







零基础学Linux内核系列文章目录
前置知识篇
1. 进程
2. 线程
进程间通信篇
1. IPC概述
2. 信号
3. 消息传递
4. 同步
5. 共享内存区
编译相关篇
1. GCC编译
2. 静态链接与动态链接
3. makefile入门基础
设备驱动篇
1. 设备驱动概述
2. 内核模块_理论篇
文章目录
一、前言
本节主要介绍一下内核设备的基本原理,会有涉及符号表的部分,目前还不太理解,所以就暂时先跳过。
二、前置条件
无
三、本文参考资料
《 [野火]i.MX Linux开发实战指南》
百度
四、正文部分
4.1 概述
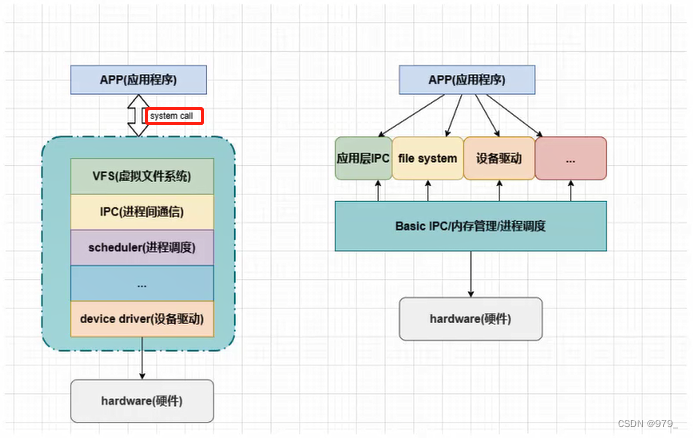
4.1.1 内核体系架构
内核,是一个操作系统的核心。
是基于硬件的第一层软件扩充,提供操作系统的最基本的功能,是操作系统工作的基础,决定着整个操作系统的性能和稳定性。
内核按照体系结构分为两类:微内核(Micro Kernel)和 宏内核(Monolithic Kernel)。
在微内核架构中,内核只提供操作系统核心功能,如实现进程管理、存储器管理、进程间通信、I/O设备管理等,
而其它的应用层IPC、文件系统功能、设备驱动模块则不被包含到内核功能中,属于微内核之外的模块,所以针对这些模块的修改不会影响到微内核的核心功能。
微内核具有动态扩展性强的优点。
Windows操作系统、华为的鸿蒙操作系统就属于这类微内核架构。
(关键功能在内核空间提供,服务功能在用户空间提供)
而宏内核架构是将上述包括微内核以及微内核之外的应用层IPC、文件系统功能、设备驱动模块都编译成一个整体。
其优点是执行效率非常高,但缺点也是十分明显的,即拓展性差,一旦我们想要修改、增加内核某个功能时(如增加设备驱动程序)都需要重新编译一遍内核。
Linux操作系统正是采用了宏内核结构。
为了解决这一缺点,linux中引入了内核模块这一机制。
(关键功能/服务功能均在内核空间提供,APP使用系统调用)
4.1.2 内核模块机制引入
-
内核模块引入原因
Linux是一个跨平台的操作系统,支持众多的设备,在Linux内核源码中有超过50%的代码都与设备驱动相关。
Linux为宏内核架构,如果开启所有的功能,内核就会变得十分臃肿。
内核模块就是实现了某个功能的一段内核代码,在内核运行过程,可以加载这部分代码到内核中, 从而动态地增加了内核的功能。
基于这种特性,我们进行设备驱动开发时,以内核模块的形式编写设备驱动,只需要编译相关的驱动代码即可,无需对整个内核进行编译。 -
内核模块引入好处
内核模块的引入不仅提高了系统的灵活性,对于开发人员来说更是提供了极大的方便。
在设备驱动的开发过程中,我们可以随意将正在测试的驱动程序添加到内核中或者从内核中移除, 每次修改内核模块的代码不需要重新启动内核。
在开发板上,我们也不需要将内核模块程序,或者说设备驱动程序的ELF文件存放在开发板中, 免去占用不必要的存储空间。
当需要加载内核模块的时候,可以通过挂载NFS服务器,将存放在其他设备中的内核模块,加载到开发板上。
在某些特定的场合,我们可以按照需要加载/卸载系统的内核模块,从而更好的为当前环境提供服务。
4.1.3 内核模块的定义和特点
了解了内核模块引入以及带来的诸多好处,我们可以在头脑中建立起对内核模块的初步认识,
下面让我们给出内核模块的具体的定义:
内核模块全称Loadable Kernel Module(LKM), 是一种在内核运行时加载一组目标代码来实现某个特定功能的机制。
模块是具有独立功能的程序,它可以被单独编译,但不能独立运行, 在运行时它被链接到内核作为内核的一部分 在内核空间运行,这与运行在用户空间的进程是不一样的。
模块由一组函数和数据结构组成,用来实现一种文件系统、一个驱动程序和其他内核上层功能。
因此内核模块具备如下特点:
模块本身不被编译入内核映像,这控制了内核的大小。
模块一旦被加载,它就和内核中的其它部分完全一样。
4.2 内核模块加载
insmod总体过程:
加载到用户空间内存
-> 内核空间vmalloc区分配空间暂存(copy_module_from_user)
-> 解析ko并分配段(setup_load_info)
-> 最终找到运行地址(layout_and_allocate -> move_module)
-> 执行ko初始化操作
insmod通过文件系统将ko读到用户空间的一块内存中
执行系统调用 sys_init_module() 解析模组
–> 内核在内核空间的vmalloc区分配与ko文件大小相同的内存来暂存ko文件,
–> 暂存好之后解析ko文件,将文件中的各个段(section)分配到init段和core段,
–> 在modules区为init段和core段分配内存,并把对应的section copy到modules区最终的运行地址,
–> 经过relocate函数地址等操作后,就可以执行ko的init操作了,
这样一个ko的加载流程就结束了。
同时,init段会被释放掉,仅留下core段来运行。
(根据elf将其拆分,并转移到各个部分去执行,完成加载)
//sys_init_module() (内核源码/kernel/module.c)
SYSCALL_DEFINE3(init_module, void __user *, umod,
unsigned long, len, const char __user *, uargs)
{
int err;
struct load_info info = { };
err = may_init_module();
if (err)
return err;
pr_debug("init_module: umod=%p, len=%lu, uargs=%p\n",
umod, len, uargs);
/* 通过vmalloc在vmalloc区分配内存空间,将内核模块copy到此空间 */
/* 此时内核模块已经从用户空间被拷贝到内核空间,info->hdr 直接指向此空间首地址,也就是ko的elf header */
err = copy_module_from_user(umod, len, &info);
if (err)
return err;
/* 进行模块加载的核心处理,在这里完成了模块的搬移,重定向等艰苦的过程。 */
return load_module(&info, uargs, 0);
}
/* load_module()函数 (内核源码/kernel/module.c) */
/* 分配并加载模块 */
static int load_module(struct load_info *info, const char __user *uargs,
int flags)
{
struct module *mod;
long err = 0;
char *after_dashes;
...
/* 加载struct load_info 和 struct module, rewrite_section_headers, */
/* 将每个section的段内存地址sh_addr修改为当前镜像所在的内存地址 */
/* section 名称字符串表地址的获取方式是从ELF头中的e_shstrndx获取到节区头部字符串表的标号 */
/* 找到对应section在ELF文件中的偏移,再加上ELF文件起始地址就得到了字符串表在内存中的地址。 */
err = setup_load_info(info, flags);
...
/* layout_sections() 负责将section 归类为core和init这两大类,为ko的第二次搬移做准备 */
/* move_module()把ko搬移到最终的运行地址!!!! */
/* 内核模块加载代码搬运过程到此就结束了。 */
mod = layout_and_allocate(info, flags);
...
}
4.3 内核模块加载
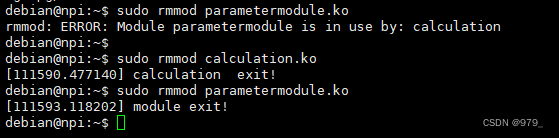
卸载过程相对加载比较简单,我们输入指令rmmod,最终在系统内核中需要调用sys_delete_module进行实现。
rmmod总体流程:
获得名称(strncpy_from_user)
-> 找到对应模块指针(find_module)
-> 卸载依赖模块 -> 确保无依赖 -> 执行本身exit函数
具体过程如下:
先从用户空间传入需要卸载的模块名称,
根据名称找到要卸载的模块指针, 确保我们要卸载的模块没有被其他模块依赖,
然后找到模块本身的exit函数实现卸载。
SYSCALL_DEFINE2(delete_module, const char __user *, name_user,
unsigned int, flags)
{
struct module *mod;
char name[MODULE_NAME_LEN];
int ret, forced = 0;
/* 确保有插入和删除模块不受限制的权利,并且模块没有被禁止插入或删除 */
if (!capable(CAP_SYS_MODULE) || modules_disabled)
return -EPERM;
/* 获得模块名字 */
if (strncpy_from_user(name, name_user, MODULE_NAME_LEN-1) < 0)
return -EFAULT;
name[MODULE_NAME_LEN-1] = '\0';
audit_log_kern_module(name);
if (mutex_lock_interruptible(&module_mutex) != 0)
return -EINTR;
/* 找到要卸载的模块指针 */
mod = find_module(name);
if (!mod) {
ret = -ENOENT;
goto out;
}
/* 有依赖的模块,需要先卸载它们 */
if (!list_empty(&mod->source_list)) {
ret = -EWOULDBLOCK;
goto out;
}
/* Doing init or already dying? */
if (mod->state != MODULE_STATE_LIVE) {
/* FIXME: if (force), slam module count damn the torpedoes */
pr_debug("%s already dying\n", mod->name);
ret = -EBUSY;
goto out;
}
/* 检查模块的退出函数 */
if (mod->init && !mod->exit) {
forced = try_force_unload(flags);
if (!forced) {
/* This module can't be removed */
ret = -EBUSY;
goto out;
}
}
/* 停止机器,使参考计数不能移动并禁用模块 */
ret = try_stop_module(mod, flags, &forced);
if (ret != 0)
goto out;
mutex_unlock(&module_mutex);
/* Final destruction now no one is using it. */
if (mod->exit != NULL)
mod->exit();
/* 告诉通知链module_notify_list上的监听者,模块状态 变为 MODULE_STATE_GOING */
blocking_notifier_call_chain(&module_notify_list,MODULE_STATE_GOING, mod);
klp_module_going(mod);
ftrace_release_mod(mod);
/* 等待所有异步函数调用完成 */
async_synchronize_full();
/* Store the name of the last unloaded module for diagnostic purposes */
strlcpy(last_unloaded_module, mod->name, sizeof(last_unloaded_module));
free_module(mod);
return 0;
out:
mutex_unlock(&module_mutex);
return ret;
}
卸载必须按照依赖顺序进行卸载
4.4 内核导出符号
4.4.1 符号概念与作用
符号指的就是内核模块中使用EXPORT_SYMBOL 声明的 函数和 变量。
当模块被装入内核后,它所导出的符号都会记录在公共内核符号表中。
在使用命令insmod加载模块后,模块就被连接到了内核,因此可以访问内核的共用符号。
查看符号表
cat /proc/kallsyms | grep xxx

通常情况下我们无需导出任何符号,
但是如果其他模块想要从我们这个模块中获取某些方便的时候, 就可以考虑使用导出符号为其提供服务。
这被称为模块层叠技术。 例如msdos文件系统依赖于由fat模块导出的符号;USB输入设备模块层叠在usbcore和input模块之上。
也就是我们可以将模块分为多个层,通过简化每一层来实现复杂的项目。
modprobe是一个处理层叠模块的工具,它的功能相当于多次使用insmod, 除了装入指定模块外还同时装入指定模块所依赖的其他模块。
4.4.2 符号使用
当我们要导出模块的时候,可以使用下面的宏
EXPORT_SYMBOL(name)
EXPORT_SYMBOL_GPL(name) //name为我们要导出的标志
符号必须在模块文件的 全局部分导出,不能在函数中使用,_GPL使得导出的模块只能被GPL许可的模块使用。
编译我们的模块时,这两个宏会被拓展为一个特殊变量的声明,存放在ELF文件中。
具体也就是存放在ELF文件的符号表中:
· st_name: 是符号名称在符号名称字符串表中的索引值
· st_value: 是符号所在的内存地址
· st_size: 是符号大小
· st_info: 是符号类型和绑定信息
· st_shndx: 表示符号所在section
当ELF的符号表被加载到内核后,会执行 simplify_symbols来遍历整个ELF文件符号表。
static int simplify_symbols(struct module *mod, const struct load_info *info)
参数:
mod: struct module类型结构体指针
info: const struct load_info结构体指针
返回值:
ret: 错误码
根据st_shndx找到符号所在的section和st_value中符号在section中的偏移得到真正的内存地址。
并最终将符号内存地址,符号名称指针存储到内核符号表中。
内核导出的符号表结构有两个字段,
- 一个是符号在内存中的地址,
- 一个是符号名称指针,
符号名称被放在了__ksymtab_strings这个section中,
以EXPORT_SYMBOL举例,符号会被放到名为___ksymtab的section中。
struct kernel_symbol {
unsigned long value; // 符号在内存中的地址
const char *name; // 符号名称
};
这个结构体我们要注意,它构成的表是导出符号表而不是通常意义上的符号表 。
其他的内核模块在寻找符号的时候会调用resolve_symbol_wait去内核和其他模块中通过符号名称寻址目标符号,
resolve_symbol_wait会调用resolve_symbol,进而调用 find_symbol。
找到了符号之后,把符号的实际地址赋值给符号表 sym[i].st_value = ksym->value;
/* 找到一个符号并将其连同(可选)crc和(可选)拥有它的模块一起返回。需要禁用抢占或模块互斥。 */
const struct kernel_symbol *find_symbol(const char *name,
struct module **owner,
const s32 **crc,
bool gplok,
bool warn)
{
struct find_symbol_arg fsa;
fsa.name = name;
fsa.gplok = gplok;
fsa.warn = warn;
/* 在each_symbol_section中,去查找了两个地方 */
/* 一个是内核的导出符号表,即我们在将内核符号是如何导出的时候定义的全局变量 */
/* 一个是遍历已经加载的内核模块,查找动作是在each_symbol_in_section中完成的 */
if (each_symbol_section(find_symbol_in_section, &fsa)) {
if (owner)
*owner = fsa.owner;
if (crc)
*crc = fsa.crc;
return fsa.sym;
}
pr_debug("Failed to find symbol %s\n", name);
return NULL;
}
EXPORT_SYMBOL_GPL(find_symbol);
至此符号查找完毕,最后将所有section借助ELF文件的重定向表进行重定向,就能使用该符号了。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









