







41.Nacos与 Zookeeper 的区别(过半机制):
1.nacos是使用mysql进行存储的,而zookeeper是使用本身的树形结构进行存储的
2.nacos支持两种方式的注册中心,持久化和非持久化存储服务信息
非持久直接存储在nacos服务节点的内存中,并且服务节点间采用去中心化的思想,服 务节点采用hash分片存储注册信息
持久化使用Raft协议选举master节点,同样采用过半机制将数据存储在leader节点上
Zookeeper:服务注册和消费信息直接存储在zk树形节点上,集群下同样采用过半机制保 证服务节点间一致性
过半机制:
目前有5台服务器,每台服务器均没有数据,它们的编号分别是1,2,3,4,5,按编号依次启动,它们的选择举过程如下:
- 服务器1启动,给自己投票,然后发投票信息,由于其它机器还没有启动所以它收不到反馈信息,服务器1的状态一直属于Looking(选举状态)。
- 服务器2启动,给自己投票,同时与之前启动的服务器1交换结果,由于服务器2的编号大所以服务器2胜出,但此时投票数没有大于半数,所以两个服务器的状态依然是LOOKING。
- 服务器3启动,给自己投票,同时与之前启动的服务器1,2交换信息,由于服务器3的编号最大所以服务器3胜出,此时投票数正好大于半数,所以服务器3成为领导者,服务器1,2成为小弟。
- 服务器4启动,给自己投票,同时与之前启动的服务器1,2,3交换信息,尽管服务器4的编号大,但之前服务器3已经胜出,所以服务器4只能成为小弟。
- 服务器5启动,后面的逻辑同服务器4成为小弟。
42. RabbitMQ
1.Broker服务节点、Queue队列、Exchange交换器
-
Broker可以看做RabbitMQ的服务节点。一般请下一个Broker可以看做一个RabbitMQ服务器。(通过vhost来新增)
-
Queue:RabbitMQ的内部对象,用于存储消息。多个消费者可以订阅同一队列,这时队列中的消息会被平摊(轮询)给多个消费者进行处理。
-
Exchange:生产者将消息发送到交换器,由交换器将消息路由到一个或者多个队列中。当路由不到时,或返回给生产者或直接丢弃
2.保证消息没有重复消费
让每个消息携带一个全局的唯一ID,即可保证消息的幂等性,具体消费过程为:
- 消费者获取到消息后先根据id去查询redis/db是否存在该消息
- 如果不存在,则正常消费,消费完毕后写入redis/db
- 如果存在,则证明消息被消费过,直接丢弃。
3.保证消息传递的顺序性
先看看顺序会错乱的场景
(1)rabbitmq:一个queue,多个consumer,这不明显乱了;
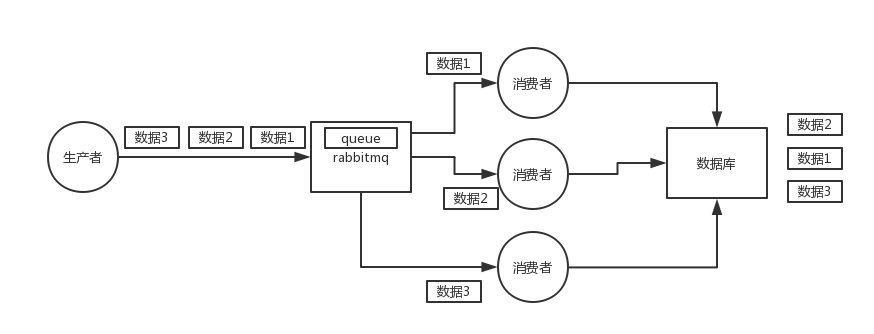
(2)rabbitmq:拆分多个queue,每个queue一个consumer,就是多一些queue而已,确实是麻烦点;或者就一个queue但是对应一个consumer,然后这个consumer内部用内存队列做排队,然后分发给底层不同的worker来处理;
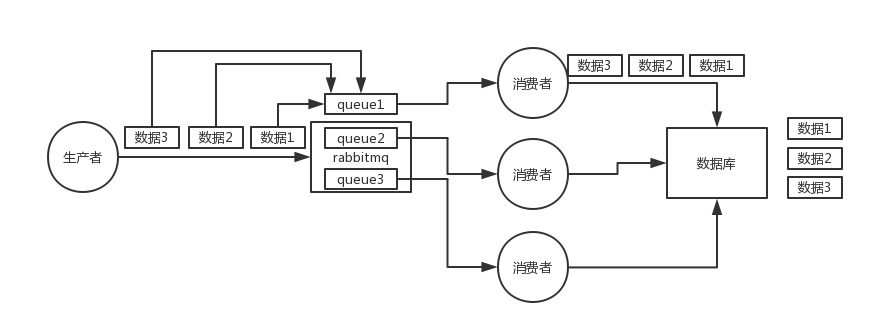
4.怎么处理消息丢失的情况
RabbitMQ的消息丢失分三种情况:
第一种:生产者弄丢了数据。生产者将数据发送到 RabbitMQ 的时候,可能数据就在半路给搞丢了,因为网络问题啥的,都有可能。
第二种:RabbitMQ 弄丢了数据。MQ还没有持久化自己挂了
第三种:消费端弄丢了数据。刚消费到,还没处理,结果进程挂了,比如重启了。
一:针对生产者
方案1.开启RabbitMQ事务
可以选择用 RabbitMQ 提供的事务功能,就是生产者发送数据之前开启 RabbitMQ 事务channel.txSelect,然后发送消息,如果消息没有成功被 RabbitMQ 接收到,那么生产者会收到异常报错,此时就可以回滚事务channel.txRollback,然后重试发送消息;如果收到了消息,那么可以提交事务channel.txCommit。
方案2 使用confirm机制
事务机制和 confirm 机制最大的不同在于,事务机制是同步的,你提交一个事务之后会阻塞在那儿,但是 confirm 机制是异步的,你发送个消息之后就可以发送下一个消息,然后那个消息 RabbitMQ 接收了之后会异步回调你的一个接口通知你这个消息接收到了。
二、针对RabbitMQ
1.消息持久化
2.设置集群镜像模式
3.消息补偿机制
消息补偿机制需要建立在消息要写入DB日志,发送日志,接受日志,两者的状态必须记录。
然后根据DB日志记录check 消息发送消费是否成功,不成功,进行消息补偿措施,重新发送消息处理。
三、针对消费者
ACK确认机制:就是RabbitMQ发送了一个消息给消费者,消费者执行完了业务,发送个ACK给RabbitMQ,mq接收到了ACK就删除队列里的消息。
5.怎么让消息延迟消费
我们可以专门创建一个延迟消费的队列,这个队列里的消息都设置了TTL过期时间
6.死信队列
DLX,全称为 Dead-Letter-Exchange,死信交换器,死信邮箱。当消息在一个队列中变成 死 信 (dead message) 之后,它能被重新被发送到另一个交换器中,这个交换器就是 DLX, 绑定 DLX 的队列就称之为死信队列。
7.消息变成死信的原因
-
消息被拒(
Basic.Reject /Basic.Nack) 且requeue = false。 -
消息TTL过期。
-
队列满了,无法再添加。
7.生产者如何将消息可靠投递到MQ
1.Client发送消息给MQ
2.MQ将消息持久化后,发送Ack消息给Client,此处有可能因为网络问题导致Ack消息无 法发送到Client,那么Client在等待超时后,会重传消息;
3.Client收到Ack消息后,认为消息已经投递成功。
8.MQ如何将消息可靠投递到消费者
1.MQ将消息push给Client(或Client来pull消息)
2.Client得到消息并做完业务逻辑
3.Client发送Ack消息给MQ,通知MQ删除该消息,此处有可能因为网络问题导致Ack失败,那么Client会重复消息,这里就引出消费幂等的问题;
4.MQ将已消费的消息删除
9.如何保证RabbitMQ消息队列的高可用
RabbitMQ 有三种模式:单机模式,普通集群模式,镜像集群模式。
单机模式:就是demo级别的,一般就是你本地启动了玩玩儿的,没人生产用单机模式
普通集群模式:意思就是在多台机器上启动多个RabbitMQ实例,每个机器启动一个。
镜像集群模式:这种模式,才是所谓的RabbitMQ的高可用模式,跟普通集群模式不一样的是,你创建的queue,无论元数据(元数据指RabbitMQ的配置数据)还是queue里的消息都会存在于多个实例上,然后每次你写消息到queue的时候,都会自动把消息到多个实例的queue里进行消息同步。
43.Spring事务失效的一种原因(this调用)
Spring中一个没有事务的方法A调用一个默认事务(PROPAGATION_REQUIRED)的方法B时,如果使用this调用方法B,方法B抛出RuntimeException,此时方法B事务未生效,不会回滚
问题原因:
JDK的动态代理。只有被动态代理直接调用时才会产生事务。在SpringIoC容器中返回的调用的对象是代理对象而不是真实的对象。而这里的this是EmployeeService真实对象而不是代理对象。
方法1、在方法A上开启事务,方法B不用事务或默认事务,并在方法A的catch中throw new RuntimeException();(在没指定rollbackFor时,默认回滚的异常为RuntimeException),这样使用的就是方法A的事务。(一定要throw new RuntimeException();否则异常被捕捉处理,同样不会回滚。)如下:
@Transactional() //开启事务
public void save(){
try {
this.saveEmployee(); //这里this调用会使事务失效,数据会被保存
}catch (Exception e){
e.printStackTrace();
throw new RuntimeException();
}
}
方法2、方法A上可以不开启事务,方法B上开启事务,并在方法A中将this调用改成动态代理调用(AopContext.currentProxy()),如下:
public void save(){
try {
EmployeeService proxy =(EmployeeService) AopContext.currentProxy();
proxy.saveEmployee();
}catch (Exception e){
e.printStackTrace();
}
}
44.Activiti
1:什么是工作流,工作流的核心对象是什么,activiti共操作数据库多少张表
* 工作流就是多个参与者,按照某种预定义的规则,传递业务信息,进行审核的功能一个框架(Activiti)
* processEngine,调用Service,从而操作数据库的表
* 25表
2:工作流中RepositoryService、RuntimeService、TaskService、HistoryService分别表示什么操作
RepositoryService:流程定义和部署对象
RuntimeService:执行管理,包括流程实例和执行对象(正在执行)
TaskService:执行任务相关的(正在执行)
HistoryService:历史管理
IdentityService:Activiti表的用户角色组
3:流程实例和执行对象的区别
* 流程从开始到结束的最大分支,一个流程中,流程实例只有1个
* 执行对象(工作项),就是按照流程定义的规则执行一次的操作,一个流程中,执行对象可以有多个
4:activiti工作流中,如果一个任务完成后,存在多条连线,应该如何处理?
* 使用流程变量
* 当一个任务完成之后,根据这几条连线的条件和设置流程变量,例如${流程变量的名称==’流程变量的值’},{}符号是boolean类型,判断走哪条连线
5:流程变量在项目中的作用
* 1:用来传递业务参数,目的就是审核人可以通过流程变量查看申请人的一些审核信息
2:在连线的condition中设置流程变量,用来指定应该执行的连线${message==’重要’}
3:使用流程变量指定个人任务和组任务的办理人#{userID}
6:activiti工作流中,排他网关和并行网关都能执行什么功能
排他网关:分支,通过连线的流程变量,判断执行哪条连线,如果条件不符合,会执行默认的连线离开,注意:只能执行其中的一个流程。
并行网关:可以同时执行多个流程,直到总流程的结束。可以对流程进行分支和聚合,注意:流程实例和执行对象是不一样的
7:分配个人任务的三种方式
*直接给值,在Xxxx.bpmn文件中指定
*流程变量${流程变量的名称}或者#{}
*使用类 监听这个类(实现一个接口),指定任务的办理人(setAssgnee())
45.MongoDB
1.什么是MongoDB
MongoDB是一个文档数据库,提供好的性能,领先的非关系型数据库。采用BSON存储文档数据。 BSON()是一种类json的一种二进制形式的存储格式,简称Binary JSON. 相对于json多了date类型和二进制数组。
2.MongoDB的优势有哪些
- 面向文档的存储:以 JSON 格式的文档保存数据。
- 任何属性都可以建立索引。
- 复制以及高可扩展性。
- 自动分片。
- 丰富的查询功能。
- 快速的即时更新。
3.什么是集合(表)
集合就是一组 MongoDB 文档。它相当于关系型数据库(RDBMS)中的表这种概念。集合位于单独的一个数据库中。 一个集合内的多个文档可以有多个不同的字段。一般来说,集合中的文档都有着相同或相关的目的。
4 什么是文档(记录)
文档由一组key value组成。文档是动态模式,这意味着同一集合里的文档不需要有相同的字段和结构。在关系型 数据库中table中的每一条记录相当于MongoDB中的一个文
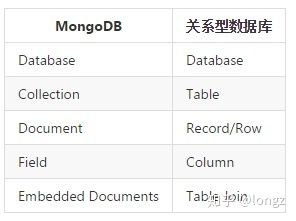
5 MongoDB和关系型数据库术语对比图
6.什么是非关系型数据库
非关系型数据库的显著特点是不使用SQL作为查询语言,数据存储不需要特定的表格模式。
7 monogodb 中的分片什么意思
分片是将数据水平切分到不同的物理节点。当应用数据越来越大的时候,数据量也会越来越大。当数据量增长 时,单台机器有可能无法存储数据或可接受的读取写入吞吐量。利用分片技术可以添加更多的机器来应对数据量增加 以及读写操作的要求。
8 MongoDB支持哪些数据类型
-
- String
- Integer
- Double
- Boolean
- Object
- Object ID
- Arrays
- Min/Max Keys
- Datetime
- Code
- Regular Expression等
9 为什么要在MongoDB中用"Code"数据类型
"Code"类型用于在文档中存储 JavaScript 代码。
10 为什么要在MongoDB中用"Regular Expression"数据类型
"Regular Expression"类型用于在文档中存储正则表达式
11 为什么在MongoDB中使用"Object ID"数据类型
"ObjectID"数据类型用于存储文档id
12 在MongoDb中什么是索引
索引用于高效的执行查询,没有索引的MongoDB将扫描整个集合中的所有文档,这种扫描效率很低,需要处理大量
的数据.
索引是一种特殊的数据结构,将一小块数据集合保存为容易遍历的形式.索引能够存储某种特殊字段或字段集的
值,并按照索引指定的方式将字段值进行排序.
13 如何添加索引
使用db.collection.createIndex()在集合中创建一个索引
14.如何查询集合中的文档
db.collectionName.find({key:value})
15用什么方法可以格式化输出结果
db.collectionName.find().pretty()
16 如何使用"AND"或"OR"条件循环查询集合中的文档
db.mycol.find(
{
$or: [
{key1: value1}, {key2:value2}
]
}
).pretty()
17更新数据
db.collectionName.update({key:value},{$set:{newkey:newValue}})
18 MongoDB支持存储过程吗?如果支持的话,怎么用?
MongoDB支持存储过程,它是javascript写的,保存在db.system.js表中。















 1564
1564











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









