









 这篇博客详细介绍了MySQL的选择语句结构,包括选择语句的使用、聚合函数的应用,以及多表数据操作,如子查询和连接查询。内容涵盖where、group by、having、order by和limit等子句,还探讨了子查询的不同类型和连接查询的三种形式:自然连接、左连接和右连接。
这篇博客详细介绍了MySQL的选择语句结构,包括选择语句的使用、聚合函数的应用,以及多表数据操作,如子查询和连接查询。内容涵盖where、group by、having、order by和limit等子句,还探讨了子查询的不同类型和连接查询的三种形式:自然连接、左连接和右连接。
目录
二,选择里的五个聚合函数(只能在 列名/列表达式、having里俩处使用)
Select 的语句结构
select 列名/列表达式 ④
from 表名
where 条件 ①
group by 分组列名(列值相同的分为一组) ②
having 条件(分组后对聚集函数的条件) ③
order by 排序列名(根据某一列进行排序) ⑤
limit 行数(限定显示的记录数) ⑥
执行顺序:WHERE子句->GROUP BY子句->HAVING子句->ORDER BY子句->SELECT子句->LIMIT子句
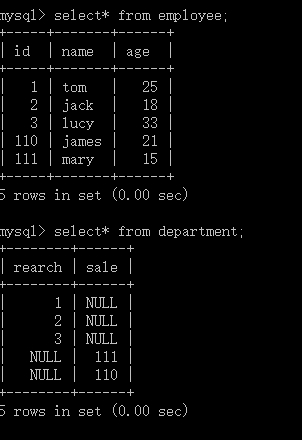
学习前准备好三个表的员工,部门,项目。
Empoyee
| ID(主键) | 名称 | 年龄 |
| 001 | 汤姆 | 25 |
| 002 | 插口 | 18 |
| 003 | 露西 | 33 |
| 111 | 结婚 | 15 |
| 110 | 詹姆士 | 21 |
department
| 元研究(外键) | 销售(外键) |
| 001 | 111 |
| 002 | 110 |
| 003 |
|
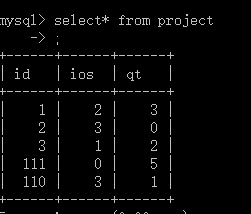
project
| ID(外键) | IOS(默认为0) | QT(默认为0) |
| 001 | 2 | 3 |
| 002 | 3 | 0 |
| 003 | 1 | 2 |
| 111 | 0 | 五 |
| 110 | 3 | 1 |
一,选择语句的使用
1.1选择语句的基本格式为:select DISTINCT(去除列值重复的行) 列名/列表达式(即对列的计算) as 别名... from 表名 +
限制条件(=,<,<=,>,> =,is null,is not null);
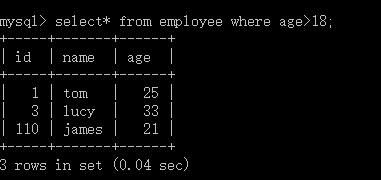
当我们要查看表中所有数据时将要查询列名部分改为*即可
当加上限制条件年龄> 18时可根据设置条件挑选表中数据
列表达式(即对列的计算) :select age*1.5 from employee where age>18
1.2“and”与“or”(在where里面使用):and表示并且,or表示或者 ;可把and理解为C ++里的&&,or理解为C ++的||
格式:select 列名 from 表名 where 条件1 and/or 条件2;
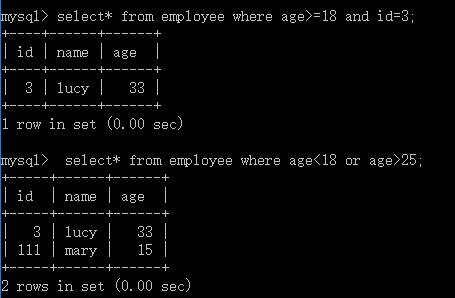
#挑选出年大于等于18并且id等于3的数据
#挑选出年小于18岁,或年龄大于25的数据
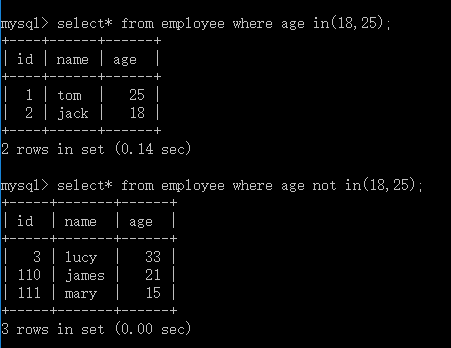
1.3 in和not in(在where里面使用):用于筛选数据表中“在”或“不在”某个范围内的数据。
between and和not between and(放在where后面使用):“在”或“不在”某个连续范围内的数据
格式:select 列名,... from 表名 where 列名 in/not in(范围1,范围2,......);
格式:select 列名, ... from 表名 where 列名 between/not between 起点值 and 终点值
between and可用来筛选时间类型数据如:查询新闻表中不是2013年发布的新闻情况
select * from news where time not between '2013-01-1' and '2013-12-31';
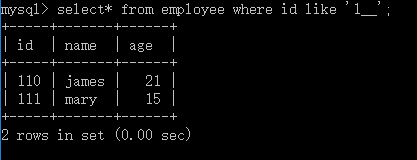
1.4通配符(在where里面使用):Key(关键):无论什么类型喜欢后面一定要加' '
格式:select 列名,... from 表名 where 列名 like '11 _'//查找11开头的数据
未知字符有俩个,分别是_和%,通常与像搭配使用,_表示一位未知字符,%表示n位未知字符。
比如,要只记得id第一位数为1,而后俩位忘记了,则可以用两个_通配符代替:
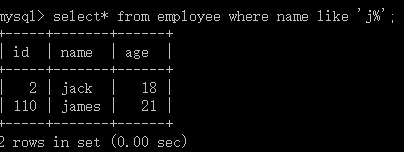
另一种情况,比如只记名字的首字母,又不知道名字长度,则用%通配符代替不定个字符:
从员工中选择*,其中名称为'j%';
这样就查找出了首字母为j的人:
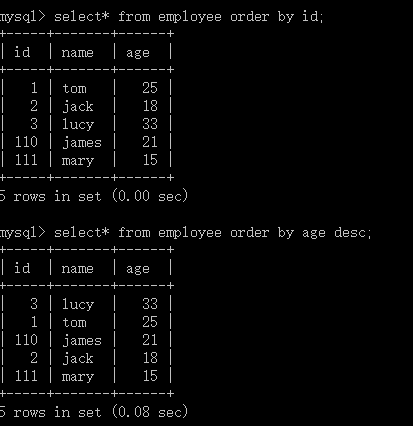
1.5对结果排序(order by):将数据表中的数据根据某一列来排序,默认为升序(asc),可设置为降序(desc);
一般放在哪里条件的后面,对查询后的结果进行分组。
格式:select 列名,... from 表名 order by 列名 asc / desc
1.6限制行数limit:用来限制查询结果的显示行数
格式:select * from 表名 .... limit 行数
格式:select * from 表名 .... limit 开始行数,行数 (行数从0开始记,即第一行行数为0)
二,选择里的五个聚合函数(只能在 列名/列表达式、having里俩处使用)
格式:select max(列名)as 自定义列别名,min(列名)from 表名;
重点:
count(*):某列里的空值记录也会计数
count(列名): 该列空值记录不会计数
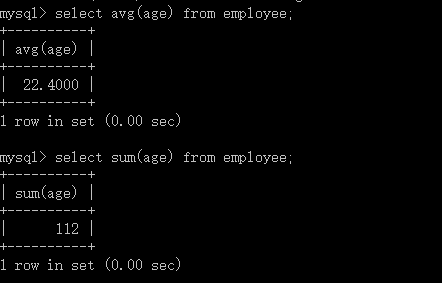
SQL允许对表中的数据进行计算的.sql有5个内置函数,这些函数都对选择的结果做操作:
函数名:count sum avg max min
作用:计数求和求平均值最大值最小值
count函数可用于任何数据类型(因为它只是计数),sum,avg函数只能对数字类数据类型做计算,max和min可用于数值,字符串或是日期时间数据类型。
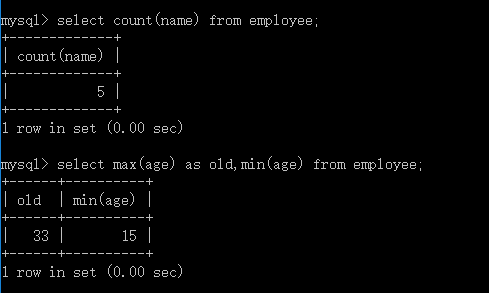
有一个细节你或许注意到了,使用作为关键词可以给显示的列重命名
三,俩张表或俩张表以上的数据操作
3.1子查询:在select语句里嵌套其它select语句,可在where、having、from里嵌套。
注意:from里嵌套需要给表起别名,与列别名格式一致。如:select * from (select id from a) as hh; 仍会显示原列名,
但必须给列起别名。
(一)子查询只返回一个列值(使用=)
如:select * from student where cid=(select cid from choose where cid='2');
(二)子查询返回的列值是一个范围(使用in)
对于这样的情况,我们可以用子查询:
如:想要知道名为“汤姆”的员工参与几个工程员工信息储存在员工表中,但工程信息储存在项目表中。
select id,qt from project where id in(select id from employee where name=‘Tom’);

(三)子查询的比较:以下关键字放在比较字符后面,表示与子查询后的列值进行比较。
any:只需要比该列其中一个值比较后满足算满足条件
all:需要比该列所有值比较后仍满足才算满足条件
如:查询选课人数最多的学生信息
select * from student where courseNum>=all(select courseNum from student);
3.2连接查询:将多个表连接起来联合查询
连接的基本思想是把两个或多个表合并成一个新的表来操作,如下:
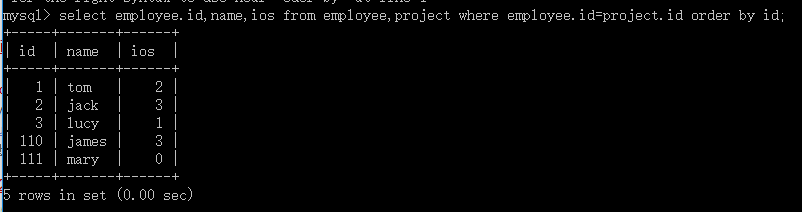
(一)自然连接查询:只显示符合查询条件的行(记录)
格式:select * from 表名 where 表1.列名=表2.列名;
select employee.id,name,ios from employee,project where employee.id = project.id order by id;
这条语句查询出的是,各员工的工程数目,其中员工的ID和名称来自员工表,IOS来自项目表:
(二)左连接查询:左连接所有行(记录)都会显示,并且显示俩个表中符合查询条件的行(记录)
格式:select * from 左表 left join 右表 on 左表.列名=右表.列名;
(三)右连接查询:右连接所有行(记录)都会显示,并且显示俩个表中符合查询条件的行(记录)
格式:select * from 左表 right join 右表 on 左表.列名=右表.列名;
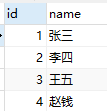
左/右连接查询需要以下俩张表(可以看到a表和b表中id值相等的记录只有俩行)
a表:
b表:

自然连接结果:
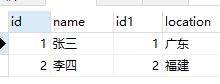
左连接结果:
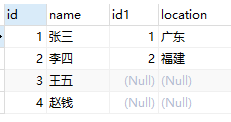
右连接结果(和自然连接一样是因为右表即b表只有俩行记录):

相关章节:
(一)https://blog.csdn.net/qq_38487155/article/details/79475851
(三)https://blog.csdn.net/qq_38487155/article/details/79508140
(四)https://blog.csdn.net/qq_38487155/article/details/79516314

















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









