







1NF 字段是最小的的单元不可再分
2NF 满足1NF,表中的字段必须完全依赖于全部主键而非部分主键 (一般我们都会做到)
3NF 在 2NF 的基础上,非主属性之间没有相互依赖(消除传递依赖)
BCNF 在 3NF 的基础上,没有任何属性完全函数依赖于非候选码的任何一组属性
4NF 在 BCNF 的基础上,消除表中的多值依赖
列类型(数据类型)
所谓的列类型,其实就是指数据类型,即对数据进行统一的分类,从系统的角度出发是为了能够使用统一的方式进行管理,更好的利用有限的空间。
在 SQL 中,将数据类型分成了三大类,分别为:数值型、字符串型和日期时间型。
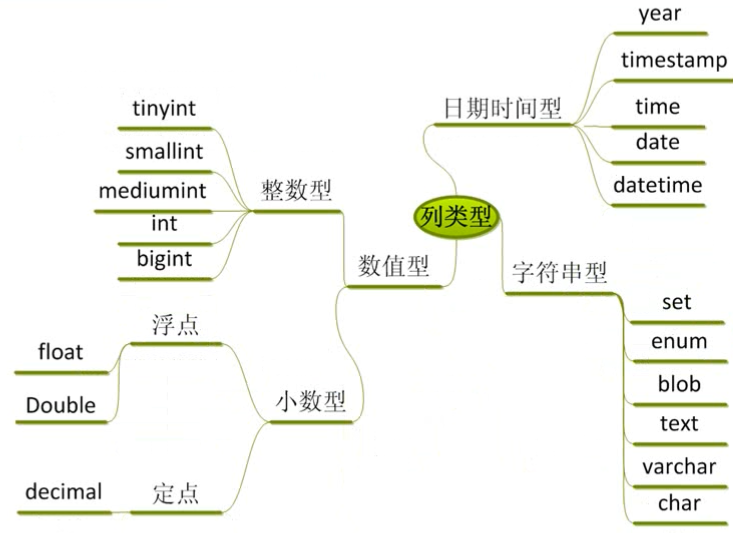
对于数值型数据,可以进一步将其划分为整数型和小数型。
整数型
在 SQL 中,由于要考虑节省磁盘空间的问题,因此系统又将整型细分成五类,分别为:
tinyint:迷你整型,使用 1 个字节存储数据(常用);smallint:小整型,使用 2 个字节存储数据;mediumint:中整型,使用 3 个字节存储数据;int:标准整型,使用 4 个字节存储数据(常用);bigint:大整型,使用 8 个字节存储数据。
事务
一系列将要发生或正在发生的连续操作。
而事务安全,是一种保护连续操作同时实现(完成)的机制。事务安全的意义就是,保证数据操作的完整性。
事务特性
事务的特性,可以简单的概括为ACID,具体为:
- 原子性:
Atomic,表示事务的整个操作是一个整体,是不可分割的,要么全部成功,要么全部失败; - 一致性:
Consistency,表示事务操作的前后,数据表中的数据处于一致状态; - 隔离性:
Isolation,表示不同的事务操作之间是相互隔离的,互不影响; - 持久性:
Durability,表示事务一旦提交,将不可修改,永久性的改变数据表中的数据。
查询数据(上)
- 基本语法:
select + 字段列表/* + from + 表名 + [where 条件]; - 完整语法:
select + [select 选项] + 字段列表[字段别名]/* + from + 数据源 + [where 条件] + [1] + [2] + [3];
[1] = [group by 子句][2] = [order by 子句][3] = [limit 子句]
SELECT 选项
select选项,即select对查出来的结果的处理方式。
all:默认,保留所有的查询结果;
distinct:去重,将查出来的结果中所有字段都相同的记录去除。
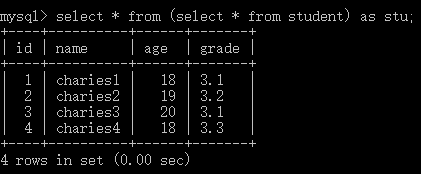
查询语句(子查询)
- 基本语法:
select * from + (select * from + 表名) + [as] + 别名;
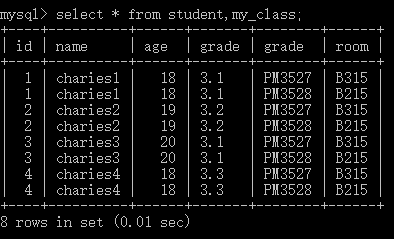
多表数据源
- 基本语法:
select * from + 表名1,表名2...;
distinct
在 SQL 中,关键字 distinct 用于返回唯一不同的值。其语法格式为:
SELECT DISTINCT 列名称 FROM 表名称- 1
假设有一个表“CESHIDEMO”,包含两个字段,分别 NAME 和 AGE,具体格式如下:
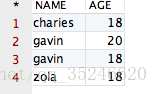
观察以上的表,咱们会发现:拥有相同 NAME 的记录有两条,拥有相同 AGE 的记录有三条。如果咱们运行下面这条 SQL 语句,
/**
* 其中 PPPRDER 为 Schema 的名字,即表 CESHIDEMO 在 PPPRDER 中
*/
select name from PPPRDER.CESHIDEMO- 1
- 2
- 3
- 4
- 5
将会得到如下结果:
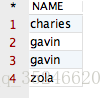
观察该结果,咱们会发现在以上的四条记录中,包含两条 NAME 值相同的记录,即第 2 条记录和第 3 条记录的值都为“gavin”。那么,如果咱们想让拥有相同 NAME 的记录只显示一条该如何实现呢?这时,就需要用到 distinct 关键字啦!接下来,运行如下 SQL 语句,
select distinct name from PPPRDER.CESHIDEMO- 1
将会得到如下结果:
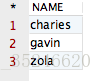
观察该结果,显然咱们的要求得到实现啦!但是,咱们不禁会想到,如果将 distinct 关键字同时作用在两个字段上将会产生什么效果呢?既然想到了,咱们就试试呗,运行如下 SQL 语句,
select distinct name, age from PPPRDER.CESHIDEMO- 1
得到的结果如下所示:
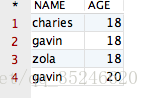
观察该结果,哎呀,貌似没有作用啊?她将全部的记录都显示出来了啊!其中 NAME 值相同的记录有两条,AGE 值相同的记录有三条,完全没有变化啊!但事实上,结果就应该是这样的。因为当 distinct 作用在多个字段的时候,她只会将所有字段值都相同的记录“去重”掉,显然咱们“可怜”的四条记录并不满足该条件,因此 distinct 会认为上面四条记录并不相同。空口无凭,接下来,咱们再向表“CESHIDEMO”中添加一条完全相同的记录,验证一下即可。添加一条记录后的表如下所示:
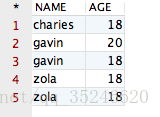
再运行如下的 SQL 语句,
select distinct name, age from PPPRDER.CESHIDEMO- 1
得到的结果如下所示:
观察该结果,完美的验证了咱们上面的结论。
此外,有一点需要大家特别注意,即:关键字 distinct 只能放在 SQL 语句中所有字段的最前面才能起作用,如果放错位置,SQL 不会报错,但也不会起到任何效果。
- 在使用关键字 distinct 的时候,咱们要知道其作用于单个字段和多个字段的时候是有区别的,作用于单个字段时,其“去重”的是表中所有该字段值重复的数据;作用于多个字段的时候,其“去重”的表中所有字段(即 distinct 具体作用的多个字段)值都相同的数据。
where子句
where字句:用来判断数据和筛选数据,返回的结果为0或者1,其中0代表false,1代表true,where是唯一一个直接从磁盘获取数据的时候就开始判断的条件,从磁盘中读取一条数据,就开始进行where判断,如果判断的结果为真,则保持,反之,不保存。
判断条件:
- 比较运算符:
>、<、>=、<=、<>、=、like、between and、in和not in; - 逻辑运算符:
&&、||、和!.
执行如下 SQL 语句,进行测试:
-- 查询表 student 中 id 为 2、3、5 的记录
select * from student where id = 2 || id = 3 || id = 5;
select * from student where id in (2,3,5); - 1
- 2
- 3

-- 查询表 student 中 id 在 2 和 5 之间的记录
select * from student where id between 2 and 5;- 1
- 2

如上图所示,咱们会发现:在使用between and的时候,其选择的区间为闭区间,即包含端点值。此外,and前面的数值必须大于等于and后面的数值,否则会出现空判断,例如:

group by子句
group by子句:根据表中的某个字段进行分组,即将含有相同字段值的记录放在一组,不同的放在不同组。
- 基本语法:
group by + 字段名;
执行如下 SQL 语句,进行测试:
-- 将表 student 中的数据按字段 sex 进行分组
select * from student group by sex;- 1
- 2

观察上图,咱们会发现:表student在分组过后,数据“丢失”啦!实际上并非如此,产生这样现象原因为:group by分组的目的是为了(按分组字段)统计数据,并不是为了单纯的进行分组而分组。为了方便统计数据,SQL 提供了一系列的统计函数,例如:
cout():统计分组后,每组的总记录数;max():统计每组中的最大值;min():统计每组中的最小值;avg():统计每组中的平均值;sum():统计每组中的数据总和。
执行如下 SQL 语句,进行测试:
-- 将表 student 中的数据按字段 sex 进行分组,并进行统计
select sex,count(*),max(age),min(age),avg(age),sum(age) from student group by sex;- 1
- 2
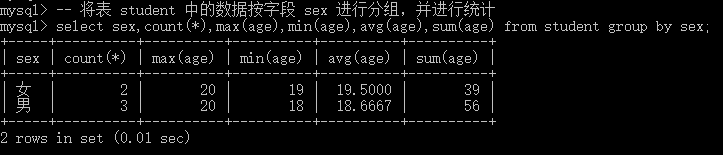
其中,count()函数里面可以使用两种参数,分别为:*表示统计组内全部记录的数量;字段名表示统计对应字段的非null(如果某条记录中该字段的值为null,则不统计)记录的总数。此外,使用group by进行分组之后,展示的记录会根据分组的字段值进行排序,默认为升序。当然,也可以人为的设置升序和降序。
- 基本语法:
group by + 字段名 + [asc/desc];
执行如下 SQL 语句,进行测试:
-- 将表 student 中的数据按字段 sex 进行分组,并排序
select sex,count(*) from student group by sex;
select sex,count(*) from student group by sex asc;
select sex,count(*) from student group by sex desc;- 1
- 2
- 3
- 4

通过观察上面数个分组示例,细心的同学会发现:咱们在之前的示例中,都是用单字段进行分组。实际上,咱们也可以使用多字段分组,即:先根据一个字段进行分组,然后对分组后的结果再次按照其他字段(前提是分组后的结果中包含此字段)进行分组。
执行如下 SQL 语句,进行测试:
-- 将表 student 中的数据先按字段 grade 进行分组,再按字段 sex 进行分组
select *,count(*) from student group by grade,sex;- 1
- 2

having子句
having字句:与where子句一样,都是进行条件判断的,但是where是针对磁盘数据进行判断,数据进入内存之后,会进行分组操作,分组结果就需要having来处理。思考可知,having能做where能做的几乎所有事情,但是where却不能做having能做的很多事情。
第 1 点:分组统计的结果或者说统计函数只有having能够使用
执行如下 SQL 语句,进行测试:
-- 求出表 student 中所有班级人数大于等于 2 的班级
select grade,count(*) from student group by grade having count(*) >= 2;
select grade,count(*) from student where count(*) >= 2 group by grade;- 1
- 2
- 3

如上图所示,显然having子句可以对统计函数得到的结果进行筛选,但是where却不能。
第 2 点:having能够使用字段别名,where则不能
执行如下 SQL 语句,进行测试:
-- 求出表 student 中所有班级人数大于等于 2 的班级
select grade,count(*) as total from student group by grade having total >= 2;
select grade,count(*) as total from student where total >= 2 group by grade;- 1
- 2
- 3

如上图所示,显然咱们的结论得到了验证。究其原因,where是从磁盘读取数据,而磁盘中数据的名字只能是字段名,别名是数据(字段)进入到内存后才产生的。值得注意的是,在上述 SQL 语句中咱们使用了字段别名,这在无意中就优化了 SQL 并提高了效率,因为少了一次统计函数的计算。
order by子句
order by子句:根据某个字段进行升序或者降序排序,依赖校对集。
- 基本语法:
order by + [asc/desc];
其中,asc为升序,为默认值;desc为降序。
执行如下 SQL 语句,进行测试:
-- 将表 student 中的数据按年龄 age 进行排序
select * from student order by age;- 1
- 2
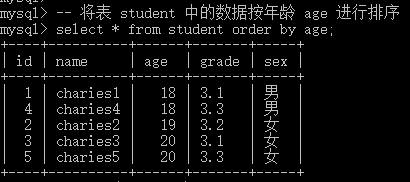
此外,咱们可以进行「多字段排序」,即先根据某个字段进行排序,然后在排序后的结果中,再根据某个字段进行排序。
执行如下 SQL 语句,进行测试:
-- 将表 student 中的数据先按年龄 age 升序排序,再按班级 grade 降序排序
select * from student order by age,grade desc;- 1
- 2

limit子句
limit子句:是一种限制结果的语句,通常来限制结果的数量。
- 基本语法:
limit + [offset] + length;
其中,offset为起始值;length为长度。
第 1 种:只用来限制长度(数据量)
执行如下 SQL 语句,进行测试:
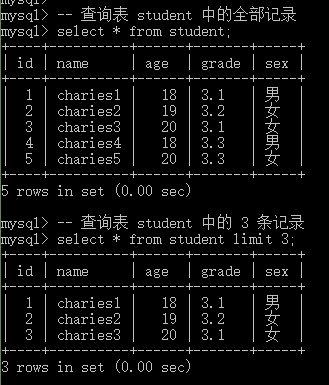
-- 查询表 student 中的全部记录
select * from student;
-- 查询表 student 中的 3 条记录
select * from student limit 3;- 1
- 2
- 3
- 4
第 2 种:限制起始值,限制长度(数据量)
执行如下 SQL 语句,进行测试:
-- 查询表 student 中的记录
select * from student limit 0,2;
-- 查询表 student 中的记录
select * from student limit 2,2;- 1
- 2
- 3
- 4

第 3 种:主要用来实现数据的分页,目的是为用户节省时间,提高服务器的响应效率,减少资源的浪费
大致设计:
- 对于用户来讲,可以通过点击页码按钮,如
1、2、3等来进行选择; - 对于服务器来讲,可以根据用户选择的页码来获取不同的数据。
其中,
length:表示每页的数据量,基本不变;offset:表示每页的起始值,公式为offset=(页码-1)*length.















 710
710











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









