







 本文介绍了一种爬取网易云音乐民谣歌曲歌词的方法,并利用爬取的数据进行初步清洗、分词及词频统计,最终通过词云和图表形式展示了民谣歌曲中的常用词汇及其分布情况。
本文介绍了一种爬取网易云音乐民谣歌曲歌词的方法,并利用爬取的数据进行初步清洗、分词及词频统计,最终通过词云和图表形式展示了民谣歌曲中的常用词汇及其分布情况。
1. 歌词获取
首先我需要一个民谣歌曲集合,选歌单的原则是尽力为选择能代表中国民谣的作品,事实上,现在民谣制作的门槛是真的低。有的民谣里面通篇就几个词翻来覆去。比如底下这种歌单很快就舍弃掉了。
 (野鸡民谣)
(野鸡民谣)
最终选择的是 歌单:民谣合集。歌单比较全,总共大概2128首歌,涉及到不少华语民谣歌手。按每人50首来算,这也有40左右个中国民谣人了
网易提供了(体验并不好的)某些API,
# 获取歌单中歌曲API url
playlist_url = 'http://music.163.com/api/playlist/detail?id=[id]'
# 获取歌曲的歌词API url
song_lyrics_url = 'http://music.163.com/api/song/lyric?os=pc&id=[id]&lv=-1'实际请求时,请将[id]替换为真实id,比如《民谣合集》歌单id为2618345367,你可以从网易音乐相关超链接上找到。这两个API返回都是JSON格式,需要自己解析。(可以看出实际中这个#是没什么用的)
然后,我们请求获取歌单的所有歌曲信息(歌曲云上id、歌曲名、作者)
def get_playlist(playlist_id, path=''):
"""
获得歌单中所有歌曲的id,cloud_id,title,author信息
:param playlist_id: 歌单id
:param path: 保存的路径和文件名
:return: text
"""
json_text = requests.get(playlist_url % playlist_id).text
json_dict = json.loads(json_text)
text_list = []
for idx, song in enumerate(json_dict['result']['tracks']):
if not idx:
text_list.append('id cloud_id title author')
text_list.append('%d %d %s %s' % (idx + 1, song['id'], song['name'], song['artists'][0]['name']))
text = '\n'.join(text_list)
if path:
with open(path, 'w') as file:
file.write(text)
return text
我们还需要一个函数,请求获取某首歌的歌词
def get_lyric(song_id, path=''):
"""
根据歌曲id获得歌曲歌词
:param song_id:
:param path: 当前歌词被保存的路径和文件名
:return:
"""
json_text = requests.get(song_lyrics_url % song_id).text
json_dict = json.loads(json_text)
text_list = []
for idx, line in enumerate(json_dict['lrc']['lyric'].split('\n')):
if '作曲' in line or '作词' in line: # 去除歌词中可能出现的作词、作曲行
continue
if line.strip() != '':
if ']' in line: # []内可能是时间信息,去除
if line.rindex(']') + 1 != len(line):
line = line[line.rindex(']') + 1:].strip()
else:
continue
if ':' in line: # 冒号前面可能是歌者,应去除。e.g.: "女:"、"老狼:"
line = line[line.rindex(':') + 1:]
if ':' in line: # 冒号前面可能是歌者,应去除。e.g.: "女:"、"老狼:"
line = line[line.rindex(':') + 1:]
text_list.append(line.strip())
text = '\n'.join(text_list)
if path:
with open(path, 'w') as file:
file.write(text)
return text
最后,我们将此歌单中所有歌曲歌词都保存下来
if __name__ == '__main__':
# 获取"中国民谣集"歌单中所有歌曲歌词
df = pd.read_csv(os.path.join(cfg.ProjectPath, cfg.DataDirectory, cfg.SongInfoFileName), delimiter=' ',
engine='python')
for idx, cloud_id, title, author in df.values:
try:
get_lyric(cloud_id, file_name='%d_%s_%s' % (idx, title, author))
except IOError as ioe:
print('id为%s,云id为%s的文件异常,%s' % (idx, cloud_id, ioe))
except BaseException as be:
print('id为%s,云id为%s的文件异常,%s' % (idx, cloud_id, be))写个函数在目录里自动生成目录保存下来所有歌词
def makedir(dir_name):
path = r"C:\Users\admin\PycharmProjects\Cloudlyric\data"
dir_name = path+'./'+dir_name
folder = os.path.exists(dir_name)
if not folder:
os.makedirs(dir_name)
print("creat dir success")
else:
print("this folder has existed")
return dir_name2.数据存储和初步简单清洗
简单的看了一下爬下来的每一个数据,发现前两行经常有不用的作词作曲信息,想办法去除掉
def ConvertStrToFile(dir_name, filename, str):
if (str == ""):
return
filename = filename.replace('/', '')
text_list = ""
for idx, line in enumerate(str.split('\n')):
if '作曲' in line or '作词' in line or '编曲' in line: # 去除歌词中可能出现的作词、作曲行
continue
if line.strip() != '':
if ']' in line: # []内可能是时间信息,去除
if line.rindex(']') + 1 != len(line):
line = line[line.rindex(']') + 1:].strip()
else:
continue
if ':' in line: # 冒号前面可能是歌者,应去除。e.g.: "女:"、"老狼:"
line = line[line.rindex(':') + 1:]
if ':' in line: # 冒号前面可能是歌者,应去除。e.g.: "女:"、"老狼:"
line = line[line.rindex(':') + 1:]
text_list +=line.strip()
path = r"C:\Users\admin\PycharmProjects\Cloudlyric\data"
with open(path+"./"+dir_name + "//" + filename + ".txt", 'w',encoding='utf-8') as f:
f.write(text_list)于是保存歌词成txt文档在最开始创建的目录里
def get_list_lyric(playlist_id):
songlist = get_list(playlist_id)
print(songlist)
playlist_name = songlist['playlist_name']
idlist = songlist['list']
dir=makedir(playlist_name)
for music in idlist:
ConvertStrToFile(playlist_name, music.text, get_lyric(music['href']))
print("File " + music.text + " is writing on the disk")
print("All files have created successfully")
return dir3.数据的清洗、分词、统计
在分词前,为了最终结果得出不必要的语气词以及冗余词,我是用的是哈工大停用词表再结合结巴分词,效果好了不少
def load_stopwords():
"""
加载停用词
:return:
"""
stopwords = set()
with open(os.path.join(naming.ProjectPath, naming.DictDirectory, naming.StopwordsFileName),encoding='utf-8') as file:
for line in file:
stopwords.add(line[:-1]) # 切除换行符
stopwords.add(' ')
return stopwords
def get_words_freq(stopwords, lyrics_dir):
"""
统计词频
:param stopwords: 停用词集合
:type stopwords: set(stopword1, stopword2, ...)
:param lyrics_dir: 歌词路径
:return: {word1: freq, word2: freq, ...}
"""
# 迭代每个文件,对每个文件,每一行分词,去除停用词后,统计词频
words_freq = {}
for file_name in os.listdir(lyrics_dir):
try:
with open(os.path.join(lyrics_dir, file_name),encoding='utf-8') as file:
for line in file:
words = posseg.cut(line.strip())
for word, pos in words:
if word not in stopwords and pos[0] in pos_retained: # 过滤停用词,词性筛选
if word not in words_freq:
words_freq[word] = 1
else:
words_freq[word] += 1
except IOError as ioe:
logger.warning('异常信息:%s' % ioe)
except BaseException as be:
logger.warning('异常信息:%s' % be)
return words_freq为了方便,得出的结果转为json格式,存储在data数据目录下
初步优化
发现许多地方名称、路径又多又杂。又开了一个py文件naming来设置命名规范 大概是这样的
# -*- coding: utf-8 -*-
from dataGet import getData
__author__ = 'Jmh'
# Project path
ProjectPath = r'C:\Users\admin\PycharmProjects\Cloudlyric'
# Data directorye
DataDirectory = 'data'
LyricsDirectory = 'data/民谣合集 - 歌单 - 网易云音乐'
DictDirectory = 'data/dict'
Resource = 'resource'
# File name
StopwordsFileName = 'stopwords' # 停用词文件名
简单的数据处理后,轻易可以得出各种自己想要的数据:

4.运用WordClouD词云
此部分比较简单也就写的比较随意了,生成了两个,一个带图片蒙版一个不带
wordcloud = WordCloud(background_color='white',mask=alice_mask,max_words =1000,font_path=r"C:\\Windows\\Fonts\\STFANGSO.ttf",).fit_words(read_dict)
#生成词云(通常字体路径均设置在C:\\Windows\\Fonts\\也可自行下载)
#不加这一句显示口字形乱码 ""报错
plt.imshow(wordcloud)
plt.axis('off')
plt.show()
其中生成中文词云时,不加font_path会显示满屏幕的口字乱码

带蒙版的,需要ps去除背景且大小要合适,最大词频数控制在1000个左右
通过词云,我们大概很清晰的能看出来:民谣歌手最常出现的几个词“时间”“姑娘”“梦想”“世界”“远方”“城市”
看来民谣歌手也没有那么丧。
5.制作图表
共用到两种工具:matplot和echarts
绘制柱状图:
import matplotlib.pyplot as plt
import numpy as np
plt.rcParams['font.sans-serif']=['SimHei'] #用来正常显示中文标签
plt.rcParams['axes.unicode_minus']=False #用来正常显示负号
# 创建一个点数为 8 x 6 的窗口, 并设置分辨率为 80像素/每英寸
plt.figure(figsize=(8, 6), dpi=80)
# 再创建一个规格为 1 x 1 的子图
plt.subplot(1, 1, 1)
# 柱子总数
N = 11
# 包含每个柱子对应值的序列
values = (75, 17, 9, 9, 2,7,6,12,7,9,25)
# 包含每个柱子下标的序列
index = np.arange(N)
# 柱子的宽度
width = 0.35
# 绘制柱状图, 每根柱子的颜色为紫罗兰色
p2 = plt.bar(index, values, width, label="城市", color="#87CEFA")
# 设置横轴标签
plt.xlabel('')
# 设置纵轴标签
plt.ylabel('次数')
# 添加标题
plt.title('民谣歌手最钟爱的城市')
# 添加纵横轴的刻度
plt.xticks(index, ('北京', '上海', '深圳', '成都', '苏州', '重庆','武汉','南京','青岛','郑州','兰州'))
plt.yticks(np.arange(0, 81, 10))
# 添加图例
plt.legend(loc="upper right")
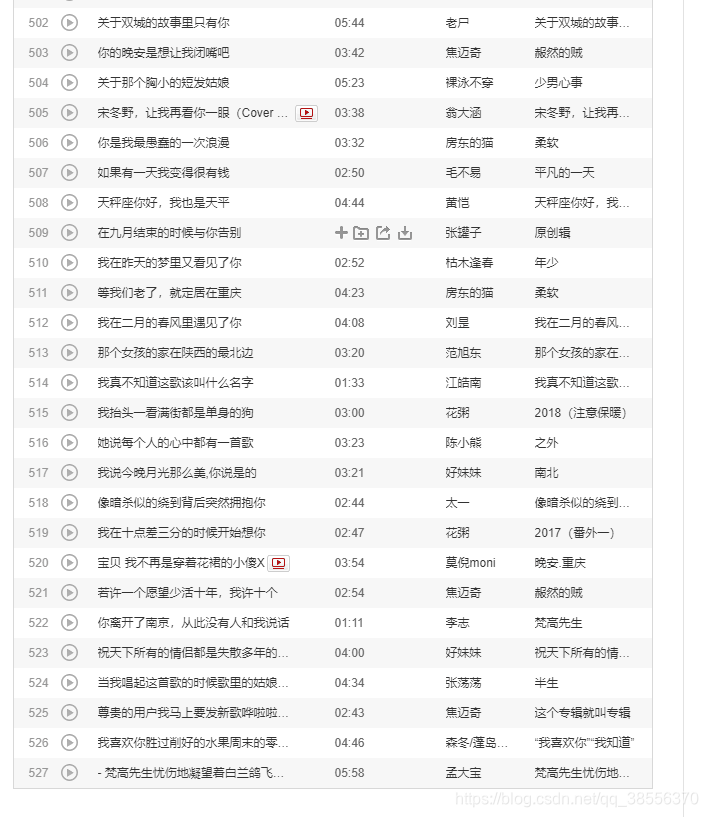
plt.show()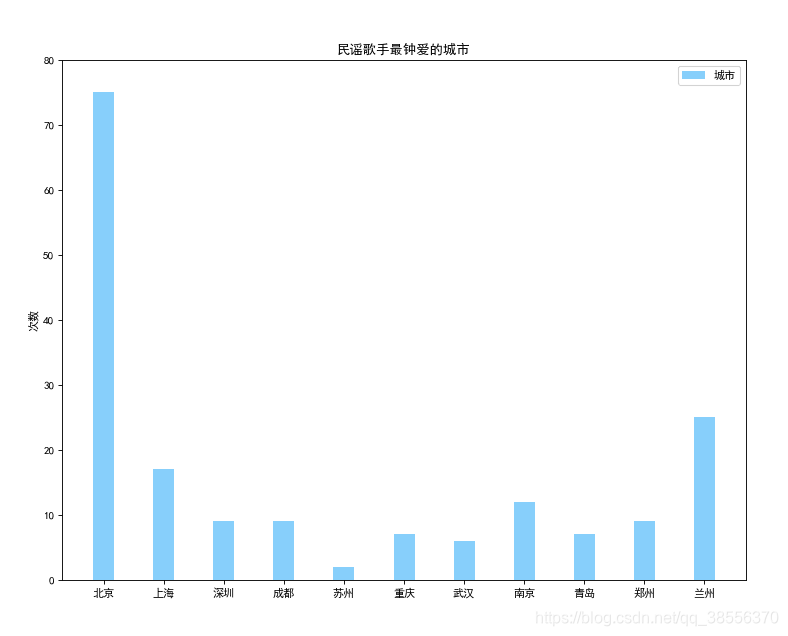
民谣歌手最爱的城市是北京,其次竟然是兰州,出乎了我的意料
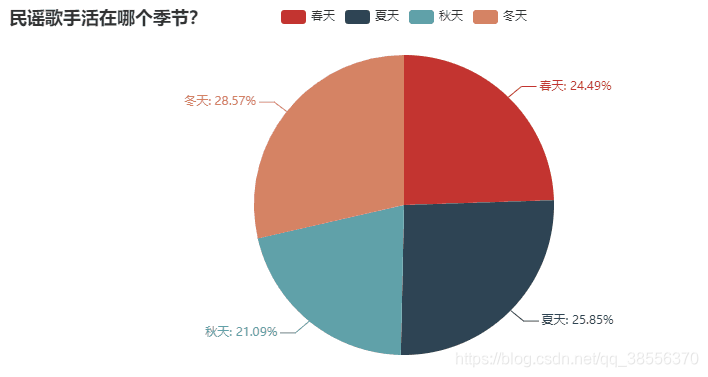
比起其他季节,民谣歌手更爱歌颂冬天
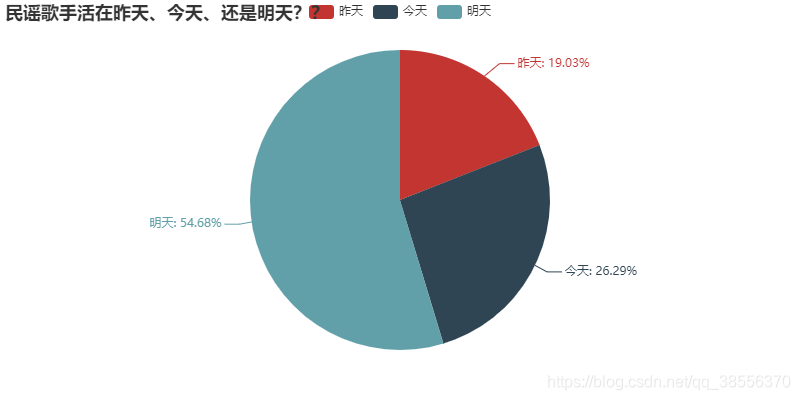
即是丧如民谣歌手,人还是要向前看。
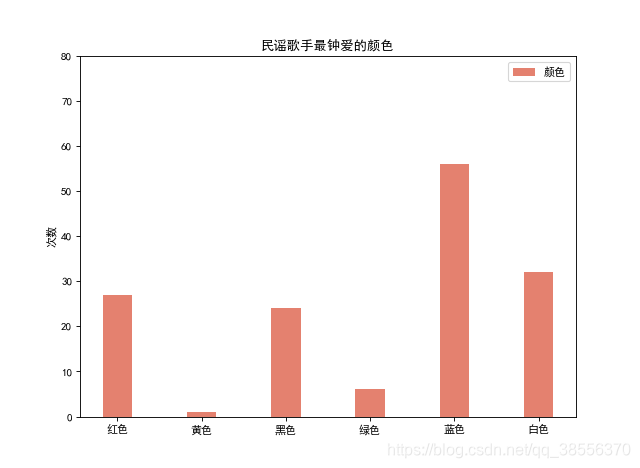
民谣歌手更喜欢忧郁的蓝色


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









