






 本文详细剖析了ArrayList的内部构造,包括其继承关系、构造方法、数组容量管理、元素添加、删除、更新、查找等核心操作的实现原理。
本文详细剖析了ArrayList的内部构造,包括其继承关系、构造方法、数组容量管理、元素添加、删除、更新、查找等核心操作的实现原理。
ArrayList是JAVA里可以说是使用的最多的集合了,一直都是直接拿来用还没怎么研究过他的内部构造,所以一直想找个机会把他好好研究研究。
首先来看一下ArrayList的继承关系图
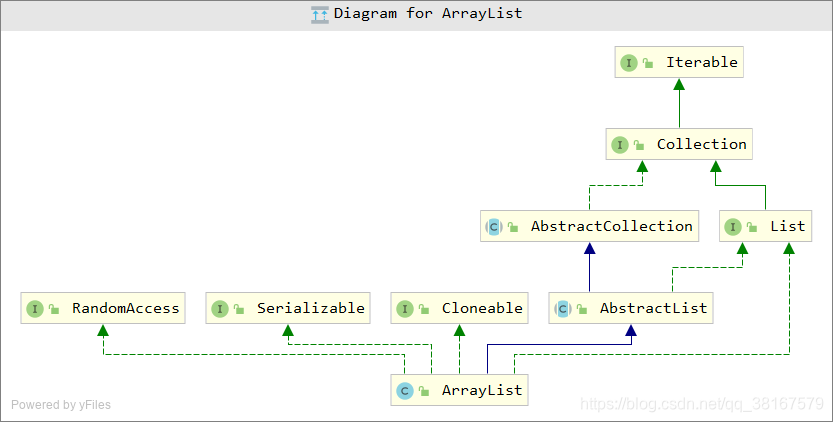
其中RandomAccess,Cloneable,Serializable都是标记接口,暂时不去管它。
一般来说,我们要使用某个对象的话,都要去new一下他。所以我们先来看他的构造方法是怎样的。
// 数组默认容量
private static final int DEFAULT_CAPACITY = 10;
// 默认空数组
private static final Object[] EMPTY_ELEMENTDATA = {};
// 默认空数组
private static final Object[] DEFAULTCAPACITY_EMPTY_ELEMENTDATA = {};
// 存放数据的数组
transient Object[] elementData; // non-private to simplify nested class access
// 数组中元素个数
private int size;
public ArrayList(int initialCapacity) {
if (initialCapacity > 0) {
this.elementData = new Object[initialCapacity];
} else if (initialCapacity == 0) {
this.elementData = EMPTY_ELEMENTDATA;
} else {
throw new IllegalArgumentException("Illegal Capacity: "+initialCapacity);
}
}
public ArrayList() {
this.elementData = DEFAULTCAPACITY_EMPTY_ELEMENTDATA;
}
// c == null , thorw NPE
public ArrayList(Collection<? extends E> c) {
elementData = c.toArray();
if ((size = elementData.length) != 0) {
if (elementData.getClass() != Object[].class)
elementData = Arrays.copyOf(elementData, size, Object[].class);
} else {
this.elementData = EMPTY_ELEMENTDATA;
}
}
可以看到,ArrayList内部维护了三个Object的数组,其中两个是默认的空数组一个是真正要存放数据的数组(elementData)。
1.默认构造函数设置elementData指向DEFAULTCAPACITY_EMPTY_ELEMENTDATA
2.带初始化容量的构造函数会判断传入的容量,如果是负数就报异常,如果是0则elementData指向EMPTY_ELEMENTDATA,否则elementData让其指向新new出来的指定容量的Object数组。
3.带集合参数的构造函数,将elementData指向集合转换出的数组,判断是否是空数组,是则将elementData指向EMPTY_ELEMENTDATA,否则先判断是否是Object数组,不是就转换为Object数组。
在这里其实有个小疑惑,DEFAULTCAPACITY_EMPTY_ELEMENTDATA 和 EMPTY_ELEMENTDATA不是一样的吗?为什么要设置两个呢?
ArrayList创建出来之后,就开始使用了。第一件事就是往里面加东西,先看最常用的add方法。
// 继承自AbstractList,用于记录ArrayList的变更数
protected transient int modCount = 0;
public boolean add(E e) {
ensureCapacityInternal(size + 1); // Increments modCount!!
elementData[size++] = e;
return true;
}
// 确保数组容量够用
private void ensureCapacityInternal(int minCapacity) {
ensureExplicitCapacity(calculateCapacity(elementData, minCapacity));
}
// 计算数组所需最小容量
private static int calculateCapacity(Object[] elementData, int minCapacity) {
if (elementData == DEFAULTCAPACITY_EMPTY_ELEMENTDATA) {
return Math.max(DEFAULT_CAPACITY, minCapacity);
}
return minCapacity;
}
// 确定数组容量
private void ensureExplicitCapacity(int minCapacity) {
modCount++;
// overflow-conscious code
if (minCapacity - elementData.length > 0)
grow(minCapacity);
}
// 扩容
private void grow(int minCapacity) {
// overflow-conscious code
int oldCapacity = elementData.length;
int newCapacity = oldCapacity + (oldCapacity >> 1);
if (newCapacity - minCapacity < 0)
newCapacity = minCapacity;
if (newCapacity - MAX_ARRAY_SIZE > 0)
newCapacity = hugeCapacity(minCapacity);
// minCapacity is usually close to size, so this is a win:
elementData = Arrays.copyOf(elementData, newCapacity);
}
// 数组最大容量
private static final int MAX_ARRAY_SIZE = Integer.MAX_VALUE - 8;
// 超大数组的容量计算
private static int hugeCapacity(int minCapacity) {
if (minCapacity < 0) // overflow
throw new OutOfMemoryError();
return (minCapacity > MAX_ARRAY_SIZE) ?
Integer.MAX_VALUE :
MAX_ARRAY_SIZE;
}
可以看出,在添加元素之前,要先确保数组容量够用。目前所需的最小容量minCapacity=size+1,如果是使用无参构造函数new出来且是第一次添加元素的话,就取Max.min(size+1, DEFAULT_CAPACITY),否则直接取size+1。这里可以解释一下为什么要设置两个一样的空数组了。在确定最小容量之后,modCount都会+1,因为无论是否扩容都要算一次数组的变更(添加进一个元素)。判断当前数组容量是否比所需最小容量要小,如果要小说明需要扩容了。
扩容操作也比较简单,新容量newCapacity=Math.max(minCapacity,oldCapacity*1.5),还需判断是否是超大容量,是的话则newCapacity=minCapacity>MAX_ARRAY_SIZE ? Integer.MAX_VALUE : MAX_ARRAY_SIZE,这里可以看出ArrayList的最大容量是Integer.MAX_VALUE。确定了newCapacity之后,再调用拷贝数组的方法,把原数组拷贝到容量更大的数组中去,就完成了一次扩容。
再回到add方法,可以发现扩容和维护modCount都是在ensureCapacityInternal方法中,所以只要调用了这个方法后就能安心的执行elementData[size++]=e,把元素添加进来了。
简单的add方法看完之后,再看看其他的添加元素方法。
public void add(int index, E element) {
rangeCheckForAdd(index);
ensureCapacityInternal(size + 1); // Increments modCount!!
System.arraycopy(elementData, index, elementData, index + 1,
size - index);
elementData[index] = element;
size++;
}
// index range is [0,size]
private void rangeCheckForAdd(int index) {
if (index > size || index < 0)
throw new IndexOutOfBoundsException(outOfBoundsMsg(index));
}
指定下标添加元素,相比add方法多了一个对下标的合法性校验,保证不能在空位置插入。以及直接的数组拷贝方法,原因就是扩容操作只能保证新增加的元素有位置存放,并不能保证能存放到你传入的index的位置,所以需要把在index及之后的元素整体向右偏移一位,就是把index的位置留出来,然后将新元素放置到index位置。
除了添加单个元素外,还可以添加多个元素。
// c == null, throw NPE
public boolean addAll(Collection<? extends E> c) {
Object[] a = c.toArray();
int numNew = a.length;
ensureCapacityInternal(size + numNew); // Increments modCount
System.arraycopy(a, 0, elementData, size, numNew);
size += numNew;
return numNew != 0;
}
// c == null, throw NPE
public boolean addAll(int index, Collection<? extends E> c) {
rangeCheckForAdd(index);
Object[] a = c.toArray();
int numNew = a.length;
ensureCapacityInternal(size + numNew); // Increments modCount
int numMoved = size - index;
if (numMoved > 0)
System.arraycopy(elementData, index, elementData, index + numNew,
numMoved);
System.arraycopy(a, 0, elementData, index, numNew);
size += numNew;
return numNew != 0;
}
先看第一个addAll,很容易理解无非就是minCapacity=size+c.size,然后调用确保数组容量够用的方法,然后把集合里的元素全都复制到elementData后面去。
再看指定位置插入的addAll,相较于第一个addAll多了一步操作,就是如果传入的集合不为空的话呢,就先在指定index的位置整体向右偏移c.size个位置,把空间留出来,再把新元素复制进来。
看完了添加操作之后,再看一下更新操作。
public E set(int index, E element) {
rangeCheck(index);
E oldValue = elementData(index);
elementData[index] = element;
return oldValue;
}
// index range is [0, size-1]
// 只有这个区间有元素,属于元素存放区
private void rangeCheck(int index) {
if (index >= size)
throw new IndexOutOfBoundsException(outOfBoundsMsg(index));
}
private String outOfBoundsMsg(int index) {
return "Index: "+index+", Size: "+size;
}
public void replaceAll(UnaryOperator<E> operator) {
Objects.requireNonNull(operator);
final int expectedModCount = modCount;
final int size = this.size;
for (int i=0; modCount == expectedModCount && i < size; i++) {
elementData[i] = operator.apply((E) elementData[i]);
}
if (modCount != expectedModCount) {
throw new ConcurrentModificationException();
}
modCount++;
}
set操作比较简单,就是先校验index的合法性,然后替换新元素,再把旧元素返回出去。
replaceAll方法是从1.8开始的,UnaryOperator的lambda表达式就是t -> r,即传入T类型,返回R类型,即你可以把T类型转变成R类型。replaceAll方法逻辑比较简单,就是遍历数据区间,对每一个元素都执行转换,然后判断modCount==expectedModCount来保证只有当前线程对数组进行了更改,最后维护modCount++;
数组中有元素了之后,当然就能删除元素啦。
public E remove(int index) {
// index range is [0,size-1]
rangeCheck(index);
modCount++;
E oldValue = elementData(index);
int numMoved = size - index - 1;
if (numMoved > 0)
System.arraycopy(elementData, index+1, elementData, index,
numMoved);
elementData[--size] = null; // clear to let GC do its work
return oldValue;
}
E elementData(int index) {
return (E) elementData[index];
}
public boolean remove(Object o) {
if (o == null) {
for (int index = 0; index < size; index++)
if (elementData[index] == null) {
fastRemove(index);
return true;
}
} else {
for (int index = 0; index < size; index++)
if (o.equals(elementData[index])) {
fastRemove(index);
return true;
}
}
return false;
}
// 不校验边界的快速删除
private void fastRemove(int index) {
modCount++;
int numMoved = size - index - 1;
if (numMoved > 0)
System.arraycopy(elementData, index+1, elementData, index,
numMoved);
elementData[--size] = null; // clear to let GC do its work
}
// 清空
public void clear() {
modCount++;
// clear to let GC do its work
for (int i = 0; i < size; i++)
elementData[i] = null;
size = 0;
}
// c: 待删除的元素集合
public boolean removeAll(Collection<?> c) {
Objects.requireNonNull(c);
return batchRemove(c, false);
}
// c: 待保留的元素集合
// 即 elementData-c.toArray
public boolean retainAll(Collection<?> c) {
Objects.requireNonNull(c);
return batchRemove(c, true);
}
// complement: true - 存在则保留, false - 存在则删除
private boolean batchRemove(Collection<?> c, boolean complement) {
final Object[] elementData = this.elementData;
// r is readIndex, w is writeIndex
int r = 0, w = 0;
boolean modified = false;
try {
for (; r < size; r++)
if (c.contains(elementData[r]) == complement)
elementData[w++] = elementData[r];
} finally {
// Preserve behavioral compatibility with AbstractCollection,
// even if c.contains() throws.
if (r != size) {
System.arraycopy(elementData, r,
elementData, w,
size - r);
w += size - r;
}
if (w != size) {
// clear to let GC do its work
for (int i = w; i < size; i++)
elementData[i] = null;
modCount += size - w;
size = w;
modified = true;
}
}
return modified;
}
public boolean removeIf(Predicate<? super E> filter) {
Objects.requireNonNull(filter);
// figure out which elements are to be removed
// any exception thrown from the filter predicate at this stage
// will leave the collection unmodified
int removeCount = 0;
// 存储待删除的index
final BitSet removeSet = new BitSet(size);
final int expectedModCount = modCount;
final int size = this.size;
for (int i=0; modCount == expectedModCount && i < size; i++) {
@SuppressWarnings("unchecked")
final E element = (E) elementData[i];
if (filter.test(element)) {
// 在待删除的index处设置true
removeSet.set(i);
removeCount++;
}
}
if (modCount != expectedModCount) {
throw new ConcurrentModificationException();
}
// 把需要保留的元素左移
final boolean anyToRemove = removeCount > 0;
if (anyToRemove) {
final int newSize = size - removeCount;
for (int i=0, j=0; (i < size) && (j < newSize); i++, j++) {
// 从i开始获取下一个为false的index
i = removeSet.nextClearBit(i);
elementData[j] = elementData[i];
}
for (int k=newSize; k < size; k++) {
elementData[k] = null; // Let gc do its work
}
this.size = newSize;
if (modCount != expectedModCount) {
throw new ConcurrentModificationException();
}
modCount++;
}
return anyToRemove;
}
先看指定下标删除元素方法remove(index),既然指定了下标那免不了要对下标进行一次校验,保证下标在[0,size-1],因为只有这个区间才有元素。然后维护modCount+1,由于最后要返回旧值所以拿个引用指向index位置的值。再把数组从index位置开始整体向左移一位(注意:这里是整体复制,所以原最后一位的元素并没有被删除),维护size--,把最后一位元素置为null。
再看指定元素删除方法remove(o),很明显都已经指定元素了,那我直接在[0,size-1]这个区间遍历就可以了,由于不需要考虑边界问题,所以调用了fastRemove方法,逻辑和remove方法类似,只需要删除找到的第一个元素即可。
clear方法,清除所有元素,直接把[0,size-1]这个区间的元素全部置null,再维护modCount和size就可以了。
相对复杂的就是批量删除了,包含removeAll和retainAll方法,可以看到其实最终调用的都是batchRemove方法,其中参数complement用于保证以下逻辑,为true:集合中存在就保留;为false:集合中存在就删除;r(readIndex),w(writeIndex)用于元素的替换,r 代表遍历的下标,w 代表最终的数据只需要[0,writeIndex],其他的地方全部置null。
遍历数据区间,找到需要保留的数据(complement为true时,c中存在则保留;为false时,c中不存在则保留),从0开始一个个替换,直到遍历完数据区间。由于传入的是一个collection,所以其contains方法可能抛出异常,所以使用了try-finally语句块来保证代码一定会执行。
如果 r!= size 说明contains异常了数据区间没有遍历完整,那么就把未遍历的数据直接复制到writeIndex,writeIndex+=未遍历的数据长度;否则不做任何操作;同样的,w != size 说明有元素被删除了,那么把writeIndex及之后的数据区间的元素全部置null,再维护modCount和size就好了。这样就完成了一次批量的数据删除。
removeIf(Predicate<? super E> filter)方法是1.8新增的,提供了方便的判断来对数组中的元素进行删除;可以看到其使用了一个BitSet来存储要删除元素所在的index,即在这个index处设置为true; 在遍历数据区间时每次都要判断modCount==expectedModCount就是为了保证这次操作只有一个线程在使用,如果有其他的线程使用就会停止循环然后抛异常,所以可以看到ArrayList并不是线程安全的。
循环完之后就标记好了要删除元素的下标已经确定了要删除元素的个数removeCount,根据它可以推算出newSize。再来执行一次数据区间的遍历,把数据复制一份。其中最重要的就是i = removeSet.nextClearBit(i)这一句话,意思是跳过要删除的元素去到它下一个要保留的元素,因为在要删除的index处标记的是true,这个方法意思是说从 i 开始,找到下一个标记为false的index,这样就相当于跳过了要删除的index,把下一个要保留的元素对这个index进行了覆盖。最后将newSize之后的区间数据全部置null,维护一下modCount就好了。
增删改操作都看完了,最简单的就是查了。
public E get(int index) {
// index range is [0,size-1]
rangeCheck(index);
// (E)elementData[index]
return elementData(index);
}
public boolean contains(Object o) {
return indexOf(o) >= 0;
}
// 继承自AbstarctCollection
public boolean containsAll(Collection<?> c) {
for (Object e : c)
if (!contains(e))
return false;
return true;
}
public int indexOf(Object o) {
if (o == null) {
for (int i = 0; i < size; i++)
if (elementData[i]==null)
return i;
} else {
for (int i = 0; i < size; i++)
if (o.equals(elementData[i]))
return i;
}
return -1;
}
public int lastIndexOf(Object o) {
if (o == null) {
for (int i = size-1; i >= 0; i--)
if (elementData[i]==null)
return i;
} else {
for (int i = size-1; i >= 0; i--)
if (o.equals(elementData[i]))
return i;
}
return -1;
}
get方法很简单,校验index是否属于元素存放区间,是则直接通过下标获取返回。
contains(o)调用的是indexOf(o)方法,indexOf(o)其实和remove(o)方法很类似,一个是删除后返回true,一个是直接返回下标。
containsAll(c)继承自AbstarctCollection,循环调用的是indexOf(o)方法,有一个false则为false。
lastIndexOf(o)和indexOf(o)类似,区别在于一个是从[0,size-1]遍历,一个是从[size-1,0]遍历而已。
增删改查都看完了,再看一下ArrayList中其他相对简单,但却少用的功能。
public void trimToSize() {
modCount++;
if (size < elementData.length) {
elementData = (size == 0)
? EMPTY_ELEMENTDATA
: Arrays.copyOf(elementData, size);
}
}
trimToSize方法,简而言之就是把数组缩减到只留下数据区间,其他的空间全部删除。实现方式就是判断元素是否为0,是则直接将elementData指向EMPTY_ELEMENTDATA,否则把数据区间拷贝到容量为size的新数组中,再让elementData指向这个新数组。
// 浅拷贝
public Object clone() {
try {
ArrayList<?> v = (ArrayList<?>) super.clone();
v.elementData = Arrays.copyOf(elementData, size);
v.modCount = 0;
return v;
} catch (CloneNotSupportedException e) {
// this shouldn't happen, since we are Cloneable
throw new InternalError(e);
}
}
clone方法,对ArrayList进行一次复制,首先复制当前对象,调用Object的clone方法,再复制elementData数组,注意这里的复制时浅拷贝,不是深拷贝!!
public void sort(Comparator<? super E> c) {
final int expectedModCount = modCount;
Arrays.sort((E[]) elementData, 0, size, c);
if (modCount != expectedModCount) {
throw new ConcurrentModificationException();
}
modCount++;
}
sort方法,调用Arrays.sort方法对数组进行排序;需要维护modCount++;
public Object[] toArray() {
return Arrays.copyOf(elementData, size);
}
public <T> T[] toArray(T[] a) {
if (a.length < size)
// Make a new array of a's runtime type, but my contents:
return (T[]) Arrays.copyOf(elementData, size, a.getClass());
System.arraycopy(elementData, 0, a, 0, size);
if (a.length > size)
a[size] = null;
return a;
}
toArray()方法,把集合转换为数组;直接把elementData拷贝一份返回,浅拷贝;
toArray(T[] a)方法,把elementData中的数据拷贝到a数组中,并返回a数组,浅拷贝;
到此为止,ArrayList的一些常用的方法的源码就读完了。还有iterator,subList等稍微复杂的方法,由于代码较多,就放在下一篇中再读吧。

















 7127
7127

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









