







整合Springboot
通过虚拟机搭建ES,这里使用的版本是6.4.3,引入相应依赖
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-elasticsearch</artifactId>
# 使用2.2.2是为了对应ES的版本
<version>2.2.2.RELEASE</version>
</dependency>
引入依赖之后可以自行查看

spring:
data:
elasticsearch:
# 在es中配置的名称
cluster-name: es
# 如果是集群,用,分隔
cluster-nodes: 192.168.1.7:9300

测试实体类
package com.csea.entity;
import lombok.Data;
import org.springframework.data.annotation.Id;
import org.springframework.data.elasticsearch.annotations.Document;
import org.springframework.data.elasticsearch.annotations.Field;
/**
* @author Csea
* @title
*/
@Data
@Document(indexName = "merchant", type = "doc")
public class Merchant {
@Id
private Long merchantId;
// store = true 表示这是要存储的字段
@Field(store = true)
private String name;
@Field(store = true)
private String mob;
@Field(store = true)
private String address;
@Field(store = true)
private String descr;
}
创建索引(文档)
当索引不存在时候,会先创建索引,并将数据插入。
@Autowired
private ElasticsearchTemplate elasticsearchTemplate;
@Test
public void createIndex() {
Merchant merchant = new Merchant();
merchant.setMerchantId(1001L);
merchant.setName("Csea-杂货铺1");
merchant.setAddress("大道8888号");
merchant.setDescr("好吃的不得了");
merchant.setMob("13899999999");
IndexQuery indexQuery = new IndexQueryBuilder().withObject(merchant).build();
elasticsearchTemplate.index(indexQuery);
}
执行完之后可以看到merchant索引已经创建,并且文档也新增了。


更新文档
@Test
public void updateMerchantDoc() {
Map<String, Object> sourceMap = new HashMap<>();
sourceMap.put("name", "Csea-杂货铺-update");
sourceMap.put("adress", "光明大道8888号");
sourceMap.put("descr", "好吃你就多吃点!~");
IndexRequest indexRequest = new IndexRequest();
indexRequest.source(sourceMap);
UpdateQuery query = new UpdateQueryBuilder().withClass(Merchant.class)
.withId("1001")
.withIndexRequest(indexRequest)
.build();
elasticsearchTemplate.update(query);
}

查询文档
@Test
public void queryMerchantDoc() {
GetQuery query = new GetQuery();
query.setId("1001");
Merchant merchant = elasticsearchTemplate.queryForObject(query, Merchant.class);
log.info("查询到的数据是={}", merchant);
}
com.test.ESTest : 查询到的数据是=Merchant(merchantId=1001, name=Csea-杂货铺-update, mob=13899999999, address=大道8888号, descr=好吃你就多吃点!~)
删除文档数据
@Test
public void delMerchantDoc() {
elasticsearchTemplate.delete(Merchant.class, "1001");
}
分页文档查询
@Test
public void searchPageMerchantDoc() {
Pageable pageable = PageRequest.of(0, 20);
SearchQuery query = new NativeSearchQueryBuilder()
.withQuery(QueryBuilders.matchQuery("description", "God Engineer "))
.withPageable(pageable)
.build();
AggregatedPage<Merchant> merchants = elasticsearchTemplate.queryForPage(query, Merchant.class);
List<Merchant> content = merchants.getContent();
for (Merchant merchant : content) {
log.info("查询到的文档为:{}", merchant);
}
}
高亮分页查询
@Test
public void searchHightMerchantDoc() {
String preTag = "<font color='red'>";
String postTg = "</font>";
Pageable pageable = PageRequest.of(0, 20);
// 排序
SortBuilder sortBuilder = new FieldSortBuilder("name")
.order(SortOrder.DESC);
SearchQuery query = new NativeSearchQueryBuilder()
// 查询的字段
.withQuery(QueryBuilders.matchQuery("mob", "88"))
.withHighlightFields(new HighlightBuilder.Field("mob")
.preTags(preTag)
.postTags(postTg))
.withSort(sortBuilder)
.withPageable(pageable)
.build();
AggregatedPage<Merchant> merchants = elasticsearchTemplate.queryForPage(query, Merchant.class,
new SearchResultMapper() {
@Override
public <T> AggregatedPage<T> mapResults(SearchResponse response, Class<T> aClass, Pageable pageable) {
SearchHits hits = response.getHits();
List<Merchant> stuList = new ArrayList<>();
for (SearchHit hit : hits) {
HighlightField highlightField = hit.getHighlightFields().get("mob");
String mob = highlightField.getFragments()[0].toString();
Object merchantId = hit.getSourceAsMap().get("merchantId");
String name = (String) hit.getSourceAsMap().get("name");
String descr = (String) hit.getSourceAsMap().get("descr");
String address = (String) hit.getSourceAsMap().get("address");
Merchant merchantHL = new Merchant();
merchantHL.setDescr(descr);
merchantHL.setMerchantId(Long.valueOf(merchantId.toString()));
merchantHL.setName(name);
merchantHL.setMob(mob);
merchantHL.setAddress(address);
stuList.add(merchantHL);
}
if (!stuList.isEmpty()) {
return new AggregatedPageImpl<>((List<T>) stuList);
}
return null;
}
});
log.info("分页总数:{}", merchants.getTotalPages());
List<Merchant> content = merchants.getContent();
for (Merchant merchant : content) {
log.info("分页文档数据:{}", merchant);
}
}
删除索引
@Test
public void deleteDelMerchantIndex() {
elasticsearchTemplate.deleteIndex(Merchant.class);
}
小结
不建议使用ElasticsearchTemplate对索引进行管理(创建索引、更新映射、删除索引),因为就像使用Mysql,不会通过java代码去改变表结构,ES也是如此,更多是用来进行CRUD操作。
Logstash
概念
- 作为数据采集的工具;
- 以id或update_time作为同步边界;
以id同步:初次同步的时候会将所有数据同步过来,之后logstash的定时任务回去检查,比如上次同步到id为2000的数据,那么这次就同步2000之后的数据,使用id作为同步有很大的弊端,就只只能新增数据,无法更新。
以update_time同步:初次同步就将所有的数据同步过来,之后如果有新增或更新的操作,那么就把以上一次更新时间为界,之后的数据全部做一次新增或更新。 - 使用logstash-input-jdbd插件同步;
- 使用logstash需要跟ES的版本保持一致,比如两者都要是6.4.3版本;
- 同步数据时,需要事先创建索引。
安装配置
logstash下载地址
上传并解压,再上传mysql的驱动jar包,以及jdk(logstash需要jdk)

cd进入logstash目录之后,创建文件夹
mkdir sync
进入sync目录,创建配置文件
# 先创建同步配置文件
vim logstash-db-sync.conf
# 拷贝数据库驱动到该路径下
cp /usr/local/mysql-connector-java-8.0.13.jar .
修改logstash-db-sync.conf
input {
jdbc {
# 设置Mysql/MariaDB 数据库url以及数据库名称
jdbc_connection_string => "jdbc:mysql://192.168.1.6:3306/xxg?serverTimezone=Asia/Shanghai&characterEncoding=utf8&useSSL=false"
# 数据库用户名密码
jdbc_user => "root"
jdbc_password => "123456"
# 数据库驱动所在位置,可以是绝对路径或相对路径
#jdbc_driver_library => "/usr/local/logstash-6.4.3/sync/mysql-connector-java-5.1.49.jar"
jdbc_driver_library => "/usr/local/logstash-6.4.3/sync/mysql-connector-java-8.0.13.jar"
# 驱动类名
#jdbc_driver_class => "com.mysql.jdbc.Driver"
jdbc_driver_class => "com.mysql.cj.jdbc.Driver"
# 开启分页
jdbc_paging_enabled => "true"
# 分页每页数量,可以自定义
jdbc_page_size => "10000"
# 执行的sql文件路径
statement_filepath => "/usr/local/logstash-6.4.3/sync/product.sql"
# 设置定时任务间隔
schedule => "* * * * *"
# 索引类型
type => "_doc"
# 是否开启记录上次追踪的结构,也就是上次更新的实际,这个会记录到 last_run_metadata_path 的文件
use_column_value => true
# 记录上一次追踪的结果值
last_run_metadata_path => "/usr/local/logstash-6.4.3/sync/track_time"
# 如果 use_column_value 为true,配置本参数,追踪的colume名,可以是自增id或者时间
tracking_column => "update_time"
# tracking_column 对应字段的类型
tracking_column_type => "timestamp"
# 是否清除 last_run_metadata_path 的记录,true则每次都从头开始查询所有
clean_run => false
# 数据库字段名称大写转小写
lowercase_column_names => false
}
}
output {
elasticsearch {
# es地址
hosts => ["192.168.1.7:9200"]
# 同步索引名
index => "product"
# 设置_docID和数据相同,按照执行sql中的字段来
document_id => "%{product_id}"
}
# 日志输出
stdout {
codec => json_lines
}
}
添加执行同步查询的sql脚本
vim product.sql
SELECT
*
FROM
jh_product
WHERE
is_delete = 0
AND update_time >= :sql_last_value
:sql_last_value是logstash中要赋值的地方,可以理解为占位符
启动logstash,先cd到目录下的bin目录
./logstash -f /usr/local/logstash-6.4.3/sync/logstash-db-sync.conf
启动之后就可以看到数据同步过去,在ES的索引中查看数据
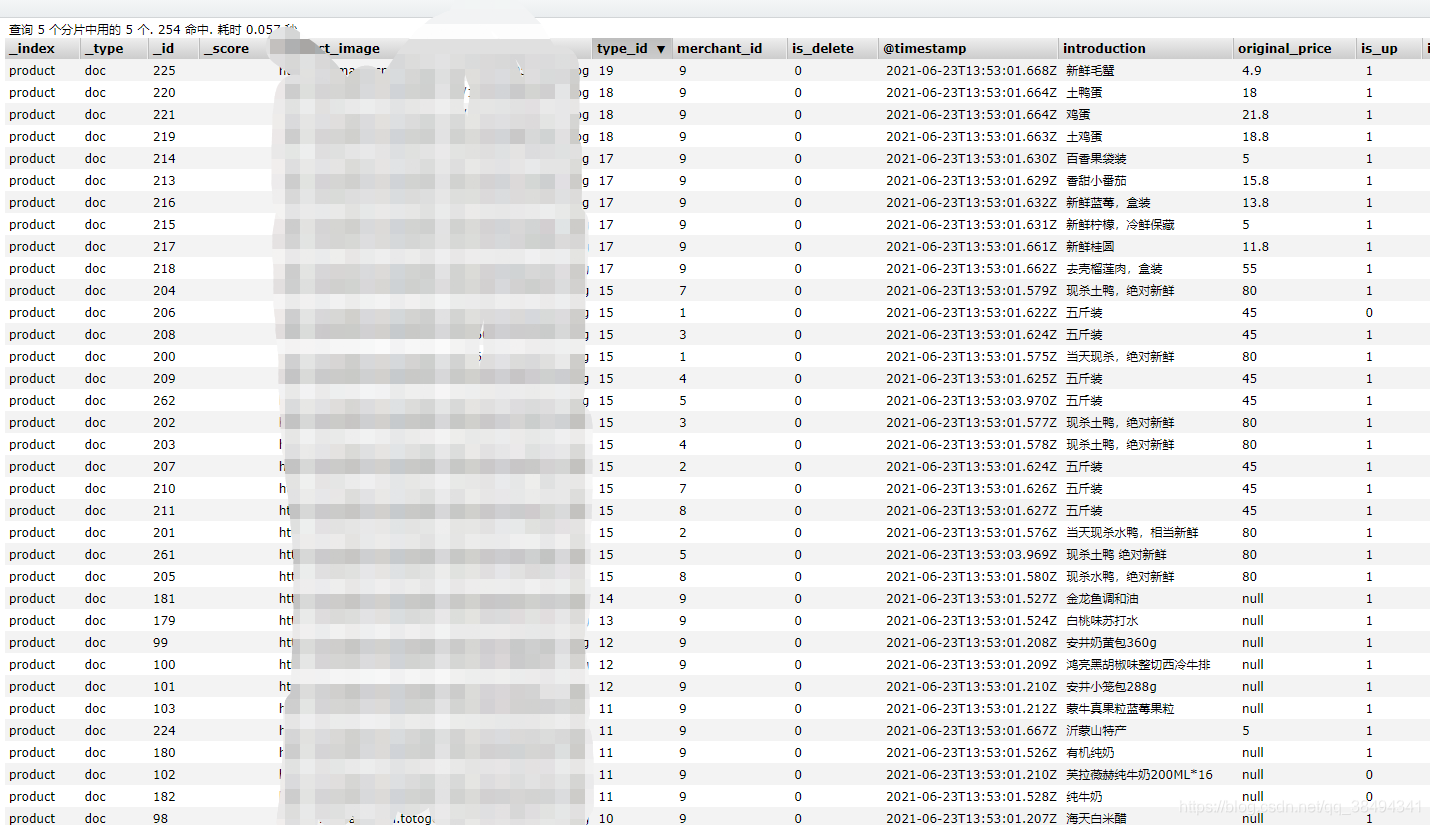
自定义模板
因为需要用到中文分词,所以需要自定义模板
Get:http://{IP}:{port}/_template/logstash
查看模板信息

将拿到的template复制出来进行自定义修改
{
"order": 10,
"version": 1,
"index_patterns": ["*"],
"settings": {
"index": {
"refresh_interval": "5s"
}
},
"mappings": {
"_default_": {
"dynamic_templates": [
{
"message_field": {
"path_match": "message",
"match_mapping_type": "string",
"mapping": {
"type": "text",
"norms": false
}
}
},
{
"string_fields": {
"match": "*",
"match_mapping_type": "string",
"mapping": {
"type": "text",
"norms": false,
"analyzer": "ik_max_word",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
}
}
}
],
"properties": {
"@timestamp": {
"type": "date"
},
"@version": {
"type": "keyword"
},
"geoip": {
"dynamic": true,
"properties": {
"ip": {
"type": "ip"
},
"location": {
"type": "geo_point"
},
"latitude": {
"type": "half_float"
},
"longitude": {
"type": "half_float"
}
}
}
}
}
},
"aliases": {}
}
创建完毕之后,在logstash目录的sync下创建新的json文件
vim logstash-ik.json
将自定义模板内容放入json文件中
然后修改logstash-db-sync.conf 配置,在output中添加如下配置,保存之后,重启logstash即可
output {
elasticsearch {
# 定义模板名称
template_name => "myik"
# 模板所在位置
template => "/usr/local/logstash-6.4.3/sync/logstash-ik.json"
# 重写模板
template_overwrite => true
#默认为true,false关闭logstash自动管理模板功能,如果自定义模板,则设置false
manage_template => false
}
}
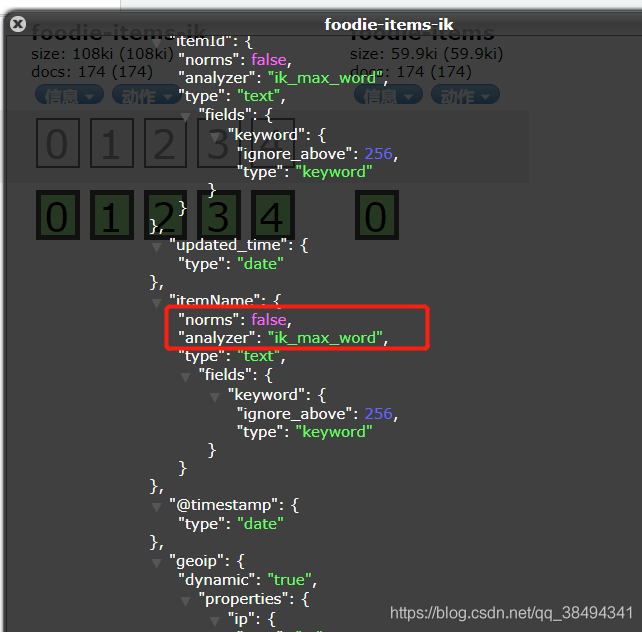
中文分词不生效
如果出现中文分词"analyzer": "ik_max_word"不生效的情况可以先将manage_template改为true,然后启动logstash同步,同步之后,使用:
Get:http://{IP}:{port}/_template/{template名称}
来查看模板是否已经上传到es
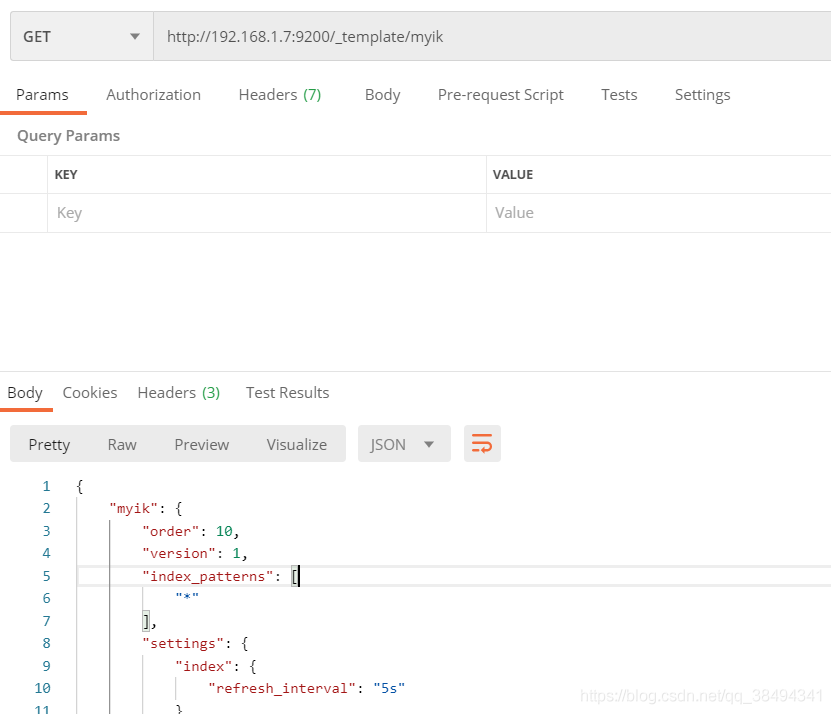
同步之后将manage_template改为false,重新同步即可。
主要就是模板没有被上传到ES导致的。
另外可以修改模板中order的值,值越大,在 merge 规则的时候优先级越高。














 487
487











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









