







国外耳语音数据库😎
| Corpus | 发音人 | 录音设备数量 | 文本数量/句 | 总时长/h | 并行录制 |
|---|---|---|---|---|---|
| UT - Vocal Effort - I (UTVE1) | 12 | 3 | 5 | 1 | no |
| UT - Vocal Effort - II (UTVE2) | 112 | 2 | 41 | 2 | no |
| CHAINs corpus | 36 | 1 | 33 | 3 | no |
| wTIMIT corpus | 48 | 1 | 460 | 15 | yes |
| CIAIR Japanese speech corpus | 123 | 2 | 110 | - | yes |
| iWhisper - Mandarin corpus | 80 | 1 | 100 | 15 | yes |
| wSPIRE | 88 | 5 | 100 | 37 | yes |
· UT - Vocal Effort - I (UTVE1)
旨在研究语音发音力度变化的影响,语料库中包含12名美国本土英语男性发音人分别用五种状态(喊叫、大声、正常、小声、耳语)录制的5句话(from the TIMIT database),另外20句正常状态的话和五种状态下各一分钟的自发讲话,总共约1小时。
录音设备:a P-Microphone (physiological microphone) ,a SHURE Beta-54 close-talking microphone,a SHURE MX391/S far field microphone
· UT - Vocal Effort - II (UTVE2)
着重于在正常语音交流中嵌入耳语关键信息,该语料库包含112名发音人(37男75女),分为自发交流部分和阅读部分( 41 sentences from the TIMIT database,two paragraphs selected from a local newspaper),总共时长大约为2小时。
录音设备:a SHURE Beta-54 microphone
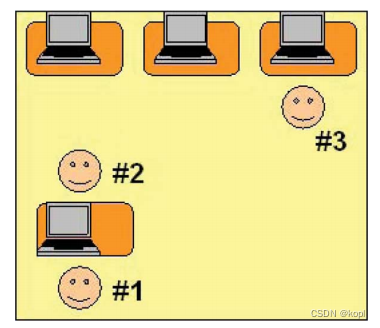
🎧自发交流部分的录音在一个模拟网吧的场景录制。被试1和被试2进行对话(面对面坐着,在被试1前面放置一台笔记本电脑,列出了一些重要信息,如姓名、住址、电话号码、银行卡号等)。在这里,被试1被要求以尽可能低的声音或耳语让被试2收到关键信息,而不至于让被试3窃听到。
· CHAINS corpus
该语料库的设计目标是为具有相同口音的说话者提供一系列的说话风格和声音变换,共有36名发音人(18男18女)用6种不同的方式说话,包含正常和耳语。其中,28人(14名男性,14名女性)来自爱尔兰东部,这为语料库整体方言的一致性提供了保证。另外8人(4名男性,4名女性)来自英国或美国。每个发音人在数据集中分别发表了33句演讲(nine selected from the CSLU Speaker Identification corpus, and 24 from the TIMIT corpus)和一篇短篇小说,语料库的总时长约为3小时。
录音设备:
1. 正常音时,a Neumann U87 Condenser microphone,a Neumann K184 condenser mic (positioned above the subject’s head),a B&K 4006 omnidirectional condenser microphone (located to the rear of the subject)
2. 耳语音时,a Shure SM50 head-mounted microphone connected to a Marantz PMD 670 Compact Flash recorder
录音配置 :44.1kHz/16bit
· wTIMIT corpus
该语料库是一个大型数据集,由48名发音人(25男23女)组成,其中有20名新加坡发音人和28名北美发音人,每个人说460句从MOCHA-TIMIT语料库中选取的句子。wTIMIT语料库的总持续时间约为15小时。
录音设备: an MX-2001 directional condenser microphone
· CIAIR Japanese speech corpus
这是一个多模态的语料库,旨在研究真实环境中语音的应用,包含有车内数据集、真实环境下领夹麦数据集和耳语数据集。其中耳语音数据集由123名发音人(68男55女)录制了超过6000句的句子,每个人读60句来自ATR语音平衡的句子和50句ASJ日本新闻中的句子。
录音设备:Sennheiser HMD410,摄像机Sony DCR-TRV900 model,手机Panasonic KX-HS110(发)、Kyocera PS-C1(收)

模拟真实环境下,用手捂住嘴进行通话的情况,左下为用手捂住嘴,右下为用手同时捂住嘴和麦克风。
· iWhisper - Mandarin corpus
该语料库类似于wTIMIT,包含正常音和耳语音对应的语音数据,专门为研究耳语音信号处理而设计的。该语料库由80位新加坡发音人(40男40女)组成,年龄为16-20岁,均为普通话母语者,每个人录制了100句普通话语音平衡的句子。
录音设备:an Audio-Technica ATH-750COM USB headset microphone
录音配置:16kHz
· wSPIRE
该耳语音语料库特点为多设备并行录制,包含88名发音人(54男34女)使用5个录音设备录制了正常音和耳语音的数据(the first 450 sentences in the MOCHA-TIMIT corpus),并且进行了单词级别的标注,总共约44000条语音,时长超过36小时。
录音设备:
-
Zoom H6 Handy Recorder: 具有高质量的录音能力,常用于专业录音。
-
Philips Stereo Headphones SHP-1900/97: 用于比较不同设备录音效果。
-
Apple iPhone 7: 市场上广泛使用的智能手机,代表高端手机录音效果。
-
Nokia 5.1: 中端智能手机,提供另一种录音标准。
-
Motorola moto e5 plus: 低端智能手机,展示在更便宜设备上的录音效果。
录音配置 :所有设备均以44.1kHz/16bit的采样率录制,并后期降采样到16kHz保存为WAV格式。

为了确保多设备录音的同步性,使用了三种音调进行标记:
-
录音开始音调:标记整个录音的开始。
-
句子开始音调:标记每个句子的开始。
-
句子结束音调:标记每个句子的结束。播放上升音调时,发音准确;播放下降音调时,需重新发音。
数据说明与分析:语音率(每秒单词数wpm)、句子时长、单词时长
用途:耳语的VAD检测、说话人确认、语音识别、录音设备分类
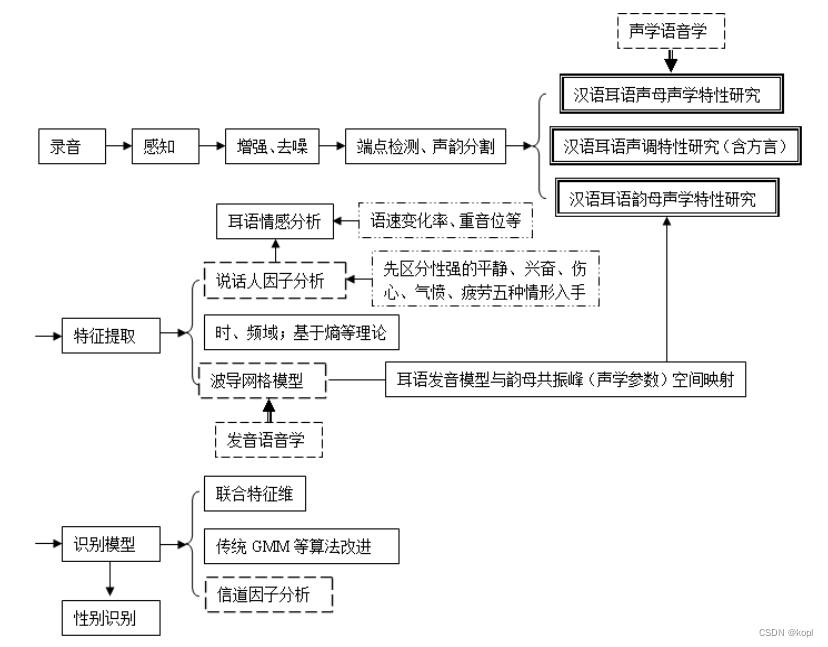
国内耳语数据库😎
1. 南京大学声学所用于基础研究时建立的一个包含1172个汉字和98个近音词的单人女生汉语耳语音库,其中每个字20遍耳语音,1遍正常音,每组词10遍耳语音,1遍正常音;在研究耳语音说话人识别时,建立了一个由0-9字符串与10个单词为语料,10男10女共20名发音人的耳语音库。
录音参数:8kHz/16bit
2. 北京理工大学建立的10小时小型耳语音库,其语料主要由0-9的单个数字和3-5个连续数字串,以及10句连续语句(from 863训练库)组成,录用由10男10女共20名发音人组成。
录音设备:Shure KSM32 (16kHz/16bit)
3. 东南大学针对耳语音情感研究建立了由10名发音人(5男5女)组成的5种情感状态(喜、怒、惊、悲、平静)的语音库。语料包含20个单词、25个短句、6个段落,每位发音者耳语音重复3遍,正常音重复1遍,共计 9600 条语句。研究耳语增强时,又额外建立了2男2女50条句子组成的耳语音库。
录音设备:M-audio Nova大振膜电容话筒 (16kHz/16bit)
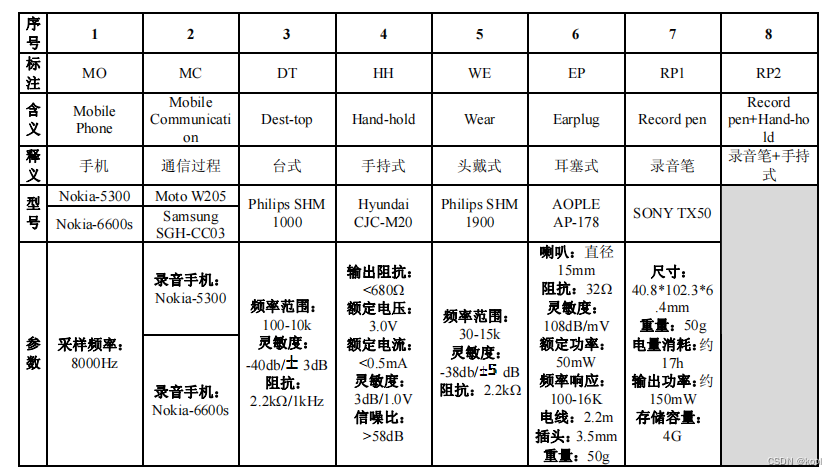
4. 苏州大学龚呈卉在基于联合因子分析的耳语音说话人识别研究中建立了一个由200名发音人(120男80女)的耳语音数据库,其中数字、单词均为1遍正常音、5遍耳语音,而语句则为1遍正常音、1遍耳语音。该语料库文本设计丰富,其中有398个音节含四声、数字0-9、适于情绪表达(平静、惊奇、高兴、愤怒、恐惧、悲伤六种)的单词8个和短句12句、新闻报道语句46句。
录音设备:
参考文献:
- C. Zhang and J. H. Hansen, “Whisper-island detection based on unsupervised segmentation with entropy-based speech feature processing,” IEEE Transactions on Audio, Speech, and Language Processing, vol. 19, no. 4, pp. 883–894, 2010.
- S. Ghaffarzadegan, H. Boˇril, and J. H. Hansen, “UT-VOCAL EFFORT II: Analysis and constrained-lexicon recognition of whispered speech,” in IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2014, pp. 2544–2548.
- F. Cummins, M. Grimaldi, T. Leonard, and J. Simko, “The CHAINS corpus: Characterizing individual speakers,” in Proc of SPECOM, vol. 6, 2006, pp. 431–435.
- B. P. Lim, “Computational differences between whispered and nonwhispered speech,” Ph.D. dissertation, University of Illinois at UrbanaChampaign, 2011.
- N. Kawaguchi, K. Takeda, S. Matsubara, I. Yokoo, T. Ito, K. Tatara, T. Shinde, and F. Itakura, “Ciair speech corpus for real world applications,” in The International conference Committee for the Coordination and Standardization of Speech Databases and Assesment Techniques, 2002.
- P. X. Lee, D. Wee, H. S. Y. Toh, B. P. Lim, N. F. Chen, and B. Ma, “A whispered mandarin corpus for speech technology applications,” in Fifteenth Annual Conference of the International Speech Communication Association, 2014.
- B. Singhal, A. R. Naini and P. K. Ghosh, "wSPIRE: A Parallel Multi-Device Corpus in Neutral and Whispered Speech," 2021 24th Conference of the Oriental COCOSDA International Committee for the Co-ordination and Standardisation of Speech Databases and Assessment Techniques (O-COCOSDA), Singapore, Singapore, 2021, pp. 146-151, doi: 10.1109/O-COCOSDA202152914.2021.9660449.
-
杨莉莉 , 李燕 , 徐柏龄 . 汉语耳语音库的建立与听觉实验研究 [J]. 南京大学学报 ( 自然科学版). 2005, 41(5): 311-317.
-
茹婷婷,谢湘.耳语音数据库的设计与采集 [J] .清华大学学报. 2008, 48 (S1): 725-729.
- 金赟,赵艳,黄程韦,等.耳语音情感数据库的设计与建立[J].声学技术,2010,29(01):63-68.
- 龚呈卉.基于联合因子分析的耳语音说话人识别研究[D].苏州大学,2014.

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









