







目录
一、NLP基本介绍
NLP(Natural Language Processing)是一种人工智能和语言学领域的交叉学科,旨在让计算机能够理解和生成人类的语言,实现人机之间的自然交流。
其具体定义为:自然语言处理(Natural Language Processing, NLP)是利用计算机科学、人工智能和语言学的理论和方法,研究如何让计算机能够“听懂”人类的语言,并实现与之无障碍交流的技术。
其目标为:使计算机能够理解、处理、生成和模拟人类语言,从而执行语言翻译、情感分析、文本摘要等任务。

二、NLP的常见应用场景
自然语言处理(NLP)技术是人工智能领域的一个重要分支,它致力于让计算机能够理解和生成人类语言。以下是一些常见的NLP应用场景及其具体描述和示例:
-
机器翻译:机器翻译是NLP技术中最为人所熟知的场景之一。通过将输入的源语言文本自动翻译成另一种语言的文本,NLP技术极大地促进了国际交流、商务合作和跨文化沟通。例如,百度翻译、Google翻译等在线翻译工具就是基于NLP技术开发的,它们能够实现多种语言之间的实时翻译。
-
情感分析:情感分析是NLP的一个子领域,它涉及识别和分类文本中的主观信息,如情感倾向(积极、消极或中性)。这一技术在市场研究、品牌监控和社交媒体分析中尤为重要。企业可以利用情感分析来了解消费者对其产品或服务的看法,从而及时调整市场策略和改进产品。
-
聊天机器人与虚拟助手:聊天机器人和虚拟助手是NLP技术的又一重要应用。这些系统能够理解用户的自然语言输入,并提供相应的回答或执行任务。在客户服务、在线购物和个人助理等领域,聊天机器人已经得到了广泛应用。例如,Siri、Alexa、Google Assistant等智能语音助手就是基于NLP技术开发的,它们能够与用户进行自然语言交流,提供各种便捷服务。
-
文本摘要与内容提取:NLP技术还可以自动生成文本的摘要,这对于快速获取大量信息的概要非常有用。文本摘要在新闻聚合、研究论文阅读和企业报告中具有极高的实用价值。通过自动提炼文档核心信息,NLP技术帮助用户快速抓住文章的主旨和要点,提高工作效率。
-
智能客服:智能客服是一个广泛应用NLP技术的领域。利用NLP技术,智能客服系统能够理解客户提出的问题,并提供准确的解答,从而提高了客服质量。这些系统还可以实时处理大量客户查询,降低了等待时间,增加了效率。
-
搜索引擎优化:在搜索引擎领域,NLP技术扮演着至关重要的角色。通过分析用户的查询意图和网页内容,NLP技术能够更准确地匹配搜索词和网页内容,从而提供更为相关和精准的搜索结果。这种技术的应用不仅提高了搜索效率,还极大地提升了用户体验。
-
医疗健康与法律领域:在医疗健康领域,NLP技术被用于电子健康记录的分析、临床决策支持和患者交流。通过自动提取病历文档中的关键信息,NLP技术为医生提供了更为全面和准确的诊断依据。在法律领域,NLP技术则被用来分析法律文件、合同和案例,以辅助法律专业人士进行研究和决策。
总之,随着技术的不断进步和应用领域的不断拓展,NLP将在未来的人工智能领域中发挥更加重要的作用,为人类社会带来更多的便利和创新。
三、NLP领域中的数据
3.1 概述
自然语言领域的核心数据是序列数据,这是一种在样本与样本之间存在特定顺序、且这种特定顺序不能被轻易修改的数据。这是什么意思呢?在机器学习和普通深度神经网络的领域中我们所使用的数据是二维表。如下所示,在普通的二维表中,样本与样本之间是相互独立的,一个样本及其特征对应了唯一的标签,因此无论我们先训练1号样本、还是先训练7号样本、还是只训练数据集中的一部分样本,都不会从本质上改变数据的含义、许多时候也不会改变算法对数据的理解和学习结果。
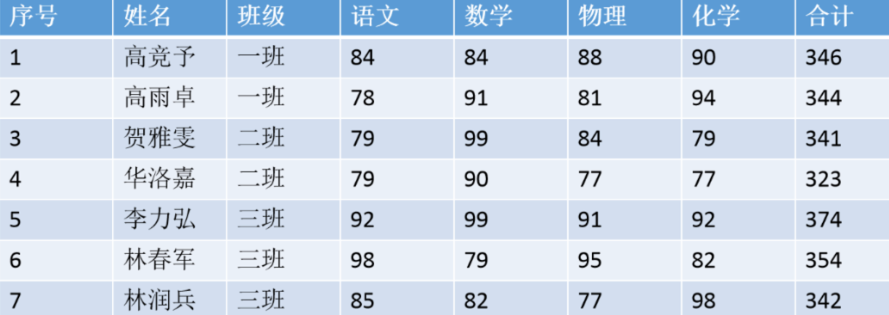
但序列数据则不然,对序列数据来说,一旦调换样本顺序或样本发生缺失,数据的含义就会发生巨大变化。最典型的序列数据有以下几种类型:
-
文本数据(Text Data):文本数据中的样本的“特定顺序”是语义的顺序,也就是词与词、句子与句子、段落与段落之间的顺序。在语义环境中,词语顺序的变化或词语的缺失可能会彻底改变语义,例如——
改变顺序:事半功倍和事倍功半;曾国藩战太平天国时非常著名的典故:他将“屡战屡败”修改为“屡败屡战”,前者给人绝望,后者给人希望。
样本缺失(对文本来说特指上下文缺失):小猫睡在毛毯上,因为它很。当我们在横线上填上不同的词(暖/冷)时,句子的含义会发生变化。
-
音频数据(Audio Data):音频数据大部分时候是文本数据的声音信号,此时音频数据中的“特定顺序”也是语义的顺序;当然,音频数据中的顺序也可能是音符的顺序,试想你将一首歌的旋律全部打乱再重新播放,那整首歌的旋律和听感就会完全丧失。
-
视频数据(Video Data):你知道动画是由一张张原画构成的吗?视频数据本质就是由一帧帧图像构成的,因此视频数据是图像按照特定顺序排列后构成的数据。和音频数据类似,如果将动画或电影中的画面顺序打乱再重新播放,那没有任何人能够理解视频的内容。
很明显,在处理序列数据时,我们不仅要让算法理解每一个样本,还需要让算法学习到样本与样本之间的联系。
3.2 序列数据的结构
序列数据的概念很容易理解,但奇妙的是,现实中的序列数据可以是二、三、四、五任意维度,只要给原始的数据加上“时间顺序”或“位置顺序”,任意数据都可以化身为序列数据。在这里,我们展现几种常见的序列数据:
二维时间序列
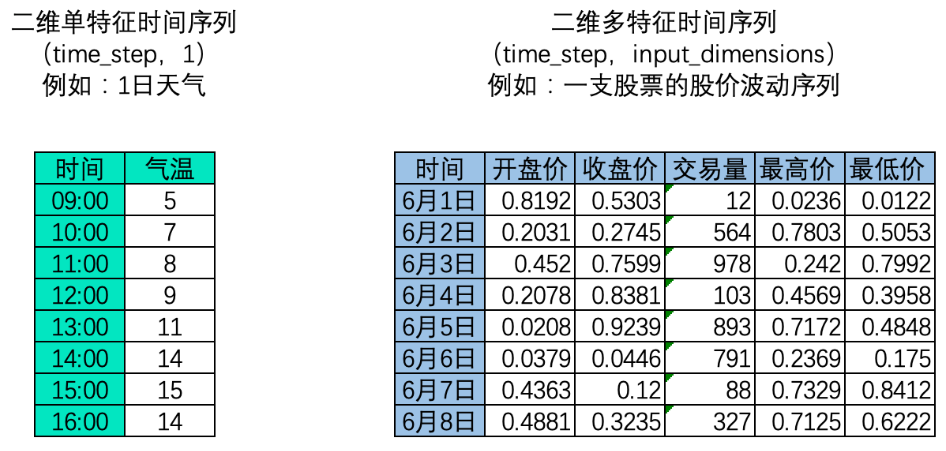
时间序列中,样本与样本之间的顺序是时间顺序,因此每个样本是一个时间点,时间顺序也就是time_step这一维度上的顺序。这种顺序在自然语言处理领域叫做“时间步”(time_step),也被叫做“序列长度”,这正是我们要求算法必须去学习的顺序。在时间序列数据中,时间点可以是任意时间单位(分钟、小时、天),但时间点与时间点之间的间隔必须是一致的。
三维时间序列
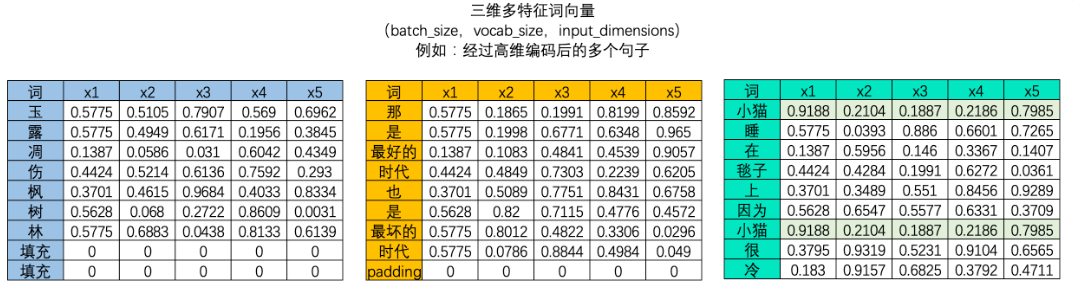
在NLP领域中,我们常常一次性处理多个时间序列,如下图所示,我们可以一次性处理多支股票的股价波动序列。
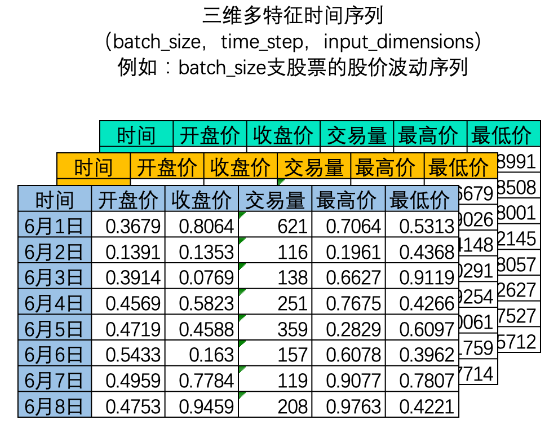
此时我们拥有的是一个三维矩阵,其中batch_size是样本量,也就是一共有多少个二维时间序列表单。因为深度学习算法会同时处理多个内在逻辑相同的时间序列。其中time_step和input_dimension决定了一个时间序列的序列长度和特征量,而batch_size决定了整个数据集中一共有多少个二维时间序列表单。这些二维表单堆叠在一起,构成深度学习算法输入所必备的三维时间序列。
二维文字序列
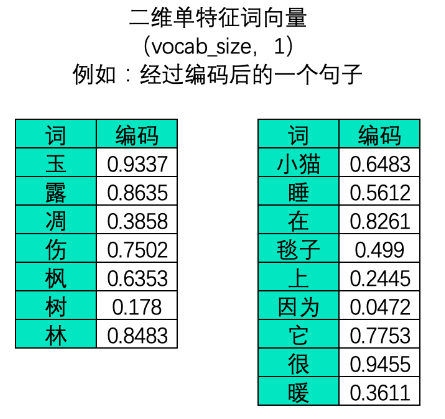
在文字数据中,样本与样本之间的联系大部分时候是词与词、字与字之间的联系,因此在文字序列中每个样本是一个单词或一个字(对英文来说大部分时候是一个单词,偶尔也可以是一个字母),故而在中文文字数据中,一张二维表往往是一个句子或一段话。此时,不能够打乱顺序的维度是vocab_size,它代表了一个句子 /一段话中的字词总数量。一个句子或一段话越长,vocab_size也就会越大,因此这一维度的作用与时间序列中的time_step一致,vocab_size在许多时候也被称之为是序列长度(sequence_length)。同样,vocab_size这一维度上的顺序就是算法需要学习的顺序。
需要注意的是,文字序列是不能直接放入算法进行运行的,必须要要编码成数字数据才能供算法学习,因此在NLP领域中我们大概率会将文字数据进行编码。编码的方式有很多种,但无一例外的,文字编码的本质是用单一数字或一串数字的组合去代表某个字/词,在同一套规则下,同一个字会被编码为同样的序列或同样的数字,而使用一个数字还是一串数字则可以由算法工程师自行决定。下图是对句子分别进行embedding编码和独热编码后产生的二维表单:
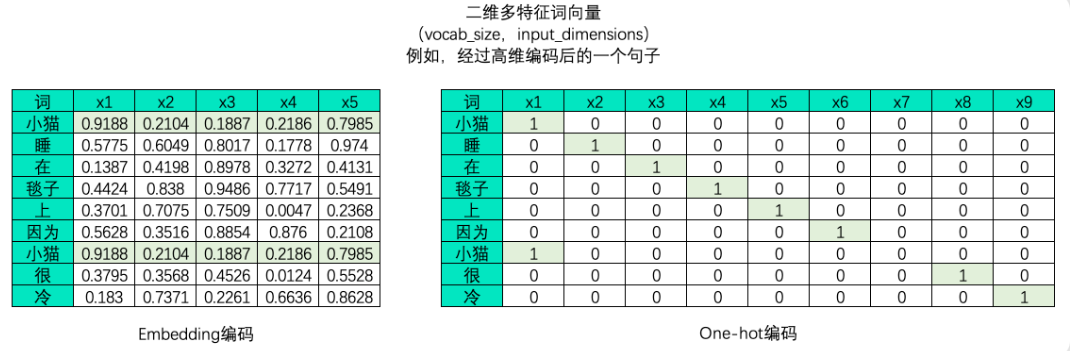
大部分时候,我们需要学习的肯定不止一个句子,当每个句子被编码成矩阵后,就会构成高维的多特征词向量。由于在实际训练时,所有句子或段落长度都一致的可能性太小(即所有句子的vocab_size都一致的可能性太小),因此我们往往为短句子进行填充、或将长句子进行裁剪,让所有的特征词向量保持在同样的维度。
Embedding编码解读: 词嵌入/词向量
继续假设我们有一句话,叫“公主很漂亮”,如果我们使用one-hot编码,可能得到的编码如下:
公 [0 0 0 0 1] 主 [0 0 0 1 0] 很 [0 1 0 0 0] 漂 [0 0 1 0 0] 亮 [1 0 0 0 0]
这样的编码,最大的好处就是,不管你是什么字,我们都能在一个一维的数组里用01给你表示出来。并且不同的字绝对不一样,以致于一点重复都没有,表达本征的能力极强。但是,因为其完全独立,其劣势就出来了。表达关联特征的能力几乎为0!!!举个例子,我们又有一句话 “王妃很漂亮” 那么在这基础上,我们可以把这句话表示为
王 [0 0 1 0 0 ] 妃 [1 0 0 0 0 ] 很 [0 0 0 1 0 ] 漂 [0 1 0 0 0 ] 亮 [0 0 0 0 1 ]
从中文表示来看,我们一下就跟感觉到,王妃跟公主其实是有很大关系的,比如:公主是皇帝的女儿,王妃是皇帝的妃子,可以从“皇帝”这个词进行关联上;公主住在宫里,王妃住在宫里,可以从“宫里”这个词关联上;公主是女的,王妃也是女的,可以从“女”这个字关联上。但是呢,我们用了one-hot编码,公主和王妃就变成了这样:
王 [0 0 1 0 0 ] 妃 [1 0 0 0 0 ]
公 [0 0 0 0 1] 主 [0 0 0 1 0]
你知道这四行向量有什么内部关系吗?看不出来,那怎么办?
既然,通过刚才的假设关联,我们关联出了“皇帝”、“宫里”和“女”三个词,那我们尝试这么去定义公主和王妃
公主一定是皇帝的女儿,我们假设她跟皇帝的关系相似度为1.0;公主从一出生就住在宫里,直到20岁才嫁到府上,活了80岁,我们假设她跟宫里的关系相似度为0.25;公主一定是女的,跟女的关系相似度为1.0;
王妃是皇帝的妃子,没有亲缘关系,但是有存在着某种关系,我们就假设她跟皇帝的关系相似度为0.6吧;妃子从20岁就住在宫里,活了80岁,我们假设她跟宫里的关系相似度为0.75;王妃一定是女的,跟女的关系相似度为1.0;于是公主王妃四个字我们可以这么表示:
皇帝 宫里 女 公主 [ 1.0 0.25 1.0] 王妃 [ 0.6 0.75 1.0]
这样我们就把公主和王妃两个词,跟皇帝、宫里、女这几个字(特征)关联起来了,我们可以认为:
公主=1.0 皇帝 +0.25宫里 +1.0*女
王妃=0.6 皇帝 +0.75宫里 +1.0*女
或者我们假设每个词的每个字都是对等(注意:只是假设,为了方便解释),则公主(2个字)和王妃(2个字)的表示为:
皇帝 宫里 女
公 [ 0.5 0.125 0.5] 主 [ 0.5 0.125 0.5] 王 [ 0.3 0.375 0.5] 妃 [ 0.3 0.375 0.5]
公主与皇帝的相似度为1,与皇宫的相似度为0.25,与女性的相似度为1 王妃与皇帝的相似度为0.6,与皇宫的相似度为0.75,与女性的相似度为1
这样,我们就把一些词甚至一个字,用三个特征给表征出来了。于是乎,我们把文字的one-hot编码,从稀疏态变成了密集态,并且让相互独立向量变成了有内在联系的关系向量。
所以,embedding层做了个什么呢?它把我们的稀疏矩阵,通过某种变换将其变成了一个密集矩阵,这个密集矩阵用了N(例子中N=3,皇帝、公里和女)个特征来表征所有的文字,在这个密集矩阵中,表象上代表着密集矩阵跟单个字的一一对应关系,实际上还蕴含了大量的字与字之间,词与词之间甚至句子与句子之间的内在关系。他们之间的关系,用的是嵌入层学习来的参数进行表征。从稀疏矩阵到密集矩阵的过程,叫做embedding。
三维文字序列
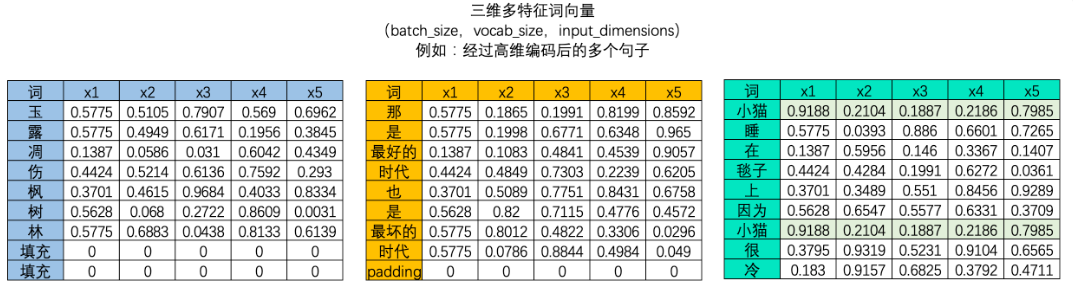
此时我们拥有的是一个三维矩阵,其中batch_size是样本量,也就是一共有多少个二维文字序列表单。
四、循环神经网络RNN
4.1 RNN概述
循环神经网络(Recurrent Neural Network)是自然语言处理领域的入门级深度学习算法,也是序列数据处理方法的经典代表作,它开创了“记忆”方式、让神经网络可以学习样本之间的关联、它可以处理时间、文字、音频数据,也可以执行NLP领域最为经典的情感分析、机器翻译等工作。
4.2 RNN基本架构
如果你去找寻网络上的各种资源,你会惊讶地发现循环神经网络有各种各样复杂的公式表示和图像表示方法。然而,光从网络架构来说,循环神经网络与深度神经网络是完全一致的。
首先,循环神经网络由输入层、隐藏层和输出层构成,输入层的神经元个数由输入数据的特征数量决定,隐藏层数量和隐藏层上神经元的个数都可自己设置,而输出层的神经元数量则需要根据输出的任务目标进行设置。假如,现在我们将每个单词都编码成了5个特征构成的词向量,因此输入层就会需要5个神经元,我们将该文字数据输入循环神经网络执行三分类的“情感分类”任务(三分类分别是[积极,消极,中性]),那输出层就会需要三个神经元。假设有一个隐藏层,而隐藏层上有2个神经元,一个最为简单的循环网络的网络结构如下:
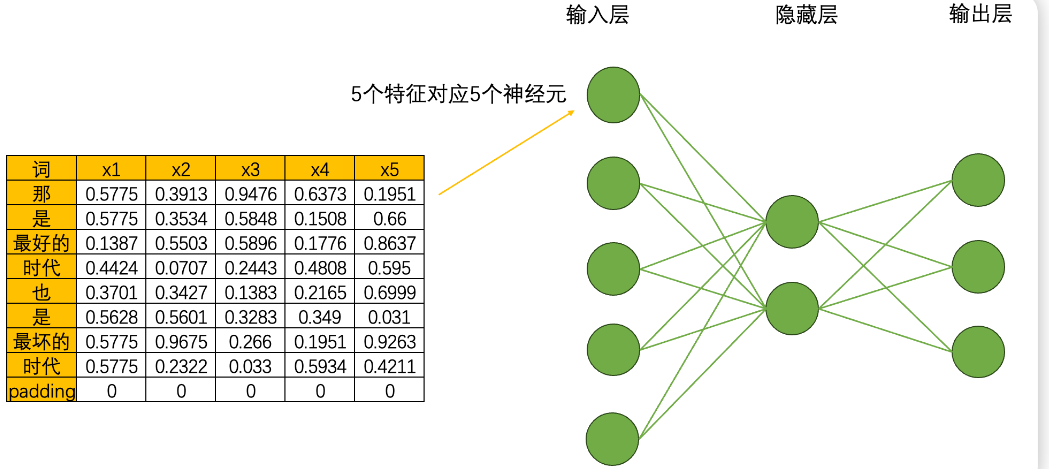
在这个结构中,激活函数的设置、神经元的连接方式等都与深度神经网络一致,因此循环神经网络在网络构建方面没有太多可以深究的内容,循环网络真正精彩的地方在于其创造了全新的数据流。
4.3 RNN数据流
当我们将数据输入到循环神经网络时,一个神经元一次性只会处理一个单词的一个数据,5个神经元会覆盖当前单词的5个特征,在一次正向传播中,循环神经网络只会接触到一个单词的全部信息。
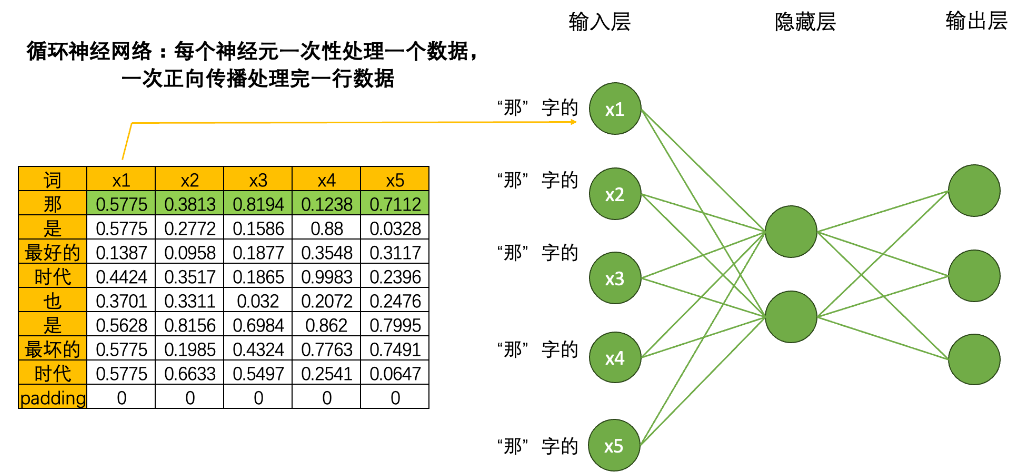
如果这样的话,岂不是要一行一行处理数据了?没错,没错,虽然非常颠覆神经网络当中对效率的根本追求,但循环神经网络是一个单词、一个单词处理文本数据,一个时间点、一个时间点处理时序数据的。具体过程如下:



如果一次正向传播只处理一行数据,那对于结构为(vocab_size,input_dimension)的文字数据来说,就需要在同一个网络上进行vocab_size次正向传播。同样的,对于结构为(time_step,input_dimension)的时间序列数据来说,就需要在同一个网络上进行time_step次正向传播。在循环神经网络中,vocab_size和time_step这个维度可以统称为sequence_length,同时还有一个更常见的名字叫做时间步,对任意数据来说,循环神经网络都需要进行时间步次正向传播,而每个时间步上是一个单词或一个时间点的数据。
基于这样的数据流设置,循环神经网络构建了自己的灵魂结构:循环数据流。在多次进行正向传播的过程中,循环神经网络会将每个单词的信息向下传递给下一个单词,从而让网络在处理下一个单词时还能够“记得”上一个单词的信息。循环网络在不同时间步的隐藏层之间建立了链接
如下图所示,在Tt-1时间步上时,循环网络处理了一个单词,此时隐藏层上输出的中间变量Ht-1会走向两条数据流,一条数据流是继续向输出层的方向正向传播,另一条则流向了下一个时间步的隐藏层。在T时间步时,隐藏层会结合当前正向传播的输入层传入的Xt和上个时间步的隐藏层传来的中间变量Ht-1共同计算当前隐藏层的输出Ht。如此,Ht当中就包含了上一个单词的信息。
假设当前时间步是t-1,当前时间步上的输入特征为𝑋𝑡−1,输入层与隐藏层之间的的权重为𝑊xh,隐藏层与输出层之间的权重为𝑊hy,当𝑋𝑡−1进入神经网络后时,权重𝑊xh将与输入信息𝑋𝑡−1共同计算,构成中间变量𝐻𝑡−1,这一中间变量被称之为是“隐藏状态”,代表在隐藏层上输出的值。
在深度神经网络中,𝐻𝑡−1将会被传导向输出层,与𝑤hy共同计算后构成输出层上的输出,但在循环神经网络中,𝐻𝑡−1除了被传导向输出层之外,还会被传导向下一个时间步,与𝑋t一起,共同构建𝐻t。
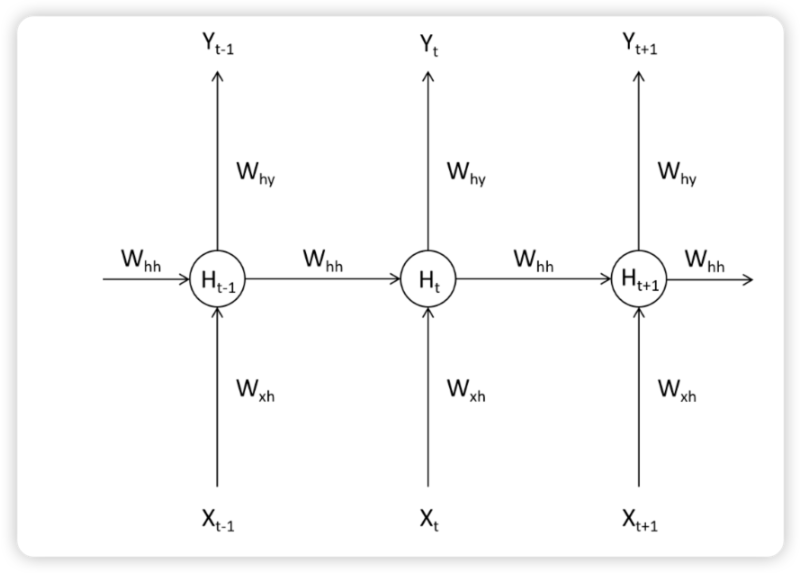
具体地来看:
-
普通神经网络,其中f是激活函数
![]()
-
循环神经网络,其中,𝑊ℎℎ是循环网络中,隐藏层与隐藏层之间链接上的权重。
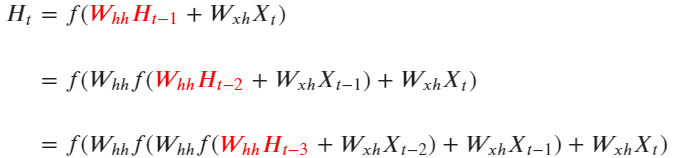
使用架构图表示,则可表示如下:
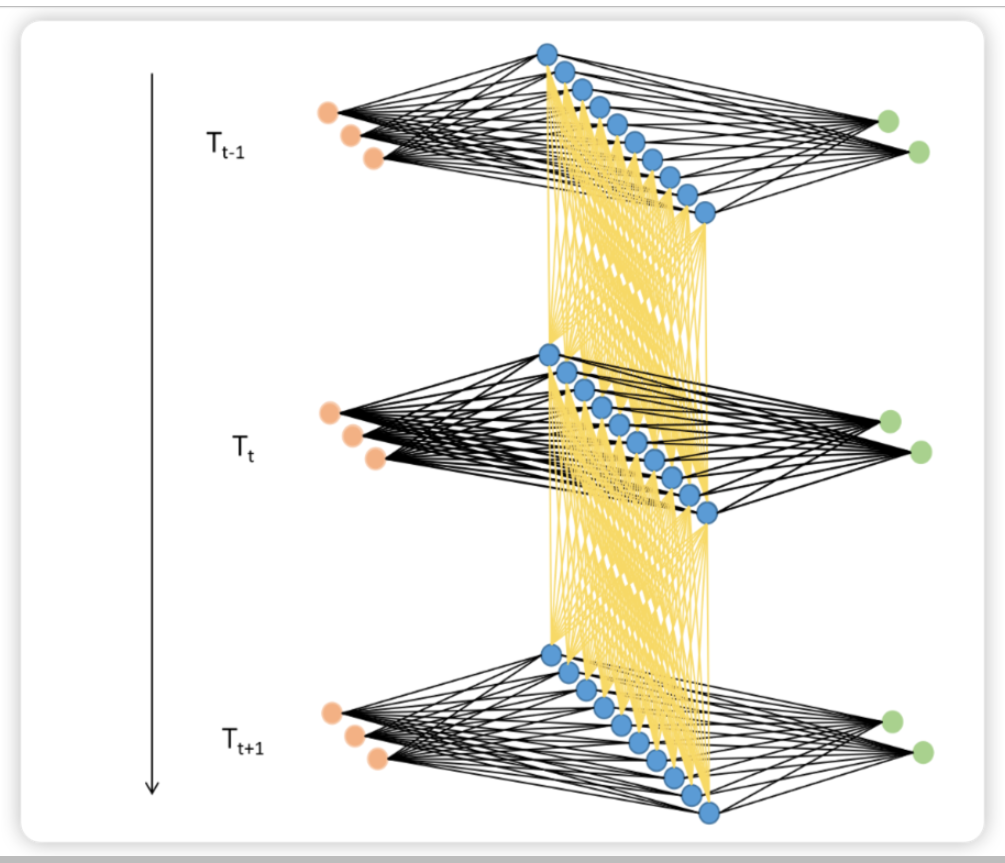
利用这种方式,只要进行vocal_size次向前传播,并且每次都将上一个时间步中隐藏层上诞生的中间变量传递给下一个时间步的隐藏层,整个网络就能在全部的正向传播完成后获得整个句子上的全部信息。在这个过程中,我们在同一个网络上不断运行正向传播,此过程在神经网络结构上是循环,在数学逻辑上是递归,这也是循环神经网络名称的由来。
这种传递方式可以让循环神经网络“记得”历史时间步上的信息,理论上来说,在最后一个时间步上输出的变量H_T应该包含从t=0到t=T的所有时间步上的信息。
4.4 RNN的权值共享
现在已经知道循环网络的数据流和基本结构了,但我们还面临一个巨大的问题——效率。刚才我们以一张表为例讲解了循环神经网络的迭代过程,但循环网络在实际应用时可能面临batch_size张表单,如果每张表单都需要一行一行进行向前传播的话,那循环神经网络运行一次需要(batch_size * sequence_length)次向前传播,这样整个网络的运行效率必然是非常非常低的。
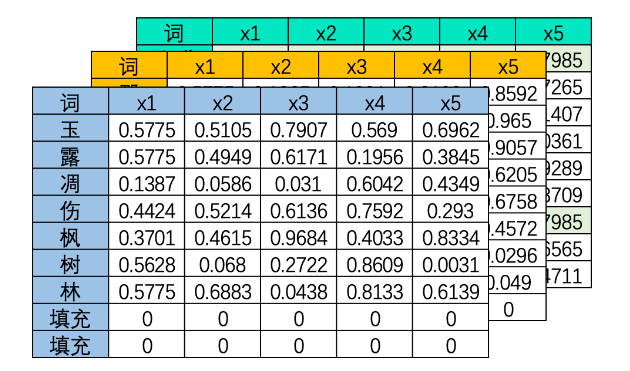
幸运的是,事实上这个问题并不存在。在现实中使用循环神经网络的时候,我们所使用的输入数据结构往往是三维时间或三维文字数据,也就是说数据中大概率会包括不止一张时序二维表、会包括不止一个句子或一个段落。之前我们提到过,循环神经网络要顺利运行的前提是所有的句子/时间序列被处理成同等的长度,因此实际上每张二维表需要循环的时间步数量是相等的,因此在实际训练的时候循环神经网络是会一次性将所有的batch_size张二维表的第一行数据都放入神经元进行处理,故而RNN并不需要对每张表单一一处理,而是对全部表单的每一行进行一一处理,所以最终循环神经网络只会进行sequence_length次向前传播,所有的batch是共享权重的。
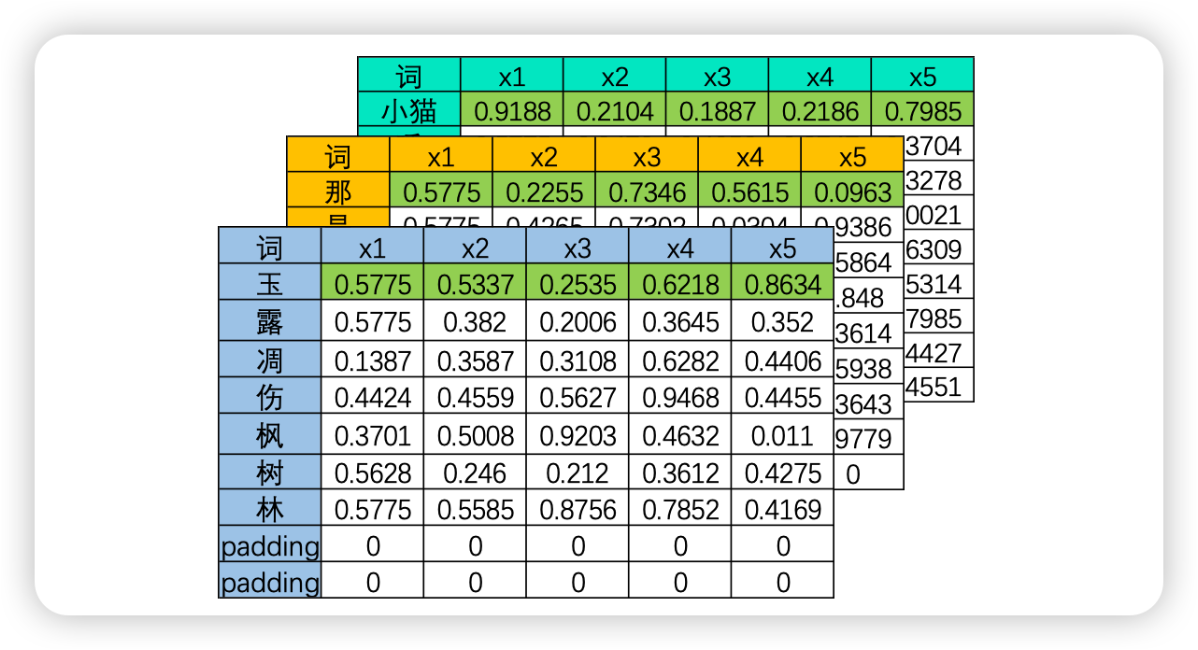
如果将三维数据看作是一个立方体,那循环神经网络就是一次性处理位于最上层的一整个平面的数据,因此循环神经网络一次性处理的数据结构与深度神经网络一样都是二维的,只不过这个二维数据不是(vocal_size,input_dimension)结构,而是(batch_size,input_dimension)结构罢了。




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











