







1.使用File来访问本地文件系统
File类可以使用文件路径字符串来创建File实例,字符串既可以是绝对路径也可以是相对路径。Windows的路径分隔符使用反斜线(\),Java里应使用\\(单个\表示转义字符)
2.IO流的三种分类
(1)输入流和输出流(从内存角度)
输入流:只读取数据
输出流:只写入数据
Java的输入流主要由InputStream和Reader作为基类,而输出流主要由OutputStream和Writer作为基类,均为抽象类,无法直接创建实例。
(2)字节流和字符流
字节流由InputStream和OutputStream作为基类,而字符流由Reader和Writer作为基类。
(3)节点流和处理流
从/向一个特定的IO设备读/写数据的流,称为节点流。
处理流对一个已经存在的流进行连接或封装,通过封装后的流来实现数据读/写功能。
IO流的40多个类都是从以下4个抽象类派生的:
InputStream/Reader:所有输入流的基类,字节输入流/字符输入流
OutputStream/Writer:所有输出流的基类,字节输出流/字符输出流
对于Windows平台,字符串内容的换行符是\r\n。
3.输入/输出流体系
(1)处理流的用法
使用处理流来包装节点流,程序通过处理流来执行输入/输出功能,让节点流与底层的I/O设备、文件交互。如:
try(
FileOutputStream fos = new FileOutputStream(“test.txt”);
//创建一个处理流,即传入一个节点流作为构造器参数即可
PrintStream ps = new PrintStream(fos);
{
//执行输出
}
)上面程序先定义了一个节点输出流,然后程序使用PrintStream包装了该节点输出流,最后使用PrintStream输出。
计算机文件分为文本文件和二进制文件,所有能用记事本打开的都是文本文件,其他的都是二进制文件,但实质上,文本文件只是二进制文件的一种特例,也是二进制文件。
(2)转换流
InputStreamReader将字节输入流转换为字符输入流,OutputStreamWriter将字节输出流转换为字符输出流。(Java没有提供字符流转换成字节流)
4.重定向标准输入/输出
在System类里提供三个重定向标准方法:
Static void setErr(PrintStream err):重定向“标准”错误输出流
Static void setIn(PrintStream in):重定向“标准”输入流
Static void setOut(PrintStream out):重定向“标准”输出流
举例见书P691
衡量输入输出时总是站在运行本程序所在内存的角度。
5.RandomAccessFile类用法
RandomAccessFile是Java输入/输出流体系中功能最丰富的文件内容访问类,支持“随机访问”方式,自由访问文件的任意位置。但只能读写文件,不能读写其他IO节点。
RandomAccessFile提供了两个方法操作文件指针:
Long getFilePointer():返回文件记录指针的当前位置
Void seek(long pos):将文件记录指针定位到pos位置
创建RandomAccessFile还需要指定一个mode参数,即访问模式(4种):
“r”:只读
“rw”:以读、写打开指定文件,若文件不存在,则新建
“rws”:以读、写打开指定文件,相对于“rw”模式,还要求对文件内容或元素据的每个更新都同步到底层存储设备。
“rwd”:以读写打开指定文件,相对于“rw”模式,还要求对文件内容的每个更新都同步写入底层存储设备。
如:
try(
RandomAccessFile raf = new RandomAccessFile(“out.txt”,“rw”);
{
raf.seek(raf.length());
raf.write(“追加的内容!\r\n”.getbytes());
}
)RandomAccessFile不能向文件的指定位置插入内容,否则将会覆盖原有内容。如果需要在指定位置插入,则先把插入点之后的内容读入缓冲区,插入数据后,追加在文件后面。举例见P696
6.对象序列化
(1)对象的序列化(Serialize)指将一个Java对象写入IO流,对象的反序列化(Deserialize)指从IO流中恢复该对象。
如果需要让某个对象支持序列化机制,则必须它的类是可序列化的,必须实现下面两个接口之一:Serializable 或 Externalizable
举例:
public class Person implements java.io.Serializable{
private String name;
private int age;
public Person(String name,int age){
System.out.println("有参数的构造器");
this.name = name;
this.age = age;
}
//省略name与age的setter和getter方法
...
}
public class WriteObject{
public static void main(String[] args)
{
try(
//创建一个ObjectOutputStream输出流
ObjectOutputStream oos = new ObjectOutputStream((new FileOutputStream("object.txt"))) {
Person per = new Person("孙悟空", 500);
//将per对象写入输出流
oos.writeObject(per);
}
catch(IOException ex){
ex.printStackTrace();
}
}
}运行上面程序,将会看到生成一个object.txt文件,文件内容是Person对象。
反序列化的代码如下:
public class ReadObject{
public static void main(String[] args)
{
try(
//创建一个ObjectInputStream输入流
ObjectInputStream ois = new ObjectInputStream(new FileInputStream("object.txt")))
{
//从输入流中读取一个java对象,并将其强制类型转换为Person类
Person p = (Person)ois.readObject();
System.out.println("名字为:"+p.getName()+"\n年龄为:"+p.getAge());
}
catch(Exception ex){
ex.printStackTrace();
}
}
}(2)对象引用的序列化
一个类引用另一个类(如某类的一个方法:public Teacher (String name , Person student))则另一个类也必须是可序列化的。
如果多次序列化同一个Java对象时,只有第一次序列化时才会把该Java对象转换成字节序列输出,再次调用时,只是输出前面的序列化编号。
(3)自定义序列化
当对某个对象进行序列化时,系统会自动对该对象的所有实例变量依次进行序列化,如果引用到另一个对象,则被引用对象也会被序列化(递归序列化)。
在一些特殊情景下,如银行帐户信息,不应该进行序列化,则应该在实例变量前使用transient关键字修饰,被transiant修饰的实例变量将被完全隔离在序列化机制之外。如:private transient int age;
7.NIO(新IO支持)
新IO是面向块的处理,除了Buffer和Channel之外,还提供了逆映射操作的Charset类和支持非阻塞式输入/输出的Selector类。
(1)使用Buffer
Buffer本质是一个数组,可以保存多个类型相同的数据。Buffer是一个抽象类,最常用的子类是ByteBuffer,可以在底层字节数组上进行set/get操作。
Buffer中三个重要概念:
容量(capacity):缓冲区的容量表示该buffer的最大数据容量,不可为负值,创建后不可改变。
界限(limit):位于limit之后的数据既不可读也不可写。
位置(position):记录指针。
除此之外,buffer里还有一个可选标记mark,允许直接将position定位到mairk处。
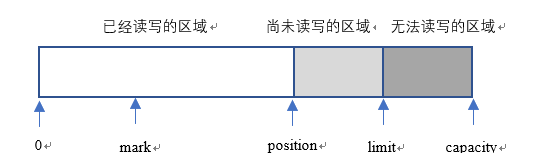
Put()方法向Buffer中放入一些数据,position相应向后移动一些位置。
Flip()方法将limit设置为position位置,并将pisition设为0.
Clear()方法不是清空buffer数据,仅将position位置为0,将limit置为capacity,再次向Buffer中装入数据做好准备。
当使用put()和get()来访问Buffer中的数据时,分为相对和绝对两种:
相对(Relative):从当前position位置开始读取或写入数据,position值顺后增加。
绝对(Absolute)直接根据索引向Buffer中读取或写入数据,使用绝对方式访问buffer里的数据时,不会影响position的值。
(2)使用channel
Channel可以直接将指定文件的部分或全部直接映射成Buffer。程序不能直接访问channel中的数据,包括读取写入都不行,只能与Buffer交互。Channel不是通过构造器来创建,而是通过getChannel()方法。
Channel中最常用的三个方法是map(),read(),write()。
Map方法的方法签名为:MappedByteBuffer map(FileChannel.MapMode , long position , long size),第一个参数执行映射时的模式,分为只读和读写。
举例如:
public class RandomFileChannelTest
{
public static void main(String[] args) throw IOException
{
File f = new File("a.txt");
try(
//创建一个RandomAccessFile对象
RandomAccessFile raf = new RandomAccessFile(f,"rw");
//获取RandomAccessFile对应的Channel
FileChannel randomChannel = raf.getChannel()
)
{
//将Channel中的所有数据映射成ByteBuffer
ByteBuffer buffer = randomChannel.map(FileChannel.MapMode.READ_ONLY , 0
,f.length());
//把Channel的记录指针移动到最后
randomChannel.position(f.length());
//将buffer中的所有数据输出
randomChannel.write(buffer);
}
}
}(3)字符集和CharSet
Charset用来处理字节序列和字符序列(字符串)之间的转换关系,Charset类是不可变的。
1)获取Charset对象
调用Charset的forName()方法创建Charset对象,如:
Charset csCn = Charset.foeName(“GBK”);2)通过该对象的newDecoder()或newEncoder()方法反别返回CharsetDecoder和CharsetEncoder对象,代表解码器和编码器。调用CharsetDecoder的decoder()方法就可以将ByteBuffer(字节序列)转换成CharBuffer(字符序列)。调用CharsetEncoder的encoder()方法就可以将CharBuffer或String(字符序列)转换成ByteBuffer(字节序列)。
(4)文件锁
直接使用lock()或trylock()方法获取的文件锁是排他锁。
区别是:当lock()试图锁定某个文件时,如果无法得到文件锁,将一直阻塞。
而trylock()是尝试锁定文件,如果获得文件锁,则返回该文件锁,否则返回null。















 538
538











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









