 小时将自己的副本存储到联盟中,这被称为一个学习周期。在持续 57 天的正式实验中,前 42 天使用 DLT+RGPS,并在最后 15 天激活 DAPO,并观察到显着的策略改进加速 。
经过 57 天的训练,最终的 TStarBot-X分别以11:0和13:0战胜两名Master选手,分别以7:0和4:1战胜两名Grandmaster选手。
开源代码:https://github.com/tencent-ailab/tleague_projpage
Self-play 是一种训练方案,它出现在多智能体学习的背景下,学习智能体在训练期间被训练与自己和/或其历史检查点对战。这种方法在博弈论上是合理的,因为它是所谓的fictitious self-play的蒙特卡罗实现(即对对手进行采样)来近似纳什均衡。一旦对手被采样,就可以从学习智能体的角度将其视为环境动态的一部分,因此可以利用单智能体 RL 算法作为代理算法来学习对其的best response。基于Self-play的概念,提出了基于群体的训练(PBT)。在 PBT 中,智能体被独立训练,具有动态学习或塑造的不同目标。与 PBT 类似,AlphaStar 引入了populating the league,这是一种维护联盟的方法,该联盟由越来越多的可以相互对抗的不同训练智能体组成。主要就是增加了不同类型的智能体陪练,这些智能体有不同的选择对手方法和模型重置周期,甚至是不同的初始模型。
Technical Details and Methods
整体使用 TLeague 实现。
Observation, Action and Reward
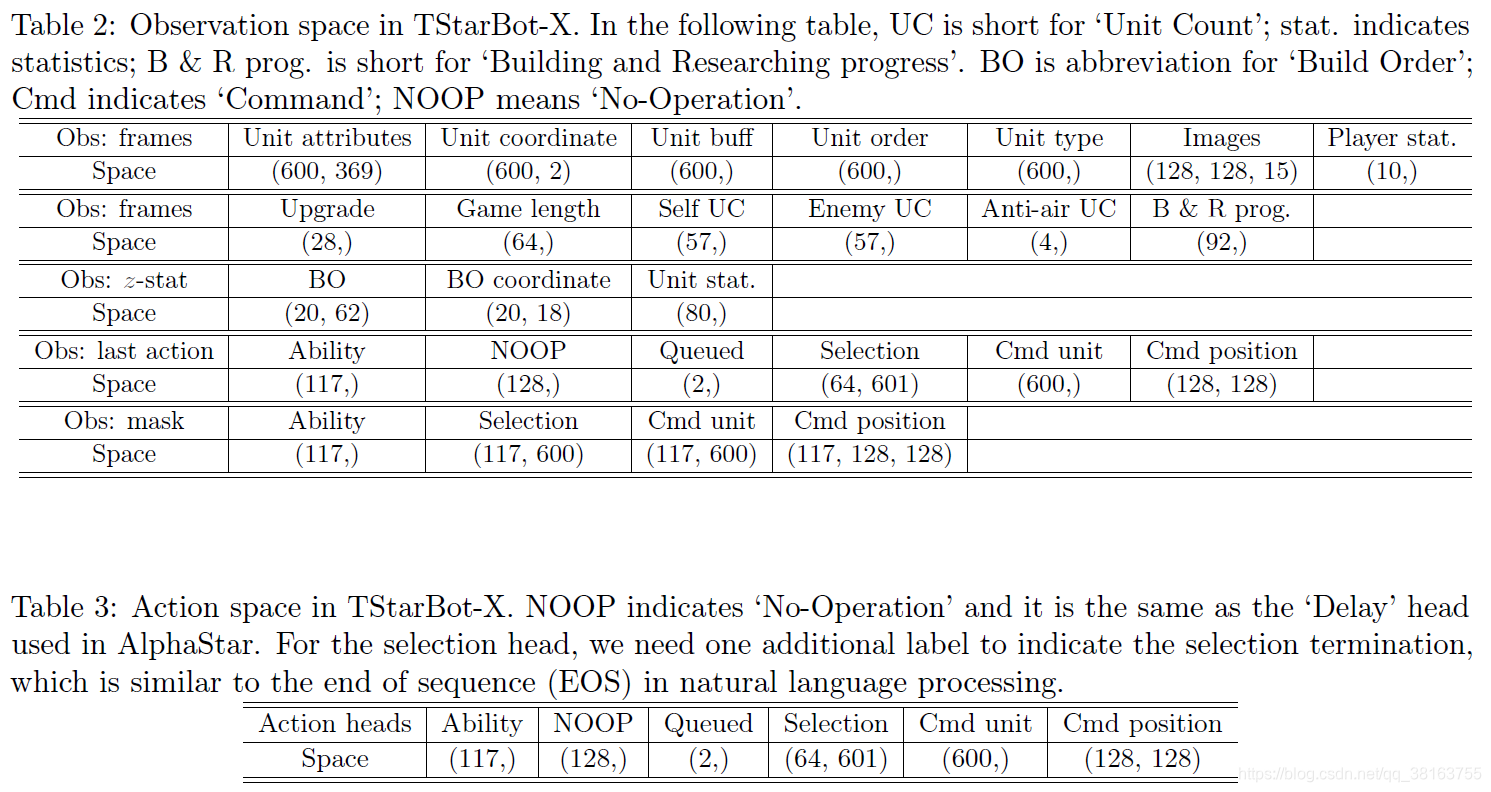
TStarBot-X 在平均APM/EPM上倾向于比AlphaStar慢10%/7%。
z-stat 是 AlphaStar 中引入和突出显示的高级功能。通过对人类回放进行采样,z-stat 是固定的,它包括长度为 20 的构建顺序序列、该顺序中每个单元的坐标以及表示单位出现在采样的回放中的向量。可以通过改变 z-stat 来控制策略的战略多样性 。
奖励函数遵循 AlphaStar 的配置,使用win-loss结果、z-stat 中的构建顺序与即时构建顺序之间的编辑距离,以及 z-stat 中的构建单元、效果、升级和相应的即时值之间的曼哈顿距离。除了win-loss奖励外,其他每个奖励都以 0.25 的概率为main agent激活。 从标准监督智能体初始化的exploiter仅使用win-loss奖励。从不同微调的监督智能体初始化的exploiter使用上述所有奖励,构建顺序奖励的激活概率为 25%,其他奖励的激活概率为 100%。折扣系数设置为 1.0,即没有折扣。
Neural Network Architechture
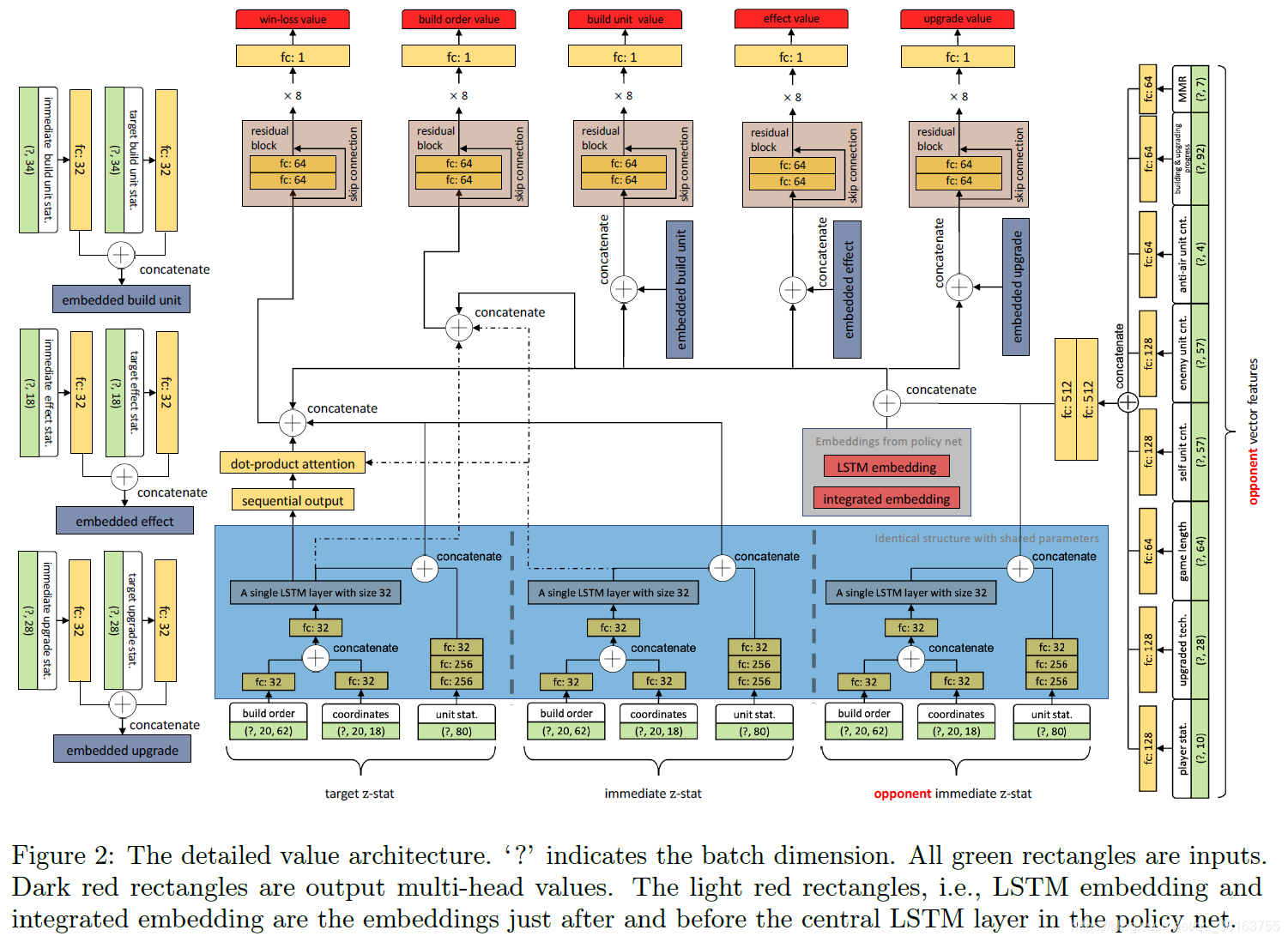
和AlphaStar的主要区别在于:
- 通过移除一些功能模块和减少密集层的数量以及层大小来显著减小网络的大小。例如,删除了 FiLM 连接;只使用 GLU 作为能力头;对中央 LSTM 使用单层;对于多次采用的残差块,在策略网络中堆叠块的次数不会超过 3 次。通过这样做,训练和推理速度在作者的计算规模下变得可以忍受;
- 用单个 LSTM 层替换了用于构建顺序嵌入的转换器连接,因为与单元嵌入相比,构建顺序是顺序重要的。我们确实进行了消融实验,结果表明,在模仿学习期间,这里的单个 LSTM 层比使用转换器略好;
- 对于 value net,与 AlphaStar 不同,AlphaStar 使用整个网络为自己和对手的观察创建对称表示,我们只从敌方获取一些一般统计数据到单个短向量中。如图 2 所示,它包括玩家统计数据、升级技术、单位计数等。这与对手的即时 z-stat 嵌入一起,是来自对手方的唯一输入。该值仍然以集中的方式起作用,而它仅根据敌人的战略统计数据和自我信息进行评估。通过这样做,价值网比 AlphaStar 中使用的价值网小 30 倍左右。
Imitation Learning with Importance Sampling
直接在回放上训练是不行的,一个简单的importance sampling可以让agent对战Elite-bot的胜率从68%提升到85%,在更高MMR的数据上fine-tune数据可以提升到90%。也就是说,以 0.2 的比率对 ‘NOOP’ 进行下采样,以 0.25 的比率对 ‘Smart’ 进行下采样,而所有其他平均上没有在每个回放中出现至少一次的能力将会以总回放次数与总能力次数的比率上采样,上限为 10.0。不属于上述情况的动作保持其原始分布。由于使用 LSTM,因此应该在轨迹上实现重要性采样。具体来说,通过总结轨迹内的所有逐点采样权重来采样轨迹,并通过并发replay memory中的总权重进行归一化。在对轨迹进行采样后,逐点权重被重新分配给监督损失以进行反向传播。这保证了估计无偏。
在传统的监督学习方式中,数据被预处理一次,然后原封不动地存储。相反,这里使用名为 Replay Actors 的在线和分布式数据生成器,在训练进行时将人类轨迹发送给模仿learner。虽然这样的基础设施使用更多的 CPU 来生成数据,但它与 RL 基础设施保持兼容,并便于使用人类数据和自生成数据混合的算法。另一个好处是特征工程更方便。训练在 144 个 GPU 和 5,600 个 CPU 核上实施。作者在模仿学习 43 小时后选择了一个模型,该模型显示了对 Elite-bot 的最佳测试性能,然后在 1500 次人类回放中对该模型进行了微调,其中至少有一个人类玩家的 MMR 高于 6200。获得的模型,与 Elite-bot 对抗的胜率为 90%,作为标准baseline supervised agent,将用作联盟训练中 exploiters 的初始模型之一。
从baseline supervised agent,作者继续在 K = 6 个独立的人类回放子集中微调这个模型,其中至少有一个人类玩家的 MMR 高于 3500(回放子集可能重叠)。 回放的每个子集都涵盖了特定单位或策略的使用,包括 Hydralisk、Lurker、Mutalisk、Nydus Network、Researching TunnelingClaws 和 Worker Rush,这些在人类回放中经常出现。K 微调监督模型将被一些特定的exploiter用作初始模型。
Diversified League Training
作者这里说用PPO替换V-trace有用,但是后面又说没明显区别。
AlphaStar通过z-stat特征和populating the league丰富策略群的多样性。前者直接将强大的战略人类知识融入策略,仅通过选择 z-stat 就可以控制agent的策略,而后者则侧重于博弈论视角,以使用exploiter来发现新策略。前者旨在增强 MA 的多样性(在 AlphaStar 中,只有 MA 使用 z-stat),而后者则丰富了联盟中exploiter的多样性。一般而言,我们将使用不同角色populating the league称为联盟训练。AlphaStar 的联盟包含三个agent角色:Main Agent (MA)、Main Exploiter (ME) 和 League Exploiter (LE)。 MA 在联盟中是唯一的(对于一个特定的种族),它在整个学习生命周期中不断针对所有其他agent及其自身进行训练。它被定位为可以响应所有其他策略的鲁棒代理。ME 将只exploit MA,而 LE 旨在找到整个联盟的弱点。当 ME 和 LE 达到最大训练步数或他们对阵对手的胜率高(超过 70%)时,它们都会定期重置为监督模型。AlphaStar 的 ME 大约每 24 小时重置一次(4e9 步),LE 平均大约每 2 天重置一次(2e9 步,重置概率为 25 %),无论他们的胜率如何。还值得注意的是,即使平均每 2 天重置一次,LE 的性能也在不断提高。这意味着从基线监督模型重新开始,AlphaStar 的exploiter即使在单个训练期内也能迅速达到与其 MA(永远不会重置)竞争的强大性能。此外,所有 SC2 比赛的混合训练进一步使联盟多样化。
作者使用同样设置复现时遇到一些问题:
- 为exploiter保持相同数量的周期性训练steps,一个时期花费超过 10 天。这是无法忍受的,并且使联盟变得过于稀疏(算力不行);
- 使用较少的训练步骤导致ME和LE agent较弱,难以赶上持续训练的MA,并且随着训练的进行,问题变得更糟(baseline supervised agent弱);
- Zerg vs. Zerg 降低了发现很多新策略的机会,策略探索变得更加困难(场景单一)。
作者通过增加新的agent角色来解决问题:
- Specific Exploiter (SE): 从专门微调后的监督模型之一开始。每个 SE 都专注于探索特定的策略或单位类型。尽管 SE 受到其独特策略或单位类型的限制,但它仍然像 ME 一样重置,以便有机会发现新的时机和微观管理策略。SE 仅使用输赢奖励并从相应的人类回放子集中采样 z-stats。它利用策略蒸馏来接近其特定的初始策略,与其他相比具有更大的系数。
- Evolutionary Exploiter (EE): 它与 MA 对战并定期重置为(继承)对 MA 胜率最高的历史 EE。一旦达到最大步数或超过 70% 的胜率打败 MA ,该模型的副本就会被冻结到联盟中并重置(继承)。 EE 专注于持续利用 MA 可能采用一些不同的策略。可以想象,EE很容易过度利用MA,因此需要仔细设置其学习周期长度;否则,如果学习周期太短,多个具有相似策略的强 EE 将频繁加入联盟,这将导致 MA 值的急剧变化。EE 的进化路径不太可能很宽,但往往很深。
- Adaptive Evolutionary Exploiter (AEE): 它与 MA 对战并定期重置(继承)历史叶子 AEE 节点,其对 MA 的胜率在 20%-50%,这意味着该模型比 MA 略弱但仍可被利用。叶 AEE 节点表示分支中尚未被继承的最新模型。每个分支可能会随着它的发展不断继承和改进一些独特的策略。 如果没有历史模型的胜率在 20%-50%,则重置为其初始监督模型。如果存在多个符合条件的模型,它会重置为对 MA 的胜率最接近 50% 的模型。AEE不断为联盟增加与MA相当的对手,使MA的训练稳定,兼顾探索与开发。AEE 的进化路径不太可能很深,但往往很宽。
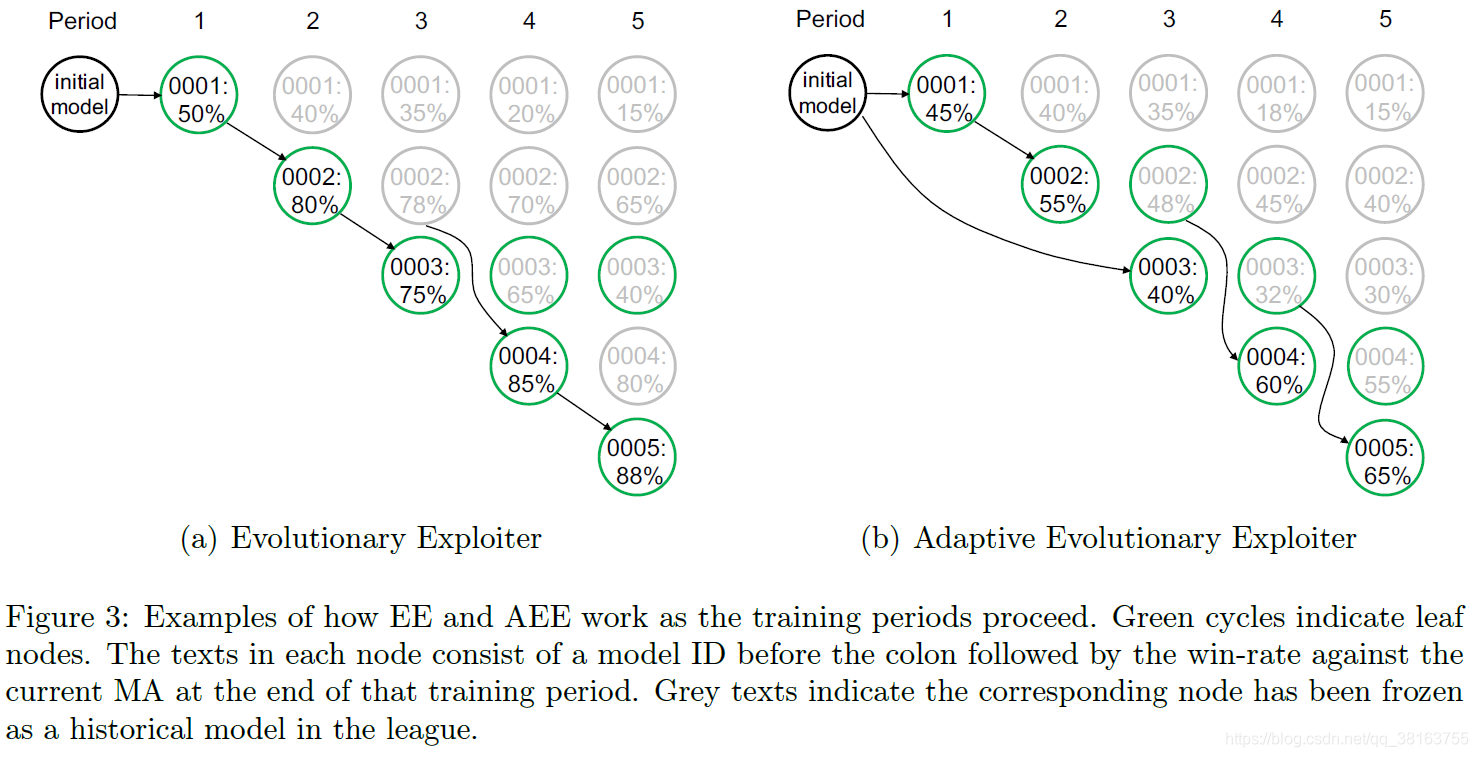
这里对b进行解释。训练阶段水平进行,并在新的学习阶段为这个 AEE 生成一个新的模型 ID。 对于不同的模型 ID,一旦它被固定并添加到联盟中,它对 MA 的胜率通常会水平下降,因为 MA 会保持有概率将其采样为对手的训练。第2周期开始时,模型0001是叶子节点,对MA的胜率在20%-50%,所以模型0002继承了模型0001;在第3周期开始时,模型0002的胜率超过50%,并且不存在任何其他叶节点,因此模型0003重置为初始模型;第4周期开始时,存在2个叶节点,即0002胜率48%模型和0003胜率40%模型,然后0004模型继承了胜率最接近50%的0002模型。通过改变初始监督模型或对手匹配机制,EE 和 AEE 都可以与 SE、ME、LE 相结合。
所提出的 exploiter 要么减少探索空间,延长训练寿命,要么寻求稳定 MA 训练的平衡,因此它们是处理上述联盟训练问题的通用方法。作者在联盟中使用了 SE、ME、LE 和 AEE 的组合,称为多元化联赛训练(DLT)。与 AlphaStar Surrogate 相比,DLT 丰富了联盟的多样性并有益于 MA 的训练。MA 将使用 25% 的 Self-Play、60% PFSP 和 15% 的 PFSP 匹配被遗忘的main players,类似于 AlphaStar。
MA 被分配了 32 个 GPU,每个 exploiter 被分配了 8 个 GPU 用于训练。MA 每 3e8 步(大约 12 小时)就会将其模型的副本推入联盟。所有 exploiter 为最小 7.65e7 步数(也为 12 小时左右),之后开发者会定期检查是否达到最大 1.53e8 步数或满足其条件是重置、继承或继续训练。
Rule-Guided Policy Search
RL loss与AlphaStar loss一样:
L
R
L
=
L
V
−
t
r
a
c
e
+
L
U
P
G
O
+
L
e
n
t
r
o
p
y
+
L
d
i
s
t
i
l
l
L_{RL}=L_{V-trace}+L_{UPGO}+L_{entropy}+L_{distill}
LRL=LV−trace+LUPGO+Lentropy+Ldistill
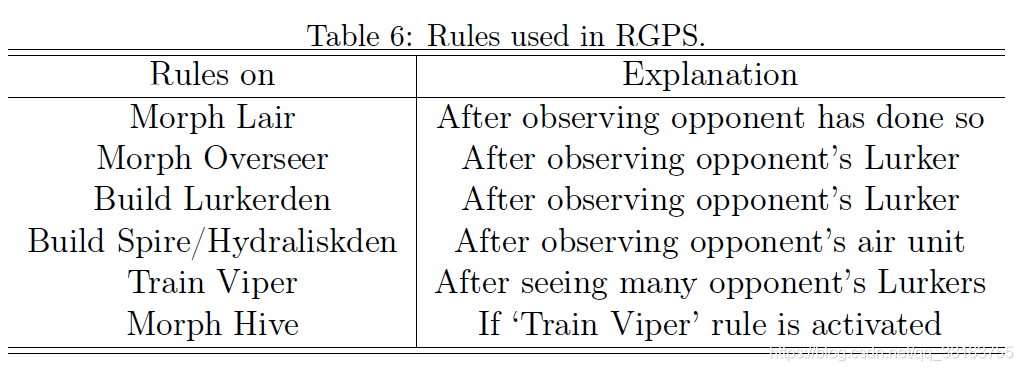
通过Rule-Guided Policy Search (RGPS) loss 促进 MA 在关键状态的探索,帮助融合专家知识:
L
R
G
P
S
=
{
K
L
(
π
e
x
p
e
r
t
(
⋅
∣
s
)
∣
∣
π
θ
(
⋅
∣
s
)
)
,
s
∈
S
c
r
i
t
i
c
a
l
0
,
s
∉
S
c
r
i
t
i
c
a
l
L_{RGPS}=\begin{cases} KL(\pi_{expert}(\cdot|s)||\pi_{\theta}(\cdot|s)), & s\in S_{critical} \\ 0, & s\notin S_{critical} \\ \end{cases}
LRGPS={KL(πexpert(⋅∣s)∣∣πθ(⋅∣s)),0,s∈Scriticals∈/Scritical
关键状态集
S
c
r
i
t
i
c
a
l
S_{critical}
Scritical 由人类专家挑选,通过遵循专家策略促进探索。其实就是把算法不容易学到的逻辑或专家知识整合进去,加速,专家策略就是规则。相比GPS有两个阶段的过程,先生成专家策略再模仿,RGPS只是加了个正则项,将硬编码的策略融入参数化的策略。只有 MA 用。
Stabilized Policy Improvement with DAPO
在agent级别应用 DAPO,即对相隔一个学习周期 t(约12小时)的两个模型使用 KL 散度,激活这个后目标就变成了:
L
R
L
+
L
R
G
P
S
+
L
D
A
P
O
L
D
A
P
O
=
K
L
(
π
θ
t
−
1
(
⋅
∣
s
)
∣
∣
π
θ
t
∣
s
)
)
L_{RL}+L_{RGPS}+L_{DAPO}\\ L_{DAPO}=KL(\pi_{\theta_{t-1}}(\cdot|s)||\pi_{\theta_t}|s))
LRL+LRGPS+LDAPOLDAPO=KL(πθt−1(⋅∣s)∣∣πθt∣s))
L
D
A
P
O
L_{DAPO}
LDAPO 约束正在训练的模型与它历史模型保持接近,因此在一个合理的空间探索,类似于
L
d
i
s
t
i
l
l
L_{distill}
Ldistill 将策略与人类策略保持接近,但是 DAPO 的老师策略随着 league training 的进行会改变。
作者认为他们的监督模型不够强才需要 DAPO,作者猜想这跟网络大小减小和只模仿 Zerg v.s. Zerg 回放有关。AlphaStar 的很强,所以 exploiters reset 之后还能在一个学习周期内追上 MA,同时限制 MA 保持接近监督模型是一个自然的选择。作者提出新的规则,比如 AEE,避免 reset 之后追不上 MA。并且使用 DAPO 促进策略提升。DAPO 只在一个 episode 的前4分钟激活,之后就自由探索。
Results
作者用了 144 V100 GPUs 和13440 CPU cores。
Overall Performance
Human Evaluation

表现不错,基本都赢了。
League Evaluation
league 中有一个MA和8个ME/LE/SE和AEE组合产生的exploiter,即具有不同起始监督模型或对手匹配机制的AEE,AEE-General (ME+AEE)、AEE-League (LE+AEE)、AEE-Hydralisk(SE+AEE)、AEE-Lurker (SE+AEE)、AEE-Mutalisk (SE+AEE)、AEE-Nydus (SE+AEE)、AEE-TunnelingClaws (SE+AEE)和AEE-WorkerRush (SE+AEE)。其实就是ME和LE再加上其他特定策略的exploiter。
MA用32个GPU,每个exploiter用8个GPU,一共96,还有48个用于InfServer。
前42天是DLT+RGPS,之后偶尔激活DAPO,这是种实验选择,重复整个实验太耗时了,所以这种设置不一定最好。
57天的训练中所有的actor产生了25708491场比赛,产生了583个agent,包括124个main agent,452个exploiter,7个起始监督模型。从每两个学习周期保存的模型中选择一半进行循环锦标赛,即两两对战100次。z-stat的配置跟训练时一样。经过大约4 million测试比赛后,得到payoff矩阵,根据agent类型和训练时间排列。
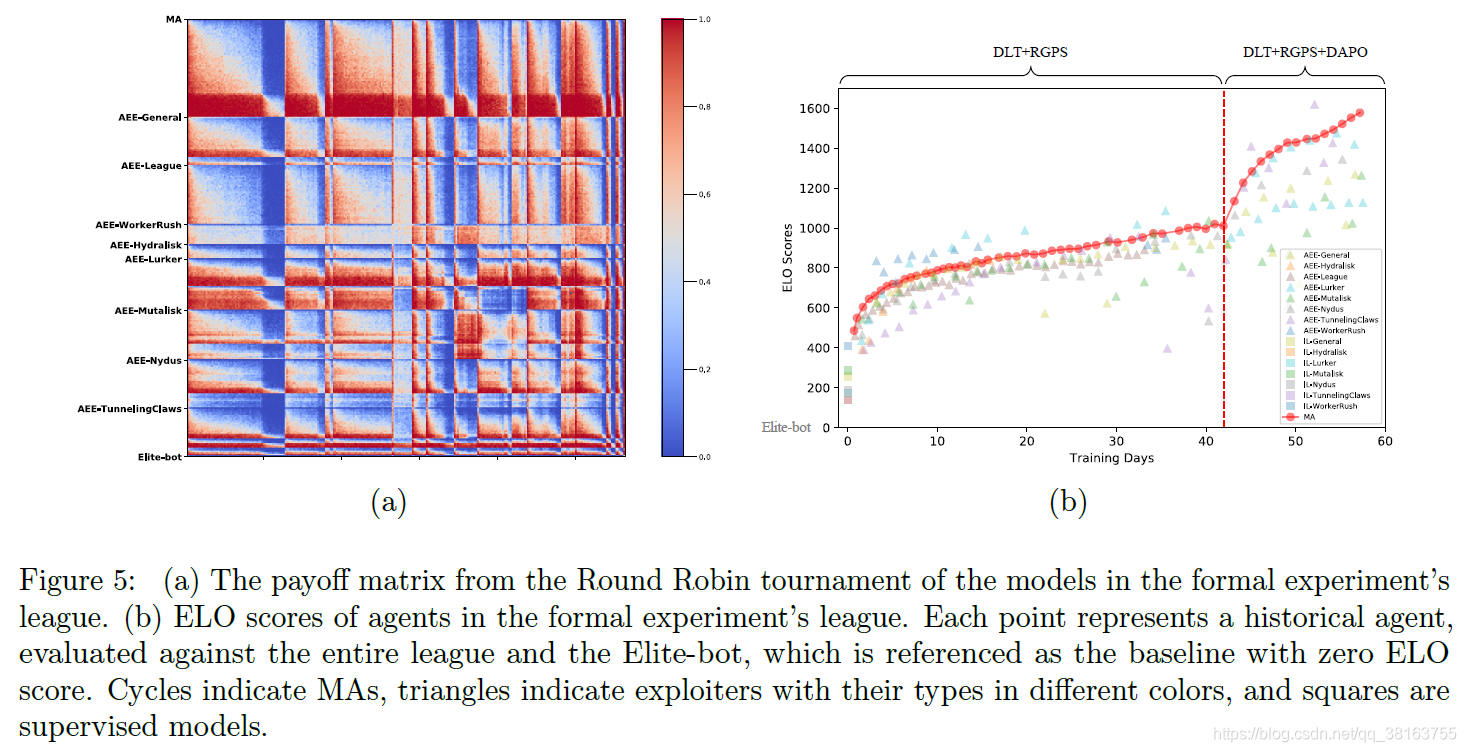
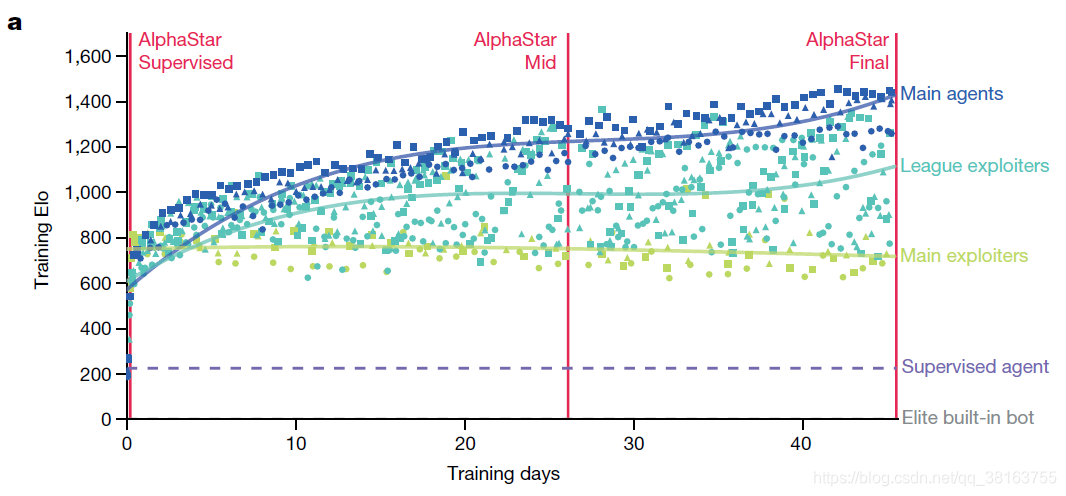
从a图中可以得到一些结论:
(1) 对于每种类型的agent,他们的实力不断增加,与早期模型的胜率更高;
(2) 对于每一种类型的exploiter,不断训练使他们与 MA 相比具有持续的竞争力(回想一下 AEE 的工作机制);AlphaStar中的收益矩阵表明,随着训练的进行,它的 ME 很少能赶上它的 MA;
(3)DAPO激活后所有agent的强度均有显着提高。
图b显示了联盟中agent的 ELO 分数,MA 持续改进,而随着训练的进行,exploiter也可以赶上 MA。很明显,DAPO 激活后显着促进了策略改进。
Key Components Evaluation in League Training
AlphaStar Surrogate由one MA (assigned with 32 GPUs), two MEs (each with 16 GPUs), and two LEs (each with 16
GPUs)组成。作者使用不同的设置与其比较,找到关键组件。通过Relative Population Performance(RPP)比较两个league,即两个league之间nash解的payoff值,具体是两两对战100次,z-stat遵循训练的设置。
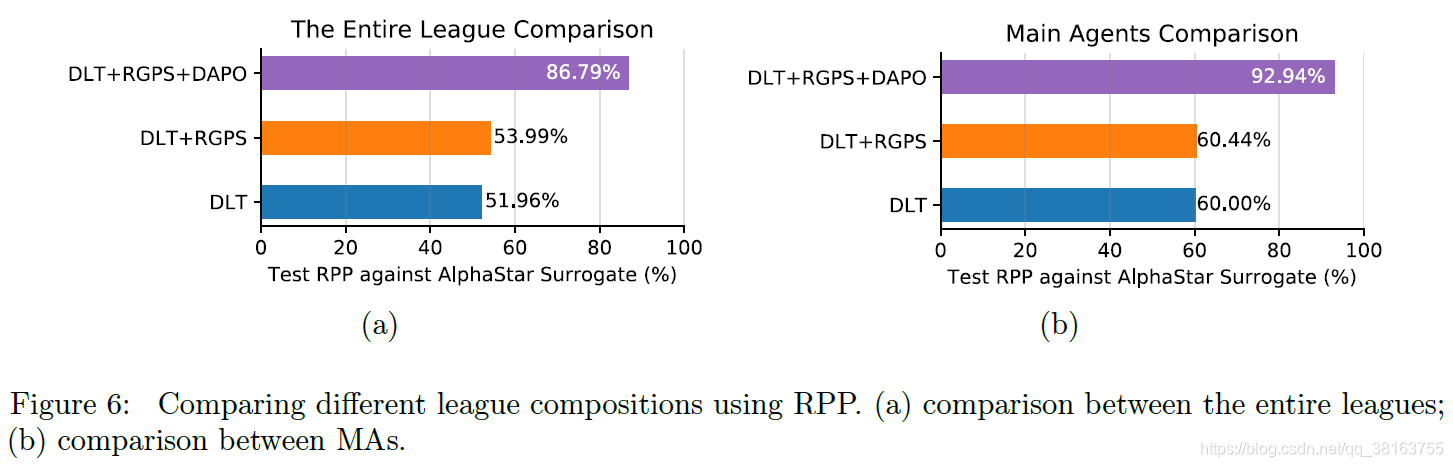
通过使用DLT,虽然整个联盟的RPP仅略高于AlphaStar Surrogate,但MA的RPP明显增加,表明DLT中的MA比AlphaStar Surrogate中的MA更健壮和强大。DLT整个联盟RPP提升不明显也就不足为奇了,因为联盟训练初期,MA不强,AEE很容易追上MA;然后,根据 AEE 的方案,这些exploiter重置为其监督的agent,因此行为类似于 ME 和 LE;此外,在 DLT 中,每个exploiter只分配了 8 个 GPU,因此与 AlphaStar Surrogate 中的 ME 和 LE 相比,他们的策略提升是有限的。然而,DLT 产生的多样性导致更强大的 MA。
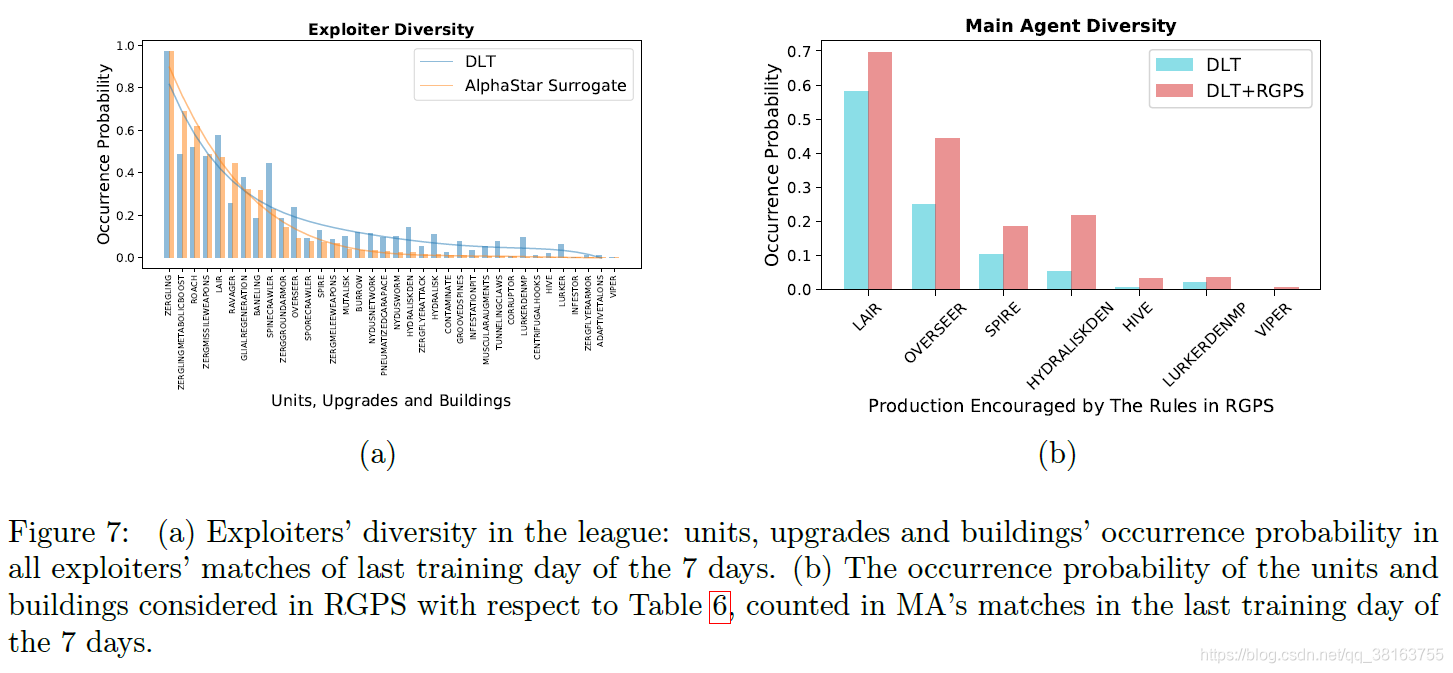
该图显示了在训练最后一天的所有训练比赛中,大多数主要虫族单位、升级和建筑的出现概率。从图中可以看出,DLT 中的exploiter表现出非常多样化的单位、升级和建筑,而 AlphaStar Surrogate 的非零数量主要集中在左侧。通过添加 RGPS,我们还观察到联赛和 MA 比较的 RPP 略有提高,以 DLT 为参考。 RPP 值略有增加也不足为奇,因为 RGPS 中考虑的临界状态很少(见表 6)。然而,在考虑这些临界状态时,图 7(b) 表明 RGPS 确实符合策略中的这些规则,以提高这些相关操作的概率。最后,在加入 DAPO 后,对于联赛和 MA 的比较,针对 AlphaStar Surrogate 的 RPP 值显着增加,表明 DAPO 在促进政策改进方面的有效性。
Other Results
Build-in Bots Evaluation
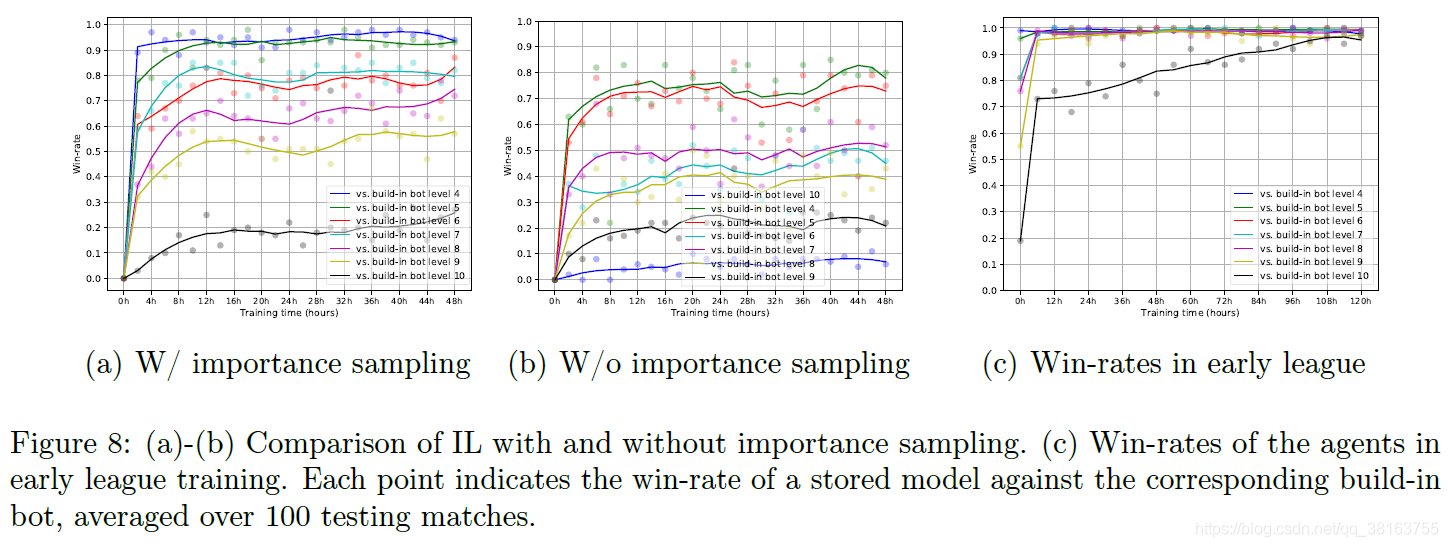
主要观察IL和早期league的ma跟built-in bot的性能比较。
每个点表示 100 场比赛的平均胜率,agent从174 人的回放子集中随机采样 z-stat,获胜者在Kairos Junction 地图上的 MMR>6200。对于消融研究,也提供了去除重要性采样的训练曲线。显然,使用原始数据分布训练agent会显着降低性能。
同样观察到增强的agent可以持续提高其对抗built-in bot的性能,尽管它在联盟训练中从未遇到过它们中的任何一个。
Opponent Matching Status in League Training

图为正式实验最后一天全联盟MA的对手匹配情况。生成了 583 个agent,每个agent在图中用条形表示。ID 由父 ID 和后代 ID 组成,用冒号分隔。如果父 ID 为“无”,则表示该模型是初始模型之一。条形值表示当时训练 MA 对联盟中所有其他代理的胜率。绿色条组(顶部子图的右侧)表示历史中生成的所有 MA,最右侧的是正在训练的 MA。所有其他彩色条表示各种exploiter。以相同颜色排列的一组条形表示一个不断发展的agent分支。 正如我们所观察到的,除了少数最近的开发者之外,训练 MA 几乎可以以0.5的胜率击败所有历史代理。
Diversity in Supervised Models and MA’s Counter Strategies
IL 中,在 6 个人类回放子集上微调了 K = 6 个监督模型。经过尝试,这些策略相对更具竞争力。与 Elite-bot 对战100 次进行评估。结果表明,使用不同的回放子集对模型进行微调在经验上是有效的,可以提供初始多样性。
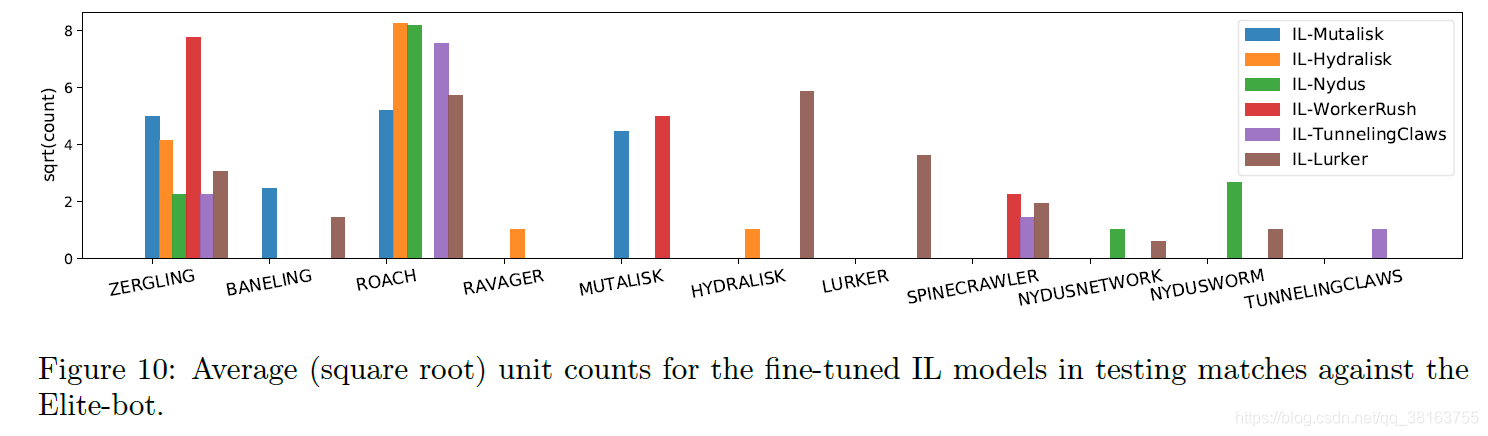
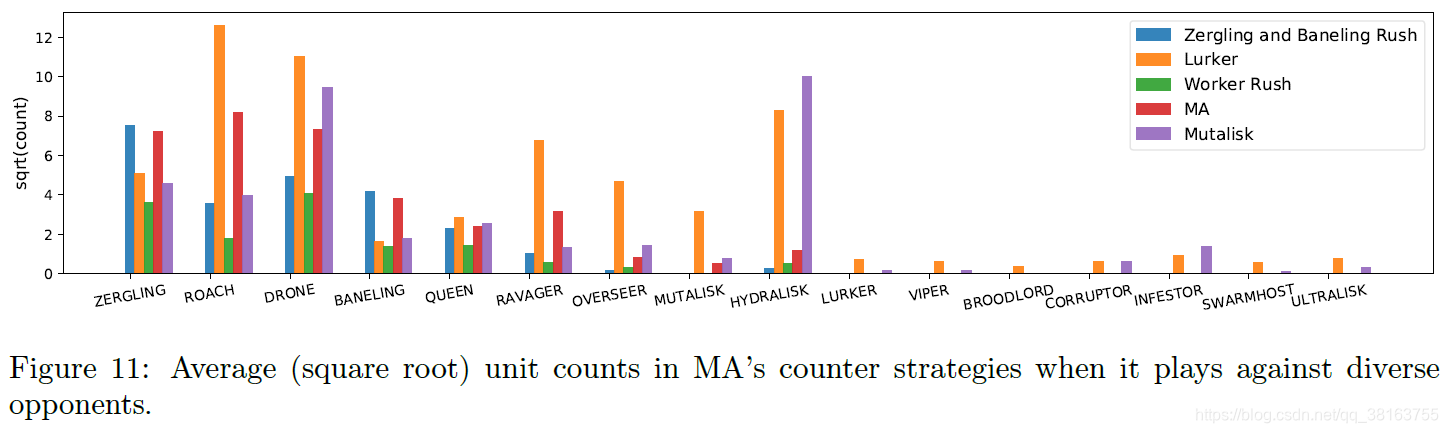
然后作者使用不同策略的exploiter与ma对战,发现ma可以使用不同的反策略做出对应,体现了鲁棒性。
Infrastructure Comparison
作者使用具有 144 个 Tesla V100 GPU 和 13,440 个 CPU 内核的分布式learner-actor基础设施。在正式实验中,96 个 GPU 用于训练,其余 GPU 用于推理。通常,分配 32 个 GPU 用于训练 MA,64 个 GPU 交替分配给不同的exploiter。每个训练 GPU 分配有 70 个actor,运行 70 个并发比赛,每个actor分配有 2 个 CPU 内核。使用的GPU和CPU总数如前言中的表所示,所有计算资源均部署在腾讯云上。
在作者的基础设施中,数据消耗速度为 210 fps/GPU,每个 GPU 的重放缓冲区以 43 fps 的速度接收数据。也就是说,每个数据点将平均使用五次。
在 AlphaStar 的基础设施中,其消耗速度为 390 fps/TPU 核,数据生成速度为 195 fps,每个数据样本在其重放缓冲区中使用两次。
从整个联盟的训练来看,AlphaStar在联盟中的总消耗/生成速度大约是TStarBot-X的30/73倍。
Discussion and Conclusion
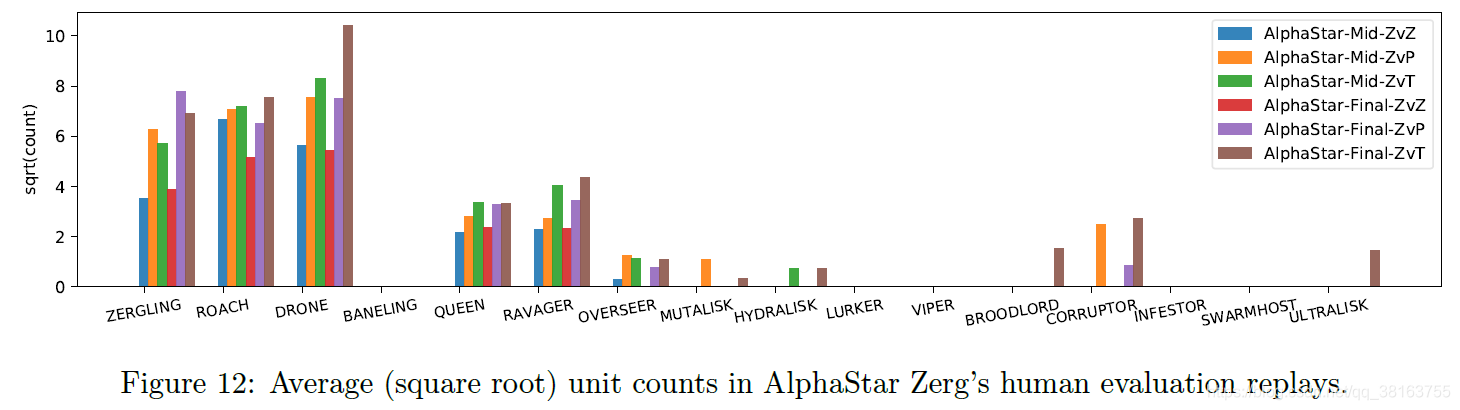
作者解析了 AlphaStar 的所有人类评估回放,在所有 Zerg vs. Zerg (ZvZ) 比赛中,AlphaStar 的 Zerg agent 似乎更喜欢使用只产生 Roach、Zergling、Ravager 和 Queen 的特定策略。只有在 Zerg vs. Terran (ZvT) 和 Zerg vs. Protoss (ZvP) 比赛中才能观察到其他一些单位。尽管这些统计数据可能与 AlphaStar 的训练分布有偏差,但它可能表明:
- 在 ZvZ 游戏中探索和保持多样性(在单一策略中)是困难的;
- 三个种族联合训练,可以提升联赛的多样性。
TStarBot-X 在单一策略中拥有更多样化的联盟和更具战略性的多样性,即使它是在更小规模的计算和 ZvZ 设置下进行训练的。但是从人类玩家大师的评价来看,TStarBot-X不擅长多任务和反多任务。
总的来说,作者详细研究了在有限的计算资源规模下在 SC2 中训练有竞争力的 AI 代理。
该研究表明
- 当计算不足以在复杂问题中进行足够的探索时,多样化的联赛训练与作者提出的agent角色混合可能是提供联盟多样性的更有效方式;
- 规则引导的策略搜索是将人类知识融合到神经网络中以避免繁琐探索的有效方式;
- agent级别的DAPO可以显着增强策略改进。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









