







k折交叉验证数据获取
- 无注释
def get_k_fold_data(k, i, X, y):
assert k > 1
n = X.shape[0]
fold_size = n // k
X_train, y_train = None, None
for j in range(k):
idx = slice(j*fold_size, (j+1)*fold_size)
X_part, y_part = X[idx, :], y[idx]
if j == i:
X_valid, y_valid = X_part, y_part
elif X_train is None:
X_train, y_train = X_part, y_part
else:
X_train = tf.concat([X_train, X_part], axis=0)
y_train = tf.concat([y_train, y_part], axis=0)
return X_train, y_train, X_valid, y_valid
- 有注释
def get_k_fold_data(k, i, X, y):
#k-折数;i-验证集为第i折;X-特征;y-标签
assert k > 1 #确保大于一折
n = X.shape[0] #样本量
fold_size = n // k #计算每折的样本量
X_train, y_train = None, None #定义训练集
for j in range(k):
#在1到k折进行循环
idx = slice(j*fold_size, (j+1)*fold_size) #获得第j折的索引
X_part, y_part = X[idx, :], y[idx] #获得第j折的数据
if j == i:
#如果第j折就是要当作验证集的数据
X_valid, y_valid = X_part, y_part
elif X_train is None:
#训练集为None时,也就是训练集仍然是空的时候
X_train, y_train = X_part, y_part
else:
#其他的情况,直接让两个数据连接
X_train = tf.concat([X_train, X_part], axis=0)
y_train = tf.concat([y_train, y_part], axis=0)
return X_train, y_train, X_valid, y_valid
该函数可以获得k折交叉验证中,以第i折为验证集的数据。在进行交叉验证时,只需要在range(k)上使用一个for循环即可。
实际上,这个代码有一些样本会被舍弃,因为计算fold_size是使用的是向下取整,余数会被舍弃。例如,有102个样本,使用十折交叉验证,那么k=10,fold_size=10,整体包括了10*10=100个样本,有两个样本被舍弃了。但是并不用太在意舍弃的两个样本,因为最多也只会有小于折数的样本被舍弃,对于十折交叉验证来说,最多也只会有9个样本被舍弃,在样本量较大的情况下,基本可以忽略。
- 例子
def k_fold(k, X_train, y_train, num_epochs,learning_rate, weight_decay, batch_size):
#这里X_train、y_train就是指X、y
train_l_sum, valid_l_sum = 0, 0
for i in range(k):
# create model
data = get_k_fold_data(k, i, X_train, y_train)
net = tf.models.Sequential(tf.keras.layers.Dense(1))
# Compile model
net.compile(loss=tf.keras.losses.mean_squared_logarithmic_error,
optimizer=tf.keras.optimizers.Adam(learning_rate))
# Fit the model
history=net.fit(data[0], data[1],validation_data=(data[2], data[3]), epochs=num_epochs,
batch_size=batch_size,validation_freq=1,verbose=0)
loss = history.history['loss']
val_loss = history.history['val_loss']
print('fold %d, train rmse %f, valid rmse %f'
% (i, loss[-1], val_loss[-1]))
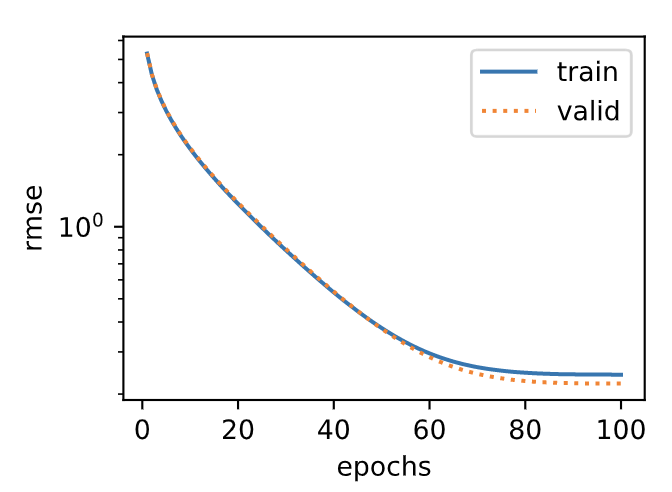
plt.subplot(1, 2, 2)
plt.plot(loss, label='train')
plt.plot(val_loss, label='valid')
plt.legend(loc='upper right')
plt.title('Training and Validation Loss')
plt.show()
输出:
fold 0, train rmse 0.241054, valid rmse 0.221462
fold 1, train rmse 0.229857, valid rmse 0.268489
fold 2, train rmse 0.231413, valid rmse 0.238157
fold 3, train rmse 0.237733, valid rmse 0.218747
fold 4, train rmse 0.230720, valid rmse 0.258712
5-fold validation: avg train rmse 0.234155, avg valid rmse 0.241113
















 160
160











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









