







我的WEB前端生活
一.HTML5 ,CSS3篇
1.常见的布局问题: flex布局,双飞翼布局,盒模型、两/三栏布局、水平/垂直居中等
(1)双飞翼布局: 是源于淘宝的UED,可以说是灵感来自于页面渲染
(2) 和圣杯布局一样,**都是两边固定宽高,中间自适应,**唯一不同的是在中间内容区域包裹一层div,然后让内容区域margin-left和margin-right的值等于两边固定侧边栏的值即可,无需像圣杯布局那样使用position定位:
按照我的理解,其实圣杯布局跟双飞翼布局的实现,目的都是左右两栏固定宽度,中间部分自适应。
实现方法:
(1):float布局 ; (2):position 布局; (3):table-cell布局; (4) :flex 布局; (5):grid 网格布局
2.圣杯布局:
圣杯布局和双飞翼布局都遵循了这个规则:
(1)两侧宽度固定,中间宽度自适应
(2)中间部分在DOM结构上优先,以便先行渲染
(3)允许三列中的任意一列成为最高列
(4)只需要使用一个额外的div标签
(5)圣杯布局的另一个核心:重要的内容先加载。就像本文中的 middle 在前,left 和 right 在后,浏览器要先渲染middle.
3.flex布局:
布局的传统解决方案,基于盒状模型,依赖 display 属性 + position属性 + float属性。
它对于那些特殊布局非常不方便,比如,垂直居中就不容易实现。
(Flex 布局将成为未来布局的首选方案。对移动端兼容性非常好)
Flex 是 Flexible Box 的缩写,意为"弹性布局",用来为盒状模型提供最大的灵活性。
任何一个容器都可以指定为Flex 布局。 并且行内元素也可以用flex布局.
注意,设为 Flex 布局以后,子元素的float、clear和vertical-align属性将失效。
注: float 属性定义元素在哪个方向浮动。以往这个属性总应用于图像,使文本围绕在图像周围,
不过在 CSS 中,任何元素都可以浮动。浮动元素会生成一个块级框,而不论它本身是何种元素。
clear 属性规定: 元素的哪一侧不允许其他浮动元素。
vertical-align: 属性设置 元素的垂直对齐方式。



容器默认存在两根轴:水平的主轴(main axis)和垂直的交叉轴(cross axis)。
主轴的开始位置(与边框的交叉点)叫做main start,结束位置叫做main end;
交叉轴的开始位置叫做cross start,结束位置叫做cross end。
项目默认沿主轴排列。单个项目占据的主轴空间叫做main size,占据的交叉轴空间叫做cross size。
***注:FLEX的6个属性:
- flex-direction:row |row-reverse| column|column-reverse; 属性决定主轴的方向(即项目的排列方向)。
row(默认值): 主轴为水平方向,起点在左端。----从左到右排列 row-reverse:主轴为水平方向,起点在右端。--- 从右到左排列 column:主轴为垂直方向,起点在上沿。 ---从上到下排列 column-reverse:主轴为垂直方向,起点在下沿。---从下到上排列
2.flex-wrap: 默认情况下,项目都排在一条线(又称"轴线")上。flex-wrap属性定义,如果一条轴线排不下,如何换行。
.box{ flex-wrap: nowrap | wrap | wrap-reverse; }
nowrap: 不换行,
wrap:换行,第一行在上方。
wrap-reverse:换行,第一行在下方。
3.flex-flow:属性是flex-direction属性和flex-wrap属性的简写形式,默认值为row nowrap。
4.justify-content : 属性定义了项目在主轴上的对齐方式。
justify-content: flex-start | flex-end | center | space-between |
space-around;
flex-start(默认值):左对齐 flex-end:右对齐 center: 居中 space-between:两端对齐,项目之间的间隔都相等。
space-around:每个项目两侧的间隔相等。所以,项目之间的间隔比项目与边框的间隔大一倍。
5.align-items:属性定义项目在交叉轴上如何对齐。
align-items: flex-start | flex-end | center | baseline | stretch;
flex-start:交叉轴的起点对齐。
flex-end:交叉轴的终点对齐。
center:交叉轴的中点对齐。
baseline: 项目的第一行文字的基线对齐。
stretch(默认值):如果项目未设置高度或设为auto,将占满整个容器的高度。
6.align-content属性定义了多根轴线的对齐方式。 注:如果项目只有一根轴线,该属性不起作用。
align-content: flex-start | flex-end | center | space-between | space-around | stretch; flex-start:与交叉轴的起点对齐。 flex-end:与交叉轴的终点对齐。 center:与交叉轴的中点对齐。 space-between:与交叉轴两端对齐,轴线之间的间隔平均分布。 space-around:每根轴线两侧的间隔都相等。所以,轴线之间的间隔比轴线与边框的间隔大一倍。 stretch(默认值):轴线占满整个交叉轴。
项目的属性: 以下6个属性设置在项目上。
1.order: 定义项目的排列顺序。 数值越小,排列越靠前,默认为0。
2.flex-grow定义项目的放大比例,默认为0,即如果存在剩余空间,也不放大。
3.flex-shrink : 定义了项目的缩小比例,默认为1,即如果空间不足,该项目将缩小。
4.flex-basis: 定义了在分配多余空间之前,项目占据的主轴空间(main size)。浏览器根据这个属性,计算主轴是否有多余空间。 它的默认值为auto,即项目的本来大小。
5.flex属性是flex-grow, flex-shrink 和 flex-basis的简写,默认值为0 1 auto。后两个属性可选。
6.align-self:允许单个项目有与其他项目不一样的对齐方式,可覆盖align-items属性。默认值为auto,表示继承父元素的align-items属性,如果没有父元素,则等同于stretch(铺满)。
2.BFC和清除浮动
BFC: BFC(Block formatting context)直译为"块级格式化上下文"。它是一个独立的渲染区域,只有Block-level box参与,它规定了内部的Block-level Box如何布局,并且与这个区域外部毫不相干。并且有一套渲染规则,它决定了其子元素将如何定位,以及和其他元素的关系和相互作用。
没有产生BFC


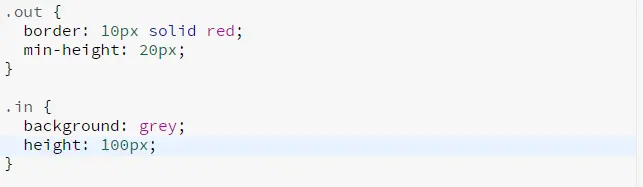
在正常的文档流中,块级元素是按照从上自下,内联元素从左到右的顺序排列的。
如果我给里面的元素一个 float 或者绝对定位,它就会脱离普通文档流中。
此时如果我们还想让外层元素包裹住内层元素该如果去做??
让外层元素产生一个 BFC 。(产生 BFC 的方法 MDN 文档里有写)

这就是 BFC 的第一个作用:使 BFC 内部的浮动元素不会到处乱跑。
和浮动元素产生边界


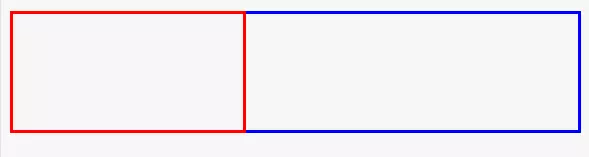
没有产生 BFC:
一般情况下如果没有 BFC的话,我们想要让普通元素与浮动元素产生左右边距,需要将 maring 设置为浮动元素的宽度加上你想要产生边距的宽度。
这里的浮动元素的宽度为 200px ,如果想和它产生 20px 的右边距,需要将非浮动元素的 margin-left 设置为 200px+20px 。
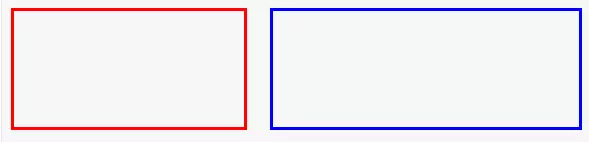
产生了BFC:
BFC 特点(功能):
(1)使 BFC 内部浮动元素不会到处乱跑;
(2)和浮动元素产生边界。
注:如何创建BFC???
1、float的值不是none。
2、position的值不是static或者relative。
3、display的值是inline-block、table-cell、flex、table-caption或者inline-flex
4、overflow的值不是visible
注:BFC的布局规则
1.内部的Box会在垂直方向,一个接一个地放置。
2.BFC的区域不会与float box重叠。
3.计算BFC的高度时,浮动元素也参与计算。
4.BFC就是页面上的一个隔离的独立容器,容器里面的子元素不会影响到外面的元素。反之也如此。
5.Box垂直方向的距离由margin决定。属于同一个BFC的两个相邻Box的margin会发生重叠。
注: BFC的作用
1.利用BFC避免margin重叠。
2.自适应两栏布局
3.清楚浮动。
当我们不给父节点设置高度,子节点设置浮动的时候,会发生高度塌陷,这个时候我们就要清楚浮动。
3.HTML5语义化
HTML5的语义化指的是合理正确的使用语义化的标签来创建页面结构,如 header,footer,nav,从标签上即可以直观的知道这个标签的作用,而不是滥用div。
语义化的优点有:
(1)代码结构清晰,易于阅读,利于开发和维护
(2)方便其他设备解析(如屏幕阅读器)根据语义渲染网页。
(3)有利于搜索引擎优化(SEO),搜索引擎爬虫会根据不同的标签来赋予不同的权重.
语义化标签主要有:
title:主要用于页面的头部的信息介绍
header:定义文档的页眉
nav:主要用于页面导航
main:规定文档的主要内容。对于文档来说应当是唯一的。它不应包含在文档中重复出现的内容,比 如侧栏、导航栏、版权信息、站点标志或搜索表单。
article:独立的自包含内容
h1~h6:定义标题
ul: 用来定义无序列表
ol: 用来定义有序列表
address:定义文档或文章的作者/拥有者的联系信息。
canvas:用于绘制图像
dialog:定义一个对话框、确认框或窗口
aside:定义其所处内容之外的内容。
4.纯CSS实现水平并垂直居中的N种方式
(1)绝对定位+ margin
(2)绝对定位+ calc
(3)绝对定位+ transform
(4)textalign---------center
(5) display------flex
(6) grid 网格布局
C3 动画部分:
transition /transform /animation 的区别,都怎么用?
transition(过渡) transform(变换) animation(动画)
从三个属性就可以知道,
tansition是一个过渡属性,就是一个属性从一个值过渡到另一个值;
tansform变换,就是一个整体的位置(或整体大小)发生变换;
animation动画,就是在一段时间内各种属性进行变化从而达到一个动画的效果。
px---------是css像素单位
em---------相对于 父节点的大小
rem--------是根节点字体的大小
注: 清楚浮动是: clearbox
出去千万不要说 clearfix (这个是讲个自己封装用的) ,
CSS盒模型
盒模型有两种:
(1)content-box(标准的盒模型,只计算内容区的宽高) (2)border-box () , (把边框也算进去了)
更改盒模型的类型用: box-sizing: xxxx
移动端开发的问题:
注: 1像素边框的问题?
1物理 像素边框 都是指 上 下 边框.
解决方法:
1.最常用的是 viewport + rem 方案
2.媒体查询 + transfrom , 利用设备像素比缩放,设置小数像素 .【缺点】对设备有要求,小数像素目前兼容性较差。
3. box-shadow 方案 ; 利用阴影也可以实现,优点是没有圆角问题,缺点是颜色不好控制
4.svg方案: 设置 border-image 方案, 利用css 线性渐变分割成几个部分百分比控制),实现小于1像素效果.
【缺点】因为每个边框都是线性渐变颜色实现,因此无法实现圆角
5.更通用的方案中,有svg格式的图片和伪类元素两种。
svg方案的兼容性更好
(2)
布局视口 : 就是网页的视口
设备视口=视觉视口 : 就是设备的大小
完美(理想)视口: 布局和视觉视口都完美了
(3)
一般开发中, rem适配和 viewport 适配都做.
如下:
viewport适配,让(设备)视觉大小=视觉适配
说到 交互 ,就涉及到 点击 .绑定监听
font-size
取值:
inherited继承,默认从父标签继承字体大小(默认值),所有CSS属性的默认值都是inherited
px像素 pixel
%百分比,相对父标签字体大小的百分比
em倍数,相对于父标签字体大小的倍数
HTML根元素默认字体的大小为16px,也称为基础字体大小
H5新增的新特性:
canvas
地理定位
拖拽
本地存储:localStorage - 没有时间限制的数据存储;sessionStorage - 针对一个 session 的数据存储,当用户关闭浏览器窗口后,数据会被删除.
WebSocket
什么是WebSocket?
Websocket是一个持久化的网络通信协议,可以在单个 TCP 连接上进行全双工通讯,没有了Request和Response的概念,两者地位完全平等,连接一旦建立,客户端和服务端之间实时可以进行双向数据传输
WebSocket: 单个 TCP 连接上进行全双工通讯的协议,是一个 网络通信协议,很多高级功能都需要它。
因为 HTTP 协议有一个缺陷:通信只能由客户端发起。
这种单向请求的特点,注定了如果服务器有连续的状态变化,客户端要获知就非常麻烦。
我们只能使用"轮询":每隔一段时候,就发出一个询问,了解服务器有没有新的信息。最典型的场景就是聊天室。
轮询的效率低,非常浪费资源(因为必须不停连接,或者 HTTP 连接始终打开)
它的最大特点就是,服务器可以主动向客户端推送信息,客户端也可以主动向服务器发送信息,是真正的双向平等对话,属于服务器推送技术的一种。
它建立在 TCP 协议之上,服务器端的实现比较容易。
(2)与 HTTP 协议有着良好的兼容性。默认端口也是80和443,并且握手阶段采用 HTTP 协议,因此握手时不容易屏蔽,能通过各种 HTTP 代理服务器。
(3)数据格式比较轻量,性能开销小,通信高效。
(4)可以发送文本,也可以发送二进制数据。
(5)没有同源限制,客户端可以与任意服务器通信。
(6)协议标识符是ws(如果加密,则为wss),服务器网址就是 URL。

实例对象的send()方法用于向服务器发送数据。
CSS3 新特性:
选择器
背景和边框
文本效果
2D/3D 转换
动画、过渡
多列布局
例子:
last-child /* 选择元素最后一个孩子 /
:first-child / 选择元素第一个孩子 /
:nth-child(1) / 按照第几个孩子给它设置样式 */
pc端
// 鼠标事件
onclick onmouseenter onmouseleave onmouseover onmouseout onmousedown onmousemove onmouseup
//键盘
onkeydown onkeypress onkeyup
//滚轮
onmousewheel
//文档事件
onload onbeforeunload
// 表单事件
onfocus onblur onsubmit onreset
//onload onbeforeunload
如下这个是关闭页面的提示框
重绘和重排
**(1)重绘: **
重绘是指一个元素外观的改变所触发的浏览器行为,浏览器会根据元素的新属性重新绘制,使元素呈现新的外观。
(2)重排 (reflow)
**浏览器为了重新渲染部分或整个页面,重新计算页面元素位置和几何结构的进程叫做reflow. **
reflow(回流)是导致DOM脚本执行效率低的关键因素之一,页面上任何一个节点触发了reflow,会导致它的子节点及祖先节点重新渲染。
重排是一定会引发重绘, 但重绘不一定会引发重排。
触发重排的条件: 任何页面布局和几何属性的改变都会触发重排!!!
二.JavaScript篇
**1.JS的特点: **
解释性脚本语言, (一边解释一边运行)运行在浏览器(浏览器内核带有js解释器,Chrome v8引擎)
弱类型语言(松散型),事件驱动(动态),可以跨平台
2.JS数据类型:
(1).基本类型:
数字number, 字符串string, null, 布尔型bool, undefined, symbol(ES6新增)
(ES10新增了一种基本数据类型:BigInt)
2.复杂类型(对象数据类型, 引用数据类型):
Object(对象类型)
(包含普通对象-Object,数组对象-Array,正则对象-RegExp,日期对象-Date,数学函数- Math,函数对象-Function)
JS的数据结构:标识符,常量和变量,标识符等.


2.1 JS的关键字和保留字
**javascript的关键字:**
break case catch continue default delete do
else finally for function if in instanceof
new return switch this throw try typeof
var void while with
javascript的保留字:
abstract boolean byte char classconst debugger double
enum , export , extends , final ,float , goto implements
import intinter face long native package private
protected public short
static super synchronized
throw stran sient volatile
3.函数防抖和函数节流
3.1 防抖函数的作用就是控制函数在一定时间内的执行次数。防抖意味着N秒内函数只会被执行一次,如果N秒内再次被触发,则重新计算延迟时间(*防抖重在清零 clearTimeout,防止抖动,以免把一次事件误认为多次)
3.1 有哪些防抖的场景呢?
(1)登录、发短信等按钮避免用户点击太快,以致于发送了多次请求,需要防抖
(2)调整浏览器窗口大小时,resize 次数过于频繁,造成计算过多,此时需要一次到位,就用到了防抖
(3)文本编辑器实时保存,当无任何更改操作一秒后进行保存.
(4)搜索框输入查询,如果用户一直在输入中,没有必要不停地调用去请求服务端接口,等用户停止输入的时候,再调用,设置一个合适的时间间隔,有效减轻服务端压力。
3.2函数节流:顾名思义,控制水的流量。控制事件发生的频率,如控制为1s发生一次,甚至1分钟发生一次。与服务端(server)及网关(gateway)控制的限流 (Rate Limit) 类似。
3.2函数节流的场景:
(1)scroll 事件,每隔一秒计算一次位置信息等
(2)浏览器播放事件,每个一秒计算一次进度信息等
(3) input 输入框实时搜索并发送请求展示下拉列表,每隔一秒发送一次请求 (也可做防抖)
函数防抖:
单位时间内事件触发会被重置,避免事件被误伤触发多次。 代码实现重在清零.clearTimeout
函数节流:
控制流量,单位时间内事件只能触发一次,如果服务器端的限流即 Rate Limit。代码实现重在开锁关锁 timer=加粗样式timeout; timer=null
4.JavaScript是严格区分大小写的,也就是abc和Abc会被解析器认为是两个不同的东西。
5.标识符
• 所谓标识符,就是指变量、函数、属性的名字,或函数的参数。
• 按照惯例,ECMAScript 标识符采用驼峰命名法。
•要注意的是JavaScript中的标识符不能是关键字和保留字符
•变量的作用是给某一个值或对象标注名称。
6.运算符
自增 自减: ++ –
赋值: = , ==, *一 , /= , %= , -= ,+二, ===
++ --作用及注意事项:
自增自减运算符,这个运算符只能和变量组成表达式
++ 在后,先赋值(先把a的值赋值给表达式)后++(后让a的值+1)
++ 在前,先++(先让a的值+1)后赋值(后把a的值赋值给表达式)


• 使用typeof操作符可以用来检查一个变量的数据类型。
• 返回结果:
– typeof 数值 //number
– typeof 字符串 //string
– typeof 布尔型 //boolean
– typeof undefined // undefined
– typeof null // object
注:null是基本数据类型,是一个历史遗留问题(也可以说是 JS 存在的一个悠久 Bug), JS 的最初版本中使用的是 32 位系统,为了性能考虑使用低位存储变量的类型信息,000 开头代表是对象,null 表示为全零,所以将它错误的判断为 object 。
•将其他数值转换为字符串有三种方式:toString()、String()、拼串。
注:
(1) ===叫做严格相等,是指:左右两边不仅值要相等,类型也要相等.
(2)JS中,类型转换只有三种: 转换成数字, 转换成布尔值 ,转换成字符串.
(1)数据类型强制转换
//String() 强制将一个其它类型数据转化为字符串类型
//Boolean() 强制将一个其它类型数据转化为boolean类型
//Number() 强制将一个其它类型数据转化为数字类型,转不了就是NaN
(2)判断数据类型
// var num = 1; ---------------------- // number
// var name = “true”; ---------------------- // 字符串
// var isMove = true; ---------------------- // 布尔值
// var age; ---------------------- // undefind
// var obj = null; ---------------------- // object ,但是null 是基本数据类型!!
// // 判断类型
// console.log(typeof num); ---------------------- //number
// console.log(typeof name); ---------------------- //string
// console.log(typeof isMove); ---------------------- //boolean
// console.log(typeof age); ---------------------- //undefined
// console.log(typeof obj); //object //因为null是用来对对象进行操作的,所以类型出来是object
注: // typeof 如果是2个及以上的话,一定是string类型; 有时候typeof无法准确的判断其类型.
使用 Number() 强制将一个其它类型数据转化为数字类型,转不了就是NaN;
把其它类型转为boolean,转化数字的时候,除了0是false,其余的都是true;
当转化字符串,除了空字符串是false,其它的全是true;
//数字之间进行运算的时候,该怎么算就怎么算!
//字符串和字符串,直接拼接字符串.
//字符串的比较也比较特殊:比较的式字符串字符的unicode码值;
//了解这几个特殊的情况
// console.log(0/1);//0
// console.log(1/0);//infinity
// console.log(0/0);//NaN
// console.log(Number.MAX_VALUE);




















7.函数和对象
命令式-----像jQuery,我们都是想干什么然后就去干就完了,例如下面的代码:
声明式:-----React是声明式的, jquery那样直接操作dom是命令式
声明式-----就像你告诉你朋友画一幅画,你不用去管他怎么画的细节
命令式-----就像按照你的命令,你朋友一步步把画画出来
换言之
命令式编程:命令“机器”如何去做事情(how),这样不管你想要的是什么(what),它都会按照你的命令实现。
声明式编程:告诉“机器”你想要的是什么(what),让机器想出如何去做(how)。
对象: 一般我们说的对象都是Object的实例对象(万能,通用的,普通的)
构造函数定义: 用个关键词 new *****来创建对象
工厂函数定义 :本质上还是使用构造函数

8. JS执行上下文
8.1 执行上下文
执行上下文就是当前 JavaScript 代码被解析和执行时所在环境的抽象概念, JavaScript 中运行任何的代码都是在执行上下文中运行。
**(1)全局执行上下文: 这是默认的、最基础的执行上下文。不在任何函数中的代码都位于全局执行上下文中。它做了两件事:1. 创建一个全局对象,在浏览器中这个全局对象就是 window 对象。2. 将 this 指针指向这个全局对象。一个程序中只能存在一个全局执行上下文。
(2)函数执行上下文: **每次调用函数时,都会为该函数创建一个新的执行上下文。**每个函数都拥有自己的执行上下文,但是只有在函数被调用的时候才会被创建。一个程序中可以存在任意数量的函数执行上下文。每当一个新的执行上下文被创建,它都会按照特定的顺序执行一系列步骤,具体过程将在本文后面讨论。
(3)Eval 函数执行上下文: 运行在 eval 函数中的代码也获得了自己的执行上下文,但由于 Javascript 开发人员不常用 eval 函数,所以在这里不再讨论。
8.2 执行上下文栈
执行栈,在其他编程语言中也被叫做调用栈,具有 LIFO(后进先出)结构,用于存储在代码执行期间创建的所有执行上下文,这与堆栈中栈的原理类似。
9. 如何正确判断this的指向?
简单的说: 用一句话说明 this 的指向,-----谁调用它,this 就指向谁。但这不太准确
(1)全局环境中的 this
浏览器环境:无论是否在严格模式,在全局执行环境中(在任何函数体外部)this 都指向全局对象 window;
node 环境:无论是否在严格模式下,在全局执行环境中(在任何函数体外部),this 都是空对象 {};
(2) ES6新增的箭头函数,没有自己的this,它继承外层上下文绑定的this。
let obj = {
age: 20,
info: function() {
return () => {
console.log(this.age); //this继承的是外层上下文绑定的this
}
}
}
let person = {age: 28};
let info = obj.info();
info(); //20
let info2 = obj.info.call(person);
info2(); //28
(3) 默认绑定,在不能应用其它绑定规则时使用的默认规则,通常是独立函数调用。
非严格模式: node环境,执行全局对象 global,浏览器环境,执行全局对象 window。
严格模式:执行 undefined
function info(){
console.log(this.age);
}
var age = 28;
//严格模式;抛错
//非严格模式,node下输出 undefined(因为全局的age不会挂在 global 上)
//非严格模式。浏览器环境下输出 28(因为全局的age会挂在 window 上)
//严格模式抛出,因为 this 此时是 undefined
info();
(4) 隐式绑定,函数的调用是在某个对象上触发的,即调用位置上存在上下文对象。典型的隐式调用为: xxx.fn()
function info(){
console.log(this.age);
}
var person = {
age: 20,
info
}
var age = 28;
person.info(); //20;执行的是隐式绑定
(5) 函数是否通过 call,apply 调用,或者使用了 bind 绑定,如果是,那么this绑定的就是指定的对象【归结为显式绑定】。
10.JavaScript作用域?
作用域就是一个独立的地盘,让变量不会外泄、暴露出去。也就是说作用域最大的用处就是隔离变量,不同作用域下同名变量不会有冲突。
作用域: 变量的作用范围,主要有以下几种:
(1)全局变量
作用范围为整个程序的执行范围,在函数体外部定义的变量就是全局变量,在函数体内部不使用var定义的也是全局变量。
(2)局部变量
作用范围是某个函数体内部,在函数体内部通过var关键字定义的变量或者形参,都是局部变量,当局部变量与全局变量重名时,在函数体内部局部变量优先于全局变量。
作用域是分层的,内层作用域可以访问外层作用域的变量,反之则不行.
块级作用域可通过新增命令let和const声明,所声明的变量在指定块的作用域外无法被访问。
(3)变量提升
let 变量的声明会提升至当前作用域的最顶端, 但不会提升赋值. 禁止重复声明
11.JS有什么用?

12.JS的 暂存性死区???
在相同的函数或块作用域内,重新声明同一个变量会引发SyntaxError;
在声明变量或常量之前使用它, 会引发ReferenceError. 这就是暂存性死区。
•••••••••••••••••••••••••••••••••••••••••••••••••••
总结 (简要答案)
重点:N个简单的JS编码标准让你的代码更整洁
编码标准可以帮助以下方面:
(1)保持代码一致 (2)易于阅读和理解 (3)易于维护
1.比较时使用 === 代替 == ,因为==它允许类型不同。
2.尽可能不要使用 var,使用 let 来代替,用 let 将有助于避免 JavaScript 中各种 var 引起的作用域问题。
3.使用 const 代替 let, 阻止了开发人员尝试更改不应该做的事情,并且确实有助于提高可读性。
4. 始终使用分号(;), 尽管这在 JavaScript 中是可选的,并不像其它语言一样需要分号作为语句终止符。但是使用 ; 有助于使代码保持一致。
5. 拼接字符串时,尽量使用ES6的模板字符串;
6. 多使用ES6箭头函数, 因为箭头函数是编写函数表达式的更简洁的语法。
7. 尝试减少嵌套;-----if 内的 if 会变得混乱并且很难阅读。有时你可能无法解决问题,但是可以好好卡看看代码结构,看看是否可以改进。
8.尽可能使用默认参数,在 JavaScript 中,如果你在调用函数时没有传递参数,则它的值就是 undefined
9.Switch 语句应使用 break 并具有 default; 我通常会尝试不使用 switch 语句,但是你确实想使用它,请确保每个条件都 break ,并写了 defalut
10.不要使用通配符导入

13. window下的子对象
location:
window.location.href 当前页面的 URL,可以获取,可以修改(页面跳转)。
window.location.hostname web 主机的域名
window.location.pathname 当前页面的路径和文件名
window.location.port web 主机的端口 (80 或 443)
window.location.protocol 所使用的 web 协议(http:// 或 https://)
window.location.search 请求参数(?后面的内容)
window.location.reload() 刷新页面的方法。
14.什么是事件循环(Eventloop)?
js是一门单线程语言,在最新的HTML5中提出了Web-Worker,但js是单线程这一核心仍未改变,不管谁写的代码,都得一句一句的来执行。
当我们打开网站时,网页的渲染过程包括了一大堆任务,比如页面元素的渲染。script脚本的执行,通过网络请求加载图片音乐之类。如果一个一个的顺序执行,遇上任务耗时过长,就会发生卡顿现象。于是,事件循环(Event Loop)应运而生。
事件循环,可以理解为实现异步的一种方式!
是为了协调事件,用户交互,脚本,渲染,网络等,用户代理必须使用本节所述的event loop。
JavaScript 有一个主线程 main thread,和调用栈 call-stack 也称之为执行栈。
所有的任务都会放到调用栈中等待主线程来执行。
待执行的任务就是流水线上的原料,只有前一个加工完,后一个才能进行。
event loops就是把原料放上流水线的工人,协调用户交互,脚本,渲染,网络这些不同的任务。
将待执行任务分为两类:
1.同步任务 2.异步任务
主线程自上而下执行所有代码
(1)同步任务直接进入到主线程被执行,而异步任务则进入到 Event Table 并注册相对应的回调函数
(2)满足指定条件(异步任务完成)后,Event Table 会将这个函数移入 Event Queue
(3)主线程任务执行完了以后,会从Event Queue中读取任务,进入到主线程去执行。
**不断重复的上述过程就是所谓的Event Loop(事件循环)。**
任务队列(task queue)
1.task也被称为macrotask(宏任务),是一个先进先出的队列,由指定的任务源去提供任务。
task任务源非常宽泛,总结来说task任务源包括:
(1).setTimeout (2)setInterval (3).setImmediate (4). I/O (5). UI rendering (6).整体代码script
所以 Task Queue 就是承载任务的队列。而 JavaScript 的 Event Loop 就是会不断地过来找这个 queue,问有没有 task 可以运行运行。
微任务(microtask)
每一个event loop都有一个microtask队列,一个microtask会被排进microtask队列而不是task队列。
microtask 队列和task 队列有些相似,都是先进先出的队列,由指定的任务源去提供任务,不同的是一个 event loop里只有一个microtask 队列。
通常认为是microtask任务源有:
*(1).process.nextTick (2).promises (3).Object.observe (4).MutationObserver
15.promise是什么? 如何实现promise? async 和await ?
Promise 是 JavaScript 异步编程的一种流行解决方案,它的出现是为了解决 回调地狱 的问题.
简单说就是一个容器,里面保存着某个未来才会结束的事件(通常是一个异步操作)的结果。
从语法上说,Promise 是一个对象,从它可以获取异步操作的消息。Promise 提供统一的 API,各种异步操作都可以用同样的方法进行处理。
注: Promise对象有以下几个特点。
(1)对象的状态不受外界影响 (2)一旦状态改变,就不会再变,任何时候都可以得到这个结果。
** (3)它的状态只能改变一次
promise只有两个状态!!!
(1)pending -------->fulfilled 未初始化的----->成功(resolved )
(2) pending------>rejected 未初始化的----->失败(rejected )
无论成功失败都有一个结果,resolved方法–fulfilled ,rejected–失败是rejected.
初始化实例后,对象的状态就变成了pending;
当resolve方法被调用的时候,状态就会由pending变成了成功fulfilled;
当reject方法被调用的时候,状态就会由pending变成失败rejected。
promise新建后会立即执行,它是同步回调函数.
.then方法会在所有的同步任务执行完毕之后,在执行


.catch方法
对于操作异常的程序,Promise专门提供了一个实例方法来处理:catch()方法。
catch() 只接受一个参数,用于处理操作异常后的业务。
Promise使用链式调用,是因为then方法和catch方法调用后,都会返回promise对象。
因为 Promise.prototype.then 和 Promise.prototype.catch 方法返回promise 对象, 所以它们可以被链式调用.
如果 Promise 状态已经变成resolved,再抛出错误是无效的。
Promise.all( ) 方法
应用场景:
我们执行某个操作,这个操作需要得到需要多个接口请求回来的数据来支持,但是这些接口请求之前互不依赖,不需要层层嵌套。这种情况下就适合使用Promise.all( )方法,因为它会得到所有接口都请求成功了,才会进行操作。
注意:如果传入的 promise 中有一个失败(rejected),Promise.all异步地将失败的那个结果给失败状态的回调函数,而不管其它 promise 是否完成。
Promise.finally( ) 方法
finally方法用于指定不管 Promise 对象最后状态如何,都会执行的操作。
该方法是 ES2018 引入标准的。这避免了同样的语句需要在then()和catch()中各写一次的情况。
16.对象
对象 ( 万能的 通用的 可以表示任何事物的)
在js当中,可以说一切皆对象;
对象的概念: 无序的名值对的集合(键值对的集合);
//如果存储一个简单的数据(一个数字,一个字符串) 直接var a = 10;
//如果存储一堆的数据 此时我们想到数组 , 数组就是专门用来存储多个数据用的
//如果我们想要执行一段代码,或者让这段代码有功能,此时我们需要函数
//如果我想描述一个复杂的事物,比如说一个人,一台电脑(需要用到多个属性或者方法才能描述 清楚),此时就要用到对象;
var obj = {} //
var obj = { //定义了一个对象,并添加了一些方法和属性
‘name’: ‘李文博’,
‘age’: ‘18’,
‘gender’: ‘famale’,
sing: function () {
console.log(‘我在唱歌’)
}
}
console.log(obj)
//
var obj1 = { //定义了一个对象(奥特曼),并添加了一些方法和属性
‘name’: ‘奥特曼’,
‘age’: ‘18’,
‘gender’: ‘famale’,
sing: function () {
console.log(‘我会打怪兽’)
}
}
console.log(obj1)
//定义2 构造函数定义
var obj2 = new Object({
name: '李文博',
age: 33
})
console.log(obj2)
// 工厂函数定义 //本质上还是构造函数
function createObject(name, age) {
var obj3 = new Object()
obj3.name = name;
obj3.age = age;
return obj3;
}
console.log(createObject('热巴', 26))
var obj={} //
var cry = "call"
// 增
obj.name= '赛罗'
obj.age= '18'
console.log(obj)
obj["color"] = "yellow" //等于obj.color
obj["cateory"] ="阿拉斯加" //不加引号 就相当于添加一个属性和方法
//若用的是[], 加上引号相当于王对象里面添加 键或者 值
obj[cry] = function(){
console.log('哈哈哈哈')
}
原型对象:

16.1 对this的理解
不同场合this的指向不同
window对象简介
浏览器窗口对象,代码执行的时候所有的一切都是包含在窗口对象下的.
16.2 new关键字实例化对象的
1、开辟内存空间
2、this指向该内存
3、执行函数
4、生成对象实例
17.call,apply和bind的区别和使用?
//对象在调用方法(或属性的时候)的时候,首先会从自己的对象的空间当中去找,如果找到就直接使用了
//如果没有找到,就会去自己的原型的原型对象的原型对象空间当中去找
//自己的构造函数的原型对象的构造函数的原型对象当中去找,如果找到就用,)
//(如果找不到,继续向上,直到找到Object的原型对象为止,找到就用,找不到就报错)
//我们把对象找属性的过程形象的描述为 原型链.
//-----------------
// -----apply和call可以让一个对象使用另外一个对象的方法;
// 让一个实例对象去调用window的方法(也就是我们所说的函数)
// 函数或者方法.apply(对象,【函数的参数】);
// 函数或者方法.call(对象,函数的参数1,函数的参数2);
function BlueCat(name, age, gender) {
this.name = name
this.age = age
this.gender = gender
}
Object.prototype.run = function () {
console.log('跑的很快!')
}
var cat1 = new BlueCat('tom', 2, 'male')
var cat2 = new BlueCat('aimi', 3, 'famale')
function add(a,b){
return a+b ;
}
// window.add(10,20)
// apply/call方法可以改变一个函数的执行对象(执行者)
// 把add的执行者window换成了cat1,让cat1有求和的方法;
//apply的用法两个参数,
//第一个参数代表的是改变后的执行者(执行对象)
//第二参数,是函数所需要的参数,这个参数必须是数组形传过来的;
//------apply-------------
var result= add.apply(cat1,[10,20]);
console.log(result)
//---- call -------------
var result= add.call(cat1,10,20);
console.log(result)
bind
bind必须我们自己去手动调用,他不会自己调用
//bind
// var a = {
// name: "Cherry",
// fn: function (a, b) {
// console.log(a + b)
// }
// }
// var b = a.fn;
// // b.bind(a, 1, 2)
// // //
// var a = {
// name: "Cherry",
// fn: function (a, b) {
// console.log(a + b)
// }
// }
// var b = a.fn;
// b.bind(a, 1, 2)() //
** //bind必须我们自己去手动调用它**
18. JS闭包是什么?
闭包是 指有权访问另外一个函数作用域中的变量的函数.
18.1闭包产生的原因?
首先要明白作用域链的概念,在ES5中只存在两种作用域-全局作用域和函数作用域.
当访问一个变量时,解释器会首先在当前作用域查找标示符,如果没有找到,就去父作用域找,直到找到该变量的标示符或者不在父作用域中,这就是作用域链.
值得注意的是,每一个子函数都会拷贝上级的作用域,形成一个作用域的链条。
举个例子:
var a = 1;
function f1() {
var a = 2
function f2() {
var a = 3;
console.log(a); //3
}
}
结果为: 3
在这段代码中,f1的作用域指向有全局作用域(window)和它本身, 而f2的作用域指向全局作用域(window)、f1和它本身。
而且作用域是从最底层向上找,直到找到全局作用域window为止,如果全局还没有的话就会报错。就这么简单一件事情!
闭包产生的本质就是,当前环境中存在指向父级作用域的引用.
问题1: --------------那是不是只有返回函数才算是产生了闭包呢?、
回到闭包的本质,我们只需要让父级作用域的引用存在即可!
问题2:---------闭包有哪些表现形式?
(1).返回一个函数 (2).作为函数参数传递
(3)在定时器、事件监听、Ajax请求、跨窗口通信、Web Workers或者任何异步中,只要使用了回调函数,实际上就是在使用闭包。
var a = 1;
function foo(){
var a = 2;
function baz(){
console.log(a);
}
bar(baz);
}
function bar(fn){
// 这就是闭包
fn();
}
// 输出2,而不是1
foo();
19.JS如何实现继承?
JS的继承只支持实现继承,实现的方式就是通过原型链。
(1)借用构造函数实现继承,通过call和apply来实现:
这样写的时候子类虽然能够拿到父类的属性值,但是问题是父类原型对象中一旦存在方法那么子类无法继承。那么引出下面的方法。
(2)借助原型链
(3) 使用—寄生组合继承。
(4) 原型式继承
(5)使用ES6的class和extends
20. toString() 为什么可以调用?
var s = new Object(‘1’);
s.toString();
s = null;
答: 由于Symbol和BigInt的出现,对它们调用new都会报错,目前ES6规范也不建议用new来创建基本类型的包装类。
整个过程体现了基本包装类型的性质,而基本包装类型恰恰属于基本数据类型,包括Boolean, Number和String。
21. JS的深拷贝和浅拷贝? 他们跟赋值有何区别?
(1)浅拷贝是创建一个新对象,这个对象有着原始对象属性值的一份精确拷贝。如果属性是基本类型,拷贝的就是基本类型的值,如果属性是引用类型,拷贝的就是内存地址 ,所以如果其中一个对象改变了这个地址,就会影响到另一个对象。
浅拷贝:重新在堆中创建内存,拷贝前后对象的基本数据类型互不影响,但拷贝前后对象的引用类型因共享同一块内存,会相互影响.
(2)深拷贝 是将一个对象从内存中完整的拷贝一份出来, 从堆内存中开辟一个新的区域存放新对象, 且修改新对象不会影响原对象。
对对象中的子对象进行递归拷贝,拷贝前后的两个对象互不影响
总而言之:
浅拷贝只复制指向某个对象的指针,而不复制对象本身,新旧对象还是共享同一块内存。
但深拷贝会另外创造一个一模一样的对象,新对象跟原对象不共享内存,修改新对象不会改到原对象
(3)赋值: 当我们把一个对象赋值给一个新的变量时,赋的其实是该对象的在栈中的地址,而不是堆中的数据。也就是两个对象指向的是同一个存储空间,无论哪个对象发生改变,其实都是改变的存储空间的内容,因此,两个对象是联动的。
代码:
// 对象赋值
// let obj1 = {
// name: ‘砥砺前行’,
// arr: [1, [2, 3], 4],
// };
// let obj2 = obj1;
// obj2.name = “李文博”;
// obj2.arr[1] = [5, 6, 7];
// console.log(‘obj1’, obj1) // obj1 { name: 李文博’, arr: [ 1, [ 5, 6, 7 ], 4 ] }
// console.log(‘obj2’, obj2) // obj2 { name: ‘李文博’, arr: [ 1, [ 5, 6, 7 ], 4 ] }
// // 深拷贝
// let obj1 = {
// name: '砥砺前行',
// arr: [1, [2, 3], 4],
// };
// let obj4 = deepClone(obj1)
// obj4.name = "李文博";
// obj4.arr[1] = [5, 6, 7]; // 新对象跟原对象不共享内存
// // 这是个深拷贝的方法
// function deepClone(obj) {
// if (obj === null) return obj;
// if (obj instanceof Date) return new Date(obj);
// if (obj instanceof RegExp) return new RegExp(obj);
// if (typeof obj !== "object") return obj;
// let cloneObj = new obj.constructor();
// for (let key in obj) {
// if (obj.hasOwnProperty(key)) {
// // 实现一个递归拷贝
// cloneObj[key] = deepClone(obj[key]);
// }
// }
// return cloneObj;
// }
// console.log('obj1', obj1) // obj1 { name: '砥砺前行', arr: [ 1, [ 2, 3 ], 4 ] }
// console.log('obj4', obj4) // obj4 { name: '李文博', arr: [ 1, [ 5, 6, 7 ], 4 ] }
// 浅拷贝
let obj1 = {
name: ‘砥砺前行’,
arr: [1, [2, 3], 4],
};
let obj3 = shallowClone(obj1)
obj3.name = “李文博”;
obj3.arr[1] = [5, 6, 7]; // 新旧对象还是共享同一块内存
// 这是个浅拷贝的方法
function shallowClone(source) {
var target = {};
for (var i in source) {
if (source.hasOwnProperty(i)) {
target[i] = source[i];
}
}
return target;
}
console.log(‘obj1’, obj1) // obj1 { name: ‘砥砺前行’, arr: [ 1, [ 5, 6, 7 ], 4 ] }
console.log(‘obj3’, obj3) // obj3 { name: ‘李文博’, arr: [ 1, [ 5, 6, 7 ], 4 ] }

JS浅拷贝的实现方式
(1)Object.assign() 方法可以把任意多个的源对象自身的可枚举属性拷贝给目标对象,然后返回目标对象。
(2)函数库lodash的_.clone方法
(3)展开运算符是es6的新特性,它提供了一种非常方便的方式来执行浅拷贝,这与 Object.assign ()的功能相同。
(4)Array.prototype.concat()
(5).Array.prototype.slice()
JS深拷贝的实现方式
(1)JSON.parse(JSON.stringify())
(2)函数库lodash的_.cloneDeep方法
(3)jQuery.extend()方法
(4)手写递归方法
22.可视化数据:
(1).什么是数据可视化?
数据可视化研究的是,如何将数据转化成为交互的图形或图像等,以视觉可以感受的方式表达,增强人的认知能力,达到发现、解释、分析、探索、决策和学习的目的。
注:
(1)To B:business(企业客户) (2) To C:customer(一般用户) (3) To G:government(政府客户)
(4)数据可视化的场景和工具
目前互联网公司通常有这么几大类的可视化需求:
1.通用报表 2.移动端图表 3.大屏可视化 4.图编辑&图分析 5.地理可视化
23.GET 请求能传图片吗?
图片一般有两种传输方式:base64 和 file 对象。
** (1)base64 的本质是字符串,而 GET 请求的参数在 url 里面,所以直接把图的 base64 数据放到 url 里面,就可以实现 GET 请求传图片。**
(2) input 输入框拿到的图是 file 对象,图片 file 对象转 base64 :
GET 请求的 url 长度是有限制的,不同的浏览器长度限制不一样,最长的大概是 10k 左右,根据 base64 的编码原理,base64 图片大小比原文件大小大 1/3,所以说 base64 只能传一些非常小的小图,大图的 base64 太长会被截断。
但其实这个长度限制是浏览器给的,而不是 GET 请求本身;
也就说,在服务端,GET 请求长度理论上无限长,也就是可以传任意大小的图片。
GET 和 POST 并没有本质上的区别,他们只是 HTTP 协议中两种请求方式,仅仅是报文格式不同(或者说规范不同)。



24. 前端发送请求的方法:
(1) AJAX 全称为Asynchronous Javascript And XML,就是异步的 JS 和 XML。
ajax 不是新的编程语言,不是新的一门独立的技术,而是一种使用现有标准的新方法。
简单的说ajax就是专门用于前后端交互用的.
通过ajax可以在浏览器中向服务器发送异步请求,最大的优势或特点:无刷新获取数据。
XML 是 可扩展标记语言。 XML 被设计用来传输和存储数据。
XML和HTML类似,不同的是HTML中都是预定义标签,而XML中没有预定义标签,全都是自定义标签,用来表示一些数据。 (预定义标签就是 比如div这种已经定义好的标签)
XML 现在已经被JSON取代了

ajax怎么发送异步请求?
(1)使用原生js发送ajax_get的步骤:
1. 实例化一个XMLHttpRequest对象
2. 绑定一个名onreadystatechange事件监听-------和发请求的人约定好成功/失败做什么
3. 调用open方法 --------用什么方法发?给谁发?带什么过去?
5. 调用send方法 --------发送请求
(2)使用xhr发送请求, 以及内部状态说明
xhr的状态变化几次. 只需要看输出几次就能判断了.
xhr本身有5中状态: 0. 1 . 2. 3. 4
xhr对象本身有5种状态: xhr“诞生”的那一刻就是0状态
0: xhr对象在实例化出来的那一刻,就已经是0状态,代表着xhr是初始化状态。
1: send方法还没有被调用,即:请求没有发出去,此时依然可以修改请求头。
2: send方法被调用了,即:请求已经发出去了,此时已经不可以再修改请求头。
3: 已经回来一部分数据了,如果是比较小的数据,会在此阶段一次性接收完毕,较大数据,有待于进一步接收。
4: 数据完美的回来了。
(3)axios 是专门用来发请求的.
如果在浏览器端发ajax请求; 如果在node服务器端就可以发http请求**
axios 是 前端最流行的ajax请求库, react/vue官方都推荐使用axios发ajax请求
axios的特点
- 基本promise的异步ajax请求库
- 浏览器端/node端都可以使用
- 支持请求/响应拦截器
- 支持请求取消
- 请求/响应数据转换
- 批量发送多个请求 (个人添加promise的all方法)
axios 是一个基于 promise 的 HTTP 库(所以axios后面可以.then())
finally是新语法.就是不论成功还是失败都会调用.这个方法一般放到最后
解决IE发送请求出现的问题:
解决方法就是加个时间戳. 这样地址永远是不一样的,这样就不走缓存了
注意只能用这种方式拼接字符串,不能用ES6模板字符串, IE不支持模板字符串…不再演示
取消上一次请求: 有3种情况
(1)

(2)如果来不及,拒之门外,请求已经到达了服务器,且服务器已经给出响应。
如下就是能够send(发送请求).然后1秒后终止.
服务器3秒后返回验证码.这种情况就是请求已经发出去了.
你中止后.如下服务器已经发送了验证码.但是浏览器是收不到的.简单说就是你发出去了,我不要了
(3)也存在根本不起作用的情况。
如下就是不起作用的情况.你发送请求.3秒后中止,但是服务器是1秒后就返回了.这个时候数据已经回来了.和没设置中止没什么区别
24.1 跨域问题怎么解决?
ajax本身不能跨域.
(1)什么是跨域?
原因是浏览器为了安全,而采用的同源策略(Same origin policy)
(2)什么是同源策略?
1. 同源策略是由Netscape提出的一个著名的安全策略,现在所有支持Js的浏览器都会使用这个策略。
2. Web是构建在同源策略基础之上的,浏览器只是针对同源策略的一种实现。
3. 所谓同源是指:协议,域名(IP),端口必须要完全相同
即:协议、域名(IP)、端口都相同,才能算是在同一个域里。
http默认端口号是80. 下面这个没写相当于http://study.cn:80
没有同源策略的危险场景
危险场景:
有一天你刚睡醒,收到一封邮件,说是你的银行账号有风险,赶紧点进www.yinghang.com改密码。你着急的赶紧点进去,还是熟悉的银行登录界面,你果断输入你的账号密码,登录进去看看钱有没有少了,睡眼朦胧的你没看清楚,平时访问的银行网站是www.yinhang.com,而现在访问的是www.yinghang.com,随后你来了一条短信,钱没了,这个钓鱼网站做了什么呢?大概是如下思路:
非同源(也就是跨域)受到哪些限制?
- Cookie不能读取;
- DOM无法获得;
- Ajax请求不能发送
ajax跨域会被拦截.
原因是ajax发请求需要通过ajax引擎,而受到同源策略的限制(或者遵守同源策略的规定)
form表单跨域不会被拦截,不受同源策略的限制
(1)用 cors解决跨域问题.全称"跨域资源共享"(Cross-origin resource sharing)。
在服务器中设置响应头
access(访问) control(控制) allow(允许) origin(这个和git里面的一样 指的是远程),
大致意思是允许http://127.0.0.1:5501这个远程 访问
(2)jsonp解决跨域问题
jsonp解决发送请求跨域问题:
要明确的是:jsonp不是一种技术,而是程序员“智慧的结晶”(利用了标签请求资源不受同源策略限制的特点). jsonp需要前后端人员互相配合。
原理:利用了script标签发请求不受同源策略的限制。所以不会产生跨域问题
套路:动态构建script节点,利用节点的src属性,发出get请求,从而绕开ajax引擎
弊端:
(1).只能解决get请求跨域的问题。(标签能发的请求全是get请求)
(2).后端工程师必须配合前端
有这样一种感觉:前端定义函数,后端“调用”。后端返回的数据,前端以js格式解析,并且运行。
在vue中发送请求??
Cookie
本质就是一个【字符串】,里面包含着浏览器和服务器沟通的信息(交互时产生的信息)。
存储的形式以:【key-value】的形式存储。
浏览器会自动携带该网站的cookie,只要是该网站下的cookie,全部携带。
cookie的分类:
–会话cookie(关闭浏览器后,会话cookie会自动消失,会话cookie存储在浏览器运行的那块【内存】上)。
–持久化cookie:(看过期时间,一旦到了过期时间,自动销毁,存储在用户的硬盘上,备注:如果没有到过期时间,同时用户清理了浏览器的缓存,持久化cookie也会消失)。
工作原理:
-
--当浏览器第一次请求服务器的时候,服务器可能返回一个或多个cookie给浏览器 -
--浏览器判断cookie种类 -
--会话cookie:存储在浏览器运行的那块内存上 -
--持久化cookie:存储在用户的硬盘上 -
--以后请求该网站的时候,自动携带上该网站的所有cookie(无法进行干预) -
--服务器拿到之前自己“种”下cookie,分析里面的内容,校验cookie的合法性,根据cookie里保存的内容,进行具体的业务逻辑。 -
**应用:** -
**解决http无状态的问题(例子:7天免登录,一般来说不会单独使用cookie,一般配合后台的session存储使用)**
不同的语言、不同的后端架构cookie的具体语法是不一样的,但是cookie原理和工作过程是不变的。 备注:cookie不一定只由服务器生成,前端同样可以生成cookie,但是前端生成的cookie几乎没有意义。

使用cookie,还是有一定局限性的.如下用户可以手动禁止使用cookie


关于session
1.是什么? 标准来说,session这个单词指的是会话。
持久化的cookie存硬盘里 , 会话cookie存浏览器内存里, Session 存在服务器的内存里
(1).前端通过浏览器去查看cookie的时候,会发现有些cookie的过期时间是:session,意味着该cookie是会话cookie。
(2).后端人员常常把【session会话存储】简称为:session存储,或者更简单的称为:session
特点:
-
1.存在于服务端 -
2.存储的是浏览器和服务器之间沟通产生的一些信息
默认session的存储在服务器的内存中,每当一个新客户端发来请求,服务器都会新开辟出一块空间,供session会话存储使用。
Cookie, SessionStorage, LocalStorage这三者都可以被用来在浏览器端存储数据,而且都是字符串类型的键值对!
注意:session和SessionStorage不是一个概念!!!在服务端有一种存储方式叫做:session
SessionStorage和LocalStorage都是浏览器本地存储,统称为Web Storage,存储内容大小一般支持5-10MB
浏览器端通过 Window.sessionStorage 和 Window.localStorage 属性来实现本地存储机制。
SessionStorage存储的内容会随着浏览器窗口关闭而消失。
LocalStorage存储的内容,需要手动清除才会消失。
.工作流程:
-
--第一次浏览器请求服务器的时候,服务器会开辟出一块内存空间,供session会话存储使用。 -
--返回响应的时候,会自动返回一个cookie(有时候会返回多个,为了安全),cookie里包含着,上一步产生会话存储“容器”的编号(id) -
--以后请求的时候,会自动携带这个cookie,给服务器。 -
--服务器从该cookie中拿到对应的session的id,去服务器中匹配。 -
--服务器会根据匹配信息,决定下一步逻辑 -
**备注:1.一般来说cookie一定会配合session使用。 -
2.服务端一般会做session的持久化,防止由于服务器重启,造成session的丢失。 -
3.session什么时候销毁? -
(1).服务器没有做session的持久化的同时,服务器重启了。 -
(2).给客户端种下的那个用于保存session编号的cookie销毁了,随之服务器保存的session销毁(不管是否做了session的持久化)。 -
(3).用户主动在网页上点击了“注销” “退出登录”等等按钮。
跨页签通信: 简单说就是多个同源的网页能够数据共享
缓存
- 缓存理解
- 缓存定义:
- 浏览器在本地磁盘上将用户之前请求的数据存储起来,当访问者再次需要改数据的时候无需再次发送请求,直接从浏览器本地获取数据
缓存的好处: - 减少请求的个数
- 节省带宽,避免浪费不必要的网络资源
- 减轻服务器压力
- 提高浏览器网页的加载速度,提高用户体验**
缓存分类
强缓存
- 不会向服务器发送请求,直接从本地缓存中获取数据**
- 请求资源的的状态码为: 200 ok(from memory cache) disk cache也是
如下访问过百度之后,再次访问百度,就是走的强缓存
协商缓存
1. 向服务器发送请求,服务器会根据请求头的资源判断是否命中协商缓存
2. 如果命中,则返回304状态码通知浏览器从缓存中读取资源**
3**. 强缓存 & 协商缓存的共同点
1. 都是从浏览器端读取资源**
4. 强缓存 VS 协商缓存的不同点
1. 强缓存不发请求给服务器
2. 协商缓存发请求给服务器,根据服务器返回的信息决定是否使用缓存
一、DNS解析(优先走缓存):
(以下5步,不是按照顺序一下子进行完. 而是到任意一步找到就会去 二(TCP) )
-
1.找浏览器DNS缓存解析域名 -
2.找本机DNS缓存:(备注:查看本机DNS缓存命令:ipconfig/displaydns > C:/dns.txt) -
3.找路由器DNS缓存 -
4.找运营商DNS缓存(80%的DNS查找,到这一步就结束) -
5.递归查询 (查询全球13台根DNS服务器)
二、进行TCP(协议)连接,三次握手(根据上一步请求回来的ip地址,去联系服务器)
-
第一次握手:由浏览器发给服务器,我想和你说话,你能“听见”嘛? -
第二次握手:由服务器发给浏览器,我能听得见,你说吧! -
第三次握手:由浏览器发给服务器,好,那我就开始说话。
三、发送请求(请求报文)
*
四、得到响应(响应报文)
*
五、浏览器开始解析html
-
--预解析:将所有外部的资源,发请求出去 -
--解析html,生成DOM树 -
--解析CSS,生成CSS树 -
--合并成一个render树 -
--js是否操作了DOM或样式 -
--有:进行重绘重排(不好,1.尽量避免;2.最小化重绘重排) -
--没有:null -
--最终展示界面
六、断开TCP连接,四次挥手(确保数据的完整性)
-
第一次挥手:由浏览器发给服务器,我的东西接受完了,你断开吧。 -
第二次挥手:--由服务器发给浏览器,我还有一些东西没接收完,你等一会,我接收好了我告诉你. --由服务器发给浏览器,我的东西接收完了,但是你还得等一会,我要验证数据的完整性,验证完了我告诉你。 -
第三次挥手:由服务器发给浏览器,我接收完(验证完)了,你断开吧。 -
第四次挥手:由浏览器发给服务器,好的,那我断开了。
备注:为什么握手要三次,挥手要四次?
-
**握手之前,还没有进行数据的传输,确保握手就可以了。 -
挥手之前,正在进行数据的传输,为了确保数据的完整性,必须多经历一次验证(继续接收)**

-----函数递归,就是在一个函数里面调用函数自己本身。
js的for循环实现 99乘法口诀表

数组的方法 :
(1) Array.isArray(), 用于确定传递的值是否是一个 Array(数组)。
(2) filter() 方法创建一个新数组, 其包含通过所提供函数实现的测试的所有元素。
(3)find()方法返回数组中满足提供的测试函数的第一个元素的值。否则返回 undefined。
(4)迭代数组 , for…of语句在可迭代对象(包括 Array,Map,Set,String,TypedArray,arguments 对象等等
(5) join() 方法将一个数组(或一个类数组对象)的所有元素连接成一个字符串并返回这个字符串。
(6) reverse() 方法将数组中元素的位置颠倒,并返回该数组。数组的第一个元素会变成最后一个,数组的最后一个元素变成第一个。该方法会改变原数组
slice() 方法返回一个新的数组对象,这一对象是一个由 begin 和 end 决定的原数组的浅拷贝
ES6新增的 set,map的方法
ES6提供了新的数据结构Set。它类似于数组,但是成员的值都是唯一的,没有重复的值。
Set 是一种叫做集合的数据结构,Map 是一种叫做字典的数据结构。
集合 与 字典 的区别:
共同点:集合、字典 可以储存不重复的值
不同点:集合 是以 [value, value]的形式储存元素,字典 是以 [key, value] 的形式储存
Set 对象允许你储存任何类型的唯一值,无论是原始值或者是对象引用。
Set 和 Map 主要的应用场景在于 数据重组 和 数据储存。
JS面向对象是什么?
首先,js面向对象是一种思想;
对象到底是什么,我们可以从两次层次来理解。
(1) 对象是单个事物的抽象。
一本书、一辆汽车、一个人都可以是对象,一个数据库、一张网页、一个与远程服务器的连接也可以是对象。当实物被抽象成对象,实物之间的关系就变成了对象之间的关系,从而就可以模拟现实情况,针对对象进行编程。
(2) 对象是一个容器,封装了属性(property)和方法(method)。
属性是对象的状态,方法是对象的行为(完成某种任务)。比如,我们可以把动物抽象为animal对象,使用“属性”记录具体是那一种动物,使用“方法”表示动物的某种行为(奔跑、捕猎、休息等等)。
在实际开发中,对象是一个抽象的概念,可以将其简单理解为:数据集或功能集。
ECMAScript-262 把对象定义为:无序属性的集合,其属性可以包含基本值、对象或者函数。 严格来讲,这就相当于说对象是一组没有特定顺序的值。对象的每个属性或方法都有一个名字,而每个名字都映射到一个值。
提示:每个对象都是基于一个引用类型创建的,这些类型可以是系统内置的原生类型,也可以是开发人员自定义的类型。
面向对象不是新的东西,它只是过程式代码的一种高度封装,目的在于提高代码的开发效率和可维 护性。
它将真实世界各种复杂的关系,抽象为一个个对象,然后由对象之间的分工与合作,完成对真实世界的模拟。
面向对象编程 —— Object Oriented Programming,简称 OOP
在面向对象程序开发思想中,每一个对象都是功能中心,具有明确分工,可以完成接受信息、处理数据、发出信息等任务。 因此,**面向对象编程具有灵活、代码可复用、高度模块化等特点,容易维护和开发,**比起由一系列函数或指令组成的传统的过程式编程(procedural programming),更适合多人合作的大型软件项目。
面向对象与面向过程的区别:
面向过程就是亲力亲为,事无巨细,面面俱到,步步紧跟,有条不紊
面向对象就是找一个对象,指挥得结果
面向对象将执行者转变成指挥者
面向对象不是面向过程的替代,而是面向过程的封装
面向对象的特性: 封装性 , 继承性 , [多态性] 抽象
CSS实现遮罩层
https://blog.csdn.net/mannix_lei/article/details/80180809
箭头函数, 也叫lambda表达式
三.Vue框架篇
1.认识Vue:
Vue是一个渐进式JS框架
作者: 尤雨溪(一位华裔前Google工程师)
作用: 动态构建(显示)用户界面
1.1 Vue的特点: 是一个构建数据的视图集合,大小只有几十kb;
(1)双向数据绑定:保留了angular的特点,在数据操作方面更为简单;
(2)组件化:保留react的优点,实现html的封装和重用,在构建单页面应用方面有着独特的优势;
(3)视图,数据,结构分离:使数据的更改更为简单,不需要进行逻辑代码的修改,只需要操作数据就能完成相关操作;
(4)虚拟DOM: dom操作是非常耗费性能的,不再使用原生的dom操作节点,极大的解放dom操作,但具体操作的还是dom不过是换了另一种方式;
(5)运行速度更快些: 和react比较而言,同样是操作虚拟dom,就性能而言,Vue存在很大的优势。

MVVM模式:

2.Vue指令: v-html,v-for,v-text,v-if,v-show, v-bind(简写:),v-on(简写@),v-block,v-once 等.
(1)v-html: v-html用于输出html,它与v-text区别在于v-text输出的是纯文本,浏览器不会对其再进行html解析,但v-html会将其当html标签解析后输出。
(2) v-text: 是用于操作纯文本,它会替代显示对应的数据对象上的值 (此处为单向绑定),数据对象上的值改变,插值会发生变化;但是当插值发生变化并不会影响数据对象的值.v-text不会解析html
(3) v-model:(双向数据绑定) 通常用于表单组件的绑定,例如input,select等.如果用于表单控件以外标签是没有用的
(4) v-once: 只渲染元素和组件一次,随后的渲染,使用了此指令的元素/组件及其所有的子节点,都会当作静态内容并跳过,这可以用于优化更新性能。(首次渲染后,即使数据发生变化,也不会被重新渲染。一般用于静态内容展示)。
(5) v-cloak: 使用v-cloak可以解决Vue插值表达式闪烁问题
(6) v-bind(简写:)
v-bind:href=’‘url’’ === ============================= :href=" url"
(7) v-on(简写@)
v-on:click=“click” ================= @click=“click” 


.prevent : 阻止事件的默认行为 event.preventDefault()
.stop : 停止事件冒泡 event.stopPropagation()

按键修饰符:

特殊知识点:
1. data: { } // 包含多个可变数据的对象, 相当于state, 为模板页面提供基础数据.
2. methods: 就是事件的回调函数,包含多个事件的回调函数.
3. computed: 计算属性,在computed属性对象中定义计算属性的方法在页面中使用{{方法名}}来显示计算的结果
4. 计算属性高级:
通过getter/setter实现对属性数据的显示和监视
计算属性computed : 存在缓存, 多次读取只执行一次getter计算
5. watch(监视属性) :
通过通过vm对象的$watch()或watch配置来监视指定的属性
当属性变化时, 回调函数自动调用, 在函数内部进行计算
js通用技巧— 回调函数的问题
弄清楚回调函数的3个问题?
1. 什么时候回调执行?
2. 它的作用是什么?
3. 函数中的this是谁?
一个组件对象就是一个小的vm
组件内回调函数的this是组件对象
模板中获取数据读取组件对象的对应属性值
注:
(1) Vue的props属性用于父组件向子组件传递值,是一个高频使用的特性。
props 是我们在不同组件之间传递变量和其他信息的方式。这类似于在 JS 中,我们可以将变量作为参数传递给函数.
props 的两个主要特点:
1.props 通过组件树传递给后代(而不是向上传递) 2.props 是只读的,不能修改
(因此数据只能从父组件流向子组件)
可以在以下位置使用组件的props:
watch 中; 生命周期 hook ; method ; computed 中
使用$children可以在父组件中访问子组件。
组件之间传递数据的方式有哪几种?
(1)父组件向子组件传值props
(2)子组件向父组件传值$emit,也可以用来调用父组件中的方法
(3)兄弟组件之间传值=VueX
(4)父组件调用子组件的方法= ref
(5)可以通过 $parent和 $children获取父子组件参数
(2) data数据

3.为什么Vue组件中data必须是一个函数?
当对象为引用类型,当复用组件时,由于数据对象都指向同一个data对象,当在一个组件中修改data时,其他重用的组件中的data会同时被修改;
而使用返回对象的函数,由于每次返回的都是一个新对象(Object的实例),引用地址不同,则不会出现这个问题。
4.Vue 中v-if 和v-show 有什么区别?
区别:
(1)v-if 在条件切换时,会对标签进行适当的创建和销毁,而v-show则仅在初始化时加载一次,因此v-if的开销相对来说会比v-show大。
(2)v-if是惰性的,只有当条件为真时才会真正渲染标签,适用于 ------在运行时很少改变条件,不需要频繁切换条件的场景; (有较高的性能消耗)如果初始条件不为真,则v-if不会去渲染标签。
v-show 则无论初始条件是否成立,都会渲染标签,它仅仅做的只是简单的CSS切换;适用于需要------非常频繁切换条件的场景。)
注:
v-else: 可以使用 v-else 指令来表示 v-if 的’‘else 块’’;
v-else 元素必须紧跟在带 v-if 或者 v-else-if 的元素的后面,否则它将不会被识别。
5.计算属性computed和watch监听的区别?
计算属性computed:
(1)支持缓存,只有依赖数据发生改变,才会重新进行计算
(2)不支持异步,当computed内有异步操作时无效,无法监听数据的变化
(3)computed 属性值会默认走缓存,计算属性是基于它们的响应式依赖进行缓存的,也就是基于data中声明过或者父组件传递的props中的数据通过计算得到的值
(4)如果一个属性是由其他属性计算而来的,这个属性依赖其他属性,是一个多对一或者一对一,一般用computed
(5)如果computed属性属性值是函数,那么默认会走get方法;函数的返回值就是属性的属性值;在computed中的,属性都有一个get和一个set方法,当数据变化时,调用set方法。
监听/监视watch:
(1)不支持缓存,数据变,直接会触发相应的操作;
(2)watch支持异步;监听的函数接收两个参数,第一个参数是最新的值;第二个参数是输入之前的值;
(3)当一个属性发生变化时,需要执行对应的操作;一对多;
(4)监听数据必须是data中声明过或者父组件传递过来的props中的数据,当数据变化时,触发其他操作,函数有两个参数:
(4.1) immediate(立即调用函数):组件加载立即触发回调函数执行()
watch: {
firstName: {
handler(newName, oldName) {
this.fullName = newName + ’ ’ + this.lastName;
},
// 代表在wacth里声明了firstName这个方法之后立即执行handler方法
immediate: true
}
}
watch: {
obj: {
handler(newName, oldName) {
console.log(‘obj.a changed’);
},
immediate: true, //立即调用
deep: true //深度监视
}
}
(4.2)deep(深度监视):
deep的意思就是 深入观察(深度监视),监听器会一层层的往下遍历,给对象的所有属性都加上这个监听器,但是这样性能开销就会非常大了,任何修改obj里面任何一个属性都会触发这个监听器里的 handler
*优化:我们可以使用字符串的形式监听;
watch: {
‘obj.a’: {
handler(newName, oldName) {
console.log(‘obj.a changed’);
},
immediate: true,
// deep: true
}
}
注: 这样Vue.js才会一层一层解析下去,直到遇到属性a,然后才给a设置监听函数。
6. Vue-loader是什么?使用它的用途有哪些?
Vue文件的一个加载器,跟template/js/style转换成js模块.
7.$nextTick是什么?
Vue实现响应式并不是数据发生变化后,DOM立即变化,而是按照一定的策略来进行dom更新。
$nextTick 是在下次 DOM 更新循环结束之后执行延迟回调,
在修改数据之后使用nextTick,则可以在回调中获取更新后的 DOM
8. v-for循环中key的作用?
key="唯一标识"
为了给Vue一个提示,以便它能跟踪每个节点的身份,从而重用和重新排序现有元素,你需要为每项提供一个唯一 key 属性。
唯一标识可以是item里面id index等,因为vue组件高度复用增加Key,可以标识组件的唯一性,为了更好地区别各个组件, key的作用主要是为了高效的更新虚拟DOM!!!
key属性的类型只能为 string或者number类型。
(当Vue用 v-for 正在更新已渲染过的元素列表是,它默认用“就地复用”策略。如果数据项的顺序被改变,Vue将不是移动DOM元素来匹配数据项的改变,而是简单复用此处每个元素,并且确保它在特定索引下显示已被渲染过的每个元素。)
key 的特殊属性主要用在Vue的虚拟DOM算法,在新旧nodes对比时辨识VNodes。
如果不使用 key,Vue会使用一种最大限度减少动态元素并且尽可能的尝试修复/再利用相同类型元素的算法。
使用key,它会基于key的变化重新排列元素顺序,并且会移除 key 不存在的元素。
9.Vue的双向数据绑定原理是什么?
vue.js 是采用** 数据劫持结合发布者-订阅者模式**的方式,**通过Object.defineProperty()**来劫持各个属性的setter,getter,在数据变动时发布消息给订阅者,触发相应的监听回调。主要分为以下几个步骤:
Vue 主要通过以下 4 个步骤来实现数据双向绑定的:
(1)需要observer的数据对象进行递归遍历,包括子属性对象的属性,都加上setter和getter这样的话,给这个对象的某个值赋值,就会触发setter,那么就能监听到了数据变化
(2)compile解析模板指令,将模板中的变量替换成数据,然后初始化渲染页面视图,并将每个指令对应的节点绑定更新函数,添加监听数据的订阅者,一旦数据有变动,收到通知,更新视图
(3)Watcher订阅者是Observer和Compile之间通信的桥梁,主要做的事情是:
①在自身实例化时往属性订阅器(dep)里面添加自己
②自身必须有一个update()方法
③待属性变动dep.notice()通知时,能调用自身的update()方法,并触发Compile中绑定的回调,则功成身退。
**(4)MVVM作为数据绑定的入口,整合Observer、Compile和Watcher三者,**通过Observer来监听自己的model数据变化,通过Compile来解析编译模板指令,最终利用Watcher搭起Observer和Compile之间的通信桥梁,达到数据变化 -> 视图更新;视图交互变化(input) -> 数据model变更的双向绑定效果。
9.1 Vue双向数据绑定, 2个重要特点:
(1)只要改变data中的数据值, 界面就自动更新 ===> 数据(单向)绑定 data ==> 模板页面
(2)改变页面输入数据, data中的数据也可以自动改变 ===> 页面 ==> data
10. Vue如何获取dom?
先给标签设置一个ref值,再通过this.$refs.domName获取.
11.常用的事件修饰符
.stop:-----阻止冒泡.
.prevent:-----阻止默认行为.
.self:------仅绑定元素自身触发
.once: -------2.1.4 新增,只触发一次
passive: 2.3.0 新增,滚动事件的默认行为 (即滚动行为) 将会立即触发,不能和.prevent 一起使用
.sync ------修饰符
12. Vue初始化页面闪动问题

13. v-on可以监听多个方法吗?
可以!
来个例子:
<input type="text" v-on="{ input:onInput,focus:onFocus,blur:onBlur, }">
14.Vue.js的template编译?
简而言之,就是先转化成AST树,再得到的render函数返回VNode(Vue的虚拟DOM节点)
15.scss是什么?是css预编译工具 在vue.cli中的安装使用步骤是?有哪几大特性?
css的预编译,使用步骤如下:
第一步:用npm 下三个loader(sass-loader、css-loader、node-sass)
第二步:在build目录找到webpack.base.config.js,在那个extends属性中加一个拓展.scss
第三步:还是在同一个文件,配置一个module属性
第四步:然后在组件的style标签加上lang属性 ,例如:lang=”scss”
特性主要有:
可以用变量,例如($变量名称=值;
可以用混合器,例如();
可以嵌套.
16.Vue开发过程中的问题 :---------assets和static的区别
这两个都是用来存放项目中所使用的静态资源文件。
两者的区别:
(1)assets 中的文件在运行npm run build的时候会打包,简单来说就是会被压缩体积,代码格式化之类的。 打包之后也会放到static中。
(2)static(静态资源)中的文件, 在运行npm run build的时候则不会被打包。
注: 区分使用webpack的 生产环境与开发环境
使用生产环境:
npm run build ==> webpack
1). 在内存中进行编译打包, 生成内存中的打包文件
2). 保存到本地(在本地生成打包文件) ===> 此时还不能通过浏览器来访问, 需要启动服务器运行
他们两个共同的特点是都在内存中打包
使用开发环境
npm run dev ==> webpack-dev-server
1). 在内存中进行编译打包, 生成内存中的打包文件
2). 调动服务器, 运行内存中的打包文件 ===> 可以通过浏览器虚拟路径访问
17.Vuex是什么?
Vuex 是一个专为 Vue.js应用程序开发的状态管理模式。它采用集中式存储管理应用的所有组件的状态,并以相应的规则保证状态以一种可预测的方式发生变化。
Vuex 也集成到 Vue 的官方调试工具 devtools extension,提供了诸如零配置的 time-travel 调试、状态快照导入导出等高级调试功能。
Vuex 用来管理, 多组件共享数据 , 从后台获取的数据.


17.1 Vuex中有几个核心属性,分别是什么?
**一共有5个核心属性,**分别是:
(1) state : 唯一数据源, Vue 实例中的 data 遵循相同的规则;
(2) getters : 可以认为是 store 的计算属性,就像计算属性一样,getter 的返回值会根据它的依赖被缓存起来,且只有当它的依赖值发生了改变才会被重新计算. getter 会暴露为 store.getters 对象,你可以以属性的形式访问这些值.
const store = new Vuex.Store({
state: {
todos: [
{ id: 1, text: ‘…’, done: true },
{ id: 2, text: ‘…’, done: false }
]
},
getters: {
doneTodos: state => {
return state.todos.filter(todo => todo.done)
}
}
})
store.getters.doneTodos // -> [{ id: 1, text: '...', done: true }]
(3) mutation : 更改 Vuex 的 store 中的状态的唯一方法是提交 mutation,非常类似于事件,通过store.commit 方法触发

(4) action:

(5) module: 由于使用单一状态树,应用的所有状态会集中到一个比较大的对象。当应用变得非常复杂时,store 对象就有可能变得相当臃肿。为了解决以上问题,Vuex 允许我们将 store 分割成模块(module)。
const moduleA = {
state: () => ({ ... }),
mutations: { ... },
actions: { ... },
getters: { ... }
}
const moduleB = {
state: () => ({ ... }),
mutations: { ... },
actions: { ... }
}
const store = new Vuex.Store({
modules: {
a: moduleA,
b: moduleB
}
})
store.state.a // -> moduleA 的状态
store.state.b // -> moduleB 的状态

17.1 ajax请求代码应该写在组件的methods中还是Vuex的actions中?
(1)若请求来的数据不被其他组件公用,仅仅在请求的组件内使用,就不需要放入Vuex 的state里。
(2)如果被其他地方复用,这个很大几率上是需要的,如果需要,请将请求放入action里,方便复用。
17.2 从Vuex中获取的数据能直接更改吗?
不能, 你需要进行浅拷贝后更改,否则报错;
17.3 -----Vuex的严格模式是什么,有什么作用,怎么开启?

17.4 ----- Vuex中的 mutation和action有什么区别?
(1) action 提交的是 mutation,而不是直接变更状态。mutation可以直接变更状态.
(2) action 可以包含任意异步操作; mutation只能是同步操作.
(3)提交方式不同,action是this.store.dispath 来提交。mutation是this.$store.commit 来提交
(4)接收参数不同,mutation是state, action是context

18.Vue项目开发中过的常用优化:
(1) v-If 和 v-show 理论上都是作用于元素的显示隐藏,一个是直接对DOM操作,一个是通过CSS的 display 来操作的,在项目中大部分的时候我都是直接使用 v-If 直接代替使用 v-Show ,只有当DOM频繁进行显示和隐藏的时候,但是这种场景非常少见,我只在信息推送优先级中使用过,项目中一直通过 WebSocket 推的消息进行消息的场景遇到过,频繁推送不同类型的通知。
(2) v-for 和v-if 不要一起使用
v-for 的优先级其实是比 v-if 高的,所以当两个指令出现来一个DOM中,那么 v-for 渲染的当前列表,每一次都需要进行一次 v-if 的判断。而相应的列表也会重新变化,这个看起来是非常不合理的。因此当你需要进行同步指令的时候。
18.Vue的生命周期实例
-----------------------请详细说下你对vue生命周期的理解?
(总共11个,常用的8个, 不常用的3个 : activated(已激活的), deactivated (已失效的), errorCaptured(已捕获错误))
常用的8个声明周期钩子函数:
注: 总共分为4个阶段,创建前/后,载入前/后,更新前/后,销毁前/后。
(1)创建前/后:
在beforeCreate阶段,Vue实例的挂载元素el和数据对象data都为undefined,还未初始化。
在created阶段vue实例的数据对象data有了,挂载元素el为undefined,还未初始化。
(2)载入前/后:
在beforeMount阶段,Vue实例的$el和data都初始化了,但还是挂载之前为虚拟的dom节点,data.message还未替换。
在mounted阶段,Vue实例挂载完成,data.message成功渲染。
(3)更新前/后:
当data变化时,会触发beforeUpdate和updated方法
(4)销毁前/后:
在执行destroy方法后,对data的改变不会再触发周期函数,说明此时Vue实例已经解除了事件监听以及和dom的绑定,但是dom结构依然存在.
注: created和mounted区别:
在created中,data和methods都已经初始化了! 最早,只能在created中操作
注: mounted是, 只要执行完了(mounted)挂载,就代表着整个 Vue实例初始化阶段完成了.
(此时组件脱离–创建阶段, 已经进入-----运行阶段)

19.
20.说说你使用 Vue 框架踩过最大的坑是什么? 怎么解决的?
21.数据请求是怎么抛出异常
20.Vue的导航守卫
导航守卫是什么?
导航守卫是vue-router提供的下面2个方面的功能
a. 监视路由跳转
b. 控制路由跳转
在项目开发中每一次路由的切换或者页面的刷新都需要判断用户是否已经登录,前端可以判断,后端也会进行判断的,我们前端最好也进行判断。
参数或查询的改变并不会触发进入/离开的导航守卫。
Vue-router提供导航钩子:
全局前置导航钩子 beforeEach和全局后置导航钩子 afterEach,他们会在路由即将改变前和改变后进行触发。所以判断用户是否登录需要在beforeEach导航钩子中进行判断。
导航钩子有3个参数:
1、to: 即将要进入的目标路由对象;
2、from: 当前导航即将要离开的路由对象;
3、next :调用该方法后,才能进入下一个钩子函数(afterEach)。
**next()//直接进to 所指路由
next(false) //中断当前路由
next('route') //跳转指定路由
next('error') //跳转错误路由**
路由守卫: 说白了就是路由拦截,在地址栏跳转之前 之后 跳转的瞬间 干什么事
**全局守卫,**就是全局的,整个项目所有路由,跳转所用到的守卫(拦截),设置了全局守卫之后,只要路由(浏览器地址栏)发生变化就会触发的事件
全局守卫分为二部分: 前置守卫(跳转之前), 后置钩子(跳转之后)
to: 即将进入的地址,比如说 点击按钮 从 A 跳转到 B ,那么to就是 B 的路由对象,
from: 要离开的地址,比如说 点击按钮 从 A 跳转到 B ,那么to就是 A 的路由对象,
next: 就是在跳转的时候要执行的事件,
路由独享守卫
他只是单独的这个组件独享的,局部的,不是全局的,只有这个路由在进行跳转的时候,才会触发的,其他的组件,路由进行跳转的时候不执行这个方法
独享守卫有三个方法:
(1)beforeRouteEnter 在渲染该组件的对应路由被 confirm 前调用 就是页面跳转前要执行的方法 要干的事
(2)beforeRouteUpdate 在当前路由改变,但是该组件被复用时调用 就是当页面 在A 跳转到 B 的一瞬间 要干的事
(3)beforeRouteLeave 导航离开该组件的对应路由时调用 就是在跳转完成之后 要干的事
这三个方法 都有三个参数 (to, from, next) 跟全局守卫的 三个参数用法一样
其中 beforeRouteEnter 守卫 不能 访问 this 其他两个守卫可以访问到this
https://www.cnblogs.com/hyl1991/p/10609193.html
使用声明式导航 -----router-link; 使用编程式导航 router.push()
this.route和this.route和this.router的区别
在Vue中this.route是路由[参数对象],所有路由中的参数params,query都属于他;
this.router是一个路由[导航对象],用它可以方便的使用JS代码实现路由的前进或后退,跳转到新的URL地址。
21. 虚拟DOM 以及它的优缺点.

缺点:
无法进行极致优化: 虽然虚拟 DOM + 合理的优化,但足以应对绝大部分应用的性能需求;
但在一些性能要求极高的应用中虚拟 DOM 无法进行针对性的极致优化。
优点:
(1) 保证性能下限:
框架的虚拟 DOM 需要适配任何上层 API 可能产生的操作,它的一些 DOM 操作的实现必须是普适的,所以它的性能并不是最优的;但是比起粗暴的 DOM 操作性能要好很多,因此框架的虚拟 DOM 至少可以保证在你不需要手动优化的情况下,依然可以提供还不错的性能,即保证性能的下限.
(2)无需手动操作 DOM:
我们不再需要手动去操作 DOM,只需要写好 View-Model 的代码逻辑,框架会根据虚拟 DOM 和 数据双向绑定,帮我们以可预期的方式更新视图,极大提高我们的开发效率.
(3)跨平台:
虚拟 DOM 本质上是 JavaScript 对象,而 DOM 与平台强相关,相比之下虚拟 DOM 可以进行更方便地跨平台操作,例如服务器渲染、weex 开发等等。
22. 使用过 Vue SSR 吗?说说 SSR?
Vue.js 是构建客户端应用程序的框架。默认情况下,可以在浏览器中输出 Vue 组件,进行生成 DOM 和操作 DOM。然而,也可以将同一个组件渲染为服务端的 HTML 字符串,将它们直接发送到浏览器,最后将这些静态标记"激活"为客户端上完全可交互的应用程序。
即:SSR大致的意思就是: Vue在客户端将标签渲染成的整个 html 片段的工作在服务器端完成,服务端形成的html 片段直接返回给客户端这个过程就叫做服务端渲染。
服务端渲染 SSR 的优缺点如下:
(1)服务端渲染的优点:
(1) 更好的 SEO:
因为 SPA 页面的内容是通过 Ajax 获取,而搜索引擎爬取工具并不会等待 Ajax 异步完成后再抓取页面内容,所以在 SPA 中是抓取不到页面通过 Ajax 获取到的内容;而 SSR 是直接由服务端返回已经渲染好的页面(数据已经包含在页面中),所以搜索引擎爬取工具可以抓取渲染好的页面;
(2) 更快的内容到达时间(首屏加载更快),性能更高:
SPA 会等待所有 Vue 编译后的 js 文件都下载完成后,才开始进行页面的渲染,文件下载等需要一定的时间等,所以首屏渲染需要一定的时间;SSR 直接由服务端渲染好页面直接返回显示,无需等待下载 js 文件及再去渲染等,所以 SSR 有更快的内容到达时间;
(2) 服务端渲染的缺点:
(1)更多的开发条件限制 :
例如服务端渲染只支持 beforCreate 和 created 两个钩子函数,这会导致一些外部扩展库需要特殊处理,才能在服务端渲染应用程序中运行;并且与可以部署在任何静态文件服务器上的完全静态单页面应用程序 SPA 不同,服务端渲染应用程序,需要处于 Node.js server 运行环境;
(2)更多的服务器负载 :
在 Node.js 中渲染完整的应用程序,显然会比仅仅提供静态文件的 server 更加大量占用CPU 资源 (CPU-intensive - CPU 密集),因此如果你预料在高流量环境 ( high traffic ) 下使用,请准备相应的服务器负载,并明智地采用缓存策略。
23. Vue-router 路由模式有几种?是干什么的?
Vue-router 有 3 种路由模式:hash、history、 abstract.
(1) hash: 使用 URL hash 值来作路由。支持所有浏览器,包括不支持 HTML5 History Api 的浏览器;
(2) abstract : 支持所有 JavaScript 运行环境,如 Node.js 服务器端。如果发现没有浏览器的 API,路由会自动强制进入这个模式.
(3) history : 依赖 HTML5 History API 和服务器配置。具体可以查看 HTML5 History 模式.
Vue-router 是 官方提供的用来实现SPA的vue插件;
相关API说明
1.VueRouter(): 用于创建路由器的构建函数
new VueRouter({
// 多个配置项
})
2.路由配置
routes: [
{ // 一般路由
path: ‘/about’,
component: About
},
{ // 自动跳转路由
path: ‘/’,
redirect: ‘/about’
}
]
24. 你对Vue 的 SPA 单页面的理解,它的优缺点分别是什么?
(1)SPA 仅在 Web 页面初始化时加载相应的 HTML、JavaScript 和 CSS。
(2)一旦页面加载完成,SPA 不会因为用户的操作而进行页面的重新加载或跳转;
(3)取而代之的是利用路由机制实现 HTML 内容的变换,UI 与用户的交互,避免页面的重新加载。
优点:
(1)前后端职责分离,架构清晰,前端进行交互逻辑,后端负责数据处理;
(2)基于上面一点,SPA 相对于服务器压力小;
(3)用户体验好、快,内容的改变不需要重新加载整个页面,避免了不必要的跳转和重复渲染.
缺点:
(1) SEO 难度较大:
由于所有的内容都在一个页面中动态替换显示,所以在 SEO 上其有着天然的弱势。
(2)前进后退路由管理:
由于单页应用在一个页面中显示所有的内容,所以不能使用浏览器的前进后退功能,所有的页面切换需要自己建立堆栈管理;
(3)初次加载耗时多:
为实现单页 Web 应用功能及显示效果,需要在加载页面的时候将 JavaScript、CSS 统一加载,部分页面按需加载;
25. 谈谈你对 keep-alive 的了解?
keep-alive 是 Vue 内置的一个组件,可以使被包含的组件保留状态,避免重新渲染 ,其有以下特性:
(1) 一般结合路由和动态组件一起使用,用于缓存组件;
(2)提供 include 和 exclude 属性,两者都支持字符串或正则表达式;
include 表示只有名称匹配的组件会被缓存, exclude 表示任何名称匹配的组件都不会被缓存;
其中 exclude 的优先级比 include 高
(3)对应两个钩子函数 activated 和 deactivated ,当组件被激活时,触发钩子函数 activated,当组件被移除时,触发钩子函数 deactivated。
26.你怎么理解Vue的单项数据流?-
注:
所有的 prop 都使得其父子 prop 之间形成了一个单向下行绑定:
父级 prop 的更新会向下流动到子组件中,但是反过来则不行。
这样会防止从子组件意外改变父级组件的状态,从而导致你的应用的数据流向难以理解。
额外的,每次父级组件发生更新时,子组件中所有的 prop 都将会刷新为最新的值。
这意味着你不应该在一个子组件内部改变 prop。
如果你这样做了,Vue 会在浏览器的控制台中发出警告。
子组件想修改时,只能通过 $emit 派发一个自定义事件,父组件接收到后,由父组件修改。
Vue自定义事件, (只能是子组件向父组件通信,类似于 function props )
问题是: 不适合隔层组件和兄弟间组件
按键修饰符:
enter
esc
up(↑)
down(↓)
left(←)
right(→)
//例如:
@keyup.enter=" " //(enter键被按下触发)
事件修饰符:
修饰符号
v-model.number // 转换为数字
v-model.lazy //延迟更新
//事件修饰符:
stop //阻止事件冒泡
once //只执行第一次
prevent //阻止默认事件 @click.once.stop= " ";
一般情况下, 一个组件多次使用才可能用 slot插槽技术. 插槽通过标签, 可以通信标签体.
给子组件对象绑定监听: 用 @xxxxx指令, $on方法,
在子组件用 $emit()方法
绑定事件监听(需要指定事件名和回调函数 )和分发(触发)事件 (需要指定事件名和数据) , 事件名要和与他匹配的监听回调函数一致, 数据就会自动传给回调函数.
必须是同一个函数,


UI 组件库使用:
element-ui : 基于vue的UI组件库(PC端) , 饿了么团队
mint-ui: 基于vue的UI组件库(移动端), 饿了么团队
常用的生命周期方法
1) created()/mounted(): 发送ajax请求, 启动定时器等异步任务
2) beforeDestory(): 做收尾工作, 如: 清除定时器
Vue组件化编码
创建Vue项目的步骤:( 使用vue-cli (脚手架)搭建基本环境;)
npm install -g @vue/cli
vue create vue-demo
npm install -g @vue/cli-init
vue init webpack vue-demo
cd vue_demo
npm install
npm run dev
访问: http://localhost:8080/
组件之间的通信方式:
(1) props
(2) Vue的自定义事件 ==> 事件总线
(3) 消息订阅与发布(如: pubsub库) / 事件总线
(4) slot插槽
(5) Vuex
注:
Vue的自定义事件 ==> 事件总线
通过v-on绑定触发事件; (只能在父组件中接收)this.$emit(eventName, data)1)
此方式只用于子组件向父组件发送消息(数据), 隔代组件或兄弟组件间通信此种方式不合适
消息订阅与发布(pubsub-js库)
订阅消息
PubSub.subscribe(‘msg’, function(msg, data){}) (subscribe 订阅,签署,认购等)
发布消息
PubSub.publish(‘msg’, data) (publish 发布,出刊等)
注意:
优点: 此方式可实现任意关系组件间通信(数据)
slot插槽 此方式用于父组件向子组件传递-----标签数据
Vue项目中常用的2个ajax库:
(1)vue-resource Vue插件, 非官方库, vue1.x使用广泛
(2)axios 通用的ajax请求库, 官方推荐, vue2.x使用广泛
Vue 3.0 知识点总结
- 数据双向绑定,Vue3之前通过get和set完成,而Vue3后通过proxy来完成。
- Vue中有一个虚拟dom,其实虚拟dom就是一个内部的json字符串。
vm最终修改的都是data中的数据 , 但是呢 单选框的value值 需要你去告诉他 , 其他的都默认都有
收集表单数据:
若是:<input type=“text”/,则v-model收集的是value值,用户输入的就是value值了若是:,则v-model收集的是value值,且要给标签配置value值若是:
1.没有配置input的value属性,那么收集的的就是checked(勾选or未勾选,是布尔值2.配置input的value属性:
(1).v-model的初始值是非数组,那么收集的的就是checked(勾选or未勾选,是布尔值)(2).v-model的初始值是数组,那么收集的的就是value组成的数组
四.Node篇
1.Node是什么? -----Node.js是一个基于 Chrome V8 引擎的JS运行环境
2.Node能做什么?
查看自己node的版本命令:node -v, 查看自己npm的版本命令:npm -v
3.Node版本的要求:
(1) node版本:最低是10
(2) npm版本:最低是6
(3) 为了让你的npm下载东西更迅速,请务必执行以下命令!!!
npm config set registry http://registry.npm.taobao.org/
3.1 包名的要求:
使用命令:npm init把一个普通的文件夹变成一个包,即自动生成package.json
不能有中文
不能有大写字母
不能与npm上已经存在的包重名,例如:(axios、jquery、less等)
3.2 安装一个包的命令
npm install xxxx
4.NodeJS的特点和不足之处.


5.CPU密集型: -------- 客人点餐墨迹属于CPU密集型 (在java服务器中);
I/O密集型: ---------- 客人不断的点餐属于I/O密集型 (在Node服务器中)
6.在Node端和浏览器 JS的组成部分?

7.Node中的全局函数

8.Node的事件循环机制

9.npm5 的 命令 很烂 ,后来 npm6 的命令行 模仿的yarn
yarn 的配置和使用:
10.Node中buffer缓冲器的使用


CPU: cpu 的70%的时间都是在进行 0和1 的操作
11.Node中的文件系统

数据库大体就分为两类: 关系型数据库(RDBS) 和 非关系型数据库(NoSQL)


先学的关系型数据库:mySQL , 再学的非关系型的 mongDB
MongoDB数据库:


为什么使用mongoose? 主要是在node平台下,更稳定的,高效,简单,安全的操作mongDB.


EXPRESS框架/模块



12.Webpack构建工具
12.1什么是webpack?
*Webpack是一个模块打包器(bundler),是前端项目的项目构建 工具 ,构建就是把将程序员写的源代码,经过编译,压缩,语法检查.兼容性处理等.
三大类工具: Grunt, gulp.js , ( 现在主流的)webpack构建工具
在Webpack看来, 前端的所有资源文件(js/json/css/img/less/…)都会作为模块处理
它将根据模块的依赖关系进行静态分析,生成对应的静态资源
**如何实现webpack的按需加载? **
在webpack中主要提供两种方法:import函数 和 require.ensure;
与正常ES6中的import语法不同,通过import函数加载的模块及其依赖会被异步地进行加载,并返回一个Promise对象。
webpack中的require.ensure()可以实现按需加载资源包括js,css等,它会给里面require的文件单独打包,不和主文件打包在一起,webpack会自动配置名字,
也可以有效地缩小资源体积,同时更好地利用缓存,给用户更友好的体验;
12.2 webpack的核心概念


12.3 webpack模块化打包的基本流程

12.4 webpack中的loader和插件


12.5 webpack常用loader与plugin汇总

12.6 插件




12.7 git的6个基本操作
git init
git add xxx
git remote
git commit xxx origin
git push

12.8-----git的使用
Git的起源是 “自由主义教皇”—林纳斯·托瓦兹

Git是目前世界上最先进的分布式版本控制 (没有之一)。说到分布式,与之相对应的是集中式




12.9 GitHub是一个Git项目托管网站。
GitHub能做什么?
(1) 能够分享你的代码或者其他开发人员配合一起开发。
(2)GitHub是一个基于Git的代码托管平台,Git并不像SVN那样有一个中心服务器。目前我们使用到的 Git命令都是在本地执行,你就需要将数据放到一台其他开发人员能够连接的服务器上。
GitHub远程仓库的使用



13.浏览器功能与组件
13.1浏览器的内核(渲染引擎)
在浏览器中有一个最重要的模块,它主要的作用把一切请求回来的资源变为可视化的图像。
这个模块就是浏览器内核,通常它也被称为渲染引擎。
渲染引擎主要包括:HTML解析器,CSS解析器,javascript引擎,布局layout模块,绘图模块.


注: 以上这些模块依赖很多其他的基础模块,包括要使用到网络 存储 2D/3D图像/音频视频解码器 和 图片解码器。 所以渲染引擎中还会包括如何使用这些依赖模块的部分。
CSS阻塞:

JS阻塞:




浏览器的主要功能总结起来就是一句话:将用户输入的url转变成可视化的图像。
前端性能优化 : 百度做得很好,爬虫优化,算法优化,阿里也有.
13.2----进程与线程
(1)进程:
程序的一次执行, 它占有一片独有的内存空间.是操作系统执行的基本单元。
一个进程中至少有一个运行的线程: 主线程, 进程启动后自动创建;
一个进程中也可以同时运行多个线程, 我们会说程序是多线程运行;
一个进程内的数据可以供其中的多个线程直接共享,多个进程之间的数据是不能直接共享的.
(2)线程:
是进程内的一个独立执行单元,是CPU调度的最小单元,程序运行的基本单元.
线程池(thread pool): 保存多个线程对象的容器, 实现线程对象的反复利用.
13.3—现代浏览器:基本都是多进程、多线程模型



13.4 内存溢出和泄露
Node.js 内存溢出时如何处理?
为什么会溢出???
主要原因是 进行 I/O密集型运算,操作的数据量较大(对象需要频繁的创建/销毁,或操作对象本身较大).
(1)V8内存分配机制 (2)JavaScript语言本身限制 (3)程序员使用不当。
如何解决内存溢出问题?
(1)使用 async/await防止事件堆积,变为同步操作.
(每次循环V8都会回收内存一次,因此内存不会再溢出。但这样做必然会造成运行效率的降低,而应该在速度在安全之间平衡,控制好循环的安全次数。)
(2)增加js引擎V8的内存空间
(3)使用非V8内存,比如
注:
Node.js程序所使用的内存分为两类:
V8内存:数组、字符串等JavaScript内置对象,运行时使用“V8内存”.
系统内存:Buffer 是 Node.js 的一个扩展对象,使用底层的系统内存,不占用V8内存空间 与 buffer 相关的文件系统 fs 和stream 流操作,都不会占用 V8 内存。

静态资源拷贝


五.Web网络篇
1. http协议是什么?
协议: 是指计算机通信网络中两台计算机之间进行通信所必须共同遵守的规定或规则。
HTTP(hypertext transport protocol)协议也叫超文本传输协议,是一种基于TCP/IP的应用层通信协议,这个协议详细规定了浏览器和万维网服务器之间互相通信的规则。
***注: 客户端与服务端通信时传输的内容我们称之为报文。
HTTP就是一个通信规则,这个规则规定了客户端发送给服务器的报文格式,也规定了服务器发送给客户端的报文格式。
客户端发送给服务器的称为“请求报文”,服务器发送给客户端的称为“响应报文”。

2.HTTP1.0和HTTP1.1的一些区别?
> HTTPS协议需要到CA申请证书,一般免费证书很少,需要交费。
> HTTP协议运行在TCP之上,所有传输的内容都是明文,HTTPS运行在SSL/TLS之上,SSL/TLS运行在TCP之上,所有传输的内容都经过加密的。
> HTTP和HTTPS使用的是完全不同的连接方式,用的端口也不一样,前者是80,后者是443。
> HTTPS可以有效的防止运营商劫持,解决了防劫持的一个大问题
HTTP的基本优化
2.1: 影响一个 HTTP 网络请求的因素主要有两个:带宽和延迟。
带宽:如果说我们还停留在拨号上网的阶段,带宽可能会成为一个比较严重影响请求的问题,但是现在网络基础建设已经使得带宽得到极大的提升,我们不再会担心由带宽而影响网速,那么就只剩下延迟了。
延迟:
(1)浏览器阻塞(HOL blocking):浏览器会因为一些原因阻塞请求。浏览器对于同一个域名,同时只能有 4 个连接(这个根据浏览器内核不同可能会有所差异),超过浏览器最大连接数限制,后续请求就会被阻塞。
(2)DNS 查询(DNS Lookup):浏览器需要知道目标服务器的 IP 才能建立连接。将域名解析为 IP 的这个系统就是 DNS。这个通常可以利用DNS缓存结果来达到减少这个时间的目的。
(3)建立连接(Initial connection):HTTP 是基于 TCP 协议的,浏览器最快也要在第三次握手时才能捎带 HTTP 请求报文,达到真正的建立连接,但是这些连接无法复用会导致每次请求都经历三次握手和慢启动。三次握手在高延迟的场景下影响较明显,慢启动则对文件类大请求影响较大。
2.2--------------------------------------------------------------------------------------------
2012年google如一声惊雷提出了SPDY的方案,优化了HTTP1.X的请求延迟,解决了HTTP1.X的安全性,具体如下:
降低延迟: 针对HTTP高延迟的问题,SPDY优雅的采取了多路复用(multiplexing)。多路复用通过多个请求stream共享一个tcp连接的方式,解决了HOL blocking的问题,降低了延迟同时提高了带宽的利用率。
请求优先级(request prioritization): 多路复用带来一个新的问题是,在连接共享的基础之上有可能会导致关键请求被阻塞。SPDY允许给每个request设置优先级,这样重要的请求就会优先得到响应。比如浏览器加载首页,首页的html内容应该优先展示,之后才是各种静态资源文件,脚本文件等加载,这样可以保证用户能第一时间看到网页内容。
header压缩: 前面提到HTTP1.x的header很多时候都是重复多余的。选择合适的压缩算法可以减小包的大小和数量。基于HTTPS的加密协议传输,大大提高了传输数据的可靠性。
服务端推送(server push):采用了SPDY的网页,例如我的网页有一个sytle.css的请求,在客户端收到sytle.css数据的同时,服务端会将sytle.js的文件推送给客户端,当客户端再次尝试获取sytle.js时就可以直接从缓存中获取到,不用再发请求了。SPDY构成图:

2.3 DNS: 经典面试题
**问题:从用户输入URl按下回车,一直到用户能看到界面,期间经历了什么?**

几次挥手??? 详细解释一下?
3.http状态码:
200:就是最理想的状态了,请求成功了!
301:重定向,请求的旧资源永久移除了,(不能访问了)会跳转到一个新的资源上,搜索引擎在抓取新内容的同时也将旧的网址替换为重定向之后的网址;
302: 重定向,被请求的旧资源还在(仍然可以访问),但会临时跳转到一个新资源,搜索引擎会抓取新的内容而保存旧的网址;
304:请求资源未被修改,浏览器将会读取缓存;(命中了协商缓存)
404:请求的资源没有找到,说明客户端错误的请求了不存在的资源;(4xx一般都是前端的锅)
500:请求资源找到了,但服务器内部出现了错误;(一般都是后端的锅)
502: 连接服务器失败
**4. 端口号 **:1–65535,不建议使用1–199的端口号,这些是预留给系统的,一般使用4位的,4位的也不要用1开头的。
常见端口号:
21端口:FTP 文件传输服务
22端口:SSH 端口
23端口:TELNET 终端仿真服务
25端口:SMTP 简单邮件传输服务
53端口:DNS 域名解析服务
80端口:HTTP 超文本传输服务
110端口:POP3 “邮局协议版本3”使用的端口
443端口:HTTPS 加密的超文本传输服务
1433端口:MS SQL*SERVER数据库 默认端口号
1521端口:Oracle数据库服务
1863端口:MSN Messenger的文件传输功能所使用的端口
3306端口:MYSQL 默认端口号
3389端口:Microsoft RDP 微软远程桌面使用的端口
5631端口:Symantec pcAnywhere 远程控制数据传输时使用的端口
5632端口:Symantec pcAnywhere 主控端扫描被控端时使用的端口
5000端口:MS SQL Server使用的端口
27017端口:MongoDB实例默认端口
6.中间件
概念:本质上就是一个函数,包含三个参数:request(请求)、response (响应)、next(放行)
作用:
1) 执行任何代码。
2) 修改请求对象、响应对象。
3) 终结请求-响应循环。(让一次请求得到响应)
4) 调用堆栈中的下一个中间件或路由
六.综合部分
开发日志:















 486
486











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









