







本文作者:苏奕嘉
公众号:Apache Doris 补习班
引言
如标题所述,本篇主要从架构设计角度来阐述一下,Doris 在中小型数据体量(总数据 100TB 内,热数据 30TB 内)的场景中,如何设计一站式的低成本高性能的离在线一体化实时数据仓库。
首先不是造词,只是通过命名的方式来阐述清楚这种设计方案和思路的主要特征,本篇将尽可能的从架构角度、开发角度、使用角度以及运维角度来充分阐述清楚该方案的利弊点,让各位看官老爷可以感受到到有价值的参考意义。
本篇我将从道(设计思路)和术(具体案例)两方面来进行阐述,分享一些自己的认知和看法。
设计思路
要解决问题,第一要义是先清楚认知到具体问题是什么。
探寻问题本身
一体化数仓,或者叫轻量级数仓,主要解决的问题痛点有以下几点:
- 运维复杂度:组件过多,运维成本高,兼容性问题大,往往开发或者升级会牵一发而动全身
- 数据冗余度:一份数据多份存储,而且可能还割裂成孤岛没法统一使用
- 数据时效性:对低可见性要求的业务场景,组件多就可能意味着整体数据流转变长,时效性就不太能有可靠保证
- 开发复杂度:以 Lambda 架构为例,若使用离线修正实时方案,那很可能一套业务要开发两套代码,工作量妥妥 Double,但从业务角度看,开发同学做的事情是事倍功半的,因为他只觉得他拿到了一份数据……
- 故障恢复率:组件多、链路长,已发布的任务出现异常,或者组件异常导致的数据行为异常,往往需要全链路排查来确定问题,定位修复以后重新流转一遍的速度往往无法让业务方满意(像大部分离线数仓得数小时级别来修复和恢复)
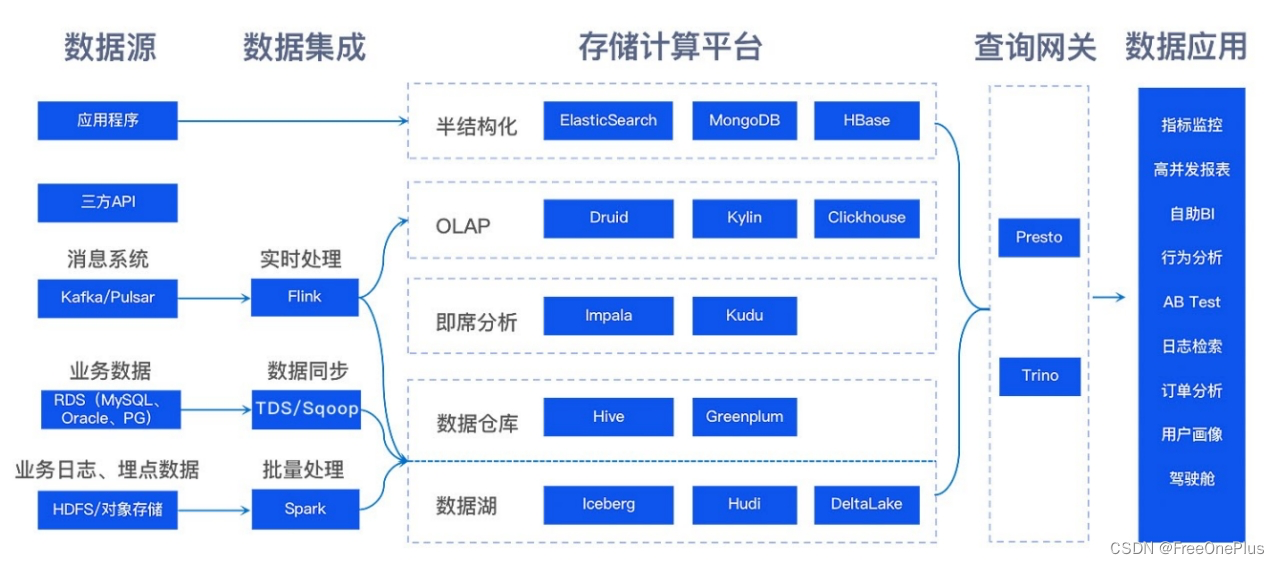
其他点还有,但是主要的问题本身就这五个方面,所以回头来看本身的诉求是什么,就显得清晰易见:
希望有一个组件,既可以完成实时计算,又可以参与离线计算,数据只存储一份,计算时实时业务和离线业务不能互相影响,计算速度要快,同时还要极简运维,最好大部分运维工作都交由自己来完成。
寻找解决方案
既然明确了诉求,那我们进一步将诉求点拆解转化为技术语言,就可以更直观的从组件特性层面判断目标组件是否满足了我们的诉求。
- 具备高可用和高可靠能力,可分布式部署,单点故障不会引起整体服务不可用
- 具备多租户和资源组隔离能力,硬限必须要有,软限尽可能有,同时使用起来不能太麻烦,最好能支持自动升降级资源组的能力
- 具备数据实时导入能力,能接入的数据源要广,上游生态要好,最好尽可能一肩挑不使用其他组件就可以完成导入
- 具备结构化和半结构化的数据处理能力,半结构化数据要能支持倒排索引检索能力,如果能具备非结构化的数据存储最好不过,进一步若能解析非结构化数据那就是遥遥领先的存在了
- 具备数据实时处理能力,应有实时或者近实时手段完成加速计算,时延越低越好,为了能流式计算,最好能支持 Binlog 解析能力
- 具备数据批式处理能力,尤其是在 TB 级,应有比较好的 CBO 优化器等灵魂 Feature,可以跑几千行的复杂 SQL 而不出现异常,同时跑的速度要比 Hive 和 Spark 要快,就算不快最起码得持平
- 具备高并发的查询能力,常规的 AdHoc、BI 看板、驾驶舱等数据核心应用场景的 QPS 要一定能保证,同时最好满足对外 API 的点查诉求,因为会有用户画像等场景需要高并发点查
- 具备极简的运维能力,如组件本身的自愈能力:数据的重分布、坏数据分片的调度修复等能力,组件部署和运维的生态工具要完善
- 如果是商业化产品,公司技术实力和公司可持续服务能力要强,如果是社区开源产品,社区要活跃,要能保证 BUG 的迭代修复和新功能的开发,最好有诸多大厂参与,保证社区的持续发展能力
那么 Doris 是否能解决以上分析的九大问题点,胜任离在线一体化实时数据仓库一岗呢?
评测组件能力
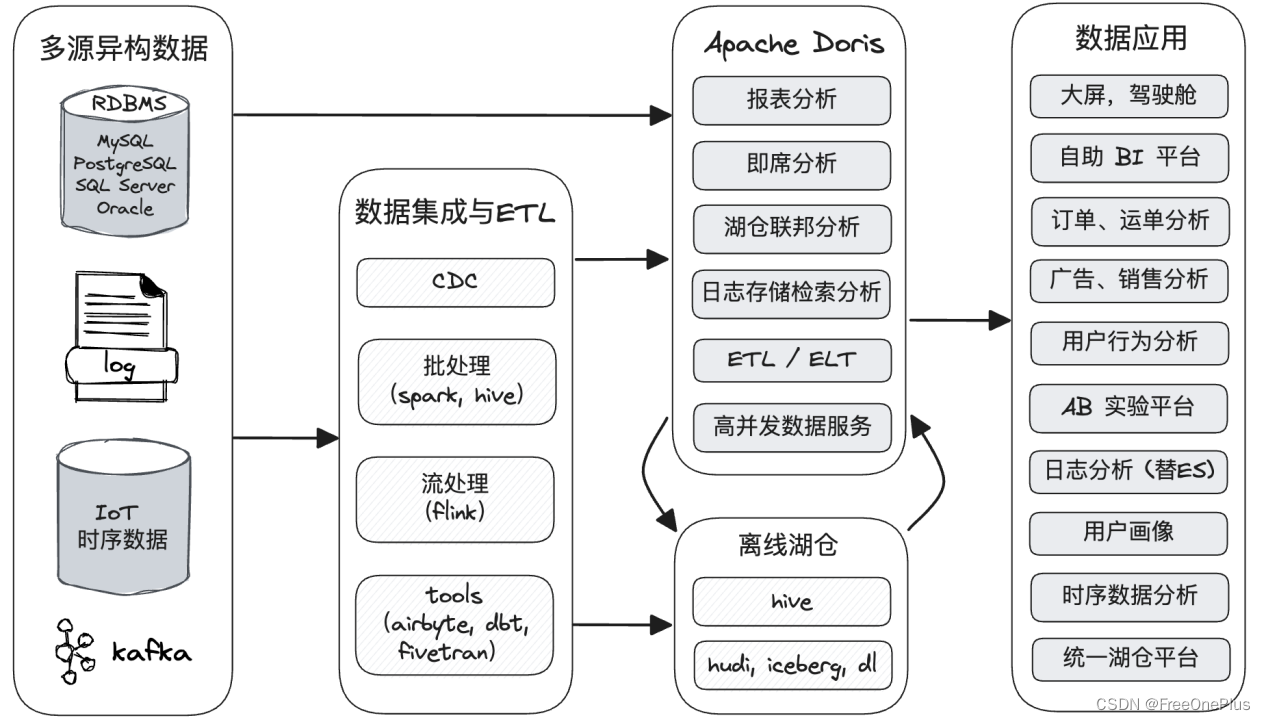
-
高可靠和高可用能力

Doris 主要进程有两个:FE 和 BE。
FE 负责查询解析和元数据存储,BE 负责数据存储和物理执行计划执行,为保证高可靠和高可用,那就得保证最少两处的高可用:查询高可用和存储高可用。
在 Doris 的架构设计中,FE 和 BE 都可以通过多节点部署来完成高可用配置,同时在存储端还具备节点间存储负载均衡和磁盘间负载均
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 2341
2341

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











