









1、项目pom引入es相关依赖
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-elasticsearch</artifactId>
</dependency>2、application.yml配置文件新增es配置
spring:
elasticsearch:
rest:
uris: http://localhost:9200
3、代码注入模板类就可以使用es了
@Autowired
private ElasticsearchRestTemplate template;
// 上述操作形式是ES早期的操作方式,使用的客户端被称为Low Level Client,
这种客户端操作方式性能方面略显不足,于是ES开发了全新的客户端操作方式,
称为High Level Client
@Autowired
private RestHighLevelClient client;4、通过es接口操作es
基本操作
ES中保存有我们要查询的数据,只不过格式和数据库存储数据格式不同而已。在ES中我们要先创建倒排索引,这个索引的功能又点类似于数据库的表,然后将数据添加到倒排索引中,添加的数据称为文档。所以要进行ES的操作要先创建索引,再添加文档,这样才能进行后续的查询操作。
要操作ES可以通过Rest风格的请求来进行,也就是说发送一个请求就可以执行一个操作。比如新建索引,删除索引这些操作都可以使用发送请求的形式来进行
创建索引
// 创建索引,books是索引名称,下同
PUT请求 http://localhost:9200/books
// 发送请求后,看到如下信息即索引创建成功
{
"acknowledged": true,
"shards_acknowledged": true,
"index": "books"
}
// 重复创建已经存在的索引会出现错误信息,reason属性中描述错误原因
{
"error": {
"root_cause": [
{
"type": "resource_already_exists_exception",
"reason": "index [books/VgC_XMVAQmedaiBNSgO2-w] already exists",
"index_uuid": "VgC_XMVAQmedaiBNSgO2-w",
"index": "books"
}
],
"type": "resource_already_exists_exception",
"reason": "index [books/VgC_XMVAQmedaiBNSgO2-w] already exists", # books索引已经存在
"index_uuid": "VgC_XMVAQmedaiBNSgO2-w",
"index": "book"
},
"status": 400
}查询索引
GET请求 http://localhost:9200/books
// 返回
{
"books": {
"aliases": {},
"mappings": {},
"settings": {
"index": {
"creation_date": "1691400465823",
"number_of_shards": "1",
"number_of_replicas": "1",
"uuid": "YPioI8LDTyiZfpw3OnInwQ",
"version": {
"created": "7090399"
},
"provided_name": "books"
}
}
}
}
// 如果查询了不存在的索引,会返回错误信息
{
"error": {
"root_cause": [
{
"type": "index_not_found_exception",
"reason": "no such index [book]",
"resource.type": "index_or_alias",
"resource.id": "book",
"index_uuid": "_na_",
"index": "book"
}
],
"type": "index_not_found_exception",
"reason": "no such index [book]",
"resource.type": "index_or_alias",
"resource.id": "book",
"index_uuid": "_na_",
"index": "book"
},
"status": 404
}删除索引
DELETE请求 http://localhost:9200/books
// 返回
{
"acknowledged": true
}
// 如果重复删除,会给出错误信息
{
"error": {
"root_cause": [
{
"type": "index_not_found_exception",
"reason": "no such index [books]",
"resource.type": "index_or_alias",
"resource.id": "books",
"index_uuid": "_na_",
"index": "books"
}
],
"type": "index_not_found_exception",
"reason": "no such index [books]",
"resource.type": "index_or_alias",
"resource.id": "books",
"index_uuid": "_na_",
"index": "books"
},
"status": 404
}创建索引并指定分词器:
前面创建的索引是未指定分词器的,可以在创建索引时添加请求参数,设置分词器。目前国内较为流行的分词器是IK分词器,使用前先在下对应的分词器,然后使用。
注意:IK分词器插件的版本要和ElasticSearch的版本一致
IK分词器下载地址:https://github.com/medcl/elasticsearch-analysis-ik/releases
分词器下载后解压到ES安装目录的plugins目录中即可,安装分词器后需要重新启动ES服务器。
注意:下载的分词器压缩文件不能放在plugins目录中,解压后可以删掉
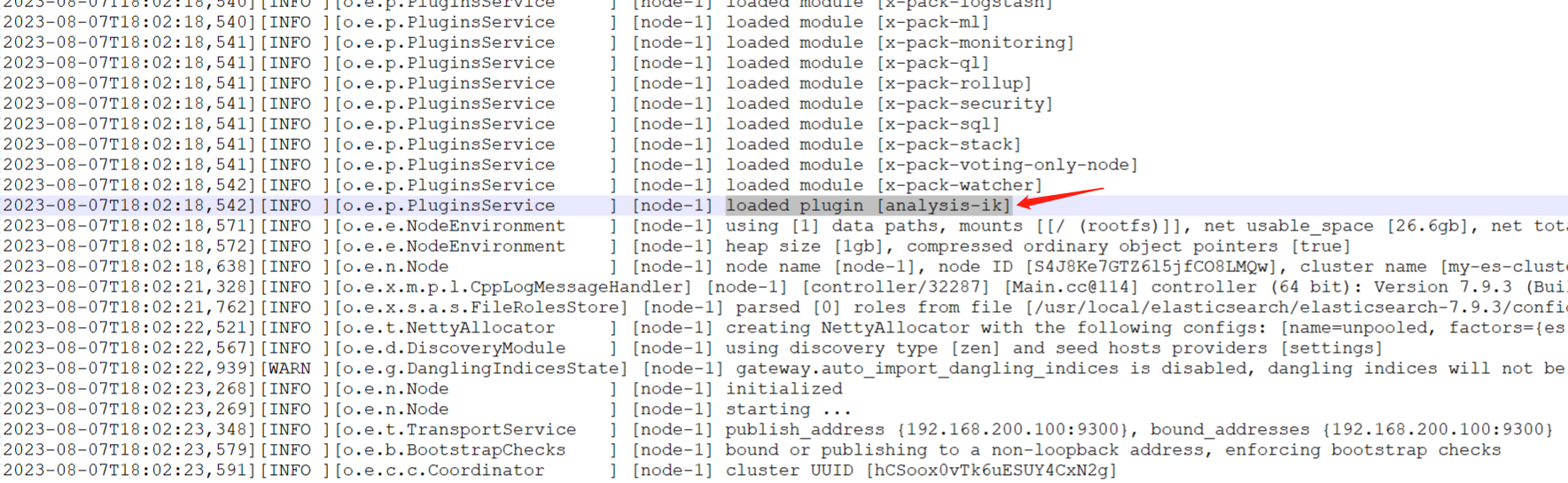
es启动日志出现如下信息说明ik分词器加载成功
使用IK分词器创建索引格式:
PUT请求 http://localhost:9200/books
注意:创建索引必须是小写,不能使用_开头
请求参数如下(注意是json格式的参数)
{
"mappings":{ #定义mappings属性,替换创建索引时对应的mappings属性
"properties":{ #定义索引中包含的属性设置
"id":{ #设置索引中包含id属性
"type":"keyword" #当前属性可以被直接搜索
},
"name":{ #设置索引中包含name属性
"type":"text", #当前属性是文本信息,参与分词
"analyzer":"ik_max_word", #使用IK分词器进行分词
"copy_to":"all" #分词结果拷贝到all属性中
},
"type":{
"type":"keyword"
},
"description":{
"type":"text",
"analyzer":"ik_max_word",
"copy_to":"all"
},
"all":{ #定义属性,用来描述多个字段的分词结果集合,当前属性可以参与查询
"type":"text",
"analyzer":"ik_max_word"
}
}
}
}
目前我们已经有了索引了,但是索引中还没有数据,所以要先添加数据,ES中称数据为文档,下面进行文档操作
添加文档,有三种方式
POST请求 http://localhost:9200/books/_doc #使用系统生成id
POST请求 http://localhost:9200/books/_create/1 #使用指定id
POST请求 http://localhost:9200/books/_doc/1 #使用指定id,不存在创建,存在更新(版本递增)
文档通过请求参数传递,数据格式json
{
"name":"springboot",
"type":"springboot",
"description":"springboot"
}
查询文档
GET请求 http://localhost:9200/books/_doc/1 #查询单个文档
GET请求 http://localhost:9200/books/_search #查询全部文档条件查询
GET请求 http://localhost:9200/books/_search?q=name:springboot # q=查询属性名:查询属性值
// 前缀匹配查询
概念:以xx开头的搜索,不计算相关度评分
{
"query": {
"prefix": {
"<field>": {
"value": "<word_prefix>"
}
}
}
}
// 模糊查询
混淆字符 (box → fox) 缺少字符 (black → lack)
多出字符 (sic → sick) 颠倒次序 (act → cat)
{
"query": {
"fuzzy": {
"<field>": {
"value": "<keyword>"
}
}
}
}
// 正则匹配查询
概念:regexp查询的性能可以根据提供的正则表达式而有所不同。
为了提高性能,应避免使用通配符模式,如.或 .?+未经前缀或后缀
{
"query": {
"regexp": {
"<field>": {
"value": "<regex>",
"flags": "ALL"
}
}
}
}
flags说明:
(1)ALL
启用所有可选操作符。
COMPLEMENT
启用操作符。可以使用对下面最短的模式进行否定。例如
a~bc # matches ‘adc’ and ‘aec’ but not ‘abc’
(2)INTERVAL
启用<>操作符。可以使用<>匹配数值范围。例如
foo<1-100> # matches ‘foo1’, ‘foo2’ … ‘foo99’, ‘foo100’
foo<01-100> # matches ‘foo01’, ‘foo02’ … ‘foo99’, ‘foo100’
(3)INTERSECTION
启用&操作符,它充当AND操作符。如果左边和右边的模式都匹配,则匹配成功。例如:
aaa.+&.+bbb # matches ‘aaabbb’
(4)ANYSTRING
启用@操作符。您可以使用@来匹配任何整个字符串。 您可以将@操作符与&和~操作符组合起来,创建一个“everything except”逻辑。例如:
@&~(abc.+) # matches everything except terms beginning with ‘abc’
// 通配符查询
概念:通配符运算符是匹配一个或多个字符的占位符。例如,*通配符运算符匹配零个或多个字符。
您可以将通配符运算符与其他字符结合使用以创建通配符模式。
{
"query": {
"wildcard": {
"<field>": {
"value": "<word_with_wildcard>"
}
}
}
}删除文档
DELETE请求 http://localhost:9200/books/_doc/1
修改文档(全量更新)
PUT请求 http://localhost:9200/books/_doc/1
文档通过请求参数传递,数据格式json
{
"name":"springboot",
"type":"springboot",
"description":"springboot"
}
修改文档(部分更新)
POST请求 http://localhost:9200/books/_update/1
文档通过请求参数传递,数据格式json
{
"doc":{ #部分更新并不是对原始文档进行更新,而是对原始文档对象中的doc属性中的指定属性更新
"name":"springboot" #仅更新提供的属性值,未提供的属性值不参与更新操作
}
}
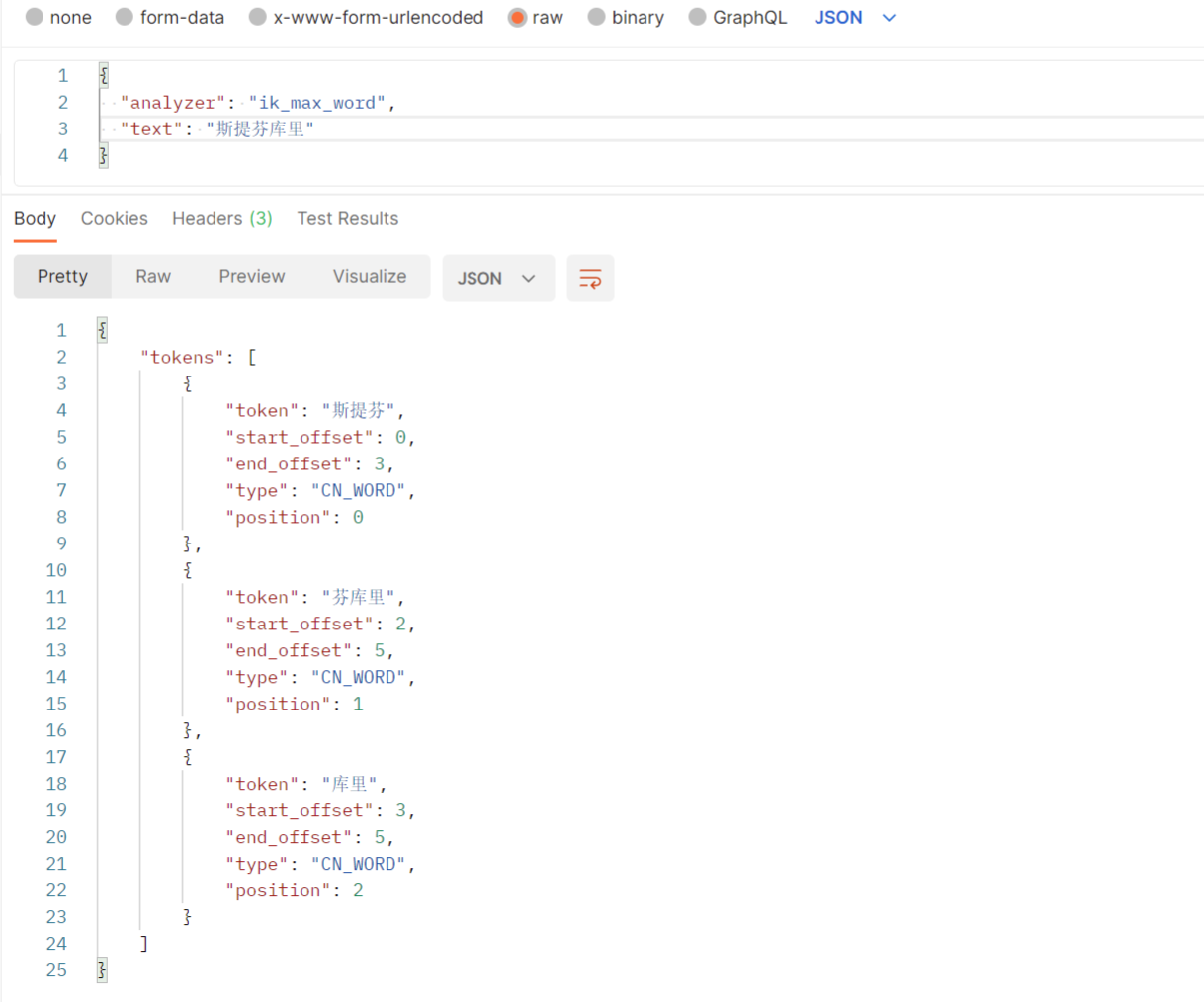
查看分词算法
GET请求 http://localhost:/_analyze
// 请求体
{
"analyzer": "ik_max_word",
"text": "斯提芬库里"
}5、自定义分词字典
用ik分词器分析的文本中不存在“芬库里”
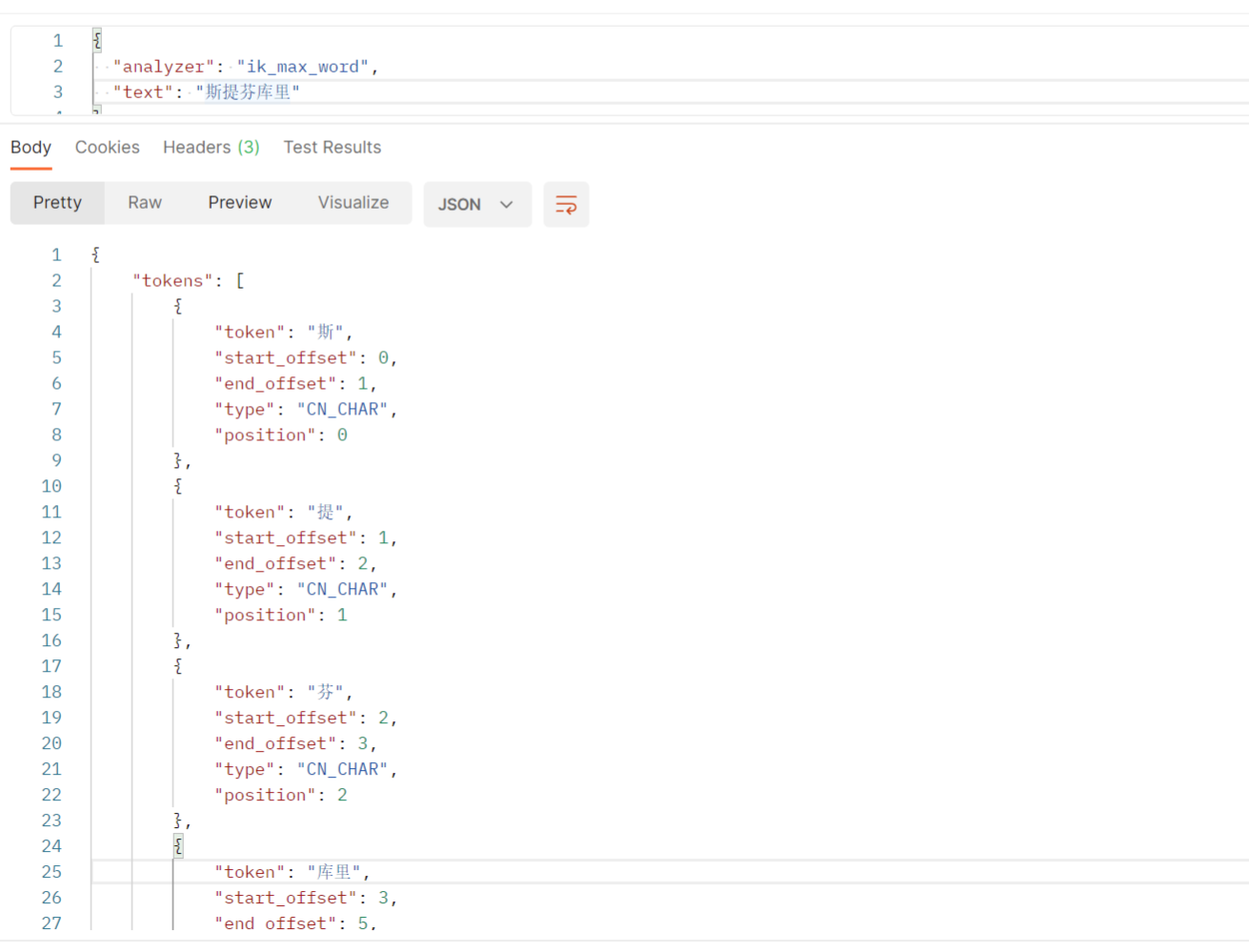
如果我想加入“芬库里”,此时就需要配置自定义字典--即自定义词组群,就是在IK分词器字典中加入我们自定义的字典,在词典中加入想要的词。
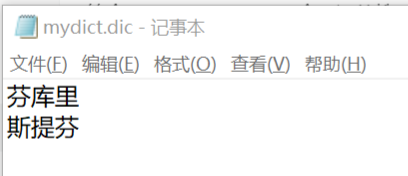
(1)在ik分词器文件的config目录中新建自定义的字典文件,以.dic为后缀,并在文件中加入“芬库里”:
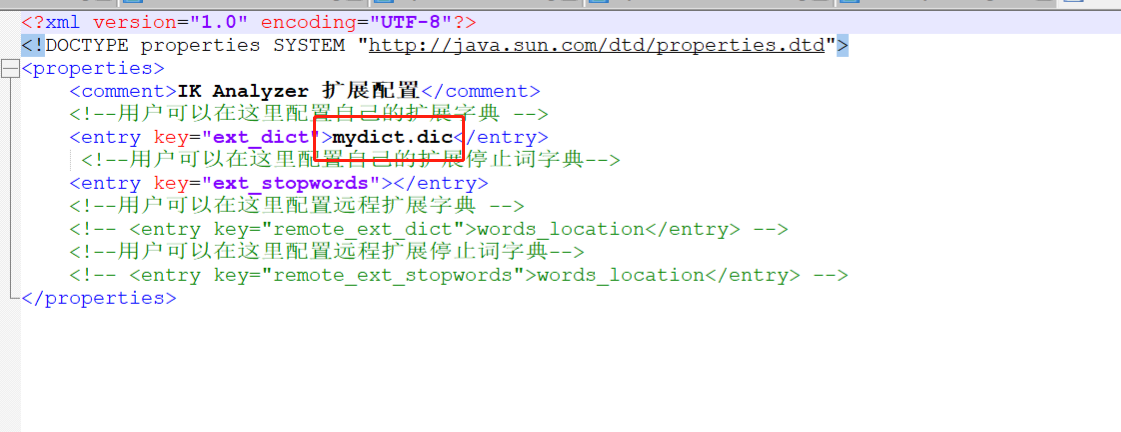
(2)在IKAnalyzer.cfg.xml配置文件中加入自定义的字典文件
(3)查看自定义分词字典是否生效
(4)创建索引时可以指定算法
{
"mappings":{
"properties":{
"name":{
"type": "text",
"analyzer":"ik_max_word"
},
"desc":{
"type": "text",
"analyzer":"ik_max_word"
}
}
}
}有问题和建议欢迎大家留言评论,谢谢~














 445
445











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









