







专栏目录:
Dubbo基础: https://blog.csdn.net/qq_38310244/article/details/125891802
Dubbo实战: https://blog.csdn.net/qq_38310244/article/details/125892120
手写一套简单的dubbo(含注册中心)之编程思想: https://blog.csdn.net/qq_38310244/article/details/125892641
手写一套简单的dubbo(含注册中心)之核心代码: https://blog.csdn.net/qq_38310244/article/details/125892849
Dubbo:阿里巴巴公司开源的一个高性能RPC 分布式服务框架
理论原理
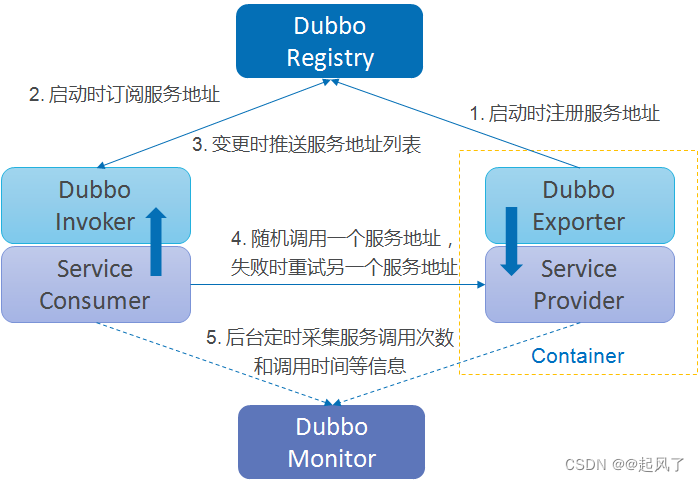
主体架构
名词解释
| 节点 | 说明 |
|---|---|
| Provider | 暴露服务的服务提供方 |
| Consumer | 调用远程服务的服务消费方 |
| Registry | 服务注册与发现的注册中心 |
| Monitor | 统计服务的调用次数和调用时间的监控中心 |
总体概述
- Provider服务提供者启动之后,通过配置信息,将自己的服务在Registry进行注册
- Consumer服务消费者启动之后,也是通过配置信息,订阅Registry中的服务者接口
- Consumer服务消费者在Registry注册之后,Registry返回服务者接口地址列表,Consumer消费者将这份地址列表保存到自己的本地
- 当Consumer调用Provider的服务时,就通过本地的地址列表找到对应的接口代理对象,通过层层处理,使用netty将请求发送给Provider,Provider处理后返回结果
- Monitor用于监控Consumer和Provider的活动情况
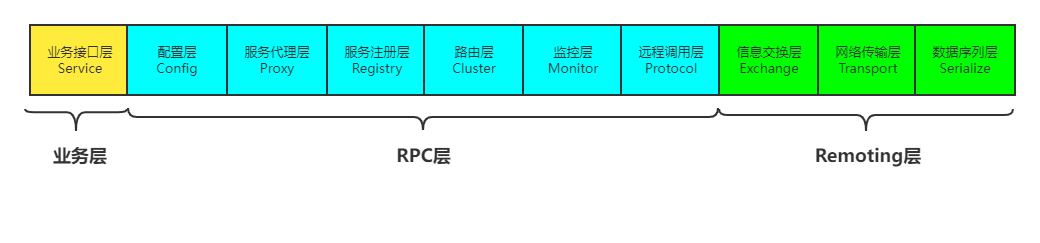
主体分层
| 主类 | 层级 | 解释 |
|---|---|---|
| 业务层 | Service 接口服务层 | 业务代码 |
| RPC层 | Config 配置层 | 初始化的配置信息,管理dubbo的配置 |
| RPC层 | Proxy 服务代理层 | 服务接口透明代理,provider和consumer都通过ProxyFactory会生成Proxy,它用来调用远程接口 |
| RPC层 | Registry 服务注册层 | 封装服务地址、端口的注册和发现 |
| RPC层 | Cluster 路由层 | 封装多个服务提供者的路由和负载均衡,并桥接注册中心 |
| RPC层 | Monitor 监控层 | PRC调用次数和调用时间监控 |
| RPC层 | Protocol 远程调用层 | 封装RPC调用的具体过程 |
| Remoting层 | Exchange 信息交换层 | 封装请求响应模式(根据通信协议),同步转异步 |
| Remoting层 | Transport 网络传输层 | 将网络传输封装成统一接口,可以在这之上扩展更多的网络传输方式 |
| Remoting层 | Serialize 数据序列化层 | 负责网络传输的序列化和反序列化 |
核心配置
| 配置 | 配置说明 |
|---|---|
| dubbo:service | 服务配置 |
| dubbo:reference | 引用配置 |
| dubbo:protocol | 协议配置 |
| dubbo:application | 应用配置 |
| dubbo:module | 模块配置 |
| dubbo:registry | 注册中心配置 |
| dubbo:monitor | 监控中心配置 |
| dubbo:provider | 提供方配置 |
| dubbo:consumer | 消费方配置 |
| dubbo:method | 方法配置 |
| dubbo:argument | 参数配置 |
dubbo:provider可配置属性:
| 属性 | 说明 |
|---|---|
| timeout | 方法调用超时 |
| retries | 失败重试次数,默认重试 2 次 |
| loadbalance | 负载均衡算法,默认随机 |
| actives | 消费者端,最大并发调用限制 |
dubbo集群容错方案
| 集群容错方案 | 说明 |
|---|---|
| Failover Cluster | 失败自动切换,自动重试其他服务器(默认) |
| Failfast Cluster | 快速失败,立即报错,只发起一次调用 |
| Failsafe Cluster | 失败安全,出现异常时,直接忽略 |
| Failback Cluster | 失败自动恢复,记录失败请求,定时重发 |
| Forking Cluster | 并行调用多个服务器,只要一个成功即返回 |
| Broadcast Cluster | 广播逐个调用所有提供者,任意一个报错则报错 |
dubbo负载均衡策略
| 负载均衡策略 | 说明 |
|---|---|
| Random LoadBalance | 随机,按权重设置随机概率(默认) |
| RoundRobin LoadBalance | 轮询,按公约后的权重设置轮询比率 |
| LeastActive LoadBalance | 最少活跃调用数,相同活跃数的随机 |
| ConsistentHash LoadBalaclava | 一致性Hash,相同参数的请求总是发到同一提供者 |
核心原理
服务调用流程
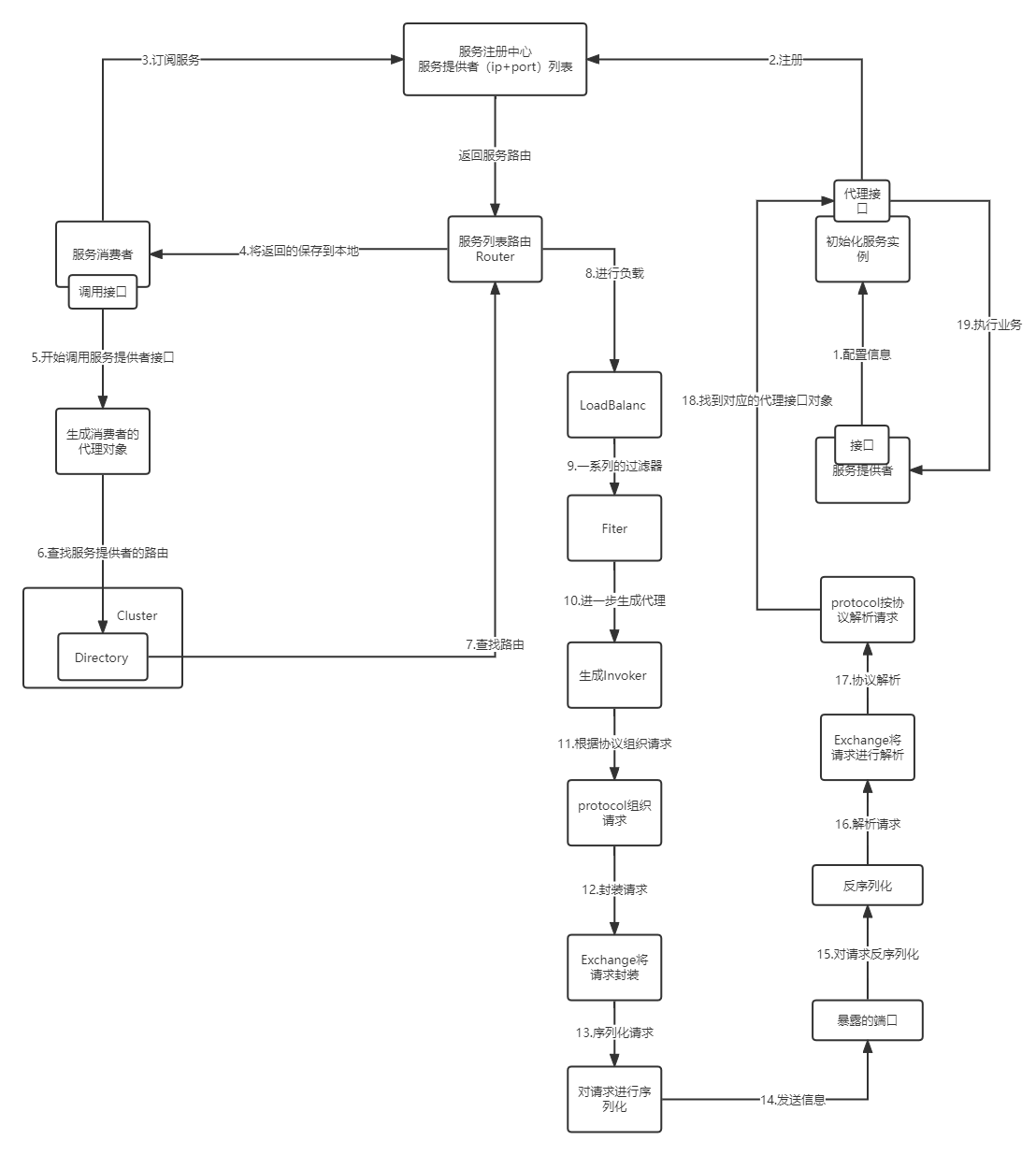
- 服务提供者在启动的时候,会根据配置信息将服务实例化
- 将服务端的接口根据 Protocol 定义协议格式封装成Proxy,方便调用者调用
- 再将Proxy封装成Invoker,这个才是调用者真实调用的用例
- Invoker再包装成Exporter,包装成Exporter是为了在注册中心中暴露自己,方便调用者调用
- 将Exporter注册到注册中心
- 服务消费者也是根据配置信息将服务初始化
- 消费者根据配置信息到注册中心订阅服务,注册中心将服务的ip和端口以及调用方式返回给消费者,消费者将这些路由列表保存到本地
- 在消费者发起调用时,会先通过Cluster里的Directory 获取所有 Invoker 列表之后,会调用路由接口(Router),其会根据用户配置的不同策略对 Invoker 列表进行过滤,只返回符合规则的 Invoker
- 获取到Invoker后会先经过LoadBalanc 进行负载(dubbo集群)
- 确定负载的节点之后,就开始经过一些列的过滤器进行过滤
- 过滤完毕确定需要发送的数据后,通过protocol定义的协议组装请求
- 请求组装完毕后,通过Exchange对请求进行封装
- 序列化Exchange请求
- 通过netty,将请求发送给服务端暴露出来的端口
- 服务端的netty接受到请求信息后,将请求信息进行反序列化
- 服务端的Exchange对请求进行解析
- 服务端的protocol解析Exchange得到需要调用调用的代理接口
- protocol将请求数据传给代理接口,代理接口通过实际的接口实现业务
提供者原理
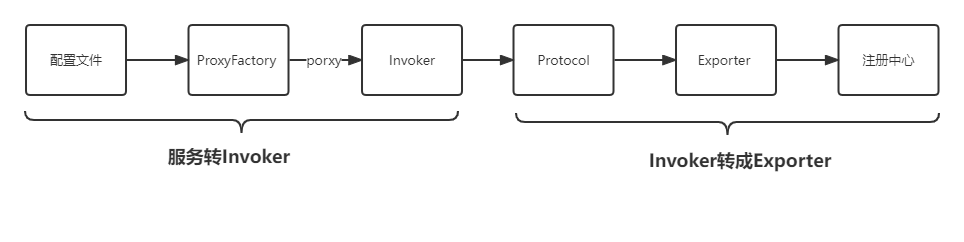
其实就是将服务接口转成Invoker方便消费者调用,而将Invoker转为Exporter则是为了注册中心管理
消费者原理
消费者启动时会去注册中心订阅服务信息,注册中心会返回服务信息,消费者将这些服务信息保存到本地。当发生远程接口调用的时候,就去查找服务信息,将远程服务转为代理对象进行调用。如果是同一个 JVM 的引用,直接使用 injvm 协议从内存中获取实例。
SPI
SPI (Service Provider Interface),主要是用来在框架中使用的,可以让不同的厂商针对统一接口编写不同的实现。SPI实际上是“接口+策略模式+配置文件”实现的动态加载机制。在系统设计中,模块之间通常基于接口编程,不直接显示指定实现类。一旦代码里指定了实现类,就无法在不修改代码的情况下替换为另一种实现。为了达到动态可插拔的效果,java提供了SPI以实现服务发现。
最常见和莫过于我们在访问数据库时候用到的java.sql.Driver接口了。在Spring中的pringFactoriesLoader这个类,它也是一种SPI机制。
java SPI
在 Classpath 下的 META-INF/services/ 目录里创建一个以服务接口命名的文件,然后文件里面记录的是此 jar 包提供的具体实现类的全限定名,文件的编码格式是 UTF-8。通过java.util.ServiceLoader 的加载机制来发现
有点类似于饿汉式的加载方式,会把文件里所有的实现类全部加载出来
缺点: JDK 标准的 SPI 会一次性加载实例化扩展点的所有实现。如果有的扩展点实现初始化很耗时或者如果有些实现类并没有用到, 那么会很浪费资源。
Dubbo SPI
Dubbo SPI 的相关逻辑被封装在了 ExtensionLoader 类中,通过 ExtensionLoader,我们可以加载指定的实现类
Dubbo是通过键值对的方式进行配置,我们可以直接通过Key获取我们想要加载的实体类。Dubbo默认的配置文件路径是在./resources/META-INF/dubbo下。其中的key则是beanName
dubbo SPI 的加载方式类似于懒汉式加载方式,即按需根据key加载需要的实现类
在消费者订阅注册中心里服务端生成的代理接口时进行加载
通信方式
dubbo service 标签有 protocol这个属性,在多协议时使用,多个协议ID用逗号分隔。
- dubbo(默认)
- 连接个数:单连接
- 连接方式:长连接
- 传输协议:TCP
- 传输方式:NIO异步传输
- 序列化:Hessian 二进制序列化(默认是 hessian)
- 使用场景:适合于小数据量大并发的服务调用,以及服务消费者机器数远大于服务提供者机器数的情况
- 缺点:不适合传送大数据量的服务,比如传文件,传视频等,除非请求量很低
- RMI
- 连接个数:多连接
- 连接方式:短连接
- 传输协议:TCP
- 传输方式:同步传输
- 序列化:Java标准二进制序列化(默认是java)
- 使用场景:传入传出参数数据包大小混合,消费者与提供者个数差不多,可传文件
- 缺点:存在反序列化安全风险
- **Hessian **
- 连接个数:多连接
- 连接方式:短连接
- 传输协议:HTTP
- 传输方式:同步传输
- 序列化:Hessian二进制序列化
- 使用场景:传入传出参数数据包大小混合,消费者与提供者个数差不多,可传文件
- 缺点:
- 参数及返回值需实现Serializable接口
- 参数及返回值不能自定义实现List, Map, Number, Date, Calendar等接口,只能用JDK自带的实现,因为hessian会做特殊处理,自定义实现类中的属性值都会丢失
- http
- 连接个数:多连接
- 连接方式:短连接
- 传输协议:HTTP
- 传输方式:同步传输
- 序列化:json
- 使用场景:需同时给应用程序和浏览器JS使用的服务
- 缺点:不支持传文件
- WebService
- 连接个数:多连接
- 连接方式:短连接
- 传输协议:HTTP
- 传输方式:同步传输
- 序列化:SOAP文本序列化
- 使用场景:系统集成,跨语言调用
- 缺点:
- 参数及返回值需实现Serializable接口
- 参数尽量使用基本类型和POJO
注册中心
dubbo的注册中心主要有 ZooKeeper,Redis,Simple 和 Multicast这四种
工作原理
1.当服务提供者启动时,将自己的IP地址/端口号/服务数据一起注册到注册中心中
2.当注册中心接收提供者的数据信息之后,会维护服务列表数据
3.当消费者启动时,会连接注册中心
4.获取服务列表数据.之后在本地保存记录
5.当用户需要业务操作时,消费者会根据服务列表数据,之后找到正确的IP:PORT直接利用RPC机制进行远程访问
6.注册中心都有心跳检测机制.当发现服务器宕机/或者新增服务时.则会在第一时间更新自己的服务列表数据,并且全网广播通知所有的消费者
ZooKeeper
它通过树形文件存储的 ZNode 在 /dubbo/Service 目录下面建立了四个目录,分别是:
- Providers 目录下面,存放服务提供者 URL 和元数据。
- Consumers 目录下面,存放消费者的 URL 和元数据。
- Routers 目录下面,存放消费者的路由策略。
- Configurators 目录下面,存放多个用于服务提供者动态配置 URL 元数据信息。
客户端第一次连接注册中心的时候,会获取全量的服务元数据,包括服务提供者和服务消费者以及路由和配置的信息。
根据 ZooKeeper 客户端的特性,会在对应 ZNode 的目录上注册一个 Watcher,同时让客户端和注册中心保持 TCP 长连接。
如果服务的元数据信息发生变化,客户端会接受到变更通知,然后去注册中心更新元数据信息。变更时根据 ZNode 节点中版本变化进行。
下一篇:Dubbo代码实战














 1889
1889











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









