







文章目录
问题来源
在JUC下的ReentrantLock,针对线程的加锁操作。使用lock.lock()。
但在其源码中,却存在一个很可疑的代码逻辑,如下图所示:
final void lock() {
acquire(1);
}
public final void acquire(int arg) {
if (!tryAcquire(arg) &&
acquireQueued(addWaiter(Node.EXCLUSIVE), arg))
selfInterrupt();
}
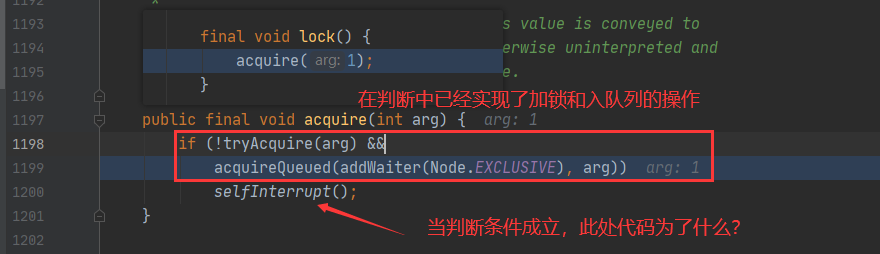
源码中,对于selfInterrupt()的执行逻辑如下所示:
static void selfInterrupt() {
Thread.currentThread().interrupt();
}
这里的处理只是一个线程的中断。
每个线程都会进入该
ReentrantLock.java类中。这里的Thread.currentThread()表示进入的线程。
关于线程唤醒
在JUC下的ReentrantLock源码中,关于线程的唤醒操作通常有以下几种方式。
unlock()方法中的release(int arg),底层采取LockSupport.unpark(xx)进行唤醒。- 线程中断。
中断唤醒演示
接下来重点说明这两种方式的区别。
LockSupport.unpark 唤醒阻塞线程
【案例1:】使用 LockSupport.unpark(thread) 进行线程唤醒:
package aqs;
import lombok.extern.slf4j.Slf4j;
import java.util.Date;
import java.util.concurrent.TimeUnit;
import java.util.concurrent.locks.LockSupport;
@Slf4j
public class LockSupportPark1 {
public static void main(String[] args) throws InterruptedException {
Thread thread = new Thread(() -> {
Thread current = Thread.currentThread();
log.info("{},开始执行....时间:{}",current.getName(),new Date().getTime());
// 死循环
for (;;){
log.info("准备park住当前线程....{}....时间:{}",current.getName(),new Date().getTime());
LockSupport.park();
log.info("当前线程...{} 已经被唤醒....时间:{}",current.getName(),new Date().getTime());
}
},"t1");
thread.start();
// 延迟2s,保证上面的线程可以执行
TimeUnit.SECONDS.sleep(2);
log.info("准备唤醒{}线程",thread.getName());
LockSupport.unpark(thread);
}
}
代码运行后,控制台的日志打印信息为:
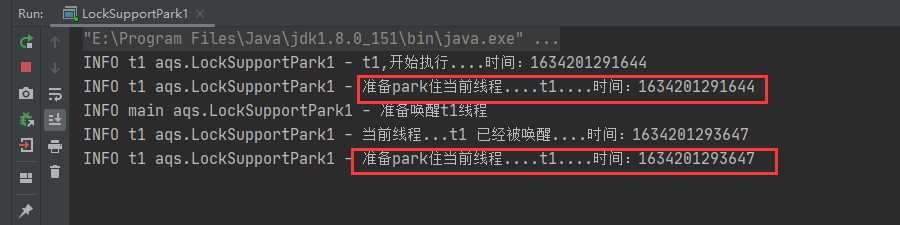
【发现:】
使用
LockSupport.unpark(thread)对已阻塞的线程进行唤醒操作,当唤醒之后,上面的死循环依旧可以将其继续park阻塞!
中断唤醒阻塞线程
【疑问:】如果这里的唤醒操作采取中断进行呢,此时的效果又将变成什么样子?
【案例2:】使用 线程中断,将阻塞的线程唤醒:
修改唤醒部分的代码,将其
LockSupport.unpark(thread)更换为线程中断。
特别注意:这里阻塞操作使用的是
LockSupport.park();
package aqs;
import lombok.extern.slf4j.Slf4j;
import java.util.Date;
import java.util.concurrent.TimeUnit;
import java.util.concurrent.locks.LockSupport;
@Slf4j
public class LockSupportPark1 {
public static void main(String[] args) throws InterruptedException {
Thread thread = new Thread(() -> {
Thread current = Thread.currentThread();
log.info("{},开始执行....时间:{}",current.getName(),new Date().getTime());
// 死循环
for (;;){
log.info("准备park住当前线程....{}....时间:{}",current.getName(),new Date().getTime());
LockSupport.park();
log.info("当前线程...{} 已经被唤醒....时间:{}",current.getName(),new Date().getTime());
}
},"t1");
thread.start();
// 延迟2s,保证上面的线程可以执行
TimeUnit.SECONDS.sleep(2);
log.info("准备唤醒{}线程",thread.getName());
// 使用 LockSupport.unpark(thread) 唤醒阻塞的线程
// LockSupport.unpark(thread);
// 使用线程中断,唤醒指定的线程
thread.interrupt(); // 中断信号
}
}
代码执行后,其效果如下所示:
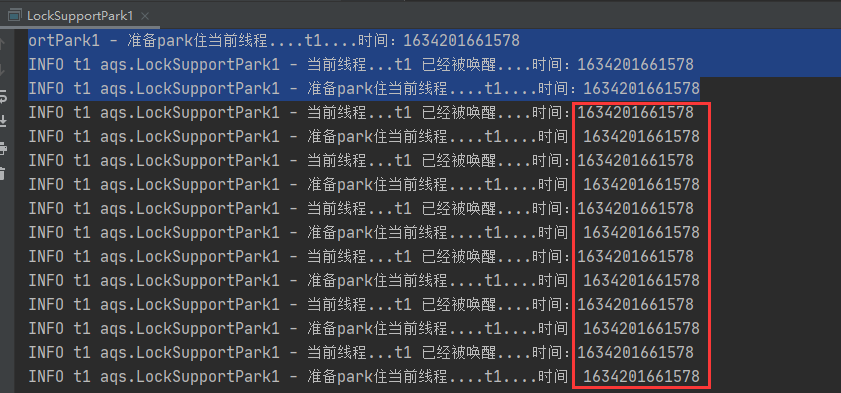
【发现:】
当执行了
thread.interrupt(),将指定的线程进行中断操作后,此时在死循环中,LockSupport.park()并不会继续保证线程被阻塞!
即:使用了 thread.interrupt()之后,LockSupport.park()将会失效!
参考资料: java线程的中断机制
但在ReentrantLock源码中,将线程进行阻塞操作,使用到的却是parkAndCheckInterrupt()。
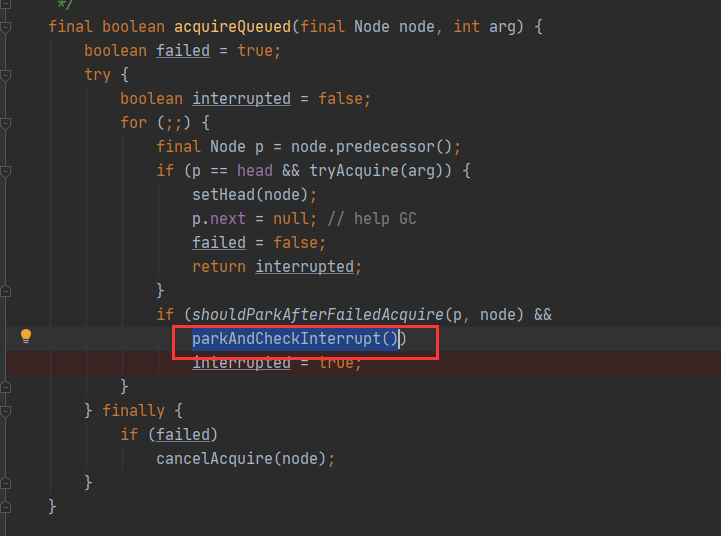
也就是下列的操作:
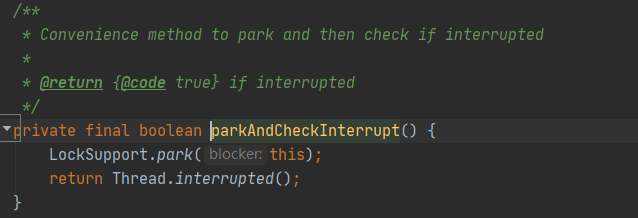
在LockSupport的源码中,关于使用park()让线程阻塞,存在两种操作方式。
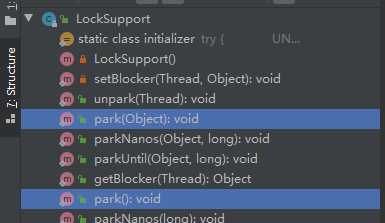
一种是有参,一种是无参。这两种方式都能将一个线程进行阻塞!
上面的测试采取unpark()和中断操作,唤醒阻塞的线程,发现:
中断会让Locksupport.park() 阻塞失效!
如果使用LockSupport.park(xxxx)来进行阻塞,再使用中断唤醒,此时的效果又该如何?
由于
LockSupport.park(Object blocker)传递的是一个bloker。无法直接进行测试。
故,此处采取ReentrantLock 进行断点调试。

package aqs;
import lombok.extern.slf4j.Slf4j;
import java.util.ArrayList;
import java.util.List;
import java.util.concurrent.TimeUnit;
import java.util.concurrent.locks.ReentrantLock;
@Slf4j
public class LockSupportPark2 {
static boolean flag = false;
static ReentrantLock lock = new ReentrantLock(true);
public static void main(String[] args) {
List<Thread> list = new ArrayList<>();
for (int i = 0; i < 10; i++) {
Thread thread = new Thread(() -> {
lock.lock();
log.info("{} get lock",Thread.currentThread().getName());
while (!flag){
if(flag){
break;
}
}
lock.unlock();
},"t-"+i);
// 添加到集合中
list.add(thread);
// 启动线程
thread.start();
}
// 主线程
try {
TimeUnit.SECONDS.sleep(2);
// 随机获取一个线程,将其中断
// 模拟AQS源码中的 selfInterrupt() 操作
list.get(5).interrupt();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
将断点打在以下两处:
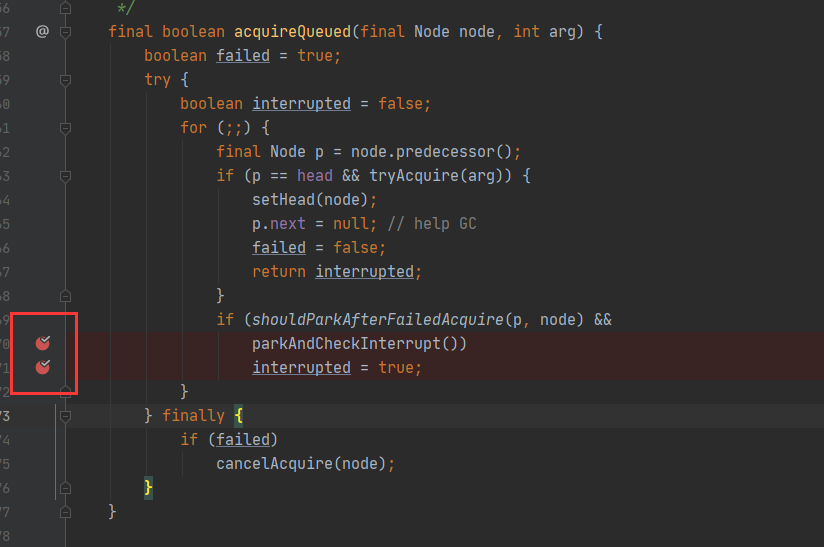
分别测试无中断和有中断两种情况下,代码的执行情况。
-
无中断时:
如上面的测试代码,将list.get(5).interrupt() 进行注释,采取debug运行。

当代码执行后,发现其中的线程停留在parkAndCheckInterrupt()上,即阻塞。查看parkAndCheckInterrupt()发现程序停留于LockSupport.park(this)上。 -
有中断时:
释放上面的注释,取消parkAndCheckInterrupt()前的断点:
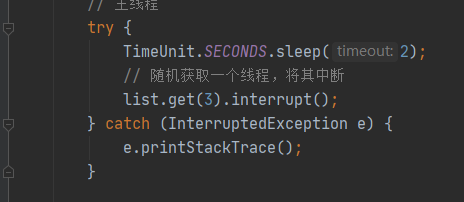
重新debug执行代码,此时效果分别如下所示:
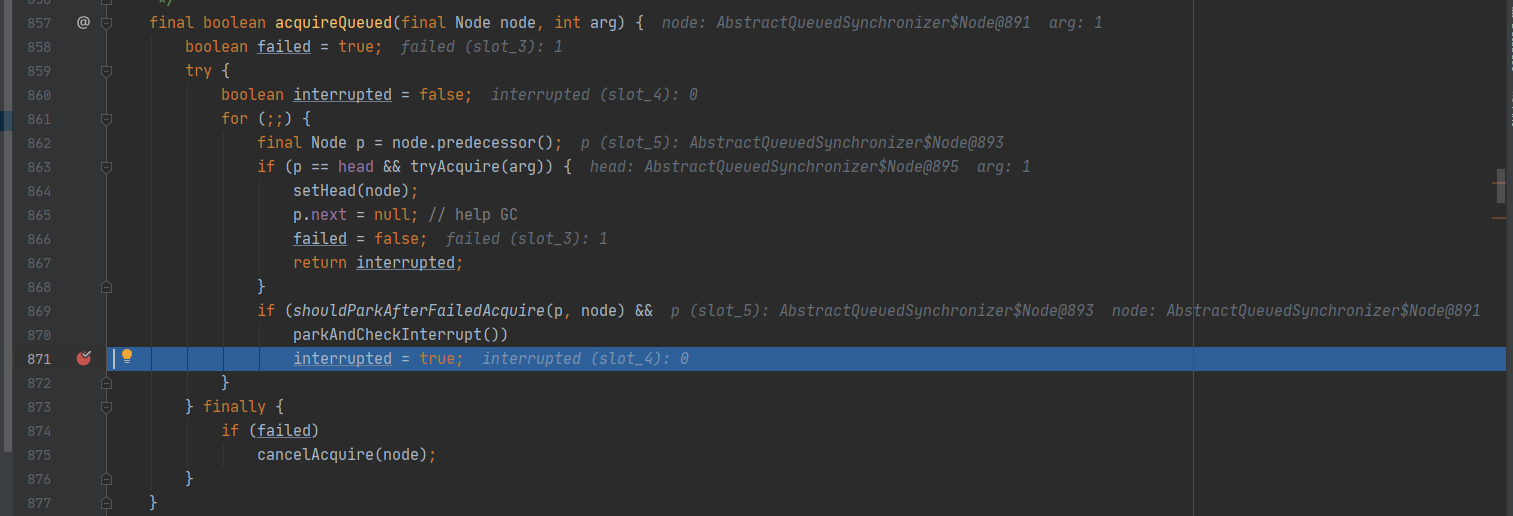
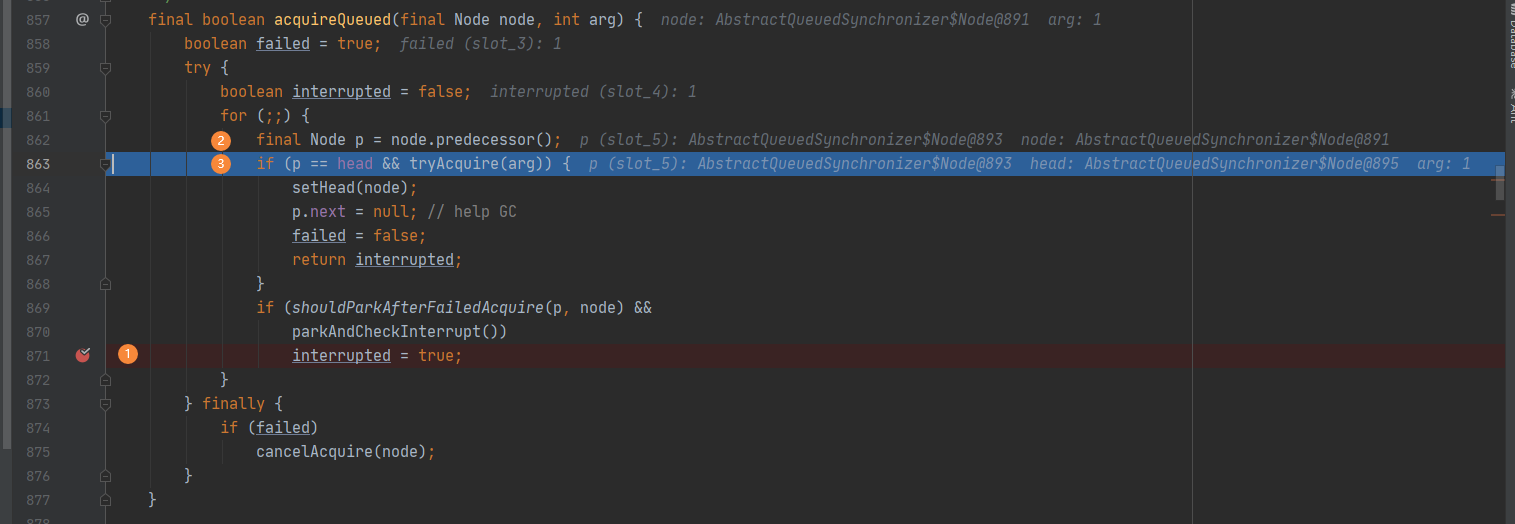
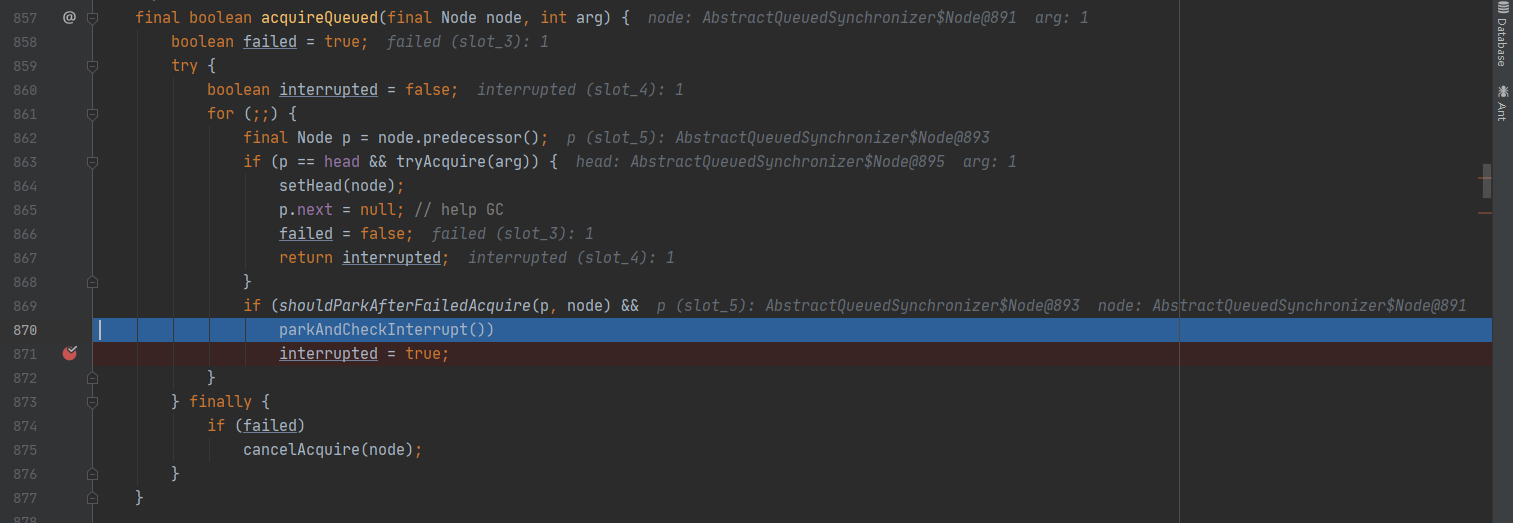
发现会在循环中重新执行一次 parkAndCheckInterrupt(),将当前线程进行阻塞。
为什么会有 selfInterrupt() 操作?
初步看ReentrantLock的lock()源码和使用debug看其执行的顺序,感觉其并无什么作用。但此处却是大有玄机!
AQS是JUC下加锁操作的一个
公共类。不仅仅适用于ReentrantLock这一个类的处理。
比如:
在
java.util.concurrent.locks.ReentrantLock#lockInterruptibly()中针对中断就有相应的处理操作。
使用 lockInterruptibly()
之前测试加锁操作,使用的是lock(),这里将之前的案例替换为lockInterruptibly()。其测试代码如下所示:
ReentrantLock lock = new ReentrantLock(true);
try {
lock.lockInterruptibly();
} catch (InterruptedException e) {
e.printStackTrace();
}
其底层源码大部分和lock()一致,只是针对中断操作有一定的区别。
在lock()操作中,如果存在中断操作引起的线程唤醒现象,则会重新进行一次parkAndCheckInterrupt()阻塞操作。
但在lock.lockInterruptibly()中却是以抛出异常的方式。
其代码上的区别如下所示:
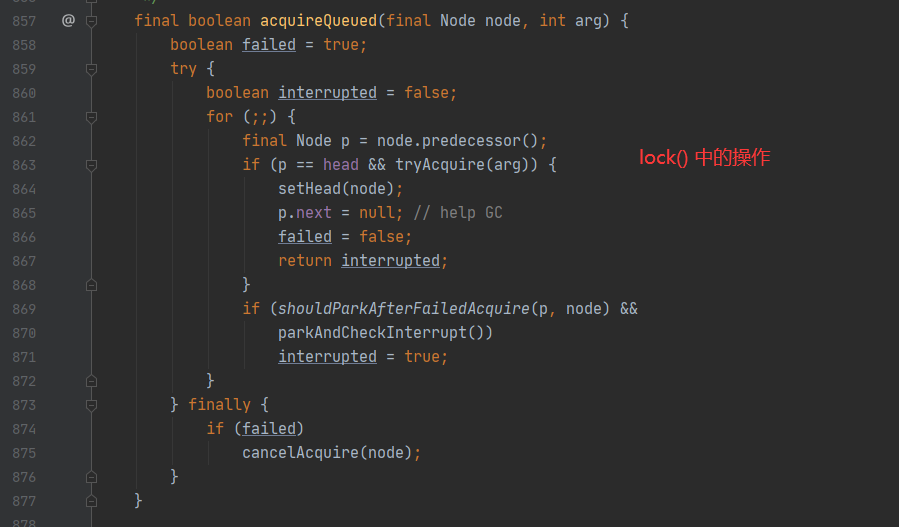
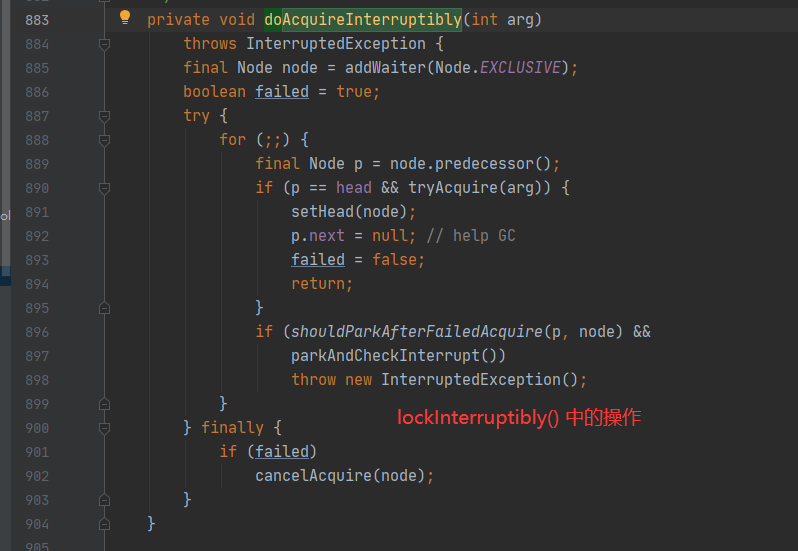
其主要源码分析如下所示:
public final void acquireInterruptibly(int arg)
throws InterruptedException {
// 如果线程中断状态,则直接抛出异常
if (Thread.interrupted())
throw new InterruptedException();
// 尝试获取锁失败,则执行 doAcquireInterruptibly(arg)
if (!tryAcquire(arg))
doAcquireInterruptibly(arg);
}
private void doAcquireInterruptibly(int arg)
throws InterruptedException {
final Node node = addWaiter(Node.EXCLUSIVE);
boolean failed = true;
try {
for (;;) {
final Node p = node.predecessor();
// 由于队首是一个空Node,
// 如果判断当前node的上一个Node是队首,则将当前的node尝试获取锁
if (p == head && tryAcquire(arg)) {
setHead(node);
p.next = null; // help GC
failed = false;
return;
}
// 当前node不是队首的下一节点,或者尝试获取锁失败,则进行入队操作
if (shouldParkAfterFailedAcquire(p, node) &&
parkAndCheckInterrupt()) // 正常入队列并阻塞后,代码会阻塞在此处
// 如果存在,因为“中断”引起“阻塞线程唤醒”问题,则抛出异常
// 抛出异常,交给程序员开发的代码块中进行捕获处理
throw new InterruptedException();
}
} finally {
// 抛出异常之前执行,或者该段代码销毁前执行
// 默认的 failed 为true
// 如果逻辑和环境都正常,就会将failed置为false
// 并不会进行 cancelAcquire(node) 操作
// 当出现因为“中断”引起“阻塞线程唤醒”问题时,执行下列逻辑
if (failed)
cancelAcquire(node);
}
}
核心源码:
// 只有当出现因“中断”引起“阻塞线程”被唤醒,才会进入当前方法
private void cancelAcquire(Node node) {
// 判断当前node对象是否存在
if (node == null)
return;
// 如果node存在
// 则将其中指向的 线程引用置空-----方便将无效的thread变为垃圾对象
node.thread = null;
// 获取当前node节点的上一个node
Node pred = node.prev;
// 如果上一个节点的 waitStatus 也是大于0
while (pred.waitStatus > 0)
// 则继续获取上面的node节点,直到找到node节点的waitStatus不是大于0的
// 并每次都将上一个的node的prev指向的node,赋值给当前node的prev属性上(参考下图理解)
// 这里的pred局部属性,时刻都在变化
node.prev = pred = pred.prev;
// 获取 waitStatus 不是大于0的那个node的next对象属性
Node predNext = pred.next;
// 将当前node的 waitStatus 置为 cancelled (1) 代表出现异常,中断引起的,需要废弃结束
node.waitStatus = Node.CANCELLED;
if (node == tail && compareAndSetTail(node, pred)) {
// 如果当前的node节点是CLH队列的 队尾,
// 则将 根据遍历获取到的上面的正常的node节点的next节点 设置为null(断开正常和废弃node之间的节点)
compareAndSetNext(pred, predNext, null); // 因为是从队尾开始找的,所以可以直接设置null
} else {
// 不是队尾(队首或者队列中)
int ws;
// 判断递归获取到的正常的node节点是否是队首
if (pred != head &&
((ws = pred.waitStatus) == Node.SIGNAL ||
(ws <= 0 && compareAndSetWaitStatus(pred, ws, Node.SIGNAL))) &&
pred.thread != null) {
// 存在于队列中部
// 获取异常node的下一个node节点
Node next = node.next;
// 如果下一个节点正常,则将这个正常的节点,设置到上面找到的正常node1的next节点上
if (next != null && next.waitStatus <= 0)
compareAndSetNext(pred, predNext, next);
} else {
// 如果正常的node节点是队首(也就是这个node是队列老二),则进行 下列操作
unparkSuccessor(node);
}
node.next = node; // help GC
}
}
// 当当前的异常node为队首node时,执行
private void unparkSuccessor(Node node) {
// 队首的node中记录的waitStatus,是下一个node的健康状态
int ws = node.waitStatus;
if (ws < 0)
// 交给阻塞操作重新修改 waitStatus 参数值
compareAndSetWaitStatus(node, ws, 0);
// 获取队首下一个node节点(队首是一个空Node)
Node s = node.next;
if (s == null || s.waitStatus > 0) {
s = null;
// 从队尾开始检索
for (Node t = tail; t != null && t != node; t = t.prev)
if (t.waitStatus <= 0)
// 从队尾找node,满足waitStatus生命值正常的node节点
// 从后往前找,找到最后个正常的node
s = t;
}
// 如果存在健康的node节点,则唤醒
if (s != null)
LockSupport.unpark(s.thread);
}
原理图分析
正常情况下的队列
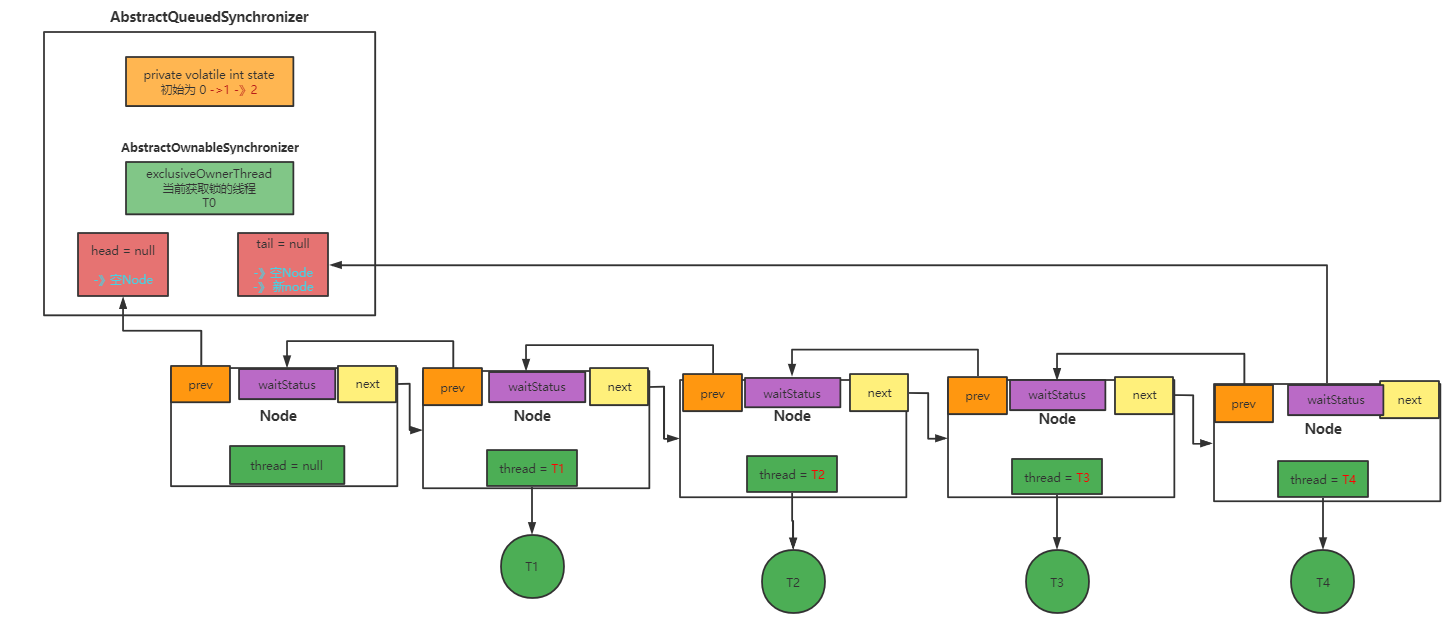
假设T2和T3出现中断
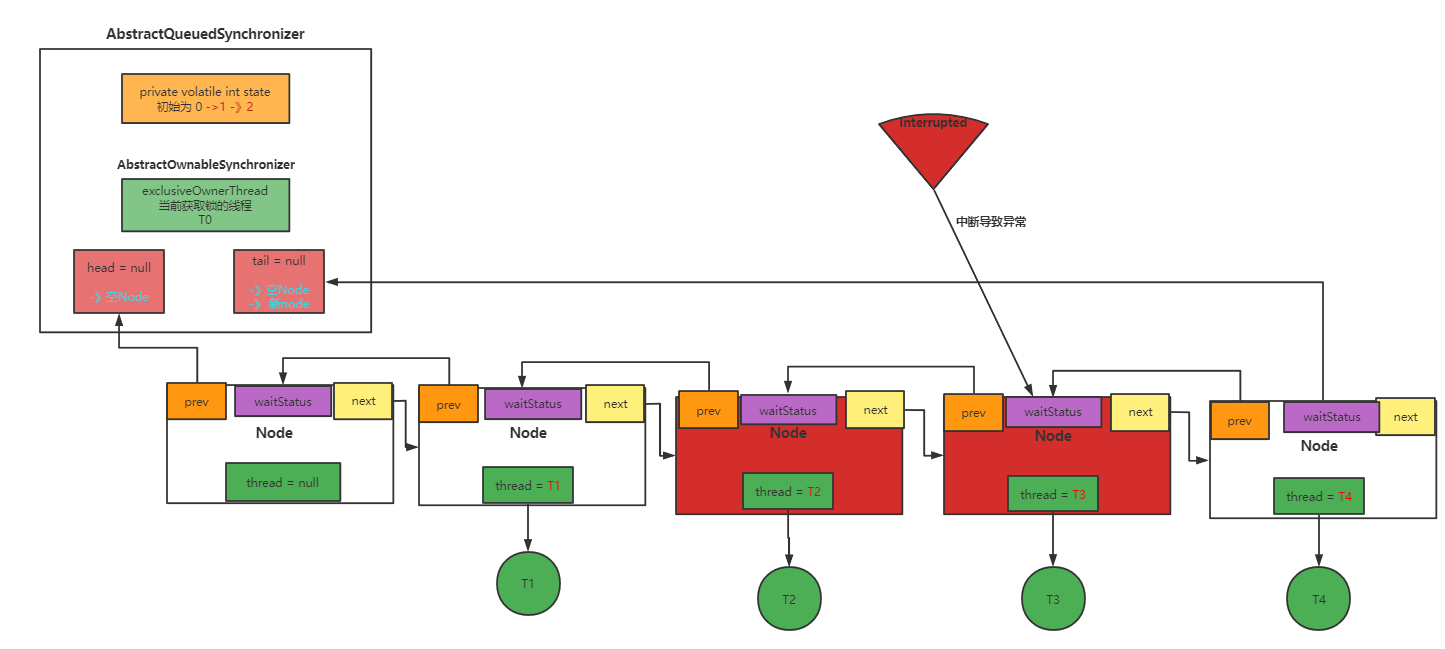
首先会将thread 置空:
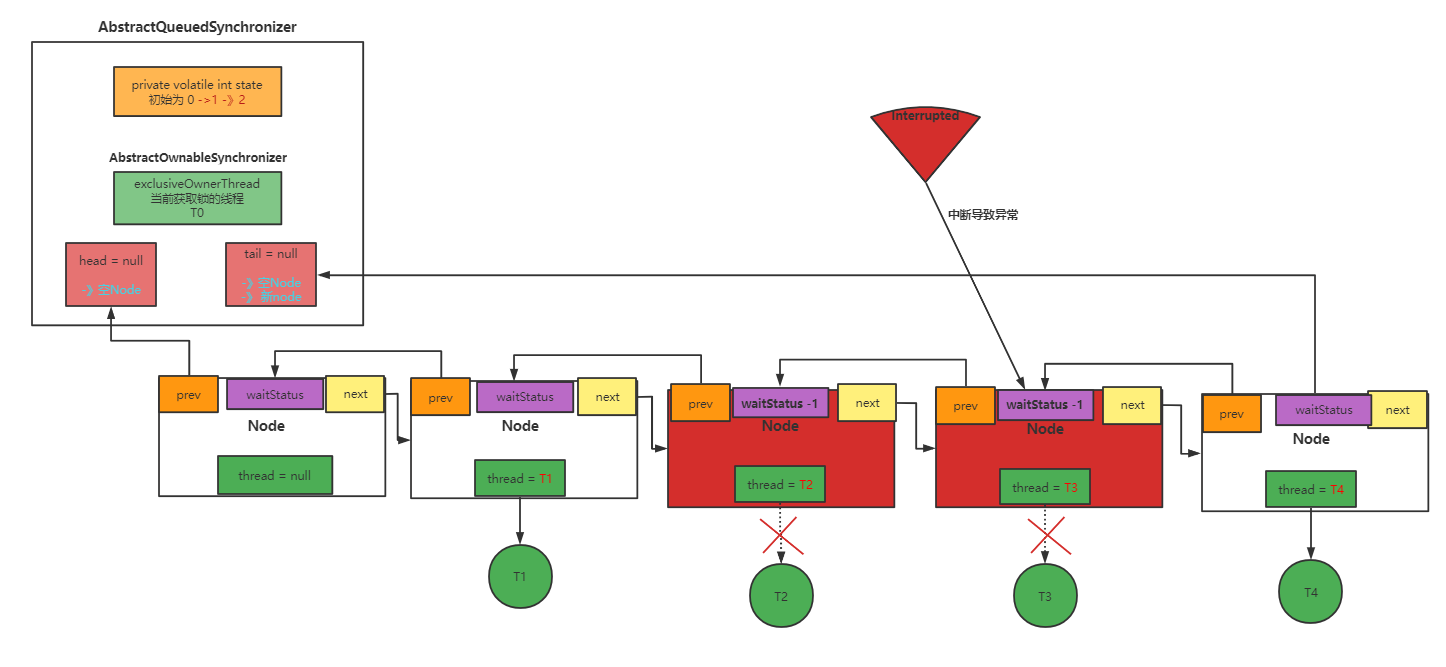
然后将其prev和next等引用废除,并将waitStatus更改为CANCELLED(1):
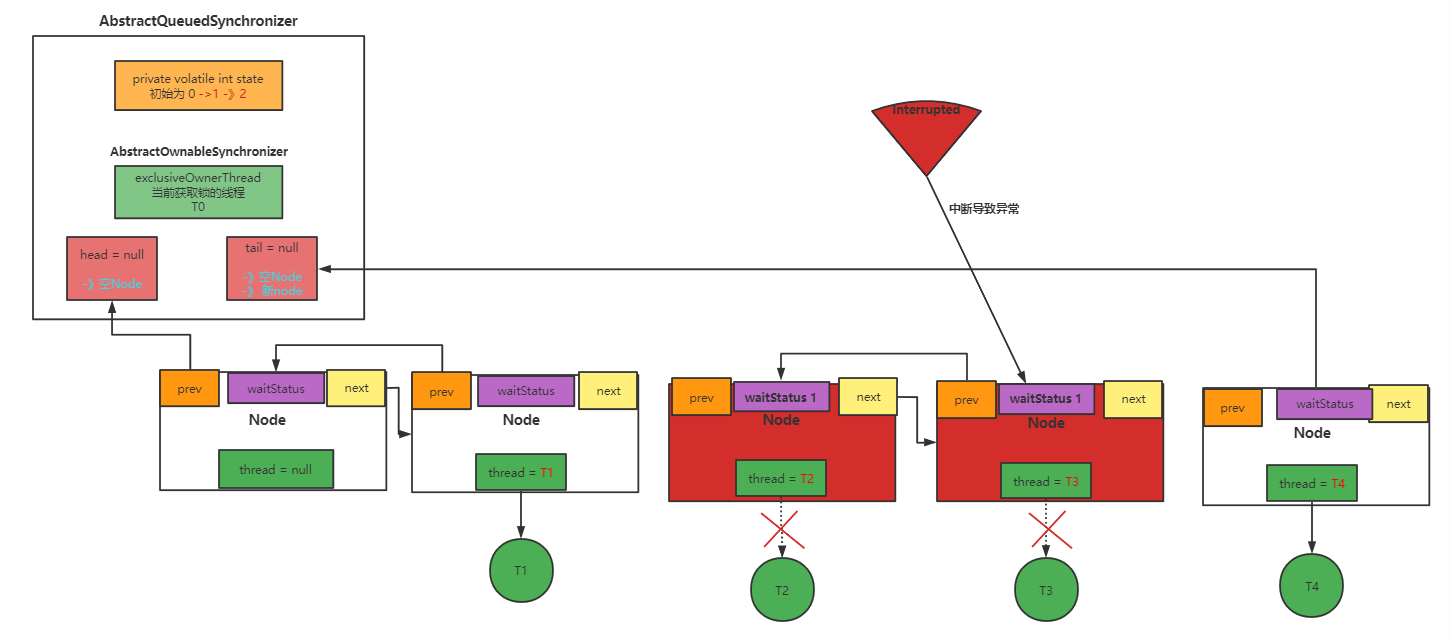
最后将节点引用重新关联:
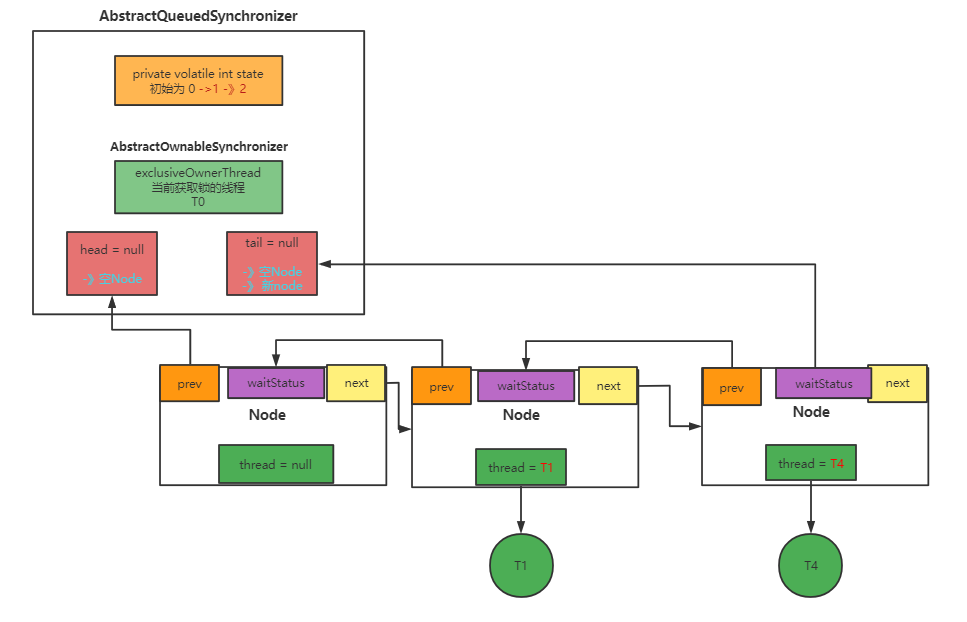















 5472
5472











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









