







HBase简介
1. HBase
(一).什么是HBase
HBase技术来源于 Fay Chang 所撰写的Google论文“Bigtable:一个结构化数据的分布式存储系统”。
HBase是Apache的Hadoop项目的子项目。HBase不同于一般的关系数据库,它是一个适合于非结构化数据存储的数据库。另一个不同的是HBase基于列的而不是基于行的模式。
HBase – Hadoop Database,是一个高可靠性、高性能、面向列、可伸缩的分布式存储系统,利用HBase技术可在廉价PC Server上搭建起大规模结构化存储集群。
HBase实际上是一个Hadoop的数据库系统,它的主要作用和传统数据库系统一样存储数据和检索数据。不同的是,HBase可以存储海量数据及海量数据的检索。
(二).为什么使用hbase
传统的RDBMS关系型数据库(例如SQL)存储一定量数据时进行数据检索没有问题,可当数据量上升到非常巨大规模的数据(TB或PB)级别时,传统的RDBMS已无法支撑,这时候就需要一种新型的数据库系统更好更快的处理这些数据。数据量达到PB,EB,ZB级别的数据考虑使用HBase。
(二).HBase的地位
HBase占有举足轻重的作用,它居于HDFS之上,与MapReduce可以集成,与Hive也是集成的,HBase表中的数据与Hive表的数据可以关联,而后面的Spark也可以读HBase的数据。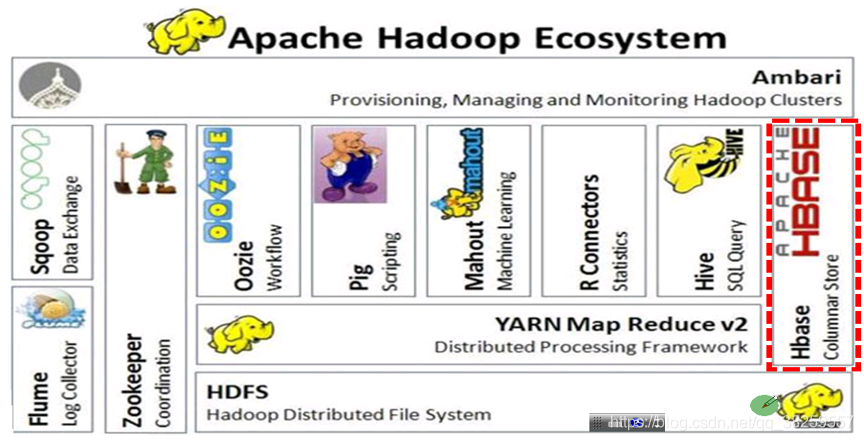
2.HBase架构设计及表的存储设计
1. HBase是水平扩展的、分布式的、开源有序映射数据库。
2. 它运行在Hadoop文件系统HDFS上。它不要求有预定义的模式,可以被看做弹性扩展的多维表格,通过动态添加列,在数据插入或查询之前修改列结构,以支持任意的数据结构。
3. HBase是一个建立在HDFS上的列存储数据库,具有至此线性扩展(横向扩展)、自动故障转移、自动分区及模式自由等特性。
(一)与hadoop的hdfs对比如下图
(二)与RDBMS对比如下图3.HBase数据存储模型
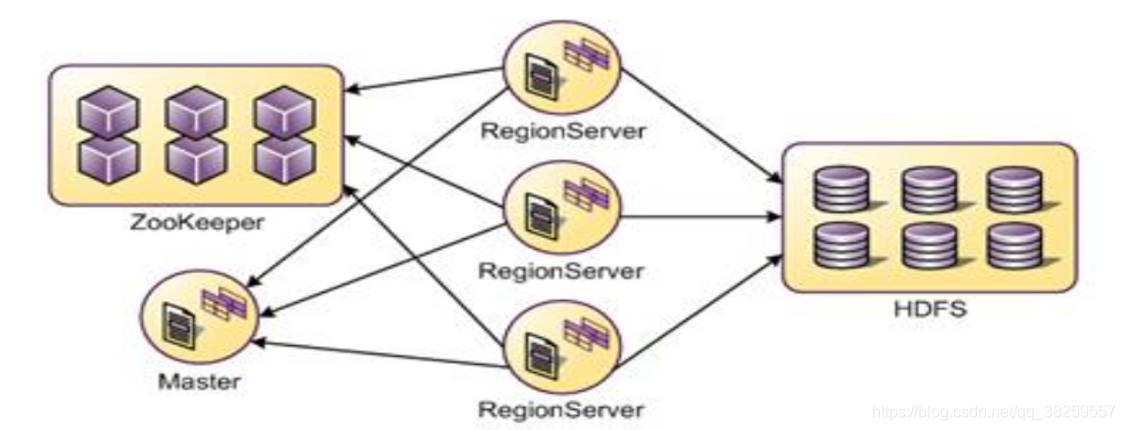
Master:
为HBase的主节点,用来协调客户端应用程序和RegionServer的关系,同时用来监控和记录元数据的变化和管理。
RegionServer:
是从节点,用region的形式处理实际的表。region是HBase表的基础单元组件,它存储了分布式表。所以HBase表和HBase集群利用Master和RegionServer来协同工作。
ZooKeeper:
是一个高性能、集中化、分布式应用程序协调服务,它为HBase提供了分布式同步和组服务。在HBase中,它用来选举集群主节点Master,以便跟踪可用的在线服务器,同时维护集群的元数据。一般安装多个,用于提供Master的高可用性。
3.HBase数据存储模型
1. Base不是以关系设计为中心,它是根据用户需求更灵活的开放设计。它提供了在行键上的单一索引,这在关系世界里称为主键。我们可以通过把行划分为列族和列来避免大的读取和写入操作,并且这种方式支持水平切分和垂直切分。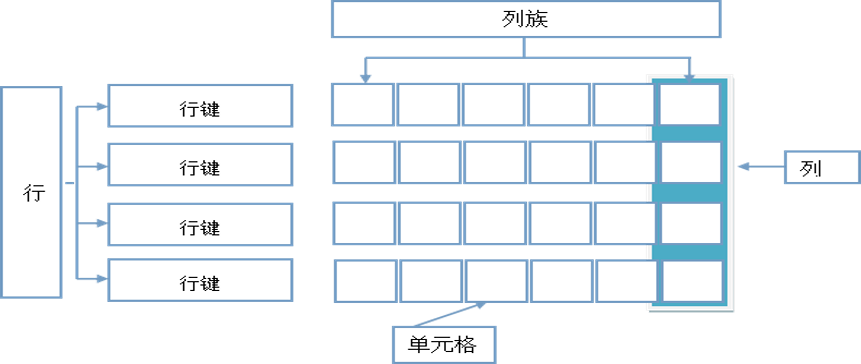
2. HBase中没有花哨的数据类型,它所有都是字节数组。它是一种字节进字节出的数据库,其特征在于,当插入一个值时,HBase隐式地通过序列号框架将数据转换成字节数组,然后存储进单元格,或者给出字节数组。
3. 当添加或者获取数值时,它隐式地转换成等价的数据展示出来。
4. HBase的单元格只能容纳字节数组。任何可以转换成字节的数据都可以存储在HBase中。
5. 可以存储10-15MB的值到HBase的单元格中,但如果值太大,可以将文件存储到HDFS中,然后在HBase中存储文件的路径。

















 3603
3603

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









