






目录
松耦合分布式系统的锁服务 Chubby
摘要
我们描述了我们使用 Chubby 锁服务的经验,该服务旨在为松散耦合的分布式系统提供粗粒度的锁以及可靠的(尽管体积很小)存储。Chubby 提供了一个类似于带有咨询锁的分布式文件系统的接口,但是其设计重点是可用性和可靠性,而不是高性能。该服务的许多实例已经使用了一年多,其中几个实例同时处理数万个客户端。本文描述了最初的设计和预期的使用,并将其与实际使用进行了比较,解释了如何修改设计以适应差异。
1 介绍
本文介绍了一种名为 Chubby 的锁服务。它的目标是在一个松散耦合的分布式系统中使用,该系统由大量的小机器通过高速网络连接而成。例如,一个 Chubby 的实例(也称为 Chubby cell )可能服务于由 1Gbit/s 以太网连接的 10,000 台 4 处理器机器。大多数 Chubby cell 被限制在一个单独的数据中心或机房里,尽管我们确实运行着至少一个 Chubby cell,它们与复制品之间相隔数千公里。
锁服务的目的是允许它的客户端同步它们的活动,并就它们的环境的基本信息达成一致。主要目标包括可靠性、对中等规模的客户端的可用性和易于理解的语义;吞吐量和存储容量被认为是次要的。Chubby 的客户端接口类似于执行整个文件读写的简单文件系统,并增加了通知锁和文件修改等各种事件的通知。
我们希望 Chubby 能够帮助开发人员处理系统内的粗粒度同步,特别是处理从一组其他方面相当的服务器中选出一个 Leader 的问题。例如,Google 文件系统使用一个 Chubby 锁来指定一个 GFS Master,而 Bigtable 以几种方式使用 Chubby :选择一个 Master ,允许 Master 发现它所控制的服务器,以及允许客户端找到 Master。此外,GFS 和 Bigtable 都使用 Chubby 存储少量元数据;实际上,他们使用 Chubby 作为分布式数据结构的根。一些服务使用锁在多个服务器之间(以粗粒度)划分工作。
在部署 Chubby 之前,Google 上的大多数分布式系统都使用了一些特别的方法来进行 Primary 选举(当工作可以在不造成任何伤害的情况下进行复制时),或者需要操作员的干预(当正确性非常重要时)。在前一种情况下,Chubby 允许在计算工作中节省一点时间。在后一种情况下,它显著提高了系统的可用性,不再需要人为干预。
熟悉分布式计算的读者将会认识到,在 Peers 之间进行 Primary 选举是分布式一致性问题的一个实例,并意识到我们需要一个使用异步通信的解决方案;这个术语描述了绝大多数真实网络(如以太网或 Internet )的行为,这些网络允许数据包丢失、延迟和重新排序。(实践者通常应该注意基于模型的协议,这些模型对环境做出了更强的假设。)异步一致性通过 Paxos 协议解决。Oki 和 Liskov 使用了相同的协议(参见他们关于 viewstamped replication 的论文),其他人也注意到了这种等价性。实际上,我们目前遇到的所有异步协商一致的工作协议的核心都是 Paxos。Paxos 在没有时间假设的情况下保持安全,但必须引入时钟以确保活性;这克服了 Fischer 等人的不可能的结果。
建设 Chubby 是一项工程努力,需要满足上述需求;这不是研究。我们没有提出新的算法或技术,这篇论文的目的是描述我们做了什么,为什么做,而不是提倡它。在下一节中,我们将介绍 Chubby 的设计和实现,以及它是如何根据经验进行更改的。我们描述了 Chubby 出人意料的用法,以及被证明是错误的功能。我们省略了文献中其他地方所涉及的细节,例如一致性协议或 RPC 系统的细节。
2 设计
2.1 基本原理
有人可能会说,我们应该构建一个包含 Paxos 的库,而不是一个访问集中式锁服务(甚至是一个高度可靠的锁服务)的库。客户端 Paxos 库将不依赖于任何其他服务器(除了 name service 之外),并为程序员提供标准框架,假设他们的服务可以作为状态机实现。实际上,我们提供了这样一个独立于 Chubby 的客户端库。
尽管如此,与客户端库相比,锁服务有一些优势。首先,我们的开发人员有时并不按照期望的方式计划高可用性。他们的系统通常以原型开始,只有很少的负载和松散的可用性保证;通常情况下,代码并没有特别的结构来与一致性协议一起使用。随着服务的成熟和客户的增加,可用性变得更加重要;然后将复制和 Primary 选举添加到现有设计中。虽然这可以通过提供分布式一致性的库来实现,但是锁服务器使维护现有的程序结构和通信模式变得更加容易。例如,选出一个 Master 然后写入现有的文件服务器需要将两个语句和一个 RPC 参数添加到一个现有的系统:一个将获得一个锁,成为 Master ,通过额外的整数(锁获取计数)写 RPC ,如果请求计数低于当前值(防止数据包延迟),将一个 if 语句添加到文件服务器拒绝写入。我们发现这种技术比让现有的服务器加入一致性协议更容易,尤其是在迁移期间( transition period )必须维持兼容性时。
其次,我们的许多服务选择一个主服务,或者在它们的组件之间划分数据时,这些服务需要一种发布结果的机制。这意味着我们应该允许客户端存储和获取少量数据——也就是说,读取和写入小文件。这可以通过 name service 来完成,但是我们的经验是,锁服务本身非常适合这项任务,因为它减少了客户端所依赖的服务器数量,而且协议的一致性特性是相同的。Chubby 作为 name server 的成功很大程度上归功于它使用了一致的客户端缓存,而不是基于时间的缓存。特别的是,我们发现开发者不会选择像 DNS 生存时间 TTL(time-to-live) 一样的缓存超时值,这个值如果选择不当会导致很高的 DNS 负载或者较长的客户端故障修复时间。
第三,我们的程序员更熟悉基于锁的接口。Paxos 的复制状态机 (replicated state machine) 和与排他锁相关联的临界区都能为程序员提供顺序编程的幻觉。可是,许多程序员已经用过锁了,并且认为他们知道怎么使用它们。颇为讽刺的是,这样的程序员经常是错的,尤其是当他们在分布式系统里使用锁时。很少人考虑单个机器的失败对一个异步通信的系统中的锁的影响。不管怎样,对锁的 "熟悉性",战胜了我们试图说服程序员们为分布式决策使用可靠机制的努力。
最后,分布式一致性算法使用 Quorums 进行决策,因此它们使用多个副本来实现高可用性。例如,通常 Chubby 本身在每个 cell 中有5个副本,Chubby 单元要存活就必须保证其中三个副本在正常运行。相反,如果客户端系统使用锁服务,即使一个客户端也可以获得锁并安全地进行处理。因此,锁服务减少了可靠的客户端系统运行时所需要的服务器数量。在广义上,人们可以将锁服务视为一种提供通用选择的方法,这种选择允许客户端系统在其自身成员未达到大多数时做出正确的决策。人们可以想象用另一种方式解决最后这个问题:通过提供 "一致性服务",在 Paxos 协议中使用许多服务器来提供 "接受者"。与锁服务一样,共识服务允许客户端在只有一个活动客户端进程的情况下安全地进行;类似的技术也用于减少拜占庭式容错所需的状态机数量。然而,假设协同服务不是专门用于提供锁(这将其简化为锁服务),则此方法无法解决上述任何其他问题。
这些论证提出了两个关键的设计决策:
- 我们选择了一个锁服务,而不是一个库或一致性服务来达成共识,以及
- 我们选择提供小文件,使得被选出来的 Primaries 可以公布自身以及它们的参数,而不是创建和维护另一个服务。
一些决定来自我们的预期使用和我们的环境:
- 通过一个 Chubby 的文件公布其 Primary 服务,可能会有成千上万的客户。因此,我们必须允许数千个客户端监视这个文件,并且在这一过程中最好不需要太多服务器。
- 客户端和有多个副本(replica)的服务的各个副本要知道什么时候服务的 Primary 发生了变化。这意味着一种事件通知机制将有助于避免轮询。
- 即使客户端不需要定期轮询文件,但许多客户端会这样做;这是支持许多开发人员的结果。因此,缓存这些文件是可取的。
- 我们的开发人员被不直观的缓存语义搞糊涂了,所以我们更喜欢一致的缓存。
- 为了避免经济损失和牢狱之灾,我们提供了包括访问控制在内的安全机制。
一个可能会让一些读者感到惊讶的选择是,我们不期望锁的使用是细粒度的,在这种情况下,锁可能只被持有很短的时间(数秒钟或更少);实际上,我们期望粗粒度的使用。例如,一个应用程序可能使用一个锁来选择一个 Master,然后 Master 将在相当长的时间内(几小时或几天)处理对该数据的所有访问。这两种使用方式意味着对锁服务器的不同需求。
粗粒度锁对锁服务器的负载要小得多。特别是,锁的获取频率通常与客户端应用系统的事务频率只有很微弱的关联。粗粒度的锁很少被获取,所以临时性的锁服务器的不可用给客户端造成的延时会更少。另一方面,锁在客户端间的转移可能需要高昂的恢复处理,所以人们不希望锁服务器的故障恢复导致锁丢失。因此,粗粒度的锁可以很好地应对锁服务器故障,几乎不需要考虑这样做的开销,而且这样的锁允许少量的锁服务器以较低的可用性为许多客户端提供足够的服务。
细粒度的锁会有不同的结论。即使锁服务器短暂地不可用,也可能导致许多客户端被挂起。因为锁服务的事务频率随着客户端的事务频率之和一起增长,所以性能和随意增加新服务器的能力非常重要。通过不维护跨锁服务器故障的锁来减少锁的开销是有优势的,而且由于锁只会被持有很短的时间,所以偶尔丢弃锁的时间损失并不严重。(客户端必须准备好在网络分区期间丢失锁,所以锁服务器故障恢复造成的锁的丢失不会引入新的恢复路径。)
Chubby 只提供粗粒度的锁定。幸运的是,客户端可以直接实现针对其应用程序定制的细粒度锁。应用程序可以将其锁划分为组,并使用 Chubby 的粗粒度锁将这些锁组分配给应用程序特定的锁服务器。维护这些细粒度的锁只需要很少的状态;服务器只需要保持一个稳定的、单调递增的且很少更新的请求计数器,客户端能够在解锁时发现丢失了的锁,如果使用简单的定长租期(lease),协议会变得简单而有效。此方案最重要的好处是,我们的客户端开发人员负责提供支持其负载所需要的服务器,而不必自己去实现共识机制。
2.2 系统结构
Chubby 有两个通过 RPC 通信的主要组件:服务器和客户端应用程序链接的库;参见图1。Chubby 客户端和服务器之间的所有通信都由客户端库进行中介。第3.1节讨论了可选的第三个组件,即代理服务器。
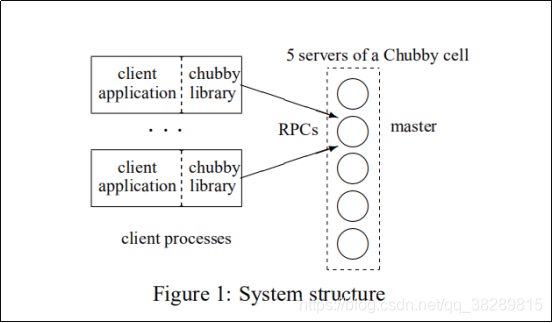
一个 Chubby 单元由一组称为副本(replicas)的服务器(通常是5个)组成,放置这些服务器是为了减少相关故障的可能性(例如,放在不同的机架上)。副本使用一个分布式一致性协议来选举一个 Master ;Master 必须从大多数副本中获得选票,并保证这些副本在 Master 租用的几秒钟内不会选择其他的 Master。主租赁由副本定期更新,前提是主租赁继续赢得多数选票。
副本维护一个简单数据库的副本集,但是只有 Master 才会发起对数据库的读写。其他所有副本只是复制来自 Master 的更新,使用一致性协议发送。
客户端通过向 DNS 中列出的副本集发送 Master 位置请求来找到 Master。非主副本通过返回主副本的身份来响应此类请求。一旦客户端找到了 Master,客户端就会将所有请求定向到它,直到它停止响应,或者直到它指出它不再是 Master。写请求通过协商一致性协议传播到所有副本;当写操作到达计算单元中的大多数副本时,将确认这些请求。读请求仅由 Master 来满足;这是安全的,只要主租赁没有到期,因为没有其他的 Master 存在。如果 Master 失败,其他副本在其 Master 租约到期时运行选举协议;新的 Master 通常会在几秒钟内选出。例如,最近的两次选举分别花了 6s 和 4s,但我们也见过长达 30s 的情况。
如果一个副本发生故障,并且几个小时内无法恢复,则简单的替换系统将从空闲池中选择一台新机器,并启动其上的锁服务器的二进制文件。然后更新 DNS 表,将失败副本的 IP 地址替换为新副本的 IP 地址。当前的 Master 定期轮询 DNS,并最终注意到变化。然后更新单元数据库中单元成员的列表;这个列表通过正常的复制协议在所有成员之间保持一致。与此同时,新副本从存储在文件服务器上的备份和活动副本的更新组合中获取数据库的最新副本。一旦新副本处理了当前 Master 等待提交的请求,就允许该副本在新 Master 的选举中投票。
2.3 文件、目录和句柄
Chubby 开放的文件系统接口与 UNIX 类似,但比后者更简单。它通常按照的方式由严格的文件和目录树组成,名称组成部分由斜杠分隔。一个典型的名字是: / ls / foo /wombat/pouch
ls 前缀对所有 Chubby 的名字都相同,代表锁服务(lock service)。第二部分(foo)是一个 Chubby 单元的名称;它通过 DNS 查询解析为一个或多个 Chubby 服务器。一个特殊的单元名称 local,表示应该使用客户端的本地 Chubby 单元;这个 Chubby 单元通常在同一栋楼里,因此这个单元最有可能能访问到。名字的剩余部分,/wombat/pouch,是在 Chubby 单元内解析的。同样,在 UNIX 下,每个目录包含子文件和子目录的列表,而每个文件包含未解析的字节序列。
因为 Chubby 的命名结构类似于一个文件系统,所以我们既可以通过专门的 API 将它开放给应用系统,也可以通过我们其他文件系统,例如 GFS 使用的接口。这显著地减少了编写基本的浏览和名字空间操作工具所需的工作,也减少了培训那些偶然使用 Chubby 的用户的需求。
这种设计使得 Chubby 接口不同于 UNIX 文件系统,它使得分布更容易(The design differs from UNIX in a ways that easy distribution)。为允许不同目录下的文件由不同的 Chubby master 来服务,我们没有放出那些将文件从一个目录移动到另一个目录的操作,我们不维护目录修改时间,也避开路径相关的权限语义(也就是文件的访问由其本身的权限控制,而不由它上层路径上的目录控制)。 为使缓存文件元数据更容易,系统不公开最后访问时间。
名称空间只包含文件和目录,统称为节点。每个这样的节点在其Chubby单元内只有一个名称;没有符号链接和硬链接。
节点可以是永久的(permanent),也可以是短暂的(ephemeral)。任意节点都可以被显示地(explicitly)删除,但是瞬时节点也会在没有客户端打开它时被删除 (另外,对目录而言,在它们为空时被删除)。短暂的文件被用作临时文件,并作为其他客户端存活的指示器。任意节点都能作为一个意向性(advisory)的读写锁;这些锁将在 2.4 节更详细地描述。
每个节点都有多种元数据,包括访问控制列表 (access control lists,ACLs) 的三个名字,分别用于控制读、写和修改其 ACL。除非被覆盖,否则节点在创建时将继承其父目录的 ACL 名称。ACLs 本身是位于一个 ACL 目录中的文件, 这个 ACL 目录是 Chubby 单元的一个为人熟知的本地名字空间。这些 ACL 文件的内容由简单的访问名字(principals)列表组成;读者可能会想起 Plan 9 的 groups 。因此,如果文件 F 的写 ACL 名称是 foo,并且 ACL 目录中包含一个 foo 文件,foo 文件中包含 bar 这个条目,那么用户 bar 就可以写文件 F。用户由内嵌在 RPC 系统里的机制鉴权。因为 Chubby 的 ACLs 是平常的文件,它们自动地就可以由其他想使用类似的访问控制机制的服务访问。
每个节点的元数据包括四个单调增加的 64 位编号,有利于客户端很容易地检测变化:
- 实例编号:大于任意先前的同名节点的实例编号。
- 内容生成编号(仅限文件):当写入文件的内容时,这个值会增加。
- 锁生成编号:当节点的锁从空闲状态转换到被持有状态时,这个值会增加。
- ACL 生成编号:当写入节点的 ACL 名称时,这种情况会增加。
- Chubby 还开放了一个 64 位的文件内容校验和,以便客户端可以判断文件是否有变化。
客户端通过打开节点以获得类似于 UNIX 文件描述符的句柄。句柄包括:
- 校验位:阻止客户端自行创建或猜测句柄,所以完整的访问控制检查只需要在句柄创建时执行(对比UNIX,UNIX 在打开时检查权限位但在每次读写时不检查,因为文件描述符不能伪造)。
- 一个序列号:这个序列号允许 Master 分辨一个句柄是由它或前面的 Master 生成。
- 模式信息:在句柄打开时设定的是否允许新 Master 在遇见一个由前面的 Master 创建的旧句柄时重建该句柄的状态。
2.4 锁和计序器
每个 Chubby 文件和目录都可以充当读/写锁:一个客户端句柄可以在独占(写)模式下持有锁,或者任意数量的客户端句柄可以在共享(读)模式下持有锁。就像大多数程序员所知道的互斥锁(mutexes)一样,锁是协同锁(advisory lock)。也就是说,它们只与获取相同锁的其他请求冲突:持有锁F既不是访问文件F的必要条件,也不会阻止其他客户端访问文件F。我们舍弃强制锁(mandatory lock),因为它使得其他没有持有锁的客户端不能访问被锁定的对象:
- Chubby 锁通常保护由其他服务实现的资源,而不仅仅是与锁相关的文件。要以一种有意义的方式强制实施强制锁定,我们需要对这些服务进行更广泛的修改。
- 我们不希望强制用户在出于调试或管理目的需要访问锁定的文件时关闭应用程序。在复杂的系统中,使用大多数个人计算机上使用的方法比较困难,在这种情况下,管理软件可以通过指示用户关闭其应用程序或重新启动来打破强制锁。
- 我们的开发人员以传统的方式执行错误检查,编写诸如 "持有锁X" 之类的断言,因此他们从强制检查中获益甚微。当不持有锁时,有 bug 的或恶意的进程有很多机会破坏数据,所以我们发现强制锁提供的额外保护没有多大价值。
在 Chubby 中,请求任意模式的锁都需要写权限,因而一个无权限的读者不能阻止一个写者的操作。
在分布式系统中,锁是复杂的,因为通信经常是不确定的,并且进程可能会独立地失败。因此可能会出现这种情况,持有锁 L 的进程可能会发出请求 R,但随后就会失败了。另一个进程可能在 R 获取之前就获得了 L,并执行了一些操作。如果 R 稍后到达,它可能在没有 L 保护的情况下被执行,并且可能对不一致的数据进行操作。接收消息顺序紊乱的问题已经被研究得很彻底:解决方案包括虚拟时间(virtual time)和虚拟同步(virtual synchrony)后者通过确保与每个参与者的观察一致的顺序处理消息,从而避免了这个问题。
在现有的复杂系统中,将序列号引入到所有的交互中的成本是很高的。相反,Chubby 提供了一种方法,通过这种方法,序列号只能被引入到那些使用锁的交互中。在任何时候,锁的持有者都可以请求一个序号,这是一个不透明的字节串,描述锁在刚获取后的状态。它包含锁的名称、获取锁的模式(独占或共享)以及锁的生成号( generation number)。如果客户端希望它的操作受到锁的保护,那么它就会将定序器 (sequencer) 传递给服务器(例如文件服务器)。接收服务器要做的工作是测试定序器 (sequencer) 是否仍然有效并具有适当的模式;如果不是,则应拒绝请求。可以根据服务器的 Chubby 缓存来检查定序器的有效性,如果服务器不希望维护与 Chubby 的会话,也可以根据服务器观察到的最新的定序器来检查。定序器机制只需要向受影响的消息添加一个字符串,并且很容易向我们的开发人员解释。
虽然我们发现定序器使用简单,但重要的协议发展缓慢。因此,Chubby 提供了一种不完美但更简单的机制,以减少向不支持定序器的服务器发送延迟或重新排序请求的风险。如果一个客户端以正常的方式释放了一个锁,那么其他客户端就可以立即使用这个锁。但是,如果锁因为持有者停止工作或不可访问而变为空闲状态,则锁服务器将在一段被称为锁延迟 (lock-delay) 的时间段内阻止其他客户端请求锁。客户端可以指定任何锁延迟(目前上限是一分钟);这个限制可以防止错误的客户端使锁(以及一些资源)在长时间内不可用。虽然不完美,但锁延迟保护未修改的服务器和客户端免受消息延迟和重启造成的日常问题。
2.5 事件
Chubby 客户端在创建句柄时可能订阅一系列事件。这些事件通过来自 Chubby 库的向上调用被异步传递到客户端。活动包括:
- 文件内容修改——通常用于监视通过文件发布的服务的位置。
- 子节点 added, removed, 或 modified——用于实现镜像。(除了允许发现新文件之外,为子节点返回事件还可以监视临时文件而不影响它们的引用计数。)
- Chubby master 故障恢复——警告客户端其他事件可能已经丢失,因此必须重新检查数据。
- 句柄(及其锁)已经失效——这通常意味着通信问题。
- 锁定获取——可用于判断什么时候 Primary 被选出来了。
- 来自另一个客户端的冲突锁请求允许缓存锁。
事件是在相应的操作发生之后被交付的。因此,如果客户端被告知文件内容已经更改,那么它随后读取文件时,保证能看到新数据(或最近的数据)。
上面提到的最后两种事件很少用到,事后想来,可以忽略不计。例如,在 Primary 选举之后,客户端通常需要与新的 Primary 进行通信,而不是简单地知道 Primary 的存在;因此,它们会等待 Primary 将地址写入文件的文件修改事件。锁冲突事件在理论上允许客户端缓存其他服务器上的数据,使用 Chubby 锁来维护缓存一致性。一个冲突的锁请求将会告诉客户端结束使用与锁相关的数据:它将结束进行等待的操作、将修改刷新到原来的位置 (home location)、丢弃缓存的数据并释放锁。到目前为止,还没有人采用这种方式。
2.6 API
客户端将一个 Chubby 的句柄视为一个指向支持各种操作的不透明结构的指针。句柄仅由 Open() 创建,Close() 销毁。
Open() 打开指定的文件或目录以生成句柄,类似于 UNIX 文件描述符。只有这个调用使用节点名;其他的调用都在句柄上操作。相对于现有的目录句柄计算名称;库提供了一个始终有效的 "/" 句柄。目录句柄避免了在包含许多抽象层的多线程程序中使用程序范围内的当前目录的困难 (Directory handles avoid the difficulties of using a program-wide current directory in a multi-threaded program that contains many layers of abstraction)。
客户端显示多种选项:
- 句柄将如何使用(阅读;写作和锁定;改变 ACL );只有当客户端具有适当的权限时,才会创建句柄。
- 应该交付的事件 (参见2.5)。
- 锁延迟 (参见2.4)。
- 是否应该(或必须)创建新文件或目录。如果创建了一个文件,调用者可以提供初始内容和初始的 ACL 名称。其返回值表明这个文件实际上是否已经创建。
Close() 关闭打开的句柄。不允许进一步使用该句柄。这个调用从来没有失败过。一个相关的调用 Poison() 会导致句柄上的未完成操作和后续操作失败,而不关闭它;这允许客户端取消其他线程发出的 Chubby 调用,而不必担心释放它们访问的内存。
作用于句柄的主要调用有:
- GetContentsAndStat() 返回文件的内容和元数据。文件的内容被原子地、完整地读取。我们避免了部分读和写来阻止大文件。一个相关的调用 GetStat() 只返回元数据,而 ReadDir() 返回子目录的名称和元数据。
- SetContents() 写一个文件的内容。可选地,客户端可以提供内容生成编号(generation number),以允许客户端模拟文件上的比较和交换;只有在生成编号是当前值时,内容才被改变。文件的内容总是以原子地、完整地写入。一个相关的调用 SetACL() 在节点关联的 ACL 名称执行类似的操作。
- Delete() 删除没有子节点的节点。
- Acquire(),TryAcquire(), Release() 获取和释放锁。
- GetSequencer() 返回一个序号(参见2.4),它描述这个句柄持有的任何锁。
- SetSequalizer() 将一个序号与一个句柄相关联。如果序号不再有效,则句柄上的后续操作将失败。
- CheckSequencer() 检查序号是否有效(参见2.4)。
如果在创建句柄之后删除了节点,即使随后重新创建了文件,调用也会失败。也就是说,句柄与文件实例相关联,而不是与文件名相关联。Chubby 可能在任意的调用上使用访问控制,但总是检查 Open() 调用(参见2.3)。
除了调用本身所需的任何其他参数外,上面的所有调用都使用一个操作参数。这个操作参数保存可能与任何调用相关联的数据和控制信息。特别是通过操作参数,客户可以:
- 提供一个回调,使调用异步,
- 等待此类呼叫的完成,和/或
- 获取扩展的错误和诊断信息。
客户端可以使用此 API 执行以下 Primary 选举:所有潜在的 Primary 选举都打开锁文件并尝试获取锁。其中一个成功并成为 Primary ,而其他的作为复制品。Primary 使用 SetContents() 将其标识写入锁文件,以便客户端和副本能够找到它,这些副本使用 GetContentsAndStat() 读取文件,这可能是响应文件修改事件。理想情况下,Primary 通过 GetSequencer() 取得一个序号,然后将其传递给与之通信的服务器;它们应该用 CheckSequencer() 确认它仍然是 Primary。锁延迟可用于无法检查序号的服务。
2.7 缓存
为了减少读流量,Chubby 客户端将文件数据和节点元数据(包括文件缺失)缓存在内存中的一个一致的写缓存中。缓存由下面描述的租约机制维护,并通过 Master 发送的失效操作维护一致性,Master保存每个客户端可能缓存的数据的列表。该协议确保客户端要么看到一致的 Chubby 状态,要么看到错误。
当要更改文件数据或元数据时,修改将被阻塞,而 Master 将数据的失效通知发送给可能已缓存数据的每个客户端;这个机制位于 KeepAlive RPC 之上,下一节将对此进行更详细的讨论。在收到无效通知时,客户端刷新无效状态并通过发出下一个 KeepAlive 调用进行确认。只有在服务器知道每个客户端都将这些缓存失效之后,修改才会继续进行,这可能是因为客户端确认了失效,也可能是因为客户端允许其缓存租约过期。
只需要进行一轮失效操作,因为 Master 在缓存过期信号没有确认期间将这个节点视为不可缓存的。这种方法允许读取总是被无延迟地处理;这很有用,因为读的数量远远超过写的数量。另一种方法是在失效期间阻止访问节点的调用;这将减少过度渴望的客户端在失效期间用未完成的访问轰炸 Master 的可能性,代价是偶尔的延迟。如果这是一个问题,人们可能会想采用一种混合方案,在检测到过载时切换处理策略。
缓存协议很简单:它在更改时使缓存的数据失效,并且永远不会更新它。它只是简单的更新而不是失效,但是只更新的协议可能会无理由地低效;访问文件的客户端可能会无限期地接收更新,从而导致大量不必要的更新。
尽管提供严格一致性的开销很大,我们还是拒绝了较弱的模型,因为我们觉得程序员会发现它们更难使用。类似地,像虚拟同步 (virtual synchrony) 这种要求客户端在所有的消息中交换序号的机制,在一个有多种已经存在的通信协议的环境中也被认为是不合适的。
除了缓存数据和元数据之外,Chubby 客户端还缓存打开的句柄。因此,如果客户端打开了它之前打开的文件,那么只有第一个Open() 调用必然会导致 RPC 到达主机。这种缓存在一些次要的方面受到限制,因此它不会影响客户端观察到的语义:临时文件上的句柄在被应用程序关闭后,不能再保留在打开状态;而容许锁定的句柄则可被重用,但是不能由多个应用程序句柄并发使用。最后的这个限制是因为客户端可能利用 Close() 或者 Poison() 的边际效应:取消正在进行的向 Master 请求的 Accquire() 调用。
Chubby 的协议允许客户端缓存锁——也就是说,持有锁的时间比严格要求的长,希望它们可以被同一个客户端再次使用。如果另一个客户端请求了一个冲突锁,则事件通知锁持有者,这允许锁持有者只在别的地方需要这个锁时才释放锁。
2.8 会话和 KeepAlives
Chubby 会话是 Chubby 的单元和 Chubby 的客户端之间的一种关系;它存在一段时间,由定期的握手来维持,这种握手被称为 KeepAlive。除非 Chubby 客户端通知 Master ,否则客户端的句柄、锁和缓存的数据都是有效的,前提是它的会话仍然有效。(然而,会话维持的协议可能要求客户端确认一个缓存过期信号以维持它的会话,请看下文)。
一个客户端在第一次联系一个 Chubby 单元的 Master 时请求一个新的会话。它显式地结束会话,或者在它终止时,或者在会话处于空闲状态时(一分钟内没有打开句柄和调用)。
每个会话都有一个相关的租期——一段延伸到将来的时间,在此期间, Master 保证不会单方面终止会话。间隔的结束被称作租期到期时间(lease timeout)。 Master 可以自由地向未来延长租期到期时间,但可能不会在时间上往回移动。
在三种情形下, Master 延长租期到期时间:在创建会话时、 Master 故障恢复时(见下面)以及响应来自客户端的 KeepAlive RPC 时。在接收到 KeepAlive 时, Master 通常会阻塞这个 RPC(不允许它返回),直到客户端之前的租期接近到期。 Master 稍后允许 RPC 返回客户端,并将新的租约超时通知客户端。 Master 可以将超时时间延长任意数量。默认的延伸是 12s,但是一个过载的 Master 可能使用更高的值来减少它必须处理的 KeepAlive 调用的数量。在收到之前的回复后,客户端立即启动一个新的 KeepAlive。这样,客户端确保在 Master 上几乎总是阻塞一个 KeepAlive 调用。
除了扩展客户端的租期外,KeepAlive 的回复还用于将事件和缓存失效发送回客户端。 Master 允许一个 KeepAlive 在有事件或者缓存过期需要递送时提前返回。在 KeepAlive 应答上搭载事件可以确保客户端在不确认缓存失效的情况下无法维护会话,并导致所有 Chubby 的 RPC 从客户端流向 Master 。这样既简化了客户端,也使得协议可以通过只允许单向发起连接的防火墙。
客户端维护一个本地租约超时,这是 Master 租约超时的保守的近似值。它跟 Master 的租期过期不一样,是因为客户端必须在两方面做保守的假设。一是 KeepAlive 花在传输上的时间,一是 Master 的时钟超前的度;为了保持一致性,我们要求服务器的时钟频率相对于客户端的时钟频率,不会快于某个常数量。
如果客户端的本地租约超时过期,它将不确定 Master 是否已终止了它的会话。客户端清空并禁用其缓存,我们称它的会话处于危险之中。客户端等待一个称为宽限期的间隔,默认为 45 秒。如果客户端和 Master 在客户端的宽限期结束之前成功 KeepAlive,则客户端将再次启用其缓存。否则,客户端假定会话已经过期。这样做是为了使 Chubby API 调用不会在一个 Chubby 单元变得不可访问时无限期阻塞;如果在通讯重新建立之前宽限期结束了,调用返回一个错误。
当宽限期开始时,Chubby 库可以通过危险事件通知应用程序。当会话在通信问题中幸存下来时,安全事件告诉客户端继续;如果会话超时,则发送一个过期事件。此信息允许应用程序在不确定其会话状态时暂停自身,并在问题被证明是暂时的情况下无需重新启动即可恢复。在启动开销很高的服务中,这在避免服务不可用方面可能是很重要的。
如果客户端持有节点上的句柄 H,而 H 上的任何操作由于关联的会话过期而失败,则H上的所有后续操作 ( Close() 和 Poison() 除外 )都将以相同的方式失败。客户端可以使用它来保证网络和服务器不可用时只导致操作序列的一个后缀丢失,而不是一个任意的子序列,从而允许使用最终写入将复杂的更改标记为已提交。
2.9 故障恢复
当 Master 失败或丢失 Master 身份时,它将丢弃关于会话、句柄和锁的内存状态。会话租约的权威计时器在 Master 上运行,因此,在选出新的 Master 之前,会话租约计时器将停止;这是合法的,因为它相当于延长客户的租约。如果 Master 选举发生得很快,客户端可以在本地(近似)租约到期之前联系新 Master 。如果选举需要很长时间,客户端就会清空他们的缓存,等待宽限期(grace period),同时试图找到新的 Master 。因此,宽限期允许在超过正常租约超时的故障恢复间维护会话。
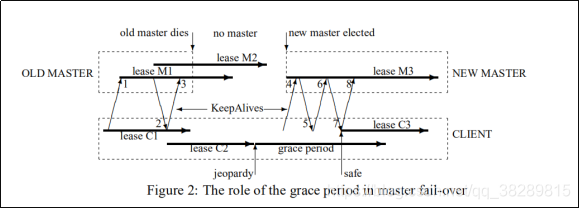
图2 显示了一个漫长的故障恢复事件中的事件序列,在这个事件中,客户端必须使用其宽限期来保存其会话。时间从左到右递增,但时间不是按比例递增的。客户端会话租约以粗箭头显示,新旧 Master (上面的M1-3)和客户端(下面的C13)都是这样看的。向上的箭头表示 KeepAlive 请求,向下的箭头表示应答。原始的 Master 为客户端提供了会话租赁M1,而客户端则有一个保守的近似C1。 Master 承诺在通过 KeepAlive reply 2通知客户前租赁 M2;客户端能够扩展其对租约 C2 的视图。原 Master 在应答下一个 KeepAlive 之前死掉了,过了一段时间后另一个 Master 被选出。最终客户端的近似租约(C2)到期。然后客户端刷新它的缓存并为宽限期启动一个计时器。
在此期间,客户端无法确定其租约在 Master 处是否已经到期。它不会破坏它的会话,但它会阻止所有应用程序对其 API 的调用,以防止应用程序观察到不一致的数据。在宽限期开始时,Chubby 库向应用程序发送一个危险事件,允许它暂停自己,直到确定其会话的状态。
最终,新的 Master 选举成功了。 Master 最初使用的是一个保守的近似 M3 的会话租约,它的前身可能已经为客户端提供了这个租约。从客户端到新 Master 的第一个 KeepAlive 请求 (4) 被拒绝,因为它的 Master 代数不正确(下面详细描述)。重试请求 (6) 成功,但通常不会进一步扩展主租约,因为 M3 是保守的。但是,应答 (7) 允许客户端再次延长其租约 (C3),并可选地通知应用程序其会话不再处于危险中。因为宽限期足够长,可以覆盖租赁 C2 结束到租赁 C3 开始的这段时间,客户端看到的只是延迟。如果宽限期小于这个间隔,客户端将放弃会话并向应用程序报告失败。
一旦客户端联系了新 Master ,客户端库和 Master 就会合作向应用程序提供没有发生故障的假象。为了实现这一点,新 Master 必须重构前一个 Master 在内存中的状态的保守近似值(conservative approximation)。这部分是通过读取磁盘上稳定存储的数据(通过普通的数据库复制协议进行复制),部分是通过从客户端获取状态,部分是通过保守的假设(conservative assumptions)实现的。数据库记录每个会话、持有的锁和临时文件。
新选出的 Master 过程如下:
1. 它首先选择一个新的代编号(epoch number),客户端需要在每次调用时显示它。 Master 拒绝使用旧的 epoch number 的客户端调用,并提供新的 epoch number。这可以确保新 Master 不会响应发送给前一个 Master 的旧包,即使是在同一台机器上运行的包。
2. 新 Master 可以响应 Master 位置请求,但不首先处理与会话相关的传入操作。
3.它为记录在数据库中的会话和锁构建内存中的数据结构。会话租期被扩展到前一个 Master 可能使用的最大限度。
4. Master 现在允许客户端执行 KeepAlives,但不允许执行其他与会话相关的操作。
5. 它向每个会话发出故障恢复事件;这将导致客户端刷新它们的缓存(因为它们可能错过了失效),并警告应用程序其他事件可能已经丢失。
6. Master 一直等待,直到每个会话确认故障恢复事件或让其会话过期。
7. Master 允许所有操作继续进行。
8. 如果客户端使用在故障恢复之前创建的句柄(根据句柄中序列号的值确定),则 Master 将在内存中重新创建句柄的表示,并执行调用。如果重新创建的句柄关闭,主句柄将把它记录在内存中,这样就不能在 Master epoch 中重新创建它;这确保延迟的或重复的网络包不会意外地重新创建一个关闭的句柄。一个有问题的客户端能在未来的时间中重建一个已关闭的句柄,但倘若该客户端已经有问题的话,则这样不会有什么危害。
9. 在一段时间之后(比如一分钟), Master 删除没有打开的文件句柄的临时文件。在故障恢复后的这段时间内,客户端应该刷新临时文件的句柄。这种机制有一个不幸的后果,如果文件上的最后一个客户端在故障恢复间丢失了会话,临时文件可能不会立即消失。
与系统的其他部分相比,故障恢复代码的执行频率要低得多,因此读者会毫不惊讶地发现,故障恢复代码是有趣 bug 的丰富来源。
2.10 数据库实现
Chubby 第一版使用带复制的 Berkeley DB 版本作为它的数据库。Berkeley DB 提供了 B-tree,它可以将字节字符串键映射到任意的字节字符串值。我们设置了一个按照路径名称中的节数排序的键比较函数,这样就允许节点用它们的路径名作为键,同时保证兄弟节点在排序顺序中相邻。因为 Chubby 不使用基于路径的权限,所以只需在数据库中进行一次查询,就可以对每个文件进行访问。
Berkeley DB 使用分布式一致性协议在一组服务器上复制其数据库日志。一旦 Master 租约被添加,这就与 Chubby 的设计相匹配,使得实现变得简单。
虽然 Berkeley DB 的 B-tree 代码使用广泛且成熟,但是复制代码是最近添加的,并且用户较少。维护者必须优先维护和改进他们的最受欢迎的产品特性。虽然 Berkeley DB 的维护者解决了我们遇到的问题,但是我们觉得使用复制代码会使我们承担更多的风险。因此,我们使用类似于 Birrell 等人的设计的提前写日志和快照来编写一个简单的数据库。与前面一样,数据库日志使用分布式一致性协议在副本之间分布。Chubby 很少使用 Berkeley DB 的特性,所以这次重写使得整个系统变得非常简单;例如,虽然我们需要原子操作,但是我们不需要通用事务。
2.11 备份
每隔几个小时,每个 Chubby 单元的 Master 就会将其数据库的快照写入不同大楼的 GFS 文件服务器。使用独立的楼宇,既可确保备份不会因楼宇损毁而损毁,又可确保备份不会对系统造成循环依赖;同一建筑物中的一个 GFS 单元可能依赖于这个 Chubby 的单元来选举它的 Master 。备份既提供了灾难恢复,也提供了一种方法来初始化新替换副本的数据库,而无需对服务中的副本施加负载。
2.12 镜像
Chubby 允许将文件集合从一个单元镜像到另一个单元。镜像非常快,因为文件很小,而且如果文件被添加、删除或修改,事件机制会立即通知镜像处理相关代码。如果没有网络问题,变化会一秒之内便在世界范围内的很多个镜像中反映出来。如果无法访问镜像,则镜像将保持不变,直到恢复连接为止。然后通过比较校验和来识别更新的文件。
镜像最常用来将配置文件复制到分布在世界各地的各种计算集群。一个名为 global 的特殊单元包含一个子树 /ls/global/master,该子树 /ls/cell/slave 被镜像到其他每个 Chubby 的单元中。global 单元是特殊的,因为它的五个副本位于世界上分布广泛的地方,所以它几乎总是可以从从大部分国家/地区访问。
从 global 单元中镜像出的文件中包括 Chubby 自己的访问控制列表、各种文件(其中 Chubby 单元和其他系统向我们的监控服务显示它们的存在)、允许客户端定位大数据集(如 Bigtable 单元)的指针以及其他系统的许多配置文件。
3 扩展机理
Chubby 的客户端是独立的进程,因此 Chubby 必须处理比预期更多的客户端;我们已经看到 9 万名客户端直接与一位 Chubby 服务器交流——远远超过所涉及的机器数量。因为每个单元只有一个 Master ,而且它的机器与客户端的机器完全相同,所以客户端可以以巨大的优势压倒 Master 。因此,最有效的扩展技术减少了与 Master 的通信。假设 Master 没有严重的性能错误,那么在 Master 上对请求处理的微小改进几乎没有什么效果。我们使用几种方法:
- 我们可以创建任意数量的 Chubby 单元;客户端几乎总是使用附近的计算单元(在 DNS 中找到)来避免依赖于远程机器。我们的典型部署是使用一个 Chubby 单元作为数千台机器的数据中心。
- Master 在高负载的情况下,可以将租赁时间从默认的 12 秒增加到 60 秒左右,因此它需要处理更少的 KeepAlive RPC。( KeepAlives 是目前占主导地位的请求类型(见4.1),未能及时处理它们是服务器超载的典型故障模式;客户端在很大程度上对其他调用的延迟变化不敏感。)
- Chubby 客户端缓存文件数据、元数据、缺失文件和打开句柄,以减少它们在服务器上的调用数量。
- 我们使用协议转换服务器,将 Chubby 协议转换成不太复杂的协议,如 DNS 和其他协议。我们将在下面讨论其中的一些。
在这里,我们描述了两种常见的机制,代理(proxies)和分区(partitioning),我们期望这两种机制将允许 Chubby 进一步扩展。我们还没有在生产中使用它们,但它们已经设计出来了,可能很快就会使用。我们目前没有必要考虑将规模扩大到原来的 5 倍以上:首先,希望放入数据中心或依赖于单个服务实例的机器数量是有限制的。其次,因为我们对 Chubby 客户端和服务器使用类似的机器,所以增加每台机器的客户端数量的硬件改进也会增加每台服务器的容量。
3.1 代理
可以通过可信的进程代理 Chubby 的协议(在两边使用相同的协议),这些进程将来自其他客户端的请求传递给一个 Chubby 单元。代理可以通过处理 KeepAlive 和 read 请求来减少服务器负载;它不能减少通过代理缓存的写流量。但即使有积极的客户端缓存,写入流量仍远小于 Chubby 正常负载的 1%,因此代理允许客户端数量的显著增加。如果一个代理处理 Nproxy 个客户端,那么 KeepAlive 流量将减少 Nproxy 倍,而 Nproxy 可能是一万甚至更大。代理缓存最多可以减少平均读取共享量的读取流量(大约是10倍)。但由于目前的阅读量占了 Chubby 负载的 10% 以下,所以 KeepAlive 流量上的节省仍然是到目前为止更重要的成效。
代理将一个额外的 RPC 添加到写操作和第一次读操作中。可以预期,代理将使计算单元暂时不可用的频率至少是以前的两倍,因为每个代理客户端都依赖于两台可能失效的机器:它的代理和 Chubby 的 Master 。
提醒读者注意,2.9节中描述的故障恢复策略对于代理来说并不理想。我们将在第4.4节中讨论这个问题。
3.2 分区
如第 2.3 节所述,选择了 Chubby 的接口,以便可以在服务器之间对计算单元的名称空间进行分区。虽然我们还不需要它,但代码可以按目录对名称空间进行分区。如果启用,一个 Chubby 的单元将由 N 个分区组成,每个分区有一组副本和一个 Master 。目录 D 中的每个节点 D/C 将存储在分区 P(D/C) = hash(D) mod N 上。注意,D 的元数据可能存储在不同的分区 P(D) = hash(D0) mod N 上,其中 D0 是 D 的父节点。
分区的目的是在分区之间几乎没有通信的情况下启用很大的 Chubby 单元集(Chubby cells)。虽然 Chubby 没有硬链接、目录修改时间和跨目录重命名操作,但仍有一些操作需要跨分区通信:
- ACL 本身就是文件,因此一个分区可以使用另一个分区进行权限检查。但是,ACL 文件很容易被缓存;只有 Open() 和 Delete() 调用需要 ACL 检查;大多数客户端读取不需要 ACL 的公共可访问文件。
- 当一个目录被删除时,可能需要一个跨分区调用来确保该目录是空的。
因为每个分区都独立于其他分区处理大多数调用,所以我们希望这种通信对性能或可用性的影响不大。
除非分区的数量 N 很大,否则每个客户端应该会联系大多数分区。因此,分区将任何给定分区上的读写流量减少了 N 倍,但不一定会减少 KeepAlive 流量。如果 Chubby 需要处理更多的客户端,那么我们的策略涉及代理和分区的组合。
4 实际应用,意外和设计错误
4.1 实际应用和表现
下表给出了一个 Chubby cell 的快照统计数据;RPC 频率在 10 分钟内可见。这些数字在 Google 的 Chubby 单元中是很常见的。
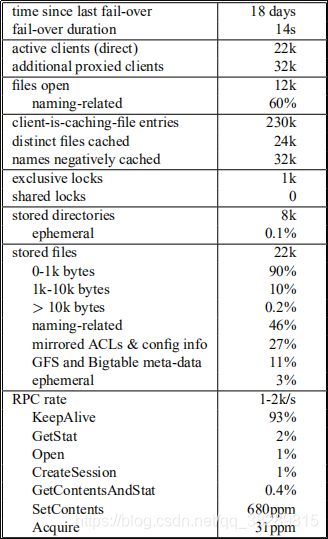
可以看到以下几点:
- 许多文件用于命名;看到 4.3。
- 配置、访问控制和元数据文件(类似于文件系统的超级块)是常见的。
- 负面缓存非常重要。
- 平均 230k/24k≈10 个客户端使用每个缓存文件。
- 很少有客户端持有锁,共享锁也很少见;这与锁用于 Primary 选举和在副本之间分区数据是一致的。
- RPC 流量由会话 KeepAlives 控制;有一些读取(即缓存丢失);很少有写或锁获取。
现在,我们简要地描述一下单元中停机的典型原因。如果我们假设(乐观地)一个单元是 "向上" 的,如果它有一个 Master 愿意服务,在我们的单元样本上,我们记录了在几周内 61 次停机,总计 700 个 cell-days 的数据。我们排除了由于维护而导致数据中心关闭的停机。其他原因包括:网络拥塞、维护、过载和由于操作员、软件和硬件引起的错误。大多数故障是 15 次或更少,52 次是 30 秒内;我们的大部分应用程序不会被 Chubby 的 30 秒内的不可用显著地影响到。其余 9 次宕机是由网络维护(4)、可疑的网络连接问题(2)、软件错误(2)和过载(1)引起的。
在好几次 Chubby 单元年(cell-years)的运行中,我们有六次丢失了数据,由数据库软件错误(4)和运营人员错误(2)引起;不涉及硬件错误。具有讽刺意味的是,操作错误与为避免软件错误的升级有关。我们有两次纠正了由非 Master 的副本的软件引起的损坏。
Chubby 的数据适合在内存中,所以大多数操作的代价都很低。无论计算单元负载如何,我们的生产服务器上的平均请求延迟始终保持在1毫秒以内,直到计算单元接近过载,此时延迟显著增加,会话被丢弃。过载通常发生在许多会话(> 90、000)是活跃的时候,但是也能由异常条件引起:当客户端们同时地发起几百万读请求时(在 4.3 节有描述),或者当客户端库的一个错误禁用了某些读的缓存,导致每秒成千上万的请求。因为大多数 RPC 都是 KeepAlives,所以服务器可以通过增加会话租期来维持许多客户端较低的平均请求延迟。当出现大量写操作时,组提交(Group commit)会减少每个请求(单独提交)所做的工作,但这种情况很少见。
在客户端测量的 RPC 读延迟受 RPC 系统和网络的限制;它们对于一个本地 Chubby 单元来说小于 1ms,但跨洲则需要 250ms。由于数据库日志更新,写操作(包括锁操作)将进一步延迟 5-10 ms,但是如果最近失效的客户端缓存了该文件,则延迟最多数十秒。这种写延迟的变化对服务器上的平均请求延迟影响很小,因为写的频率非常低。
如果会话没有被丢弃,客户端对延迟变化相当不敏感。在某一点上,我们在 Open() 中添加了人为的延迟来抑制滥用的客户端(参见4.5);开发人员只注意到延迟超过 10 秒并被重复应用。我们发现,扩展 Chubby 的关键不是服务器性能;减少与服务器的通信可能会产生更大的影响。在优化读/写服务器代码路径方面没有付出重大努力;我们检查了没有异常的 bug 存在,然后关注于更有效的扩展机制。在另一方面,如果一个性能缺陷影响到客户端会每秒读几千次的本地 Chubby 缓存,开发者肯定会注意到。
4.2 Java 客户端
Google 的基础架构主要是用 C++ 编写的,但是越来越多的系统是用 Java 编写的。这种趋势给 Chubby 带来了一个意想不到的问题,因为它有一个复杂的客户端协议和一个重要的客户端库。Java 鼓励整个应用程序的可移植性,但却牺牲了增量采用的代价,因为它使得与其他语言的链接有些麻烦。通常用于访问非原生(non-native)的库的 Java 机制是 JNI,但是它被认为是缓慢而笨拙的。我们的 Java 程序员非常不喜欢 JNI,为了避免使用它,他们宁愿将大型库转换成 Java,并维护它们。
Chubby 的 C++ 客户端库有 7000 行(与服务器相当),客户端协议非常复杂。在 Java 中维护这个库需要细心和代价,而没有缓存的实现会增加 Chubby 服务器的负担。因此,我们的 Java 用户运行协议转换服务器的副本,该服务器导出一个简单的 RPC 协议,该协议与 Chubby 的客户端 API 紧密对应。即使事后来看,我们也不清楚如何才能避免编写、运行和维护这个额外服务器的成本。
4.3 用作名称服务
尽管 Chubby 被设计为一个锁服务,但我们发现它最流行的用法是作为名称服务器。
在常规的 Internet 命名系统(DNS)中,缓存是基于时间的。DNS 条目有生存时间(TTL),如果在此期间没有刷新 DNS 数据,则将丢弃这些数据。通常,选择一个合适的 TTL 值是很简单的,但是如果需要立即替换失败的服务,TTL 会变得很小,以至于使 DNS 服务器超载。
例如,我们的开发人员经常运行涉及数千个进程的任务,并且每个进程之间相互通信,这导致了二次级的 DNS 查询。我们可能希望使用 60 秒的 TTL;这将允许行为不端的客户端被替换,而不会有过多的延迟,并且在我们的环境中不会被认为是一个不合理的短替换时间。在这种情况下,要维护单个任务的 DNS 缓存(最小为3000个客户端),需要每秒 15 万个查询(相比之下,一个2-CPU 2.6GHz 的 Xeon DNS 服务器每秒可以处理 5 万个请求)。更大的任务产生更恶劣的问题,并且多个任务可能同时执行。在引入 Chubby 之前,我们的 DNS 负载的波动性是 Google 面临的一个严重问题。
相比之下,Chubby 的缓存使用显示地失效(invalidations),因此恒定速率的会话 KeepAlive 请求可以在没有更改的情况下在客户端上无限期地维护任意数量的缓存条目。一个2-CPU 2.6GHz 的 Xeon Chubby Master 可以处理与它直接通信的9万个客户端(没有代理);这些客户端包括了具有上文描述过的那种通讯模式的庞大任务。在不逐个轮询每个名称的情况下提供快速名称更新的功能非常有吸引力,以至于现在 Google 的大部分系统都由 Chubby 提供名字服务。
尽管 Chubby 的缓存允许一个单独的单元能承受大量的客户端,但负载峰值仍然是一个问题。当我们第一次部署基于 Chubby 的名称服务时,启动一个 3000 个进程任务(从而产生 900 万个请求)可能会让 Chubby Master 崩溃。为了解决这个问题,我们选择将名称条目分组成批,这样一次查询就可以返回并缓存作业中大量相关进程(通常为100个)的名称映射。
Chubby 提供的缓存语义要比名字服务需要的缓存语义更加精确;名称解析只需要及时通知,而不需要完全一致。因而,这里有一个时机,可以通过引入特别地为名字查找设计的简单协议转换服务器,来降低 Chubby 的负载。假如我们预见到将 Chubby 用作名字服务的用法,我们可能选择实现完整的代理,而不是提供这种简单但没有必要的额外的服务器。
还有一个协议转换服务器:Chubby 的 DNS 服务器。这使得存储在 Chubby 中的命名数据对 DNS 客户端可用。这种服务器很重要,它既能减少了 DNS 名字到 Chubby 名字之间的转换,也能适应已经存在的不能轻易转换的应用程序,例如浏览器。
4.4 故障恢复问题
Master 故障恢复的原始设计要求 Master 在创建新会话时向数据库写入新会话。在 Berkeley DB 版本的锁服务器中,当多个进程同时启动时,创建会话的开销就成为了一个问题。为了避免过载,服务器被修改为在数据库中存储会话,而不是在第一次创建会话时存储,而是在尝试第一次修改、锁获取或打开临时文件时存储。此外,活动会话被记录在数据库中,每个 KeepAlive 都有一定的概率。因此,只读会话的写操作在时间上是分散的。
虽然有必要避免过载,但这种优化有一个不好的结果,即比较新的只读会话可能不会记录在数据库中,因此在发生故障恢复时可能会被丢弃。虽然这样的会话不持有锁,但这是不安全的;如果所有记录的会话都要在被丢弃会话的租约到期之前与新主会话检入(check in),那么被丢弃的会话可以在一段时间内读取过时的数据。这在实践中很少见;在大型系统中,几乎可以肯定的是某些会话将无法检入,从而迫使新 Master 等待最大的租约时间。然而,我们修改了故障恢复设计,以避免这种影响,并避免当前方案引入代理的复杂性。
在新的设计中,我们完全避免在数据库中记录会话,而是使用与 Master 当前重新创建句柄相同的方式重新创建它们。现在,新 Master 必须等待一个最坏情况下的租约超时,才能允许操作继续进行,因为它无法知道是否所有会话都已检入。同样,这在实践中几乎没有效果,因为可能不是所有会话都将检入。
一旦可以在没有磁盘状态的情况下重新创建会话,代理服务器就可以管理 Master 不知道的会话。仅对代理可用的额外操作允许它们更改与锁关联的会话。这允许一个代理在代理失败时从另一个代理接管客户端。 Master 所需要的惟一必要的更改是保证不放弃与代理会话关联的锁或者临时文件句柄,直到一个新的代理有机会获得它们。
4.5 滥用的客户端
Google 的项目团队可以自由地设置他们自己的 Chubby 单元,但是这样做会增加他们的维护负担,并消耗额外的硬件资源。因此,许多服务使用共享的 Chubby 单元,这使得将客户端与其他人的不当行为隔离开来非常重要。Chubby 打算在一家公司内运行,因此针对它的恶意拒绝服务攻击很少见。然而,开发人员的错误、误解和不同的期望会导致类似于攻击的效果。
我们的一些补救措施是严厉的。例如,我们检查项目团队计划使用 Chubby 的方式,并在检查满意之前拒绝访问共享的 Chubby 名称空间。这种方法的一个问题是,开发人员常常无法预测他们的服务在未来将如何使用,以及使用将如何增长。读者会注意到,我们自己也未能预测到 Chubby 会被如何利用,这是多么讽刺。
我们审查的最重要方面是确定 Chubby 的资源(RPC速率、磁盘空间、文件数量)的使用是否随用户数量或项目处理的数据量线性增长(或更糟)。任何线性增长都必须通过一个可调整的补偿参数来缓解,以将 Chubby 的负载降低到合理的范围。然而,我们早期的审查不够彻底。
一个相关的问题是大部分软件文档中缺少性能建议。一个团队编写的模块可能在一年后被另一个团队重用,从而导致灾难性的结果。有时很难向接口设计人员解释,他们必须更改接口并不是因为接口不好,而是因为其他开发人员可能不太了解 RPC 的成本。
下面我们列出一些我们遇到的问题。最初缺少可应付冲击的缓存(aggressive caching) ,我们没有意识到缓存缺少文件的关键需求,也没有意识到重用打开的文件句柄。尽管尝试过培训,但我们的开发人员经常编写循环,当文件不存在时无限重试,或者通过打开文件并在可能只打开文件一次的时候反复关闭它来轮询文件。
最初,我们对付这些重试循环的方法是,在某个应用程序短时间内做了许多 Open() 同一个文件的尝试时,引入指数级递增的延时。在某些情况下,这暴露了开发人员承认的缺陷,但通常这需要我们花费更多的时间在培训上。最后,很容易使重复性的 Open() 调用所花费的代价没有那么大。
Chubby 从未打算用作存储大量数据的系统,因此它没有存储配额。事后看来,这是缺乏经验的。Google 的一个项目编写了一个模块来跟踪数据上传,在 Chubby 中存储一些元数据。这样的上传很少发生,而且仅限于一小部分人,所以空间是有限的。但是,其他两个服务开始使用相同的模块来跟踪来自更广泛用户群的上传。不可避免的是,这些服务不断增长,直到 Chubby 的使用达到极限:在每个用户操作中,一个1.5 mb的文件被全部重写,服务使用的总体空间超过了所有其他 Chubby 客户端的空间需求的总和。
我们引入了文件大小限制(256kBytes),并鼓励服务迁移到更合适的存储系统。但是,要对忙碌的人们维护的生产系统进行重大的更改是很困难的——大约花了一年的时间才将数据迁移到其他地方。
发布/订阅 曾有数次将 Chubby 的事件机制作为 Zephyr 式的发布/订阅系统的尝试。Chubby 的重量级保证,以及它在维护缓存一致性时使用无效而不是更新的方法,使得它对于除了无意义的发布/订阅示例之外的所有示例来说都非常缓慢和低效。幸运的是,在重新设计应用程序的成本太大之前,所有这些用途都被捕获。
4.6 经验教训
在这里,我们列出了经验教训,以及如果有机会,我们可能会做的各种设计更改:
开发者极少考虑可用性。 我们发现开发者极少考虑失败的可能性,并倾向于认为像 Chubby 这样的服务好像总是可用的。例如,我们的开发人员曾经构建了一个系统,该系统使用了数百台机器,在 Chubby 选出新 Master 时,启动恢复过程需要几十分钟。这将单个故障的后果在时间和受影响的机器数量上都放大了 100 倍。我们希望开发人员为短时间的中断做好计划,以便这样的事件对他们的应用程序影响很小或没有影响。这是第 2.1 节讨论的粗粒度锁的参数之一。
开发人员也没有意识到服务启动与应用程序可用之间的区别。例如,global Chubby 单元几乎总是处于上升状态,因为同时处于下降状态的数据中心很少超过两个。但是,对于给定的客户端,其观察到的可用性通常低于客户端的局部 Chubby 单元的观察到的可用性。首先,本地单元不太可能与客户端分区,其次,虽然本地单元可能经常由于维护而停机,但是相同的维护直接影响客户端,所以客户端不会观察到 Chubby 的不可用性。
我们的 API 选择也会影响开发人员处理 Chubby 停机的方式。例如,Chubby 提供了一个事件,允许客户端检测 Master 故障恢复何时发生。目的是让客户端检查可能的更改,因为其他事件可能已经丢失。不幸的是,许多开发人员选择在收到这个事件时关闭他们的应用程序,从而大大降低了系统的可用性。我们可以更好地发送冗余的"文件更改"事件,甚至确保在故障恢复间没有丢失事件。
目前,我们使用三种机制来防止开发人员对 Chubby 的可用性过于乐观,特别是global cell的可用性。首先,正如前面提到的,我们审查了项目团队计划如何使用 Chubby ,并建议他们不要使用那些将其可用性与 Chubby 紧密联系在一起的技术。
其次,我们现在提供执行一些高级任务的库,这样开发人员就可以自动地从中断中隔离出来。第三,我们使用每次 Chubby 停机的事后分析作为一种方法,不仅可以消除 Chubby 和我们的操作过程中的 bug,而且还可以降低应用程序对 Chubby 可用性的敏感性——这两种方法都可以提高系统的整体可用性。
可以忽略细粒度锁定的内容在 2.1 节的末尾,我们概述了一个服务器的设计,客户端可以运行该服务器来提供细粒度锁定。到目前为止,我们还不需要编写这样的服务器,这可能令人感到惊讶;我们的开发人员通常发现,为了优化他们的应用程序,他们必须删除不必要的通信,这通常意味着找到一种使用粗粒度锁定的方法。
糟糕的 API 选择通常会带来意想不到的影响,我们的 API 发展得很好,但有一个错误很明显。我们取消长时间运行的调用的方法是 Close() 和 Poison() RPC,它们也会丢弃句柄的服务器状态。这可以防止获取锁的句柄被共享,例如被多个线程共享。我们可以添加一个 Cancel() RPC 来允许更多地共享打开的句柄。
RPC的使用影响传输协议KeepAlives被用于刷新客户端的会话租约,也用于将事件和缓存失效从 Master 传递给客户端。这个设计有自动的符合预期的效应:一个客户端不能在没有应答缓存过期的情况下刷新会话状态。
这似乎很理想,除了这样会在传输协议的选择中引入紧张情形以外。TCP 的拥塞时回退(back off)策略不关心更高层的超时,例如 Chubby 的租期,因此基于 TCP 的 KeepAlive 在发生高网络拥塞时导致许多丢失的会话。我们被迫通过 UDP 而不是 TCP 发送 KeepAlive RPC;UDP 没有拥塞避免机制,因此我们只有当高层的时间界限必须满足时才使用 UDP 协议。
我们可以使用一个附加的基于 TCP 的 GetEvent() RPC 来扩展协议,它将用于在正常情况下通信事件和失效,使用的方式与 KeepAlives 相同。KeepAlive 回复仍然包含未确认事件的列表,因而事件最终都将被应答。
5 与相关工作的比较
Chubby 是基于成熟的理念之上的。Chubby 的缓存设计源于对分布式文件系统的研究。它的会话和缓存标记的行为与 Echo 中的类似;会话减少了系统中租约的开销。在 VMS 中发现了锁服务的思想,尽管该系统最初使用了允许低延迟交互的专用高速互连的互联网络。与它缓存模型一样,Chubby 的 API 也基于文件系统模型,其中包括这样一个思想,即类似文件系统的名称空间可方便地存放文件。
Chubby 与 Echo 或 AFS 等分布式文件系统在性能和存储方面有所不同:客户端不会读取、写入或存储大量数据,除非数据被缓存,否则它们不会期望高吞吐量甚至低延迟。他们确实期望一致性、可用性和可靠性,但是当性能不那么重要时,这些属性更容易实现。因为 Chubby 的数据库很小,我们可以在线存储它的许多副本(通常是五个副本和少数备份)。我们每天进行多次完全备份,通过数据库状态的校验和,我们每隔几个小时就相互比较副本。正常的文件系统性能和存储需求的弱化使我们能够用一个 Chubby Master 为成千上万的客户端提供服务。我们通过提供一个中心点,许多客户端在这个中心点共享信息和协同活动,解决了一类我们的系统开发人员面对的问题。
各种文献描述了大量的文件系统和锁服务器,所以不可能做一个彻底的比较。所以我们提供细节:我们选择与 Boxwood 的锁服务器比较,因为它是最近设计的,它也旨在在松耦合的环境中运行,但其设计在很多方面不同于Chubby,一些设计是有趣的,一些设计是因为系统的差异所决定的。
Chubby 在单个服务中实现锁、可靠的小文件存储系统以及会话/租赁机制。相反,Boxwood 将它们分为三个:锁服务、Paxos 服务(状态的可靠存储库)和故障检测服务。Boxwood 系统本身使用这三个组件,但另一个系统可以独立使用这些构件。我们怀疑这种设计上的差异源于目标受众的不同。Chubby 的目标受众和应用程序是多样化的;它的用户范围从创建新分布式系统的专家到编写管理脚本的新手。对于我们的环境,使用熟悉的 API 的大型共享服务似乎很有吸引力。相比之下,Boxwood 提供了一个工具包(至少在我们看来是这样),它适用于少数更成熟的开发人员,他们从事的项目可能共享代码,但不需要一起使用。
在许多情况下,Chubby 提供了比 Boxwood 更高级别的接口。例如,Chubby 组合了锁和文件名空间,而 Boxwood 的锁名称是简单的字节序列。Chubby 客户端默认缓存文件状态;Boxwood 的 Paxos 服务的客户端可以通过锁服务实现缓存,但是很可能会使用 Boxwood 本身提供的缓存。
这两个系统有明显不同的默认参数,为不同的期望而选择:每个客户端每 200 毫秒与每个 Boxwood 故障检测器联系一次,超时为1; Chubby 的默认租赁时间是 12 秒,每隔 7 秒交换一次 KeepAlives。Boxwood 的子组件使用两个或三个副本来实现可用性,而我们通常每个单元使用五个副本。然而,这些选择本身并没有表明深层次的设计差异,而是指出了这些系统中的参数必须如何调整以适应更多的客户端机器,或者机架与其他项目共享的不确定性。
一个更有趣的区别是引入了 Chubby 的宽限期,这是 Boxwood 所缺乏的。(回忆一下,宽限期允许客户在长时间的 Master 宕机期间不丢失会话或锁。Boxwood 的 "宽限期" 相当于 Chubby 的 "会话租赁",是一个不同的概念。)同样,这种差异是由于对两个系统的规模和失败概率的期望不同造成的。虽然 Master 故障恢复很少见,但是丢失的 Chubby 锁对客户来说代价是很昂贵的。
最后,这两个系统中的锁用于不同的目的。Chubby 的锁重量更重,需要记序器来保证外部资源的安全,而 Boxwood 锁重量更轻,主要用于 Boxwood 内部。
6 总结
Chubby 是一个分布式锁服务,用于 Google 的分布式系统中粗粒度的活动同步;它被广泛用作名称服务和配置信息存储库。
它的设计基于一些已经很好地融合在一起的、众所周知的思想:在几个副本之间为容错进行分布式协商,一致的客户端缓存以减少服务器负载,同时保留简单的语义,及时的更新通知,以及一个熟悉的文件系统接口。我们使用缓存、协议转换服务器和简单的负载调整,使它可以扩展到每个 Chubby 实例的数万个客户端进程。我们希望通过代理和分区进一步扩展它。
Chubby 已经成为 Google 的主要内部名称服务;它是 MapReduce 等系统常用的对接机制( rendezvous mechanism);存储系统 GFS 和 Bigtable 使用 Chubby 从冗余副本中选择一个 Master ;它是一个标准的存储库,用于存储需要高可用性的文件,比如访问控制列表。
7 感谢
许多人对 Chubby 系统做出了贡献:Sharon Perl 在 Berkeley DB 上编写了复制层;Tushar Chandra 和 Robert Griesemer 编写了替代 Berkeley DB 的复制数据库;Ramsey Haddad 将 API 连接到 Google 的文件系统接口;Dave Presotto、Sean Owen、Doug Zongker 和 Praveen Tamara 分别编写了 Chubby 的 DNS、Java 和命名协议转换器,以及完整的 Chubby 的代理;Vadim Furman 增加了打开处理和文件缺失的缓存;Rob Pike、Sean Quinlan 和 Sanjay Ghemawat给出了宝贵的设计建议;许多 Google 开发人员发现了早期的缺陷。

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









