







贴吧评论敏感词识别及情感分析初级实现之情感分析
分三个模块实现贴吧评论敏感词识别及情感分析研究:“评论爬虫抓取”、“评论敏感词识别”、“评论情感分析(积极或消极)”。数据存储于MongoDB中,现设数据库“spiders”,数据集合users。其余两个模块见本人博文。
在贴吧评论敏感词识别及情感分析初级实现里,只涉及最基础的知识,未进行代码的升级以及相应模块的技术完善。
评论情感分析
现有两种对于短文本情感倾向研究的方法,一种是基于词典匹配,另一种是基于机器学习。
词典匹配法,即直接将待测文本分句,找到其中的情感词、程度词、否定词等,计算出每句情感倾向分值。词典匹配情感分析语料适用范围更广,但受限于语义表达的丰富性。
Python+机器学习情感分析,即选出一部分积极情感的文本与消极情感的文本,之后用机器学习方法进行训练,得出情感分类器,再通过这个情感分类器对所有文本进行积极与消极的二分分类。
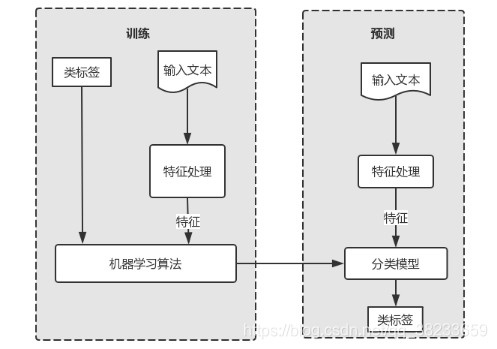
该模块旨在对全部的网民言论进行情感分析,判定是积极言论还是消极言论。利用机器学习判断待测文本的情感倾向,即积极或消极。因为需要根据给定的输入预测某个结果,并且应该有输入/输出对的示例,所以属于有监督的二分类机器学习,类标签即为neg(消极)与pos(积极)。已知有监督机器学习的流程,如图所示。
模块实现
(1)处理语料库
语料库中有10000条购酒体验评论,现将所有评论分别归属于“good.txt”与“bad.txt”,即人为的为文本赋予类标签。
(2)特征提取
四种特征提取方式:
- 单字作为特征
- 双字(词语)作为特征
- 单字加双字作为特征
- 结巴分词形成的词语作为特征
(3)特征降维
- 所有字作为特征
- 双词作为特征,并利用卡方统计选取信息量排名前n的双字
- 单字和双字共同作为特征,并利用卡方统计选取信息量排名前n的
单字和双字; - 结巴分词外加卡方统计选取信息量排名前n的词汇作为特征
(4)特征表示
def text():
f1=open('good.txt','r',encoding='utf-8')
f2=open('bad.txt','r',encoding='utf-8')
line1=f1.readline()
line2=f2.readline()
str=''
while line1:
str+=line1
line1=f1.readline()
while line2:
str+=line2
line2=f2.readline()
f1.close()
f2.close()
return str
#单个字作为特征
def bag_of_words(words):
return dict([(word,True) for word in words])
#print(bag_of_words(text())
#把词语(双字)作为搭配,并通过卡方统计,选取排名前1000的词语
from nltk.collocations import BigramCollocationFinder
from nltk.metrics import BigramAssocMeasures
def bigram(words, score_fn=BigramAssocMeasures.chi_sq, n=1000):
bigram_finder = BigramCollocationFinder.from_words(words)
bigrams = bigram_finder.nbest(score_fn, n) # 使用卡方统计的方法,选择排名前1000的词语
newBigrams = [u + v for (u, v) in bigrams]
#return bag_of_words(newBigrams)
#print(bigram(text(),score_fn=BigramAssocMeasures.chi_sq,n=1000))
# 把单个字和词语一起作为特征
def bigram_words(words, score_fn=BigramAssocMeasures.chi_sq, n=1000):
bigram_finder = BigramCollocationFinder.from_words(words)
bigrams = bigram_finder.nbest(score_fn, n)
newBigrams = [u + v for (u, v) in 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









