






一、正则表达式
正则表达式是一个特殊的字符序列,它能帮助你方便的检查一个字符串是否与某种模式匹配。使用 re 模块来处理正则表达式。
re 模块提供了一组函数,允许你在字符串中进行模式匹配、搜索和替换操作。
要匹配变长的字符,在正则表达式中,用*表示任意个字符(包括0个),用+表示至少一个字符,用?表示0个或1个字符,用{n}表示n个字符,用{n,m}表示n-m个字符
1.1、re.match函数
re.match 尝试从字符串的起始位置匹配一个模式,如果不是起始位置匹配成功的话,match() 就返回 None。
1、函数语法:
re.match(pattern, string, flags=0)
pattern--匹配的正则表达式;
string--要匹配的字符串。
flags--标志位,用于控制正则表达式的匹配方式,如:是否区分大小写,多行匹配等等。详情请参照章节【正则表达式修饰符 - 可选标志】。
2、返回值
匹配成功 re.match 方法返回一个匹配的对象,否则返回 None。
3、使用
我们可以使用 group(num) 或 groups() 匹配对象函数来获取匹配表达式。

4、举例
例子1:
import re
print(re.match('www', 'www.runoob.com').span()) # 在起始位置匹配
print(re.match('com', 'www.runoob.com')) # 不在起始位置匹配
运行结果:
(0, 3) None
注意:
span() 是 re 模块中的一个函数,它用于在字符串中搜索模式并返回匹配的起始和结束位置。
例子2:
import re
line = "Cats are smarter than dogs"
# .* 表示任意匹配除换行符(\n、\r)之外的任何单个或多个字符
# (.*?) 表示"非贪婪"模式,只保存第一个匹配到的子串
matchObj = re.match( r'(.*) are (.*?) .*', line, re.M|re.I)
if matchObj:
print ("matchObj.group() : ", matchObj.group())
print ("matchObj.group(1) : ", matchObj.group(1))
print ("matchObj.group(2) : ", matchObj.group(2))
else:
print ("No match!!")
执行结果如下:
matchObj.group() : Cats are smarter than dogs
matchObj.group(1) : Cats
matchObj.group(2) : smarter
1.2、re.search函数
扫描整个字符串并返回第一个成功的匹配。
1、语法
re.search(pattern, string, flags=0)
pattern--匹配的正则表达式;
string--要匹配的字符串。
flags--标志位,用于控制正则表达式的匹配方式,如:是否区分大小写,多行匹配等等。详情请参照章节【正则表达式修饰符 - 可选标志】。
2、返回值
匹配成功re.search方法返回一个匹配的对象,否则返回None。
3、使用
我们可以使用group(num) 或 groups() 匹配对象函数来获取匹配表达式。

4、举例
例子1:
import re
print(re.search('www', 'www.runoob.com').span()) # 在起始位置匹配
print(re.search('com', 'www.runoob.com').span()) # 不在起始位置匹配
运行结果:
(0, 3) (11, 14)
注意:
span() 是 re 模块中的一个函数,它用于在字符串中搜索模式并返回匹配的起始和结束位置。
例子2:
import re
line = "Cats are smarter than dogs"
searchObj = re.search( r'(.*) are (.*?) .*', line, re.M|re.I)
if searchObj:
print ("searchObj.group() : ", searchObj.group())
print ("searchObj.group(1) : ", searchObj.group(1))
print ("searchObj.group(2) : ", searchObj.group(2))
else:
print ("Nothing found!!")
执行结果如下:
matchObj.group() : Cats are smarter than dogs
matchObj.group(1) : Cats
matchObj.group(2) : smarter
1.3、re.match 与 re.search的区别
re.match 只匹配字符串的开始,如果字符串开始不符合正则表达式,则匹配失败,函数返回 None,而 re.search 匹配整个字符串,直到找到一个匹配。
1.4、检索和替换(re.sub)
Python 的re模块提供了re.sub用于替换字符串中的匹配项。
1、语法
re.sub(pattern, repl, string, count=0, flags=0)
pattern--匹配的正则表达式。
repl--替换的字符串(即匹配到pattern后替换为repl),也可为一个函数。
string--要被查找替换的原始字符串。
count--模式匹配后替换的最大次数,默认 0 表示替换所有的匹配。
flags--标志位,编译时用的匹配模式,数字形式。
前三个为必选参数,后两个为可选参数
2、使用
3、举例
import re
phone = "2004-959-559 # 这是一个电话号码"
# 删除注释
num = re.sub(r'#.*$', "", phone) # $匹配字符串的末尾。
print ("电话号码 : ", num)
# 移除非数字的内容
num = re.sub(r'\D', "", phone) # \D匹配任意非数字
print ("电话号码 : ", num)
执行结果:
电话号码 : 2004-959-559 电话号码 : 2004959559
3、repl 参数是一个函数
以下实例中将字符串中的匹配的数字乘以 2:
import re
# 将匹配的数字乘以 2
def double(matched):
value = int(matched.group('value'))
return str(value * 2)
s = 'A23G4HFD567'
print(re.sub('(?P<value>\d+)', double, s)) # \d匹配任意数字
执行结果:
A46G8HFD1134
1.5、re.compile 函数
compile 函数用于编译正则表达式,生成一个正则表达式( Pattern )对象,供 match() 和 search() 这两个函数使用。
1、语法
re.compile(pattern[, flags])
- pattern : 一个字符串形式的正则表达式
- flags 可选,表示匹配模式,比如忽略大小写,多行模式等,具体参数为:
-
- re.IGNORECASE 或 re.I - 使匹配对大小写不敏感
- re.L 表示特殊字符集 \w, \W, \b, \B, \s, \S 依赖于当前环境
- re.MULTILINE 或 re.M - 多行模式,改变 ^ 和 $ 的行为,使它们匹配字符串的每一行的开头和结尾。
- re.DOTALL 或 re.S - 使 . 匹配包括换行符在内的任意字符。
- re.ASCII - 使 \w, \W, \b, \B, \d, \D, \s, \S 仅匹配 ASCII 字符。
- re.VERBOSE 或 re.X - 忽略空格和注释,可以更清晰地组织复杂的正则表达式。
这些标志可以单独使用,也可以通过按位或(|)组合使用。例如,re.IGNORECASE | re.MULTILINE 表示同时启用忽略大小写和多行模式。
2、举例
>>>import re
>>> pattern = re.compile(r'\d+') # 用于匹配至少一个数字
>>> m = pattern.match('one12twothree34four') # 查找头部,没有匹配
>>> print( m )
None
>>> m = pattern.match('one12twothree34four', 2, 10) # 从'e'的位置开始匹配,没有匹配
>>> print( m )
None
>>> m = pattern.match('one12twothree34four', 3, 10) # 从'1'的位置开始匹配,正好匹配
>>> print( m ) # 返回一个 Match 对象
<_sre.SRE_Match object at 0x10a42aac0>
>>> m.group(0) # 可省略 0
'12'
>>> m.start(0) # 可省略 0
3
>>> m.end(0) # 可省略 0
5
>>> m.span(0) # 可省略 0
(3, 5)
在上面,当匹配成功时返回一个 Match 对象,其中:
group([group1, …])方法用于获得一个或多个分组匹配的字符串,当要获得整个匹配的子串时,可直接使用group()或group(0);start([group])方法用于获取分组匹配的子串在整个字符串中的起始位置(子串第一个字符的索引),参数默认值为 0;end([group])方法用于获取分组匹配的子串在整个字符串中的结束位置(子串最后一个字符的索引+1),参数默认值为 0;span([group])方法返回(start(group), end(group))。
举例:
>>>import re
>>> pattern = re.compile(r'([a-z]+) ([a-z]+)', re.I) # re.I 表示忽略大小写
>>> m = pattern.match('Hello World Wide Web')
>>> print( m ) # 匹配成功,返回一个 Match 对象
<_sre.SRE_Match object at 0x10bea83e8>
>>> m.group(0) # 返回匹配成功的整个子串
'Hello World'
>>> m.span(0) # 返回匹配成功的整个子串的索引
(0, 11)
>>> m.group(1) # 返回第一个分组匹配成功的子串
'Hello'
>>> m.span(1) # 返回第一个分组匹配成功的子串的索引
(0, 5)
>>> m.group(2) # 返回第二个分组匹配成功的子串
'World'
>>> m.span(2) # 返回第二个分组匹配成功的子串索引
(6, 11)
>>> m.groups() # 等价于 (m.group(1), m.group(2), ...)
('Hello', 'World')
>>> m.group(3) # 不存在第三个分组
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
IndexError: no such group
1.6、re.findall
在字符串中找到正则表达式所匹配的所有子串,并返回一个列表,如果有多个匹配模式,则返回元组列表,如果没有找到匹配的,则返回空列表。
注意: match 和 search 是匹配一次 findall 匹配所有。
1、语法 re.findall(pattern, string, flags=0) 或 pattern.findall(string[, pos[, endpos]])
参数:
- pattern 匹配模式。
- string 待匹配的字符串。
- pos 可选参数,指定字符串的起始位置,默认为 0。
- endpos 可选参数,指定字符串的结束位置,默认为字符串的长度。
2、举例
例子1:查找字符串中的所有数字:
import re
result1 = re.findall(r'\d+','runoob 123 google 456')
pattern = re.compile(r'\d+') # 查找数字
result2 = pattern.findall('runoob 123 google 456')
result3 = pattern.findall('run88oob123google456', 0, 10)
print(result1)
print(result2)
print(result3)
输出结果:
['123', '456']
['123', '456']
['88', '12']
例子2:多个匹配模式,返回元组列表:
import re
result = re.findall(r'(\w+)=(\d+)', 'set width=20 and height=10')
print(result)
输出结果:
[('width', '20'), ('height', '10')]
1.7、re.finditer
和 findall 类似,在字符串中找到正则表达式所匹配的所有子串,并把它们作为一个迭代器返回。
1、语法
re.finditer(pattern, string, flags=0)
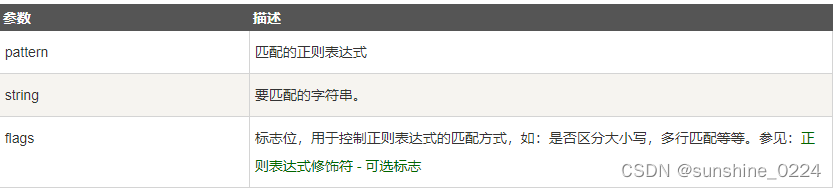
2、举例
import re
it = re.finditer(r"\d+","12a32bc43jf3")
for match in it:
print (match.group() )
输出结果:
12 32 43 3
1.8、re.split
split 方法按照能够匹配的子串将字符串分割后返回列表。
1、语法
re.split(pattern, string[, maxsplit=0, flags=0])
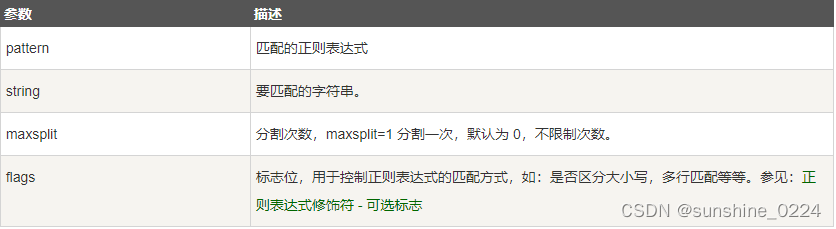
>>>import re
>>> re.split('\W+', 'runoob, runoob, runoob.')
['runoob', 'runoob', 'runoob', '']
>>> re.split('(\W+)', ' runoob, runoob, runoob.')
['', ' ', 'runoob', ', ', 'runoob', ', ', 'runoob', '.', '']
>>> re.split('\W+', ' runoob, runoob, runoob.', 1)
['', 'runoob, runoob, runoob.']
>>> re.split('a*', 'hello world') # 对于一个找不到匹配的字符串而言,split 不会对其作出分割
['hello world']
1.9、正则表达式对象
re.RegexObject
re.compile() 返回 RegexObject 对象。
re.MatchObject
group() 返回被 RE 匹配的字符串。
- start() 返回匹配开始的位置
- end() 返回匹配结束的位置
- span() 返回一个元组包含匹配 (开始,结束) 的位置
1.10、正则表达式修饰符 - 可选标志
正则表达式可以包含一些可选标志修饰符来控制匹配的模式。
以下标志可以单独使用,也可以通过按位或(|)组合使用。例如,re.IGNORECASE | re.MULTILINE 表示同时启用忽略大小写和多行模式。

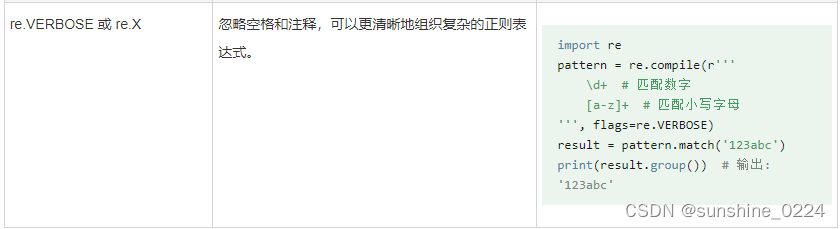
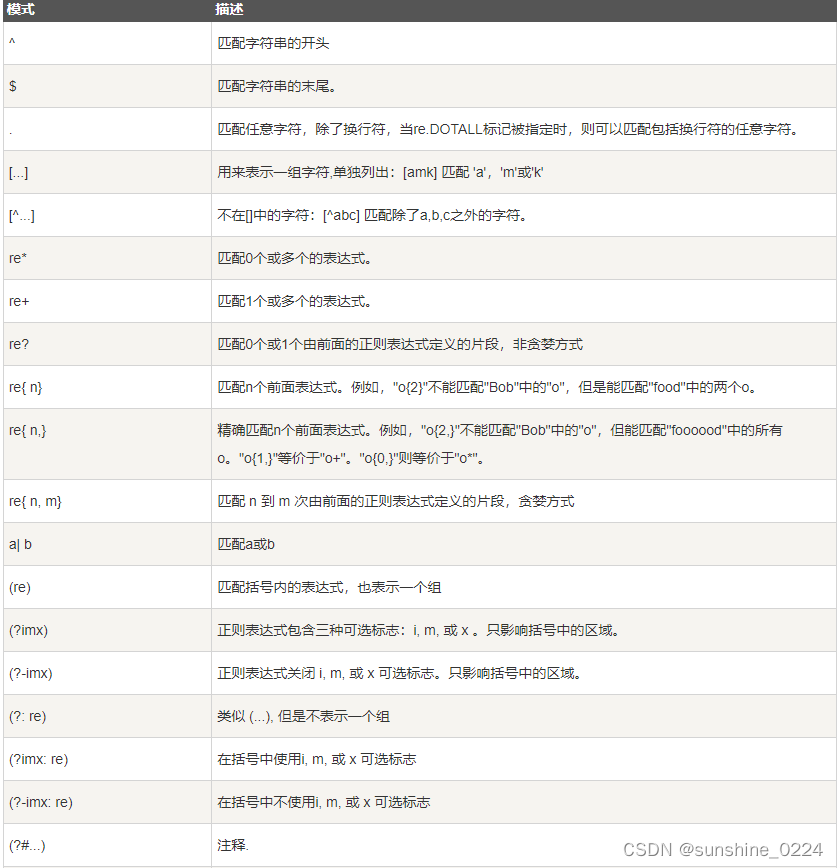
1.11、正则表达式模式
模式字符串使用特殊的语法来表示一个正则表达式。
字母和数字表示他们自身。一个正则表达式模式中的字母和数字匹配同样的字符串。
多数字母和数字前加一个反斜杠时会拥有不同的含义。
标点符号只有被转义时才匹配自身,否则它们表示特殊的含义。
反斜杠本身需要使用反斜杠转义。
由于正则表达式通常都包含反斜杠,所以你最好使用原始字符串来表示它们。模式元素(如 r'\t',等价于 \\t )匹配相应的特殊字符。
下表列出了正则表达式模式语法中的特殊元素。如果你使用模式的同时提供了可选的标志参数,某些模式元素的含义会改变。
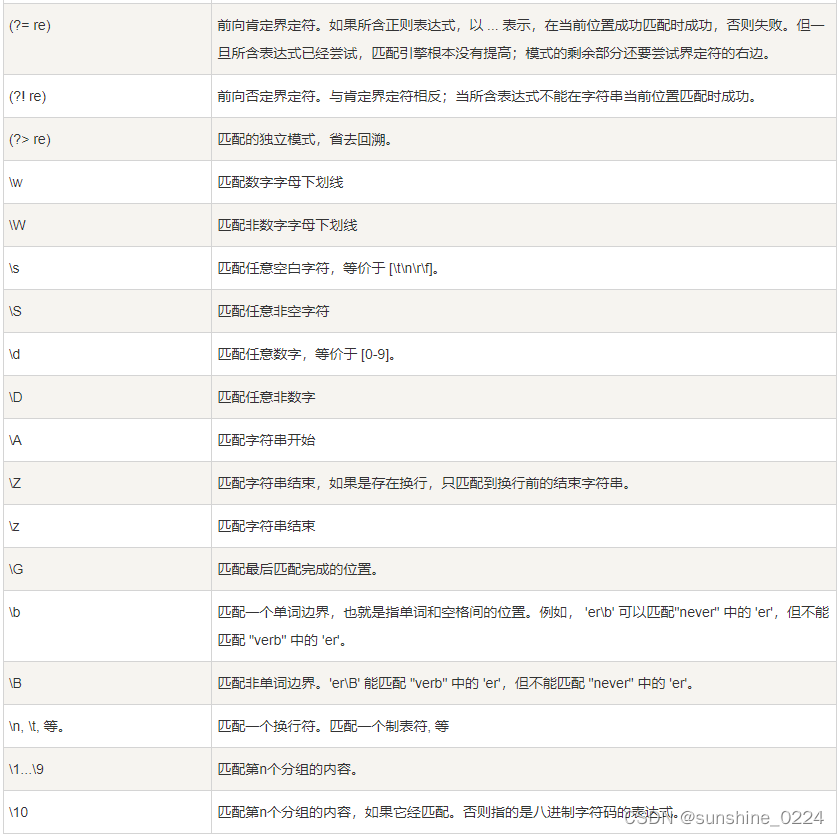
1.12、正则表达式实例
字符匹配

字符类
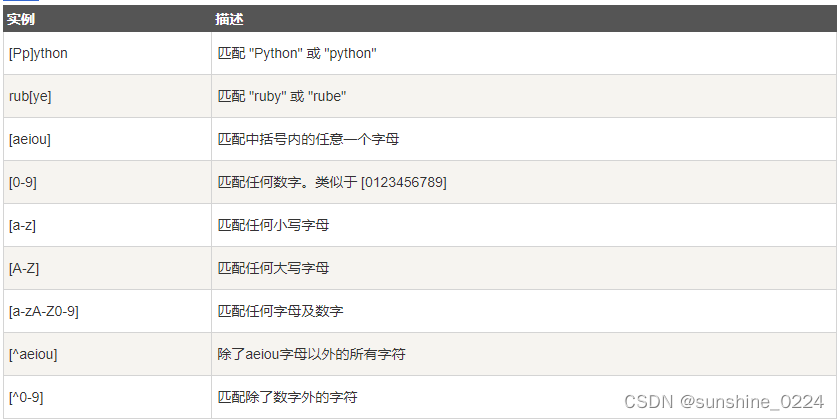
特殊字符类

1.13、注意事项
1、在Python的string前面加上‘r’, 是为了告诉编译器这个string是个raw string,不要转意反斜杠backslash '\' ,因此,当一个字符串使用了正则表达式后,最好在前面加上'r'。
2、在正则表达式中有3种类型的括号:
方括号"["内是需要匹配的字符;
花括号"{"内是指定匹配字符的数量;
“a|b”:表示匹配a或者b。
二、GCI编程
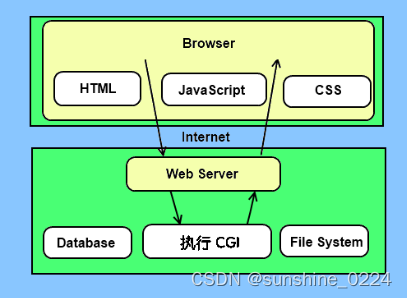
CGI(Common Gateway Interface),通用网关接口,它是一段程序,运行在服务器上如:HTTP服务器,提供同客户端HTML页面的接口。
一种用于Web服务器与CGI脚本之间通信的标准协议,是一种比较传统的Web编程方式。主要用于Web页面的动态生成。在Python中,CGI编程可以通过CGI模块实现,CGI模块提供了一组操作CGI脚本的函数和类。
为了更好的了解CGI是如何工作的,我们可以从在网页上点击一个链接或URL的流程:
- 1、使用你的浏览器访问URL并连接到HTTP web 服务器。
- 2、Web服务器接收到请求信息后会解析URL,并查找访问的文件在服务器上是否存在,如果存在返回文件的内容,否则返回错误信息。
- 3、浏览器从服务器上接收信息,并显示接收的文件或者错误信息。
CGI程序可以是Python脚本,PERL脚本,SHELL脚本,C或者C++程序等。
2.1、CGI架构图
2.2、Web服务器支持及配置
在你进行CGI编程前,确保您的Web服务器支持CGI及已经配置了CGI的处理程序。
Apache 支持CGI 配置:
设置好CGI目录:
ScriptAlias /cgi-bin/ /var/www/cgi-bin/
所有的HTTP服务器执行CGI程序都保存在一个预先配置的目录。这个目录被称为CGI目录,并按照惯例,它被命名为/var/www/cgi-bin目录。
CGI文件的扩展名为.cgi,python也可以使用.py扩展名。
默认情况下,Linux服务器配置运行的cgi-bin目录中为/var/www。
如果你想指定其他运行CGI脚本的目录,可以修改httpd.conf配置文件,如下所示:
<Directory "/var/www/cgi-bin">
AllowOverride None
Options +ExecCGI
Order allow,deny
Allow from all
</Directory>
在 AddHandler 中添加 .py 后缀,这样我们就可以访问 .py 结尾的 python 脚本文件:
AddHandler cgi-script .cgi .pl .py
2.2.1、windows环境下
windows+Apache2.4+Python3
1、基本环境安装
Windows下安装Apache2.4,下载地址:
https://link.zhihu.com/?target=https%3A//www.apachehaus.com/cgi-bin/download.plx
VC14需要下载Microsoft Visual C++ 2015
安装Python3
2、环境配置
下载完Apache2.4安装包后进行解压缩;
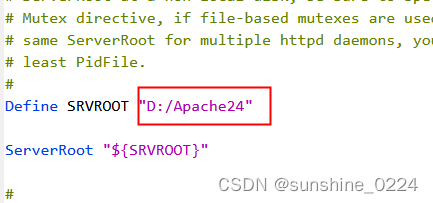
打开\Apache2.4.46\Apache24\conf\目录下的httpd.conf文件;
a、配置文件的根目录:
b、设置Python代码的存储路径,方便Python解析器能找到它:
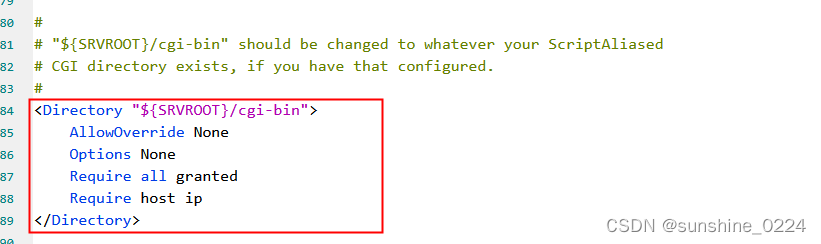
c、打开cgi_module modules/mod_cgi.so模块(去掉注释符#,一般默认是打开的);
d、修改端口:
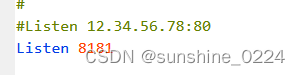
3、到这里关于httpd.conf文件的基本配置已经ok,下面打开cmd窗口,进行注册服务:命令行下进入Apache24下面的bin目录下,输入httppd -k install(注意以管理员身份进行)
4、Python CGI编程之实现Hello World
在Apache24的cgi-bin目录下,新建一个hello.py文件。用Visual Studio Code或其他代码编辑器打开,复制下面的代码到hello.py文件中(ps:注意修改第一行的代码,根据实际本机器python安装路径进行修改)。
#!D:\SOFT\python3.12.0/python.exe
# -*- coding: utf-8 -*-
print("Content-type:text/html\n\n")
print # 空行,告诉服务器结束头部
print('<html>')
print('<head>')
print('<meta charset="utf-8">')
print('<title>Hello Word!</title>')
print('</head>')
print('<body>')
print('<h2>Hello Word555!</h2>')
print('</body>')
print('</html>')
5、接下来在浏览器的地址栏输入:http://localhost:8181/cgi-bin/hello.py,即可显示页面信息。
2.2.2、linux环境下
我们使用Python创建第一个CGI程序,文件名为hello.py,文件位于/var/www/cgi-bin目录中,内容如下:
#!/usr/bin/python3
print ("Content-type:text/html")
print () # 空行,告诉服务器结束头部
print ('<html>')
print ('<head>')
print ('<meta charset="utf-8">')
print ('<title>Hello Word - 我的第一个 CGI 程序!</title>')
print ('</head>')
print ('<body>')
print ('<h2>Hello Word! 我是来自菜鸟教程的第一CGI程序</h2>')
print ('</body>')
print ('</html>)
文件保存后修改 hello.py,修改文件权限为 755:
chmod 755 hello.py
以上程序在浏览器访问显示结果如下:
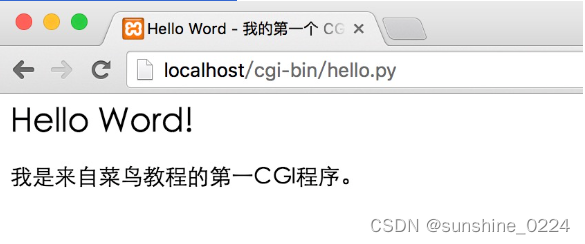
这个的hello.py脚本是一个简单的Python脚本,脚本第一行的输出内容"Content-type:text/html"发送到浏览器并告知浏览器显示的内容类型为"text/html"。
用 print 输出一个空行用于告诉服务器结束头部信息。
2.2.3、HTTP头部
hello.py文件内容中的" Content-type:text/html"即为HTTP头部的一部分,它会发送给浏览器告诉浏览器文件的内容类型。
HTTP头部的格式如下:
HTTP 字段名: 字段内容
例如:
Content-type: text/html
以下表格介绍了CGI程序中HTTP头部经常使用的信息:

2.2.4、CGI环境变量
所有的CGI程序都接收以下的环境变量,这些变量在CGI程序中发挥了重要的作用:
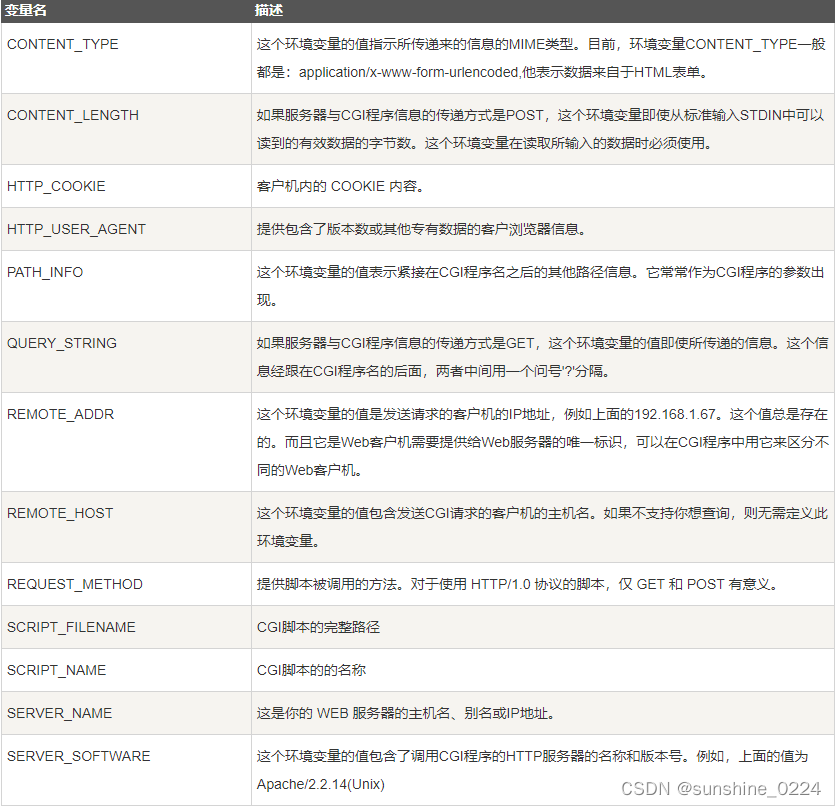
以下是一个简单的CGI脚本输出CGI的环境变量:
#!D:\SOFT\python3.12.0/python.exe
import os
print ("Content-type: text/html")
print ()
print ("<meta charset=\"utf-8\">")
print ("<b>环境变量</b><br>")
print ("<ul>")
for key in os.environ.keys():
print ("<li><span style='color:green'>%30s </span> : %s </li>" % (key,os.environ[key]))
print ("</ul>")
将以上点保存为 test.py ,并修改文件权限为 755,执行结果如下:
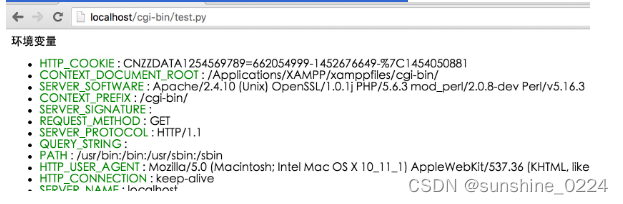
说明:
`os.environ`是Python中的一个字典对象,它包含了当前进程的环境变量。通过使用`os.environ`,可以获取和设置环境变量的值。
os.environ.keys() 主目录下所有的 key。
2.3、编程使用
2.3.1、GET和POST方法
浏览器客户端通过两种方法向服务器传递信息,这两种方法就是 GET 方法和 POST 方法。
1、使用GET方法传输数据
GET方法发送编码后的用户信息到服务端,数据信息包含在请求页面的URL上,以"?"号分割, 如下所示:
http://www.test.com/cgi-bin/hello.py?key1=value1&key2=value2
有关 GET 请求的其他一些注释:
- GET 请求可被缓存
- GET 请求保留在浏览器历史记录中
- GET 请求可被收藏为书签
- GET 请求不应在处理敏感数据时使用
- GET 请求有长度限制
- GET 请求只应当用于取回数据
简单的url实例:GET方法
以下是一个简单的URL,使用GET方法向hello_get.py程序发送两个参数:
/cgi-bin/test.py?name=菜鸟教程&url=http://www.runoob.com
以下为 hello_get.py 文件的代码:
#!D:\SOFT\python3.12.0/python.exe
# CGI处理模块
import cgi, cgitb
# 创建 FieldStorage 的实例化
form = cgi.FieldStorage()
# 获取数据
site_name = form.getvalue('name')
site_url = form.getvalue('url')
print ("Content-type:text/html")
print ()
print ("<html>")
print ("<head>")
print ("<meta charset=\"utf-8\">")
print ("<title>菜鸟教程 CGI 测试实例</title>")
print ("</head>")
print ("<body>")
print ("<h2>%s官网:%s</h2>" % (site_name, site_url))
print ("</body>")
print ("</html>
文件保存后修改 hello_get.py,修改文件权限为 755:
chmod 755 hello_get.py
简单的表单实例:GET方法
以下是一个通过HTML的表单使用GET方法向服务器发送两个数据,提交的服务器脚本同样是hello_get.py文件,hello_get.html 代码如下:
<!DOCTYPE html>
<html>
<head>
<meta charset="utf-8">
<title>菜鸟教程(runoob.com)</title>
</head>
<body>
<form action="/cgi-bin/hello_get.py" method="get">
站点名称: <input type="text" name="name"> <br />
站点 URL: <input type="text" name="url" />
<input type="submit" value="提交" />
</form>
</body>
</html>
默认情况下 cgi-bin 目录只能存放脚本文件,我们将 hello_get.html 存储在 test 目录下,修改文件权限为 755:
chmod 755 hello_get.html
2、使用POST方法传递数据
使用POST方法向服务器传递数据是更安全可靠的,像一些敏感信息如用户密码等需要使用POST传输数据。
以下同样是hello_get.py ,它也可以处理浏览器提交的POST表单数据:
#!/usr/bin/python3
# CGI处理模块
import cgi, cgitb
# 创建 FieldStorage 的实例化
form = cgi.FieldStorage()
# 获取数据
site_name = form.getvalue('name')
site_url = form.getvalue('url')
print ("Content-type:text/html")
print ()
print ("<html>")
print ("<head>")
print ("<meta charset=\"utf-8\">")
print ("<title>菜鸟教程 CGI 测试实例</title>")
print ("</head>")
print ("<body>")
print ("<h2>%s官网:%s</h2>" % (site_name, site_url))
print ("</body>")
print ("</html>
以下为表单通过POST方法(method="post")向服务器脚本 hello_get.py 提交数据:
<!DOCTYPE html>
<html>
<head>
<meta charset="utf-8">
<title>菜鸟教程(runoob.com)</title>
</head>
<body>
<form action="/cgi-bin/hello_get.py" method="post">
站点名称: <input type="text" name="name"> <br />
站点 URL: <input type="text" name="url" />
<input type="submit" value="提交" />
</form>
</body>
</html>















 2700
2700











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









