






一、底层原理
- sql慢是因为没有走索引,因此需要添加索引然它走索引
- 联合索引需要匹配最左匹配原则
- (索引回表)如果查询列超出索引的key, 会导致回表,回表数量多,则会走全表扫描
索引是分聚集索引、非聚集索引的,因此如果select * from id = 1,这个是直接走聚集索引也就是主键索引,叶子节点存储的是全部列的数据,这样就不需要回表,但是如果是select * from name = ‘xx’ ,name列创建的索引是非聚集索引,叶子节点是存储的是(id,name),这样会通过ID去聚集索引再去找。
- 索引分为聚集索引和非聚集索引
- 一次sql查询,只会查询一次索引
- inner join \ left join \right join 需要区分驱动表和被驱动表,驱动表应该为小表,被驱动表为大表, 需要在被驱动表添加索引
inner join 有优化,left join ,左边的表则为驱动表,右边的表为被驱动表。right join 右边为驱动表,左表为被驱动表。
- group by 应该先过滤再group by
-
,<,in,between等等,都是可以使用索引的
二、sql优化
- 查询SQL尽量不要使用select *,而是具体字段
- 避免在where子句中使用 or 来连接条件
or 不走索引,可以使用union all或者union来连接不同条件的查询,虽然两者都不会走索引,但是or的话,可能会全表扫描+索引扫描+合并,如果它一开始就走全表扫描,直接一遍扫描就搞定;
- 尽量使用数值替代字符串类型
- 使用varchar代替char
- 避免在where子句中使用!=或<>操作符
- 避免在索引列上使用内置函数
- 优化like语句,尽量采用右模糊查询, 即like ‘…%’,是会使用索引的;
- 使用explain分析你SQL执行计划
1、type
system:表只有一行记录,这个是const的特例,一般不会出现,可以忽略
const:表示通过索引一次就找到了,const用于比较primary key或者unique索引。因为只匹配一行数据,所以很快。
eq_ref:唯一性索引扫描,表中只有一条记录与之匹配。一般是两表关联,关联条件中的字段是主键或唯一索引。select * from a,b where a.id = b.id
ref:非唯一行索引扫描,返回匹配某个单独值的所有行; select * from a where a.key = 1;
range:只检索给定范围的行,使用一个索引来选择行。当使用=、<>、>、>=、<、<=、IS NULL、<=>、BETWEEN或者IN操作符,用常量比较关键字列时,可以使用range;
index:遍历索引树。通常比ALL快,因为索引文件通常比数据文件小。all和index都是读全表,但index是从索引中检索的,而all是从硬盘中检索的。select id from b;
all:全表扫描;
性能排名:system > const > eq_ref > ref > range > index > all。
实际sql优化中,最后达到ref或range级别。
2、Extra常用关键字
Using filesort:使用外部的索引排序,而不是按照表内的索引顺序进行读取。(一般需要优化)
Using temporary:使用了临时表保存中间结果。常见于排序order by和分组查询group by(最好优化)
Using index:只从索引树中获取信息,而不需要回表查询;
Using where:WHERE子句用于限制哪一个行匹配下一个表或发送到客户。除非你专门从表中索取或检查所有行,如果Extra值不为Using where并且表联接类型为ALL或index,查询可能会有一些错误。需要回表查询。
- 数据库和表的字符集尽量统一使用UTF8
字符不一致也不会走索引
3. using filesort
Using filesort表示在索引之外,需要额外进行外部的排序动作。导致该问题的原因一般和order by有者直接关系,一般可以通过合适的索引来减少或者避免。
Using filesort 的含义很简单,就是使用了排序操作,和file没有任何关系,出现这个选项的常见情况就是 Where 条件和 order by 子句作用在了不同的列上。
- 当Where 条件和 order by 子句作用在不同的列上,建立联合索引可以避免Using filesort的产生
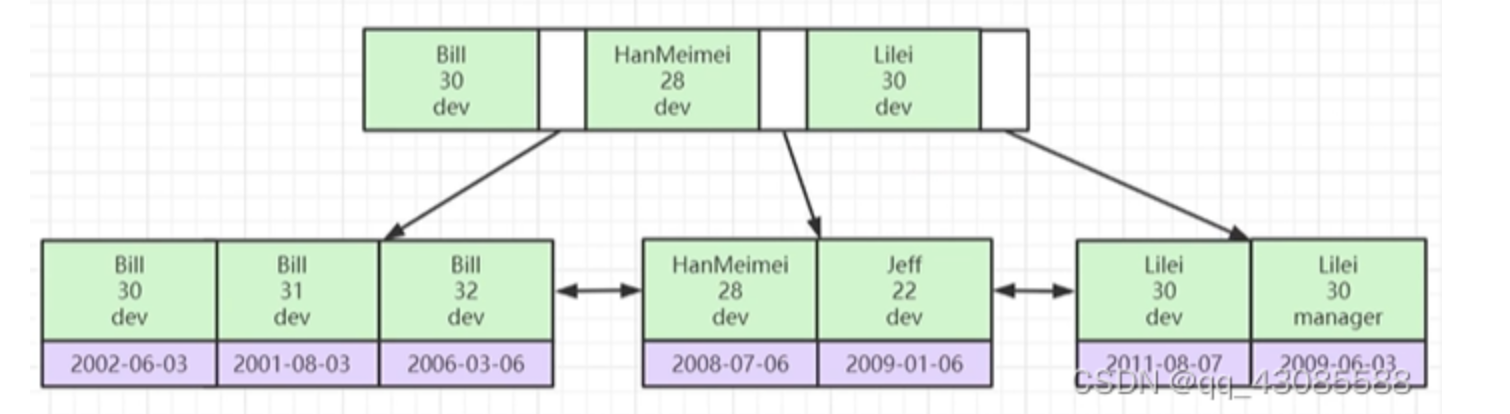
可以看到联合索引在b+树上会根据最左匹配原则,先将前面的排号序,相同前key的值会对第二个进行排序。
比如select name from a where a.type = 3 order by name desc;
那么这里会先走type的索引,找到type=3的值,会获得对应ID,然后去聚集索引再查询对应的内容,然后会根据内容的name进行排序,这样explain会出现using filesort。但是我们可以创建一个type name联合索引,这样查询到的type的id就是排好序的id了。
三、问题
- explain 中的index和ref有什么区别
在我们内置印象中,index才是使用到了索引,ref也是使用到了索引,那么index和ref有什么区别呢?
ref的时间效率高于index的
index是指:进行了全索引的扫描
ref是指的是:进行了索引的匹配
区别是一个是全索引扫描一个是索引查找,全索引扫描也就是会扫描全部的索引。
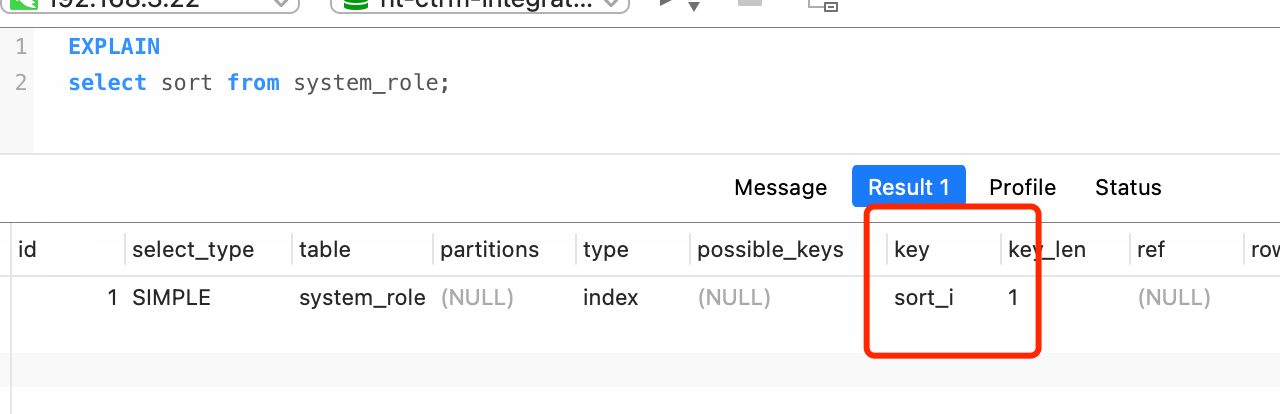
比如 select name from user; 如果name有索引,那么
这里type就是index
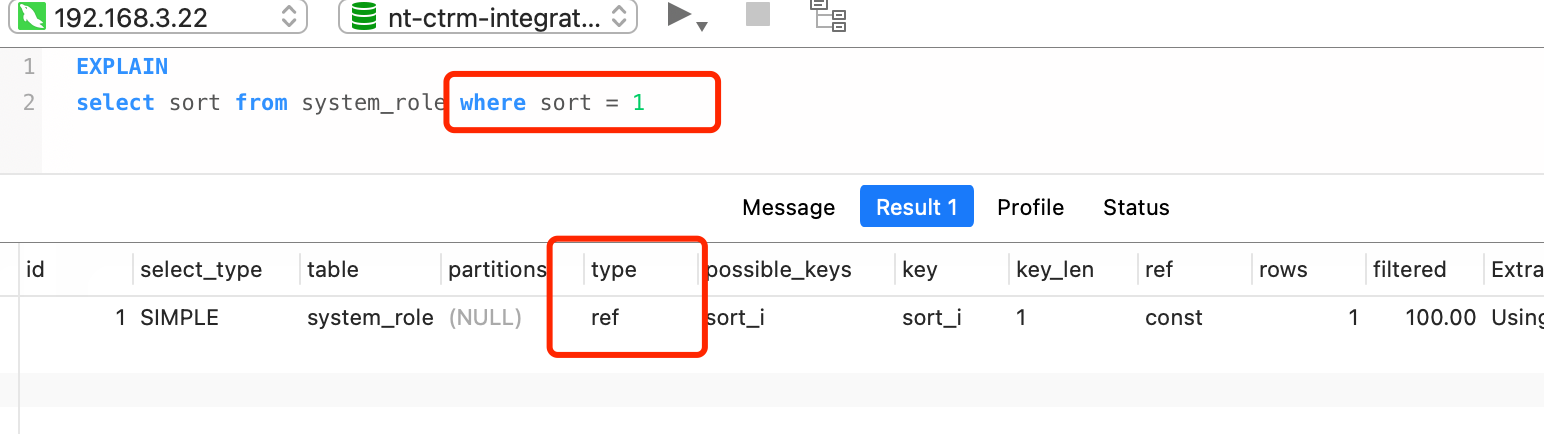
ru如果执行sort = 1d的的查询也就是意味不是全索引扫描,而是索引查询,因此如果type=ref效果最高好















 280
280











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









