









目录:
本节的所有代码都在这里:这里
位于javalearn的filelearn中
IO流
File类的一个对象代表一个类或者一个文件目录
File声明在java.io包下。


路径&路径分隔符:


File方法
需要注意的是:new File()是不会创建一个新的文件的,只是在内存中创建对应的对象。



文件本身操作(文件创建删除):
未对文件内部操作

例子:创建文件


例子:删除文件

IO流原理
我们是站在程序的角度上看输入和输出。

字符流:常用于文本文件。
字节流:常用于图片,视频。




流的使用步骤:

文件读取案例:
注意读入需要文件本身存在!!!

上述代码只是代码主体,但是如果使用throws方法进行异常处理,如果在关闭前出现了异常,整段代码最终就不会关闭,容易造成内存泄漏,所以我们需要使用try-catch-finally方法进行异常处理。所以我们更改为下面代码:

但是这段代码还是有问题:问题在于如果我们创建了一个fr的对象之后,在new的时候出现了异常,也就是没有成功创建对象,最后我们在关闭fr时就会出现空指针问题。所以为了解决这个问题,我们需要修改finally中的方法:

文件读取案例2:

文件写案例1:
没有的文件会直接自动创建
写操作覆盖整个文件(缺省)。如果修改为true就表示不覆盖,直接在后面写。


文件读入写出案例:


字节流Stream输入输出案例:


为什么使用数组:
如果每次存取一个祖字符,这样交互产生的开销会非常大。这个数组就相当于组成原理中的缓存的概念,取一个合适的大小最终再一起读或者取。但是不能太大否则内存消耗过大。
上述的四种方式在实际操作过程中用的很少,原因在于这个方法效率不高,一般来说我们都会使用缓冲流。

注意处理流是不可以直接创建的,需要在节点流的基础上使用
缓冲流的使用案例:
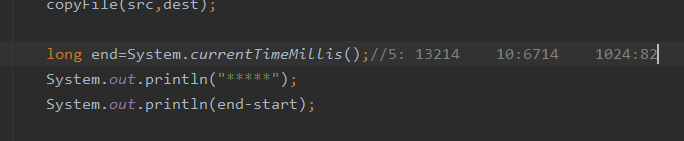
使用了缓冲流之后再数组同为10时:花费时间为58.如果不适用缓冲流,如上图所示时间为6714.



转换流(属于字符流)


转换流案例:

标准输入输出流(了解):

打印流(了解):
只有输出流
数据流(了解):
用于持久化基本数据类型的变量或者字符串

例子:

读取数据的顺序需要和当初写入文件的顺序相同。

对象流:
数据流没法存储相应的对象,所以产生了对象流。

对象的序列化:


详细说明上述三种问题:
1.注意一个自定义的类如果能够序列化我们需要这个对象实现Serializable这种接口称之为标识接口,没有方法。
其次我们需要一个标识序列号


2.就是说如果不加这个版本序列号,我们要是修改了序列化之后的自定义类,很有可能会在反序列化的时候出现异常。
3.如果我们的自定义类中还有其他的自定义类,但是这个其他的自定义类没有声明为可序列化的也会导致错误出现。
4.补充知识:如果成员变量使用的是static或者是transient修饰,则不能序列化。会出现无法保存的问题(transient表示不能序列化这个属性)
序列化反序列化案例:


随机存取文件流

写文件的时候会从头开始进行覆盖。


NIO2(了解)

NIO是JDK7之前的,NIO2为JDK7之后的
















 654
654











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









