







字典压缩算法-LZ77
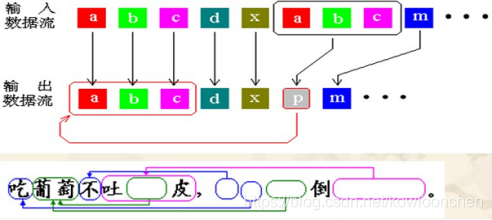
LZ77字典算法的想法是企图查找正在压缩的字符序列是否在以前输入的数据中出现过,然后用已经出现过的字符串代替重复的部分,它的输出仅仅是指向早期出现过的字符串的“指针”。例如:
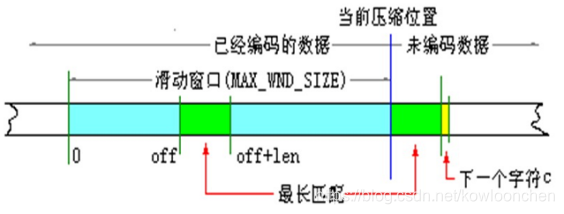
LZ77算法在某种意义上又可以称为“滑动窗口压缩”,该算法将一个虚拟的、可以跟压缩进程滑动的窗口作为词典,要压缩的字符串如果在该窗口中出现,则输出其出现的位置和长度。使用固定大小窗口进行匹配,而不是在所有已经编码的信息中匹配,是因为匹配算法的时间消耗往往很多,必须限制词典的大小才能保证算法的效率,随着压缩进程移动窗口词典窗口,使其中总包含最近编码过的信息,对大多数信息而言,要编码的字符串往往在最近的上下文中更容易找到匹配串。
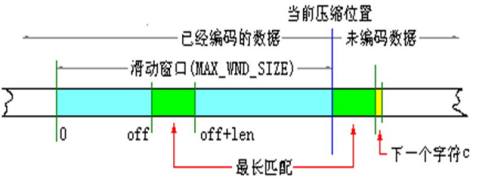
LZ77算法的基本流程:
-
从当前压缩位置开始,考察未编码的数据,并试图在滑动窗口中找出最长的匹配字符串,如果找到,则进行步骤2,否则进行步骤3;
-
输出三元符号组(off,len,c),其中off为窗口中匹配字符串相对窗口边界的偏移,len为可匹配的仓长度,c为下一个字符,即不匹配的第一个字符,然后将窗口向后滑动len+1个字符,继续步骤1;
-
输出三元符号组(0,0,c),其中c为下一个字符。然后将窗口向后滑动一个字符,继续步骤1.
LZ77算法示例:
| A | A | B | C | B | B | A | B | C |
|---|
如上一段字符串,我们可以通过下面的步骤来进行压缩:
| 步骤 | 位置 | 输入 | 匹配串 | 输出 |
|---|---|---|---|---|
| 1 | 1 | A | – | 0,0,A |
| 2 | 2 | AB | A | 1,1,B |
| 3 | 4 | C | – | 0,0,C |
| 4 | 5 | BB | B | 3,1,B |
| 5 | 7 | ABC | AB | 2,2,C |
LZ77算法通过输出真实的字符解决了在窗口中出现没有匹配串的问题,但是这个解决方案包含有冗余信息。冗余学习表现在连个方面:一是空指针;二是编码器可能输出额外的字符,这种字符是指可能包含在下一个匹配串中的字符。
原文链接:https://blog.csdn.net/kowloonchen/article/details/103931523














 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









