






The Visual Microphone: Passive Recovery of Sound from Video
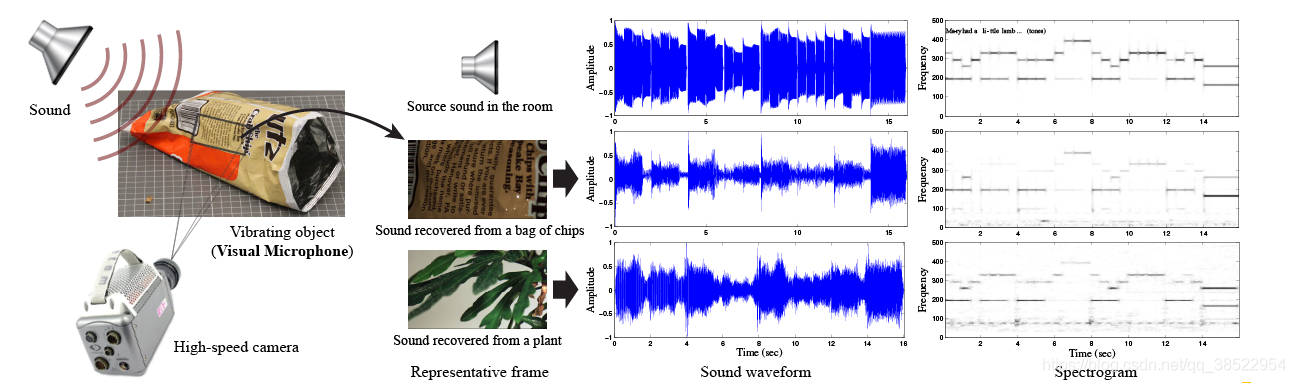
Abstract
当声音撞击物体时,会引起物体表面的轻微振动。我们展示了如何仅使用物体的高速视频,就能提取这些微小的振动,并部分地恢复产生这些振动的声音,使我们能够将日常物体比如一杯水、一盆植物、一盒纸巾或一袋芯片–变成一个可视麦克风。我们从不同属性的物体的高速镜头中恢复声音,并使用真实数据和模拟数据来检查影响我们视觉恢复声音能力的一些因素。我们使用可理解度和信噪比指标评估恢复后的声音质量,并提供输入和恢复后的音频样本进行直接比较。我们还探索了如何利用普通消费相机的卷帘门从标准帧率视频中恢复音频,并使用我们的方法的空间分辨率来可视化与声音相关的振动在物体表面的变化,我们可以用它来恢复物体的振动模式。
1 Introduction
声波是在介质中传播的压力波动。当声音击中一个物体时,它会使该物体的表面移动。根据不同的条件,表面可能会随着周围介质的运动或根据其振动模式变形。在这两种情况下,运动模式都包含有用的信息,可以用来恢复声音或了解物体的结构。声波是在介质中传播的压力波动。
我们的方法通常不能像主动测量声音和振动那样恢复声音,但它确实提供了一些优势。特别是,它不需要对纹理对象和光照良好的场景进行主动照明(图2),并且不依赖于高速摄像机之外的其他传感器或检测模块。它也不要求振动表面是反反射的或镜面的(激光麦克风经常需要),也没有对相机的表面方向施加明显的限制。此外,由于我们的方法产生了声音的空间测量(视频中每个像素的估计音频信号),我们可以使用它来分析声音引起的物体变形。
虽然声音可以通过大多数物质传播,但并不是所有的物体和材料对视觉声音恢复都有同样好的效果。声波在材料中的传播取决于多种因素,如材料的密度和压缩性,以及物体的形状。我们进行了对照实验,测量了不同物体和材料对已知和未知声音的反应,并评估了我们利用我们的技术从高速视频中恢复这些声音的能力。
我们首先详细描述我们的技术,并在各种不同的物体和声音上显示结果。然后,我们通过观察校准实验和模拟的数据来描述我们的技术的行为和限制。最后,我们利用CMOS传感器的卷帘门来展示如何使用具有标准帧率的普通消费相机来恢复声音。
2 Related Work
传统麦克风的工作原理是将内部膜片的运动转化为电信号。膜片被设计成容易随声压移动,以便其运动可以被记录和解释为音频。激光麦克风的工作原理与此类似,但它测量的是远处物体的运动,本质上是将物体作为一个外部膜片。这是通过记录激光射向物体表面的反射来实现的。最基本的激光麦克风记录了反射激光的相位,使物体的s距离模量为激光的s波长。激光多普勒振动计(LDV)通过测量反射激光的多普勒位移来确定反射表面的速度,解决了相位包绕的模糊性[Rothberg等,1989]。两种类型的激光麦克风都可以从很远的地方恢复高质量的音频,但这依赖于激光和接收器相对于具有适当反射率的表面的精确定位。
Zalevsky等人[2009]通过使用失焦高速相机记录反射激光散斑模式的变化,解决了其中的一些限制。他们的工作使接收器的定位更加灵活,但仍然依赖于记录反射激光。相反,我们的技术不依赖于主动照明。
由于我们的方法依赖于从视频中提取极其细微的运动,这也与最近放大和可视化此类运动的工作有关[Wu et al. 2012;Wadhwa et al. 2013;Wadhwa et al. 2014;Rubinstein 2014]。这些工作的重点是可视化的小运动,而在这篇论文中,我们的重点是测量这些运动和使用他们来恢复声音。我们工作中使用的局部运动信号来自Simoncelli等人[1992]提出的复杂可操纵金字塔中的相位变化,因为这些变化被证明非常适合在视频中恢复小运动[Wadhwa等人,2013]。然而,也可以使用其他技术计算局部运动信号。例如,经典的光流和点相关方法在以往的视觉振动传感工作中得到了成功的应用[Morlier et al. 2007;D Emilia等,2013]。在我们的例子中,由于我们的输出是单个振动对象的一维运动信号,所以我们能够对输入视频中的所有像素进行平均,并处理非常细微的运动,大约是千分之一像素。
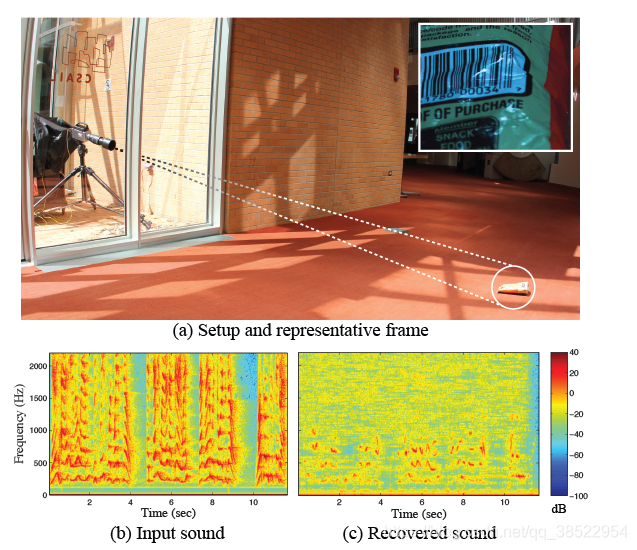
图2:语音恢复从一个4千赫的视频包芯片通过隔音玻璃拍摄。芯片袋(位于(a)右下角的地板上)仅由自然光照射。相机(在(a)的左边)被放置在房间外面厚厚的隔音玻璃后面。从录制的视频(400*480像素)的单一帧显示在插图中。玛丽有一个小羊羔…欢迎来到SIGGRAPH !是薯片袋旁边的一个人说的。(b)及©分别显示由晶片袋旁的标准麦克风录得的声源声谱图,以及我们回收的声源声谱图。恢复的声音是嘈杂的,但可以理解的(音频剪辑可以在项目网页上找到)。
3 Recovering Sound from Video
译文:图3给出了可视麦克风工作原理的高级概述。输入的声音(我们想要恢复的信号)由某些物体表面气压的波动组成。这些波动会导致物体移动,随着时间的推移,会产生一种位移模式,我们用相机记录下来。然后我们用我们的算法处理录制的视频,以恢复输出的声音。
译文:我们方法的输入是一个对象的视频V (x, y, t)在本节中,我们考虑高速视频(1kHz-20kHz)。较低的帧速率将在第6节中讨论。我们假设物体和相机的相对运动是由声音信号s(t)引起的振动控制的。我们的目标是从视频V中恢复声音信号s(t)。
我们分三步进行。首先,我们将V输入视频分解成空间部分波段对应不同方向θ和音阶r。然后我们在每一个像素计算当地的运动信号,方向,和规模。我们通过一系列的平均值和对齐操作将这些运动信号组合起来,为对象生成一个单一的全局运动信号。最后,我们将音频去噪和滤波技术应用于目标的运动信号中,得到我们的恢复声音。
3.1 Computing Local Motion Signals
在视频V的复杂可操纵金字塔表示中,我们使用相位变化来计算局部运动。复杂可操纵金字塔[Simoncelli et al. 1992;Portilla and Simoncelli 2000]是一个滤波器组,它将视频V (x, y, t)的每一帧分割成对应于不同尺度和方向的复值子带。这个变换的基函数是缩放的以及具有余弦和正弦相位分量的定向哈博样小波。每一对余弦滤波器和正弦滤波器都可以用来分离局部小波的振幅和相位。具体来说,每个规模r和θ方向是一个复杂的形象,可以表达的振幅和相位ϕ为
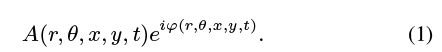
我们局部阶段ϕ计算方程和减去他们的当地阶段参考系t0(通常是视频的第一帧)计算相位变化

对于微小运动,这些相位变化与图像结构沿相应方向和尺度的位移近似成正比[Gautama and Van Hulle 2002]。
3.2 Computing the Global Motion Signal
复杂的可操纵金字塔振幅A给出了纹理强度的度量,因此我们用它的(平方)振幅来衡量每个局部信号每个方向θ和规模r复杂的可操纵的金字塔分解的视频,我们计算空间加权平均当地的运动信号产生一个运动信号Φ(r,θ,t)我们进行加权平均,因为当地的阶段是模棱两可的地区没有太多纹理,因此运动信号在这些地区是很嘈杂的。复杂的可操纵金字塔振幅A给出了纹理强度的度量,因此我们用它的(平方)振幅来衡量每个局部信号:
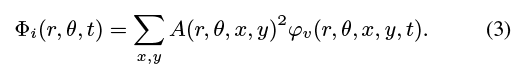
在平均Φ(r,θ,t)在不同尺度和方向,我们使他们暂时为了防止破坏性的干扰。复杂的可操纵金字塔振幅A给出了纹理强度的度量,因此我们用它的(平方)振幅来衡量每个局部信号要理解为什么要这样做,考虑这样一种情况:我们想要从一个空间尺度组合两个方向(x和y)。现在,考虑一个在y = x方向上振动的小高斯函数,这里,x和y方向相位的变化是负相关的,总是和一个恒定的信号相加。然而,如果我们将两个相位信号对齐(通过及时移动其中一个),我们可以使相位建设性地相加。的信号对齐Φ(riθi t ti),这样:
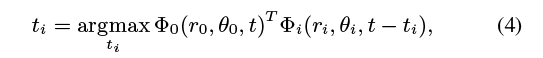
我所有scale-orientation索引对(r,θ),和Φ0 (r0,θ0,t)是任意选择的参考的规模和方向。复杂的可操纵金字塔振幅A给出了纹理强度的度量,因此我们用它的(平方)振幅来衡量每个局部信号Liu等人在2005年使用了类似的相关度量对相关运动进行聚类以获得运动放大。
我们的全局运动信号为:
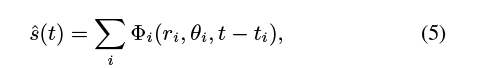
which we scale and center to the range [−1, 1].
3.3 Denoising
我们进一步处理恢复的全局运动信号,以提高其信噪比。在很多视频中,我们注意到低频的高能噪声通常与音频不相对应。我们通过应用一个高通巴特沃思滤波器来解决这个问题,它的截止频率为20-100Hz(对于大多数例子,是奈奎斯特频率的1/20)。
我们对额外去噪算法的选择取决于我们的目标应用程序,无论我们关注的是准确性还是可理解性。复杂的可操纵金字塔振幅A给出了纹理强度的度量,因此我们用它的(平方)振幅来衡量每个局部信号对于精确定位的应用,我们使用了我们自己实现的一种技术,称为光谱减法[Boll 1979]。对于可理解性,我们使用了一种基于感知动机的语音增强算法[Loizou 2005],其工作原理是计算去噪信号的贝叶斯最优估计,其代价函数考虑了人类对语音的感知。本文给出的所有结果都是用这两种算法中的一种自动去噪的。我们的结果可能会进一步改善使用更复杂的音频去噪算法可用的专业音频处理软件(其中一些需要手动交互)。
不同频率的恢复信号可能会被不同的记录对象调制。复杂的可操纵金字塔振幅A给出了纹理强度的度量,因此我们用它的(平方)振幅来衡量每个局部信号在4.3节中,我们展示了如何使用一个已知的测试信号来描述一个对象如何衰减不同的频率,然后使用这个信息来均衡新视频中从同一对象(或相似对象)恢复的未知信号。
4 Experiments
我们做了各种实验来测试我们的技术。这部分的所有视频都是在室内用幻影V10高速摄像机录制的。这些实验的设置由一个物体、一个扬声器和一个相机组成,如图4所示。为了避免接触振动,扬声器总是被放置在独立的支架上,与支撑物体的表面分开。这些物体用照明灯照明,在0.5米到2米的距离内拍摄。在其他实验中,我们不用照明灯(如图2)就可以从更远的地方恢复声音,视频帧率在2kHz-20kHz之间,分辨率从192x192像素到700x700像素不等。声音的音量从80分贝(演员的舞台声音)到110分贝(相当于100米高空的喷气发动机)不等。较低的卷在第5节(图2)和web页面上的其他实验中进行了探讨。视频处理采用4个尺度和2个方向的复杂可操纵金字塔,我们使用公共可用的Portilla和Simoncelli代码计算[2000]。在一台拥有两个3.46GHz处理器和32GB内存的机器上,使用MATLAB处理每个视频通常需要2到3个小时。

这是我们控制实验装置的一个例子。来自音源的声音,如扬声器(a)激发普通物体(b)。高速摄像机©记录物体。然后我们从录制的视频中恢复声音。为了将不期望的振动最小化,这些物体被放置在一个沉重的光学板上,在涉及扬声器的实验中,我们将扬声器放置在一个与包含这些物体的表面分离的表面上,置于一个隔声器的顶部。
我们的第一组实验测试了可以从不同物体上恢复的频率范围。我们通过扬声器播放一个线性的频率斜坡,然后看看哪些频率可以通过我们的技术恢复。第二组实验侧重于从视频中恢复人类语言。在这些实验中,我们使用了TIMIT数据集[Fisher et al. 1986]中通过扬声器播放的几个标准语音示例,以及来自人类受试者的实时语音(此处图4中的扬声器被一个会说话的人替换)。这些实验和其他实验的音频可以在项目网站上找到。我们的结果是最好的体验通过耳机听伴音文件。
4.1 Sound Recovery from Different Objects/Materials
在第一组实验中,我们播放一个斜坡信号,它由一个正弦波组成,它的频率随时间呈线性增长,作用于不同的物体。图5(a)显示了我们输入声音的频谱图,它在5秒内从100Hz增加到1000Hz。图5(b)为从2.2kHz不同材质物体视频中恢复的信号谱图。图5(b)顶部的砖块被用作一个控制实验,由于对象是刚性和重的,我们期望恢复的信号很少。低频信号恢复的砖(见砖的声谱图可视化图5 (b))可能来自运动砖或相机,但这个信号很弱的事实表明,摄像机运动和其他意想不到的因素在实验设置最多一个次要的影响我们的结果。特别是,虽然几乎没有从砖块中恢复任何信号,但是从显示的其他对象中恢复的信号要好得多。
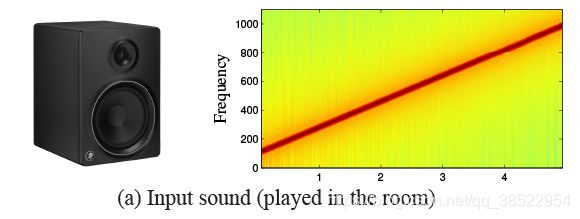
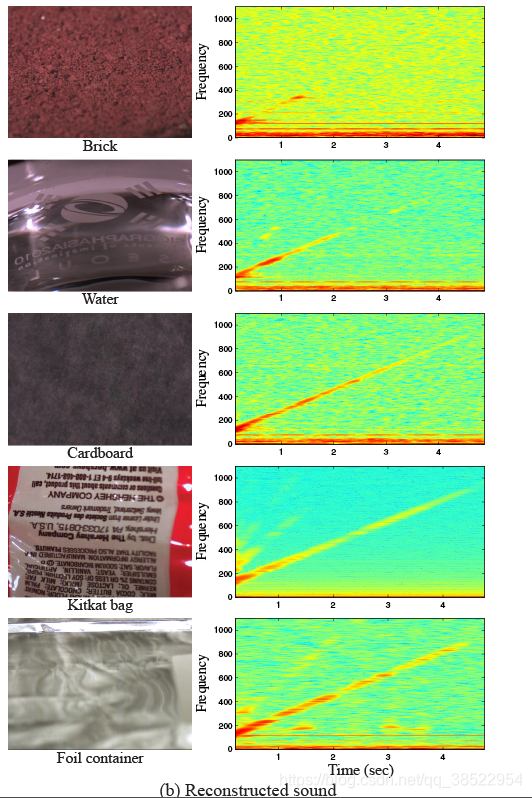
图五:声音由不同的物体和材料重建而成。通过扬声器(a)播放100 - 1000Hz的线性斜坡,并根据不同的物体和材料(b)进行重构。在水中,摄像机对准了一个盛有水的透明马克杯的一侧,水面刚好在马克杯一侧印有商标的上方。水面的运动导致折射和镜面反射的变化。更多细节可以在我们的项目网页上找到。
几乎在我们所有的结果中,恢复的信号在较高的频率下较弱。这是可以预料的,因为更高的频率产生更小的位移,并被大多数材料衰减得更严重。我们在第5节用激光多普勒振动计的数据更明确地说明了这一点。然而,随着频率的增加,功率的降低并不是单调的,这可能是由于振型的激励作用。毫不奇怪,更轻的物体更容易移动,比更惰性的物体更容易恢复更高的频率。
4.2 Speech Recovery
语音恢复是视觉麦克风的一个令人兴奋的应用。来测试我们的能力恢复语音我们使用标准的语音TIMIT数据集的例子(费舍尔et al . 1986年),以及现场演讲从人类议长背诵这首诗玛丽有只小羊羔,在引用第一个单词在1877年由托马斯爱迪生的留声机。更多的语音实验可以在项目网站上找到。
在我们大部分的语音恢复实验中,我们以2200 fps的速度拍摄了一袋芯片,空间分辨率为700*700像素。恢复的信号用感知动机语音增强算法去噪[Loizou 2005],见第3.3节。
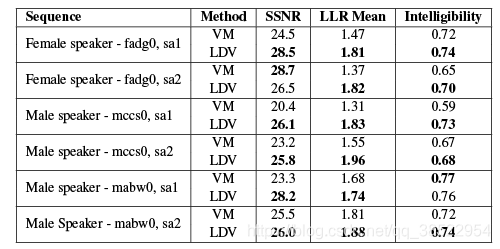
评估我们重建语音的最好方法是听附在我们项目网站上的音频文件。除了提供这些音频文件,我们还使用来自音频处理社区的量化度量来评估结果。为了测量精度,我们使用了分段信噪比(SSNR) [Hansen and Pellom 1998],它平均了一段时间内的局部信噪比。为了测量可理解性,我们使用了Taal等人的基于感知的度量标准[2011]。对于表1中的结果,我们还包括Log似然比(LLR) [Quackenbush et al. 1988],它是一个度量方法,用于捕获恢复后的信号的光谱形状与原始干净信号的光谱形状的匹配程度。最后,通过查看输入语音和恢复信号的频谱图,可以直观地评估我们的结果,如图6所示。
在我们视频的Nyquist频率下,恢复的信号与预先录制和现场语音的输入非常匹配。在一个实验中,我们以每秒20,000帧的速度捕获了一袋芯片,并能够恢复一些较高的语音频率(图6,右下角)。帧率越高,曝光时间越短,图像噪声也就越大,这就是为什么得到的图像比2200Hz时的图像噪声更大。然而,即使有了这些额外的噪音,我们仍然能够定性地理解重建音频中的语音。
在我们视频的Nyquist频率下,恢复的信号与预先录制和现场语音的输入非常匹配。在一个实验中,我们以每秒20,000帧的速度捕获了一袋芯片,并能够恢复一些较高的语音频率(图6,右下角)。帧率越高,曝光时间越短,图像噪声也就越大,这就是为什么得到的图像比2200Hz时的图像噪声更大。然而,即使有了这些额外的噪音,我们仍然能够定性地理解重建音频中的语音。
我们还将结果与激光多普勒振动计恢复的音频进行了比较(表1)。我们的方法以与视频相同的采样速率恢复了与激光振动计相当的音频,并通过可懂度度量进行了测量。然而,LDV需要主动照明,我们必须在物体上粘贴一块反光带,让激光从物体上反弹回来,回到振动计。如果没有反光带,测振仪信号的质量会明显变差。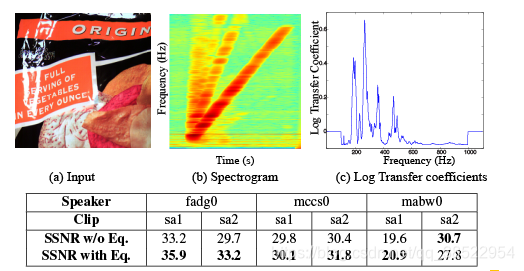
表2:我们使用已知的斜坡信号来估计一袋芯片的传输系数。然后我们使用这些传递系数来平衡从同一个袋子中恢复的未知信号。a)从一帧视频中取出一包薯条。b)恢复的斜坡信号,我们用来计算传递系数。c)对数传输系数(设置为1,在我们斜坡的频率范围之外)。
表中给出了6个带均衡和不带均衡的语音例子的信噪比。在均衡后再次应用谱减法,因为增加衰减频率也会增加这些频率的噪声。注意,这里报告的去噪方法SSNR值与表1不同,因为我们的均等化关注的是精度而不是可理解性(详见文本)。
4.3 Transfer Functions and Equalization
我们可以使用4.1节中的ramp信号来表征一个对象的(视觉)频响,以提高从该对象的新观测中恢复的信号的质量。理论上,如果我们认为对象的线性系统,可以使用维纳反褶积估计的复数传递函数与该系统相关联,并且传递函数可以用来deconvolve新的观测信号以一种最优的方式(在均方误差意义上的)。然而,在实践中,这种方法可能非常容易受到噪声和非线性伪影的影响。相反,我们描述了一种更简单的方法,首先使用训练示例的短时间傅里叶变换(线性斜坡)粗略地计算频率传输系数,然后使用这些传输系数均衡新的观测信号。
我们的转移系数的短时功率谱中提取出来的一对输入/输出的信号(如图5所示的)。每个系数对应于频率的短时间观察训练信号的功率谱,并计算加权平均频率的s级。每次的权值由对准输入训练信号的短时功率谱给出。假设我们的输入信号一次只包含一个频率,这个加权方案忽略了非线性伪影,如图2(b)所示的倍频。
一旦我们有了传递系数我们就可以用它们来平衡新的信号。有很多方法可以做到这一点。将增益应用于新信号短时功率谱的频率,然后在时域内对信号进行重新合成。我们对每个频率施加的增益与它对应的传输系数的倒数成正比,该系数取指数k。
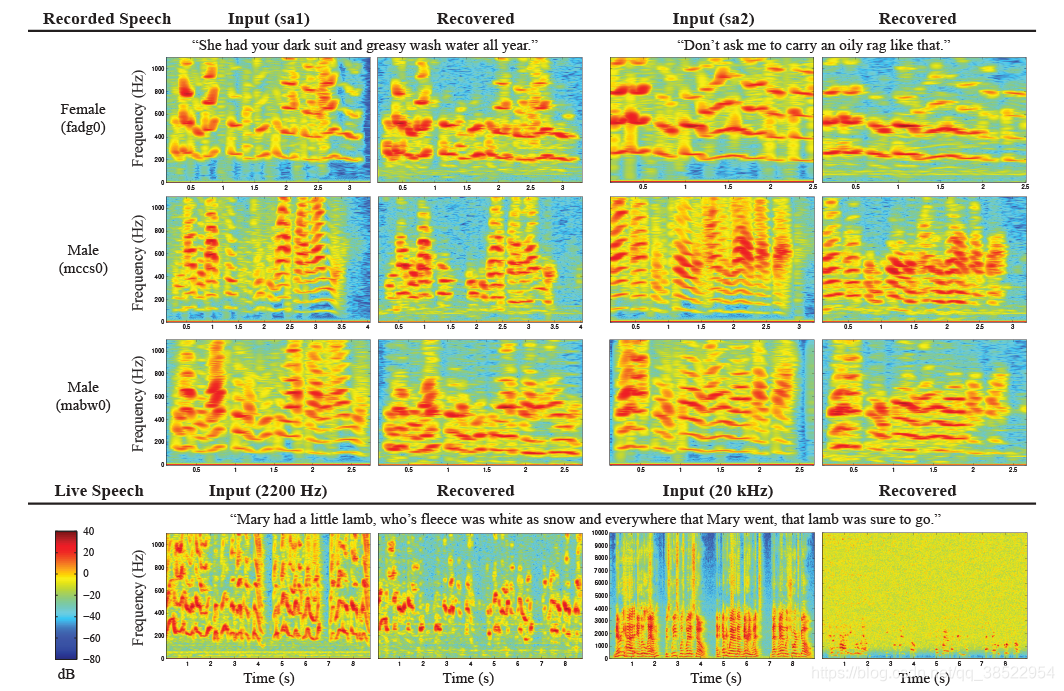

图2显示了将来自芯片包的均衡器应用于从同一对象恢复的语音序列的结果。在没有噪声的情况下,k将被设置为1,但是广谱噪声压缩了估计传递系数的范围。用更大的k可以补偿这个。我们在其中一个女性语音示例上手动调优k,然后将结果均衡器应用于所有六个语音示例。由于这种均衡的目的是提高恢复信号的信度,而不是提高语音的可解性,因此我们使用谱减法去噪和SSNR来评估我们的结果。
注意校准和均衡是可选的。特别地,本文表2外的所有结果均假设不存在记录对象频率响应的先验知识。
5 Analysis
在本节中,我们将提供一个分析,帮助预测我们的技术何时以及如何工作,并估计我们能够恢复的运动范围。在较高的水平上,我们的方法试图通过观察输入声音在附近物体中引起的运动来推断一些输入声音s(t)。图3概述了描述此过程的一系列转换。声音s(t),由空气压力随时间的波动所定义,作用于物体表面。然后,物体会对这种声音做出反应,将空气压力转化为表面位移。我们将这种转换称为对象响应,A。然后用摄像机记录产生的表面位移模式,我们的算法B将记录的视频转换为恢复的声音。直观地说,我们恢复s(t)的能力将取决于转换A和B。在本节中,我们将描述这些转换,以帮助预测A可视麦克风在新情况下的工作情况。
5.1 Object Response (A)
对于每一个物体,我们都在校准过的实验室环境中记录了它们对两个信号的响应。第一种是300Hz纯音,音量从[0.1-1]帕斯卡(RMS)(57到95分贝)线性增长。这个信号被用来描述体积和物体运动之间的关系。为了准确测量体积,我们用分贝计校准了我们的实验装置(扬声器、房间和被测物体的位置)。图7 (b)显示了不同物体的RMS运动作为Pascals (300Hz)中RMS气压的函数。从这个图中我们可以看到,对于我们测试的大多数物体,其运动在声压下近似线性。对于每个对象,我们测试了一个或多个附加频率,发现这种关系保持线性,这表明我们可以将对象响应A建模为线性时不变(LTI)系统。
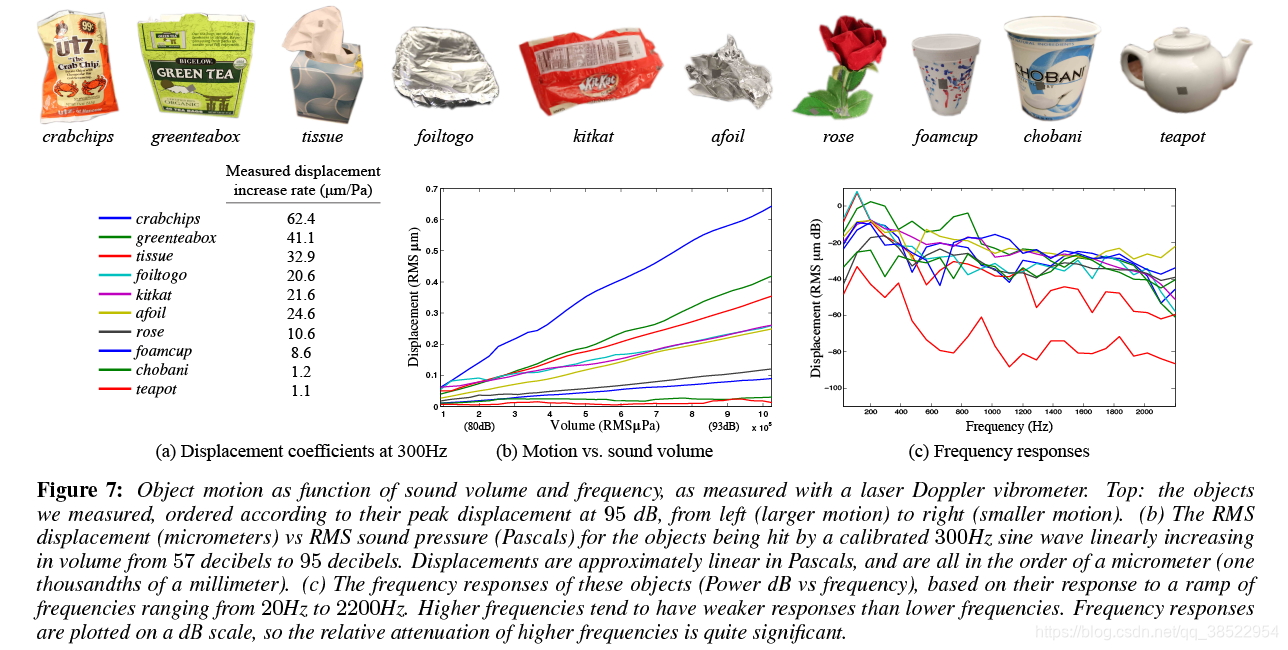
我们的第二个测试信号是一个斜坡信号,与4.1节中使用的信号相似,频率在20Hz到2200Hz之间。
将A建模为一个LTI系统,我们使用这个斜坡信号来恢复该系统的脉冲响应。这是通过我们已知的输入用维纳反褶积对我们观察到的斜坡信号(这次由LDV记录)进行反褶积来实现的。图7 ©显示了从我们恢复的脉冲响应中得到的频率响应。
从这个图中我们可以看到,大多数物体在低频率下的响应比高频率下的响应更强(正如预期的那样),但是这个趋势不是单调的。这与我们在4.1节中观察到的一致。我们现在可以在频域表达转换作为我们的声谱的乘法,S(ω),通过传递函数(ω),给我们的运动,Dmm (ω):
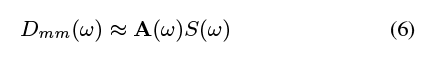
我们现在可以在频域表达转换作为我们的声谱的乘法,S(ω),通过传递函数(ω),给我们的运动,
5.2 Processing (B)
物体运动Dmm与像素位移Dp之间的关系是通过摄像机的投影和采样得到的。相机参数,如距离、变焦、视角、等,影响我们的算法的输入(视频)通过改变像素的数量看到物体,np,像素运动的放大(毫米/像素),m,σN捕获图像的噪声。物体运动与像素运动的关系可以表示为:
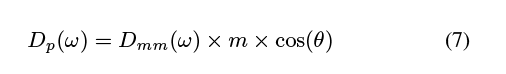
θ是相机的视角相对于物体表面的运动;m是mm/pixel中曲面的放大率。
通过模拟我们还研究了像素成像对象的数量的影响(np),振幅(像素)的运动(Dp(ω))和图像噪声(由标准差σn)的信噪比恢复声音。这些模拟的结果(可在我们的网页上找到)证实了以下关系:
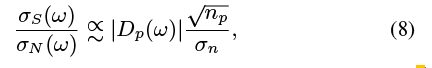
说明了信噪比随运动幅度和像素数的增加而增大,随图像噪声的增加而减小。
为了用真实数据验证信噪比与运动幅度之间的关系,并测试我们的技术在不同对象上的局限性,我们进行了另一个校准实验,类似于第5.1节中讨论的实验,这次使用的是可视麦克风,而不是激光振动仪。在本实验中,相机放置在距离被记录对象约2米的位置,以400×480像素成像,每毫米放大17.8像素。通过这个设置,我们将信噪比(dB)作为体积(标准分贝)的函数进行了评估。对于足够大的像素位移幅值,我们恢复的信号在体积上近似线性(图8(a)),验证了式8给出的关系。
为了对视频中运动的大小有所了解,我们还使用基于相位的光流(Gautama和Van Hulle 2002)对每个对应视频的运动(以像素为单位)进行了估计。我们发现这些运动大约是像素的百分之一到千分之一(图8(b))。
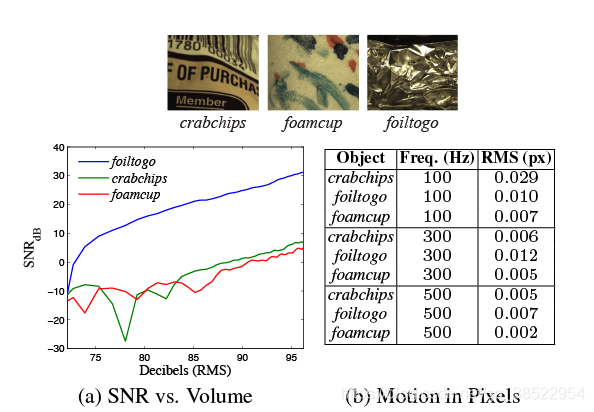
图8:从视频中恢复的声音的信噪比作为体积的函数(a),以及若干物体在不同频率和体积的正弦波作用下的绝对像素运动(b)。
6 Recovering Sound with Normal Video Cameras using Rolling Shutter
到目前为止,该技术的一个限制是对高速视频的需要。我们利用大多数手机和单反相机CMOS传感器中常见的滚动快门,探索了从以常规帧率拍摄的视频中恢复音频的可能性[中村2005]。通过滚动快门,传感器像素被暴露出来,并在不同的时间从上到下逐行依次读出。与统一的全局百叶窗相比,这种设计的实现成本更低,功耗更低,但通常会在记录的图像中产生不需要的偏置工件,特别是在移动对象的照片中。此前,研究人员曾试图减轻卷帘门对计算机视觉问题的影响,比如由运动产生的结构(Meingast et al. 2005)和视频稳定(Grundmann et al. 2012)。AitAider等[2007]利用滚动快门从一张图像中估计刚体的姿态和速度。利用卷帘门有效地提高了相机的采样率,恢复了高于相机帧频的声音频率。
因为每一行在传感器捕捉传感器在不同的时间,我们可以恢复一个音频信号对于每一行,而不是每一帧,增加采样率从相机的帧速率的速度行记录(图9)。我们可以完全确定的映射传感器行到音频信号通过了解相机的曝光时间,E,延迟,d,这之间的时间行捕捉帧周期T,帧捕获之间的时间,以及帧延迟D(图9)。卷闸门参数可以从相机和传感器规格中获取,也可以通过一个简单的校准过程计算(适用于任何相机)[Meingast et al. 2005],我们在项目网页上也描述了这个过程。我们进一步假设一个正向模型,其中一个对象的图像由B (x, y)给出,该对象以s(t)描述的前后一致的水平运动运动,并且该运动反映了我们想要恢复的音频,和前面一样。假设曝光时间E¡Ö0,则相机拍摄的第n帧可以由方程表征
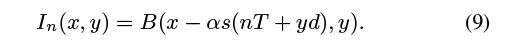
如果我们假设B的第y行有足够的水平纹理,我们可以使用基于相位的运动分析来恢复s(nT + yd)。如果帧延迟,也就是从一帧的最后一行到下一帧的第一行之间的时间,不是零,那么就会有一些时候相机没有记录任何东西。这将导致音频信号中缺少样本或“间隙”。在图9(b)中,我们展示了如何从卷帘门相机中恢复三角波。
每一帧贡献11个样本,每一行一个。每帧之间有5个缺失的样本,用浅灰色表示,对应的帧延迟不可忽略。为了处理音频信号中缺失的样本,我们使用了Janssen等人[1986]的音频插值技术。
#在实际操作中,曝光时间不是零,每一行都是其在曝光过程中所处位置的平均时间。正弦音频信号的频率ω> E1,记录行大约将左边的静止位置的一半暴露和对另一半。因此,单次平移并不能很好地描述它,这表明E是我们希望用卷帘门捕捉的最大频率的极限。大多数相机的最小曝光时间为0.1毫秒(10kHz)。
我们在图10中展示了一个使用普通帧速率DSLR视频恢复声音的示例结果。我们视频了一袋糖果(图10 (a))附近的一个扬声器播放演讲,并将视频从一个观点loudspeaker-object轴正交,这样的运动包由于扬声器将水平和fronto-parallel在摄像机图像平面。我们使用的宾得K-01与31毫米镜头。该相机以每秒60帧的速度拍摄,分辨率为1280720,曝光时间为20100秒。通过测量直线的斜率,我们确定它有一条线延迟16μs和帧延迟5毫秒,这样有效的采样率为61920 hz以30%的样本失踪。曝光时间限制在最大可恢复频率为2000Hz左右。除了利用音频插值来恢复缺失的样本,我们还利用语音增强算法和低通滤波器对信号进行去噪,去除由于曝光时间过长而无法恢复的范围外的频率。除了瞬间(零)曝光时间外,我们还用相同的相机参数进行了模拟实验。恢复的音频剪辑可以在网上找到。
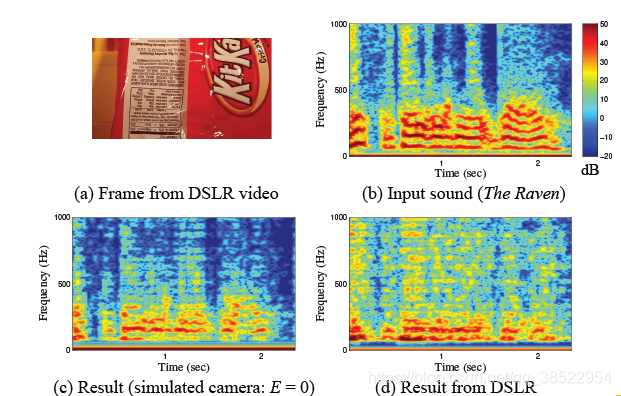
图10:用标准单反相机和卷帘拍摄的普通帧速率视频恢复的声音。(A)是数码单反视频的一个画面。埃德加·爱伦·坡(Edgar Allan Poe)的《乌鸦》(recitation of the Raven)通过扬声器播放詹姆斯·厄尔·琼斯(James Earl Jones)的《乌鸦》(spectrogram,见(b)),旁边放着一台普通的数码单反相机拍摄的奇巧包。我们设法从单反相机中恢复的信号的光谱图如图(d)所示。在图©中,我们显示了滚动快门模拟的结果,除了曝光时间(E)被设置为零外,其他参数与单反相机相似。
7 Discussion and Limitations
我们的许多例子都集中在恢复声音的可理解性上。然而,在某些情况下,听不懂的声音仍然可以提供信息。例如,在某些监视场景中,即使无法恢复可理解的语音,识别房间中说话者的数量和性别也是有用的。图11显示了一个实验的结果,在这个实验中,我们能够使用一个标准的音高估计器从难以理解的讲话中检测说话者的性别[De Cheveigne and Kawahara 2002]。在我们的project web页面上,我们展示了另一个例子,在这个例子中,我们很好地恢复了音乐,使一些听众能够识别歌曲,尽管歌词本身在恢复的声音中是难以理解的。
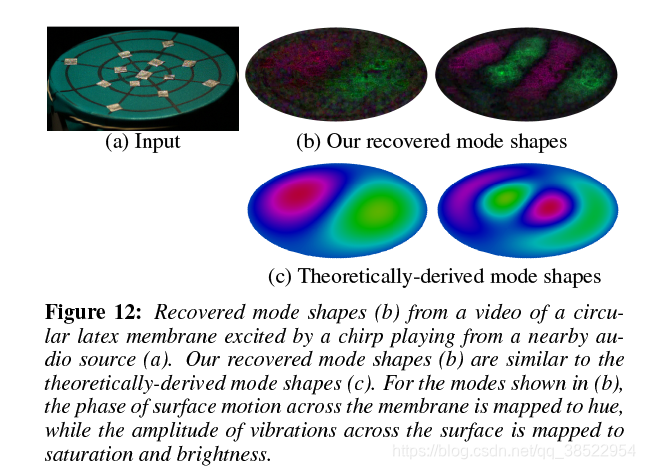
Visualizing Vibration Modes 因为我们正在从视频中恢复声音,所以我们获得了对被拍摄对象上多个点的音频信号的空间测量,而不是像激光麦克风那样的单个点。我们可以用这种空间测量来恢复物体的振动模式。这可以成为结构分析的有力工具,在结构分析中,物体的一般变形通常表示为物体振动模态的叠加。与从表面振动中恢复声音一样,大多数现有的模式形状恢复技术都是活跃的。例如,Stanbridge和Ewins[1999]以光栅模式扫描表面上的激光振动计。另外,全息干涉术的工作原理是首先记录一个静止物体的全息图,然后将这个全息图投射回物体上,这样表面变形就会产生可预测的干涉图样[Powell和Stetson 1965;Jansson等人,1970]。像我们一样,Chen等人[2014]提出从高速视频中恢复振型,但他们只研究了梁在被锤子击中后振动的具体情况。
振动模式的特征是物体的所有部分都以相同的时间频率振动,即模态频率,物体不同部分之间有固定的相位关系。我们可以通过在局部运动信号的频谱中寻找峰值来找到模态频率。在其中一个峰值处,我们将得到图像中每个空间位置的傅里叶系数。这些傅里叶系数给出了与运动量对应的振幅振型和与点间固定相位关系相对应的相位振型。在图12中,我们将鼓头的两种振动模式的振幅映射为强度,相位映射为色调。这些恢复的振动模态(图12(b))与理论推导的模态形状(图12©)密切对应。
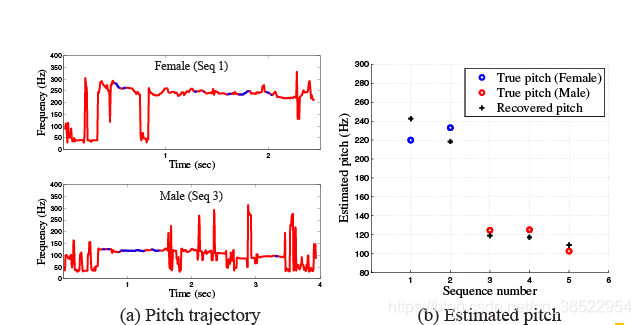
图11:即使恢复后的语音无法理解,我们的方法也是有用的。在这个例子中,我们使用了5个TIMIT语音样本,从一个纸巾盒和一个箔纸容器中恢复。恢复后的语音很难理解,但是使用标准音高估计器[De Cheveigne和Kawahara 2002],我们能够恢复说话人的音高(b)。蓝色的线段表示对估计有很高的信心(详见[De Cheveigne和Kawahara 2002])。
Limitations除采样率外,我们的技术主要受透镜放大率的限制。我们的技术所恢复的音频信噪比与像素的运动幅度和覆盖对象的像素数成正比(式8),二者均随放大倍数的增大而增大,随距离的增大而减小。因此,为了从遥远的物体上恢复清晰的声音,我们可能需要一个强大的变焦镜头。图2中的实验使用400mm镜头从3-4米的距离恢复声音。从更大的距离恢复可能需要昂贵的光学与大焦距。
8 Conclusion
我们已经证明,许多日常物体对声音的振动可以从高速视频中提取出来,用来恢复声音,把这些物体变成可视麦克风。我们将物体表面的局部微小运动信号整合起来,计算出一个单一的运动信号,该信号能够捕捉物体随时间推移对声音的响应。然后,我们使用语音增强和其他技术去噪该运动信号,以产生一个恢复的音频信号。通过我们的实验,我们发现光和刚性物体是特别好的可视麦克风。我们相信,利用摄像机来恢复和分析不同物体中与声音有关的振动,将会开启有趣的新研究和应用。我们的视频、结果和补充材料可以在项目网页上找到:http://people.csail.mit.edu/mrub/VisualMic/。
Acknowledgements
We thank Justin Chen for his helpful feedback, Dr. Michael Feng and Draper Laboratory for lending us their Laser Doppler Vibrometer, and the SIGGRAPH reviewers for their comments. We acknowledge funding support from QCRI and NSF CGV-1111415.
Abe Davis and Neal Wadhwa were supported by the NSF Graduate Research Fellowship Program under Grant No. 1122374. Abe Davis was also supported by QCRI, and Neal Wadhwa was also supported by the MIT Department of Mathematics. Part of this work was done when Michael Rubinstein was a student at MIT, supported by the Microsoft Research PhD Fellowship.


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









