







简单说说mysql的索引
1.什么叫索引?
索引在MYSQL中也叫“键”,是存储引擎用于快速找到记录的一种数据结构。索引对于良好的性能非常关键,当数据量越来越大时,索引对于性能的影响愈发重要,索引优化查询性能,能够轻易将性能提高好几个数量级。
2.出现的原因
索引的目的在于提高查询效率,和查阅图书用的目录一样,先定位到章,节,页数。
本质都是:通过不断缩小数据的范围来筛选出所需要的结果,将随机事件变成顺序事件,使我们能够用同一种查找方式来锁定数据。
数据库也是一样,但显然要复杂的多,因为不仅面临着等值查询,还有范围查询(>、<、between、in)、模糊查询(like)、并集查询(or)等等。数据库应该选择怎么样的方式来应对所有的问题呢?我们回想字典的例子,能不能把数据分成段,然后分段查询呢?最简单的如果1000条数据,1到100分成第一段,101到200分成第二段,201到300分成第三段…这样查第250条数据,只要找第三段就可以了,一下子去除了90%的无效数据。但如果是1千万的记录呢,分成几段比较好?稍有算法基础的同学会想到搜索树,其平均复杂度是lgN,具有不错的查询性能。但这里我们忽略了一个关键的问题,复杂度模型是基于每次相同的操作成本来考虑的。而数据库实现比较复杂,一方面数据是保存在磁盘上的,另外一方面为了提高性能,每次又可以把部分数据读入内存来计算,因为我们知道访问磁盘的成本大概是访问内存的十万倍左右,所以简单的搜索树难以满足复杂的应用场景。
3.磁盘的IO与预读
考虑到磁盘IO是非常高昂的操作,计算机操作系统做了一些优化,当一次IO时,不光把当前磁盘地址的数据,而是把相邻的数据也都读取到内存缓冲区内,因为局部预读性原理告诉我们,当计算机访问一个地址的数据的时候,与其相邻的数据也会很快被访问到。每一次IO读取的数据我们称之为一页(page)。具体一页有多大数据跟操作系统有关,一般为4k或8k,也就是我们读取一页内的数据时候,实际上才发生了一次IO,这个理论对于索引的数据结构设计非常有帮助。
4.索引的数据结构
MYSQL索引实现是在存储引擎端(引擎是基于表的,不同表可以有不同的引擎),不同的引擎支持不同的索引类型,myiam和innodb默认btree索引数据结构,memory默认hash。
这里详细的说明了mysql索引的数据结构:https://blog.csdn.net/qq_38238296/article/details/88362635
InnoDB 支持事务,支持行级别锁定,支持 B-tree、Full-text 等索引,不支持 Hash 索引;
MyISAM 不支持事务,支持表级别锁定,支持 B-tree、Full-text 等索引,不支持 Hash 索引;
Memory 不支持事务,支持表级别锁定,支持 B-tree、Hash 等索引,不支持 Full-text 索引;
这里了解一下MyISAM和InnoDB的物理存储结构:
MyISAM:由3个文件组成。
- MYI:存储索引
- MYD:存储数据
- FRM:表结构定义等
InnoDB:只有一个文件组成,IDB:即存索引又存数据。
我们一般使用的引擎就是myisam和innodb,所以索引一般使用b-tree的数据结构,这里的b-tree通常指的是b+tree。
5.mysql索引操作
5.1.索引的分类
1.普通索引index :加速查找
2.唯一索引
主键索引:primary key :加速查找+约束(不为空且唯一)
唯一索引:unique:加速查找+约束 (唯一)
3.联合索引
-primary key(id,name):联合主键索引
-unique(id,name):联合唯一索引
-index(id,name):联合普通索引
4.全文索引fulltext :用于搜索很长一篇文章的时候,效果最好。
5.2.创建/删除索引的语法
方法一:创建表时
CREATE TABLE 表名 (
字段名1 数据类型 [完整性约束条件…],
字段名2 数据类型 [完整性约束条件…],
[UNIQUE | FULLTEXT | SPATIAL ] INDEX | KEY
[索引名] (字段名[(长度)] [ASC |DESC])
);
方法二:CREATE在已存在的表上创建索引
CREATE [UNIQUE | FULLTEXT | SPATIAL ] INDEX 索引名
ON 表名 (字段名[(长度)] [ASC |DESC]) ;
方法三:ALTER TABLE在已存在的表上创建索引
ALTER TABLE 表名 ADD [UNIQUE | FULLTEXT | SPATIAL ] INDEX 索引名 (字段名[(长度)] [ASC |DESC]) ;
删除索引:DROP INDEX 索引名 ON 表名字;
实例:
1.在创建表的时候添加索引:
mysql> create table test(
-> id int auto_increment primary key,
-> name varchar(4),
-> num char(20),
-> unique(num),
-> index(name));
Query OK, 0 rows affected
2.在创建表之后
mysql> create table test(
-> id int auto_increment primary key,
-> name varchar(4),
-> num char(20));
Query OK, 0 rows affected
mysql> create index iname on test(name);
mysql> create unique index inum on test(num);
mysql> create index name on test(id,name);
Query OK, 0 rows affected ——创建普通联合索引
3.删除索引
mysql> drop index name on test;
mysql> drop index inum on test; 唯一索引的删除和普通的一样不需要加unique
mysql> drop index iname on test;
5.3.测试索引
1.准备
1.表
create table s1(
id int,
name varchar(20),
gender char(6),
email varchar(50)
);
2.创建存储过程,批量插入记录
delimiter $$ #声明存储过程的结束符号为$$
create procedure auto_insert1()
BEGIN
declare i int default 1;
while(i<1000)do
insert into s1 values(i,concat('egon',i),'male',concat('egon',i,'@oldboy'));
set i=i+1;
end while;
END$$ #$$结束
delimiter ; #重新声明分号为结束符号
call auto_insert1(); #调用存储过程
2.测试索引的速度
mysql> select * from s1 where id =555;
+------+---------+--------+----------------+
| id | name | gender | email |
+------+---------+--------+----------------+
| 555 | egon555 | male | egon555@oldboy |
+------+---------+--------+----------------+
1 row in set (0.01 sec)
我们创建索引一定是为搜索条件的字段添加索引(很明显 = =)
mysql> create index idx on s1(id);
Query OK, 0 rows affected (0.15 sec)
Records: 0 Duplicates: 0 Warnings: 0
mysql> select * from s1 where id =555;
+------+---------+--------+----------------+
| id | name | gender | email |
+------+---------+--------+----------------+
| 555 | egon555 | male | egon555@oldboy |
+------+---------+--------+----------------+
1 row in set (0.00 sec)
由于我的数据太少了才1000条,速度差别不明显。
6.索引的工作原理
这里我说的是InnoDB引擎中的B+树索引。
从上面的例子语句中分析:
select * from s1 where id =555;
在使用这条语句的时候,我只创建了id值得索引,但是我select的并不只有id值,而是所有值。那么他是如何检索出来的?
过程:select * from s1 where id =3 id为主键索引,检索时会遍历B+树,不管有没有匹配到,都要遍历到叶子节点(叶子节点保存数据记录(类似指针指向数据库中的数据)),最后将结果显示出来。
InnoDb索引的实现方式:
前面说到InnoDB的物理存储是由一个文件idb组成的对于InnoDB表,数据文件ibd本身就是按B+Tree组织的一个索引结构,这棵树的叶节点data域保存了完整的数据记录。
下面的test表id是主键索引(聚集索引),name是辅助索引(非聚集索引)
mysql> select * from test;
+----+--------+-----+
| id | name | num |
+----+--------+-----+
| 1 | Jack | 1 |
| 2 | Alice | 0 |
| 3 | Darren | 1 |
| 4 | Bob | 1 |
| 5 | Tom | 1 |
| 6 | Helen | 0 |
+----+--------+-----+
假如在一棵5阶B+tree树(关键字范围[2,4]),它的主键索引组织结构如下:
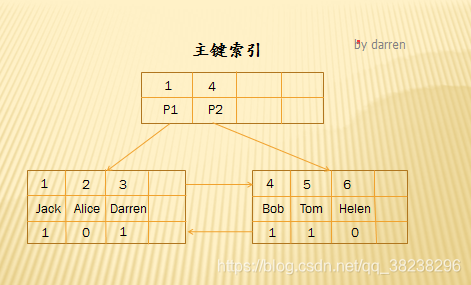
上图是InnoDB主键索引的B+tree,叶子节点包含了完整的数据记录,像这种索引叫做聚集索引。在InnoDB中只有一个聚集索引,通常是指定主键。p1和p2是指针指向孩子节点,叶子结点也通过指针形成一个有序的链表。
因为InnoDB的数据文件本身要按主键聚集,所以InnoDB要求表必须有主键(MyISAM可以没有),如果没有显示指定,那么myslq会优先选择一个可以唯一标识的数据列作为主键,如果没有唯一列,则Mysql会自动为InnoDB表生成一个隐含字段作为主键,长度为6个字节,类型为longint。
辅助索引结构(非聚集索引):
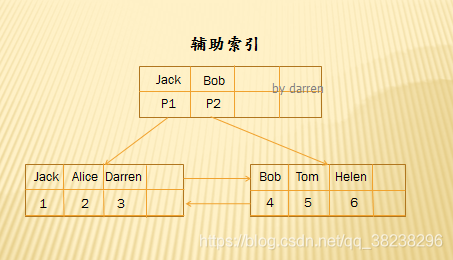
对于非聚集索引,非叶子节点保存的是索引值,比如图中最上层的节点;叶子节点保存的不再是数据记录了,而是主键值,如上如下面保存的是主键值。
总结:
MySQL聚集索引使得按主键的搜索非常高效的。
辅助索引需要搜索两遍索引:
第一:检索辅助索引获得主键值
第二:用主键值到主键索引中检索获得记录
问题1、为什么Innodb表需要主键?
1)innodb表数据文件都是基于主键索引组织的,没有主键,mysql会想办法给我搞定,所以主键必须要有;
2)基于主键查询效率高;
3)其他类型索引都要引用主键索引;
问题2、为什么不建议Innodb表主键设置过长?
因为辅助索引都保存引用主键索引,过长的主键索引使辅助索引变得过大;















 104
104











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









