







PostgreSQL压缩算法(源码分析)-pglz
在PostgreSQL中,PGLZ算法主要用于TOAST(The Oversized-Attribute Storage Technique)机制,用于压缩大型数据库中的字段值。当某个字段的值超过一定长度时,PostgreSQL会将该字段值压缩为PGLZ格式,这样可以有效地减少数据库的存储空间占用,并提高查询性能。
PGLZ是PostgreSQL使用的LZ系列压缩算法,对于大于2KB的值,它会自动启动,在pg14之前,postgreSQL就只有pglz压缩算法。
下面注释节选自postgreSQL源码中pg_lzcompress.c
```C
/* The compression algorithm
*
* The following uses numbers used in the default strategy.
*
* The compressor works best for attributes of a size between
* 1K and 1M. For smaller items there's not that much chance of
* redundancy in the character sequence (except for large areas
* of identical bytes like trailing spaces) and for bigger ones
* our 4K maximum look-back distance is too small.
压缩器最适合处理大小在1K到1M之间的属性。对于较小的项目,字符序列中出现冗余的可能性不大(除了像尾部空格这样的大面积相同字节),而对于较大的项目,我们4K的最大回溯距离太小。
*
* The compressor creates a table for lists of positions.
* For each input position (except the last 3), a hash key is
* built from the 4 next input bytes and the position remembered
* in the appropriate list. Thus, the table points to linked
* lists of likely to be at least in the first 4 characters
* matching strings. This is done on the fly while the input
* is compressed into the output area. Table entries are only
* kept for the last 4096 input positions, since we cannot use
* back-pointers larger than that anyway. The size of the hash
* table is chosen based on the size of the input - a larger table
* has a larger startup cost, as it needs to be initialized to
* zero, but reduces the number of hash collisions on long inputs.
该压缩器为位置列表创建了一个表。对于每个输入位置(除了最后3个),都会根据接下来的4个输入字节和该位置构建一个哈希键,并将该位置存储在适当的列表中。因此,该表指向的是可能有至少前4个字符匹配的字符串的链表。这是在将输入压缩到输出区域时实时完成的。表项只保留最近的4096个输入位置,因为我们无论如何都不能使用大于此的回指针。哈希表的大小是根据输入的大小来选择的——较大的表有更大的启动成本,因为它需要被初始化为零,但可以减少长输入上的哈希冲突数量。
* For each byte in the input, its hash key (built from this
* byte and the next 3) is used to find the appropriate list
* in the table. The lists remember the positions of all bytes
* that had the same hash key in the past in increasing backward
* offset order. Now for all entries in the used lists, the
* match length is computed by comparing the characters from the
* entries position with the characters from the actual input
* position.
对于输入中的每个字节,其哈希键(由该字节和接下来的3个字节构建)用于在表中查找适当的列表。这些列表记住了过去具有相同哈希键的所有字节的位置,并按向后偏移的递增顺序排列。现在,对于所使用的列表中的所有条目,通过比较条目的位置与实际输入位置的字符来计算匹配长度。
*
* The compressor starts with a so called "good_match" of 128.
* It is a "prefer speed against compression ratio" optimizer.
* So if the first entry looked at already has 128 or more
* matching characters, the lookup stops and that position is
* used for the next tag in the output.
压缩器以所谓的“good_match”(良好匹配)值128开始。
它是一种“优先考虑速度而不是压缩率”的优化器。
因此,如果查看的第一个条目已经有128个或更多匹配的字符,则查找停止,并且该位置用于输出中的下一个标记。
*
* For each subsequent entry in the history list, the "good_match"
* is lowered by 10%. So the compressor will be more happy with
* short matches the farer it has to go back in the history.
* Another "speed against ratio" preference characteristic of
* the algorithm.
* 对于历史列表中的每个后续条目,“good_match”(良好匹配)值降低10%。因此,压缩器对于较短的匹配会更加满意,因为它需要在历史记录中回溯得更远。这是该算法的另一个“速度优先于比率”的偏好特征。
*
* Thus there are 3 stop conditions for the lookup of matches:
*
* - a match >= good_match is found
* - there are no more history entries to look at
* - the next history entry is already too far back
* to be coded into a tag.
* 因此,查找匹配的停止条件有三个:
*
* - 找到一个匹配 >= good_match(良好匹配)
* - 没有更多的历史条目可供查看
* - 下一个历史条目已经太远,无法编码为一个标记。
*
* Finally the match algorithm checks that at least a match
* of 3 or more bytes has been found, because that is the smallest
* amount of copy information to code into a tag. If so, a tag
* is omitted and all the input bytes covered by that are just
* scanned for the history add's, otherwise a literal character
* is omitted and only his history entry added.
* 最后,匹配算法会检查是否找到了至少3个或更多字节的匹配,因为这是编码为一个标记所需的最小的复制信息量。如果是这样,则会省略一个标记,并且只扫描该标记所覆盖的所有输入字节以添加到历史记录中;否则,会省略一个文字字符,并且只添加其历史记录条目。
*/
/* The decompression algorithm and internal data format:
*
* It is made with the compressed data itself.
*
* The data representation is easiest explained by describing
* the process of decompression.
* 通过描述解压缩过程,可以最容易地解释数据表示。
*
* If compressed_size == rawsize, then the data
* is stored uncompressed as plain bytes. Thus, the decompressor
* simply copies rawsize bytes to the destination.
如果compressed_size == rawsize,则数据以未压缩的原始字节形式存储。因此,解压缩器只需将rawsize字节复制到目标位置即可。
*
* Otherwise the first byte tells what to do the next 8 times.
* We call this the control byte.
* 否则,第一个字节会告诉我们在接下来的8次中应该做什么。我们将其称为控制字节。
*
* An unset bit in the control byte means, that one uncompressed
* byte follows, which is copied from input to output.
* 控制字节中未设置的位意味着,一个未压缩的字节紧随其后,从输入复制到输出。
*
* A set bit in the control byte means, that a tag of 2-3 bytes
* follows. A tag contains information to copy some bytes, that
* are already in the output buffer, to the current location in
* the output. Let's call the three tag bytes T1, T2 and T3. The
* position of the data to copy is coded as an offset from the
* actual output position.
* 控制字节中设置的位意味着,一个2-3字节的标记紧随其后。标记包含将输出缓冲区中已有的一些字节复制到输出当前位置的信息。让我们将这三个标记字节称为T1、T2和T3。要复制的数据的位置被编码为相对于实际输出位置的偏移量。
* The offset is in the upper nibble of T1 and in T2.
* The length is in the lower nibble of T1.
* 偏移量位于T1的上半部分和T2中。
* 长度位于T1的下半部分。
(注:原文中的“nibble”指的是4位二进制数,也就是半个字节。)
*
* So the 16 bits of a 2 byte tag are coded as
*
* 7---T1--0 7---T2--0
* OOOO LLLL OOOO OOOO
*
* This limits the offset to 1-4095 (12 bits) and the length
* to 3-18 (4 bits) because 3 is always added to it. To emit
* a tag of 2 bytes with a length of 2 only saves one control
* bit. But we lose one byte in the possible length of a tag.
* 因此,2字节标记的16位被编码为
*
* 7---T1--0 7---T2--0
* OOOO LLLL OOOO OOOO
*
* 这将偏移量限制为1-4095(12位),将长度限制为3-18(4位),因为总是要将3添加到长度上。要发出一个长度为2的2字节标记,只能节省一个控制位。但是我们在可能的标记长度上损失了一个字节。
*
* In the actual implementation, the 2 byte tag's length is
* limited to 3-17, because the value 0xF in the length nibble
* has special meaning. It means, that the next following
* byte (T3) has to be added to the length value of 18. That
* makes total limits of 1-4095 for offset and 3-273 for length.
* 在实际实现中,2字节标记的长度被限制为3-17,因为长度字节中的值0xF具有特殊含义。它意味着,接下来的字节(T3)必须添加到长度值18上。这使得偏移量的总限制为1-4095,长度的总限制为3-273。
*
* Now that we have successfully decoded a tag. We simply copy
* the output that occurred <offset> bytes back to the current
* output location in the specified <length>. Thus, a
* sequence of 200 spaces (think about bpchar fields) could be
* coded in 4 bytes. One literal space and a three byte tag to
* copy 199 bytes with a -1 offset. Whow - that's a compression
* rate of 98%! Well, the implementation needs to save the
* original data size too, so we need another 4 bytes for it
* and end up with a total compression rate of 96%, what's still
* worth a Whow.
* 现在我们已经成功解码了一个标记。我们只需将发生在<offset>字节之前的输出复制到当前输出位置的指定<length>中。因此,一个由200个空格组成的序列(想想bpchar字段)可以用4个字节编码。一个文字空格和一个三字节标记,以-1的偏移量复制199个字节。哇 - 压缩率达到了98%!好吧,实现还需要保存原始数据大小,所以我们还需要另外4个字节来保存它,最终的总压缩率为96%,这仍然值得哇。
*/
```
pglz压缩算法采用的是LZ77类似的压缩策略,相关介绍在:
字典压缩算法-LZ77介绍 - 知乎 (zhihu.com)
PGLZ是一种用于PostgreSQL数据库的压缩算法,其主要流程如下:
-
初始化:给定一个待压缩串source和压缩结果输出目标dest。
-
检查control byte:查看是否已经分配了control byte,如果没有,则在dest中分配一个control byte。
-
获取待压缩序列:从source中获取一个长度至少为3的尽量长的序列。
-
查找重复序列:在已压缩的source串中查找与待压缩序列相同的连续串。
-
写入control bit和偏移量:如果找到了重复序列,将control bit置为1,并将偏移量和长度写入dest。
-
写入原始字节:如果没有找到重复序列,将control bit置为0,并将待压缩序列的第一个字节直接写入dest。
-
重复步骤:重复步骤3至6,直到压缩完成source串中的所有字节为止。
需要注意的是,具体实现中可能包含更多的细节和优化,可以参考PostgreSQL的源代码或相关文档获取更多信息。
/*
* 将源数据直接压缩到输出缓冲区。
*/
while (dp < dend)
{
/*
* 如果我们已经超过了最大结果大小,失败。
*
* 我们每次循环检查一次;由于循环体可能发出多达4个字节(一个控制字节和3字节标签),PGLZ_MAX_OUTPUT()最好允许4个字节的冗余。
*/
if (bp - bstart >= result_max)
return -1;
/*
* 如果我们发出超过first_success_by字节而没有找到任何可压缩的数据,失败。这让我们在查看不可压缩的输入(如预压缩数据)时能够合理地快速退出。
*/
if (!found_match && bp - bstart >= strategy->first_success_by)
return -1;
/*
* 尝试在历史记录中查找匹配项
*/
if (pglz_find_match(hist_start, dp, dend, &match_len,
&match_off, good_match, good_drop, mask))
{
/*
* 创建标签并添加所有匹配字符的历史记录条目。
*/
pglz_out_tag(ctrlp, ctrlb, ctrl, bp, match_len, match_off);
while (match_len--)
{
pglz_hist_add(hist_start, hist_entries,
hist_next, hist_recycle,
dp, dend, mask);
dp++; /* 不要在上面那行做这个++! */
/* 该宏会执行四次 - Jan。 */
}
found_match = true;
}
else
{
/*
* 未找到匹配项。复制一个字面字节。
*/
pglz_out_literal(ctrlp, ctrlb, ctrl, bp, *dp);
pglz_hist_add(hist_start, hist_entries,
hist_next, hist_recycle,
dp, dend, mask);
dp++; /* 不要在上面那行做这个++! */
/* 该宏会执行四次 - Jan。 */
}
}
PGLZ算法,其解压流程如下:
-
初始化:给定一个待解压的压缩串source和解压结果输出目标dest。
-
读取control byte:从source中读取一个control byte,获取压缩信息。
-
检查control bit:查看control bit,判断是否有重复序列。
-
如果有重复序列:将control bit后面的偏移量和长度信息解析出来,根据偏移量在已经解压的dest中找到对应的重复序列,将其复制到dest的当前位置。
-
如果没有重复序列:将source中的下一个字节直接复制到dest的当前位置。
-
重复步骤:重复步骤2至5,直到解压完成source中的所有字节为止。
这里,我们对pglz的解压缩源码进行分析
/* ----------
* pglz_decompress -
*
* Decompresses source into dest. Returns the number of bytes
* decompressed in the destination buffer, and *optionally*
* checks that both the source and dest buffers have been
* fully read and written to, respectively.
将源数据解压缩到目标数据。返回解压缩后在目标缓冲区中的字节数,并可选地检查源缓冲区和目标缓冲区是否已被完全读取和写入。
* ----------
*/
int32
pglz_decompress(const char *source, int32 slen, char *dest,
int32 rawsize, bool check_complete)
{
const unsigned char *sp;
const unsigned char *srcend;
unsigned char *dp;
unsigned char *destend;
sp = (const unsigned char *) source; //源数据头部
srcend = ((const unsigned char *) source) + slen;//源数据尾部
dp = (unsigned char *) dest;//结果数据头部
destend = dp + rawsize;//结果数据尾部
while (sp < srcend && dp < destend)
{
/*
* Read one control byte and process the next 8 items (or as many as
* remain in the compressed input).
*/
unsigned char ctrl = *sp++; //读取一个字节的控制位
int ctrlc;
//对字节的8个位做判断
for (ctrlc = 0; ctrlc < 8 && sp < srcend && dp < destend; ctrlc++)
{
// 位值为1,则表示压缩,否则为自由字节,那么我们只需从输入复制到输出即可
if (ctrl & 1)
{
/*
* Otherwise it contains the match length minus 3 and the
* upper 4 bits of the offset. The next following byte
* contains the lower 8 bits of the offset. If the length is
* coded as 18, another extension tag byte tells how much
* longer the match really was (0-255).
| 控制字节T1 | T2 | T3 | T4 |
| 0000 0000 | 0000 1111 | 0000 0000| 0000 0000 |
T2的低4位记录长度len,这个长度还要加上3,如果len==18,那么len还有加上T4字节的值
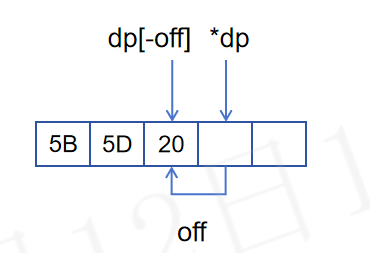
off由T2的高4位和T3字节的8位一起组成来决定 ,一共12位,表示off的长度,off表示目标数据头部向前的偏移位置
比如:off = 1,表示dp--所指向的值,
*/
int32 len;
int32 off;
len = (sp[0] & 0x0f) + 3;
off = ((sp[0] & 0xf0) << 4) | sp[1];
sp += 2;
if (len == 18)
len += *sp++;
/*
* Now we copy the bytes specified by the tag from OUTPUT to
* OUTPUT. It is dangerous and platform dependent to use
* memcpy() here, because the copied areas could overlap
* extremely!
*/
len = Min(len, destend - dp);
while (len--)
{
*dp = dp[-off];
dp++;
}
}
else
{
/*
* An unset control bit means LITERAL BYTE. So we just copy
* one from INPUT to OUTPUT.
*/
*dp++ = *sp++;
}
/*
* Advance the control bit
*/
ctrl >>= 1;
}
}
/*
* Check we decompressed the right amount. If we are slicing, then we
* won't necessarily be at the end of the source or dest buffers when we
* hit a stop, so we don't test them.
*/
//这里是判断是一个完整的压缩数据,还是部分(toast压缩后分片的数据)
if (check_complete && (dp != destend || sp != srcend))
return -1;
/*
* That's it.
*/
return (char *) dp - dest;
}
pglz_decompress中的off,指的是 dp所指向的位置向前移动的距离,dp[-off]示意图如下:
pglz会对超过2000字节的数据,进行压缩,若压缩后依旧超过2000字节,那么会写入toast表















 2456
2456











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









