







一.首先我们来了解混音、叠加音频、拼接音频的概念
1.1 混音:把单声道音频a和单声道音频b(可以是两个单声道音频或更多单声道音频)合并成一个多声道音频c。需要注意的是音频a和音频b的时长要相同且都为单声道音频。(音频c的时长=音频a的时长)
1.2 叠加音频:把音频a和音频b叠加成音频c,单声道音频a和单声道音频b叠加成单声道音频c,双声道音频a和单声道音频b叠加成双声道音频c,双声道音频a和双声道音频b叠加成双声道音频c。(如果把音频b叠加在音频a上,那么音频c的时长和音频a的时长相同,反之如果把音频a叠加在音频b上,那么音频c的时长和音频b的时长相同)
1.3 拼接音频:把音频a和音频b拼接起来成一个长音频c(即音频c的时长=音频a的时长+音频b的时长)
二.代码示例:
2.1 混音代码:
from pydub import AudioSegment
sound1 = AudioSegment.from_wav(r'F:\误入测试集\dianshiju-0.wav')
sound2 = AudioSegment.from_wav(r'F:\误入测试集\dianshiju-14.wav')
# sound3 = AudioSegment.from_wav(r'F:\误入测试集\dianshiju-16.wav')
output = AudioSegment.from_mono_audiosegments(sound1, sound2) # 把sound1和sound2合并成两通道音频
# output = AudioSegment.from_mono_audiosegments(sound1, sound2,sound3) # 把sound1、sound2、sound3合并成三通道音频
output.export("output.wav", format="wav") # 保存文件
2.2 叠加音频代码:
from pydub import AudioSegment
sound1 = AudioSegment.from_wav(r'F:\误入测试集\dianshiju-0.wav')
sound2 = AudioSegment.from_wav(r'F:\误入测试集\dianshiju-14.wav')
output = sound1.overlay(sound2) # 把sound2叠加到sound1上面
# output = sound1.overlay(sound2,position=5000) # 把sound2叠加到sound1上面,从第5秒开始叠加
output.export("output.wav", format="wav") # 保存文件
2.3 拼接音频代码
from pydub import AudioSegment
sound1 = AudioSegment.from_wav(r'F:\误入测试集\dianshiju-0.wav')
sound2 = AudioSegment.from_wav(r'F:\误入测试集\dianshiju-14.wav')
# sound3 = AudioSegment.from_wav(r'F:\误入测试集\dianshiju-16.wav')
output = sound1 + sound2 # sound1拼接sound2
# output=sound1+sound2+sound3 # sound1拼接sound2拼接sound3
output.export("output.wav", format="wav") # 保存文件
三、敲重点!!!批处理
3.1 一个文件夹的批处理,即一个文件夹内的音频文件和一个音频文件进行批处理
import os
from pydub import AudioSegment
input_path = r"E:\untitled1\audio_test\a" # 第一个文件路径
output_path = r"E:\untitled1\audio_test\output" # 输出文件路径
for file in os.listdir(input_path): # 遍历第一个文件路径下的文件
path1 = input_path + "\\" + file # 拼接第一个输入路径和对应文件名
path3 = output_path + "\\" + file # 拼接输出路径和输出文件名,这里我是以第一个输入的文件名命名
sound1 = AudioSegment.from_wav(path1) # 第一个文件
sound2 = AudioSegment.from_wav(r"E:\untitled1\audio_test\b\爱惜花草不践踏_高清_1.wav") # 第二个文件
output = sound1.overlay(sound2) # 把sound2叠加到sound1上面
output.export(path3, format="wav") # 保存文件
3.2 两个文件夹的批处理,即两个文件夹分别有相同数量的音频文件进行批处理
import os
from pydub import AudioSegment
input_path1 = r"E:\untitled1\audio_test\a" # 第一个文件路径
input_path2 = r"E:\untitled1\audio_test\b" # 第二个文件路径
output_path = r"E:\untitled1\audio_test\output" # 输出文件路径
for file1, file2 in zip(os.listdir(input_path1), os.listdir(input_path2)): # 遍历两个文件路径下的文件
path1 = input_path1 + "\\" + file1 # 拼接第一个输入路径和对应文件名
path2 = input_path2 + "\\" + file2 # 拼接第二个输入路径和对应文件名
path3 = output_path + "\\" + file1 # 拼接输出路径和输出文件名,这里我是以第一个输入的文件名命名
sound1 = AudioSegment.from_wav(path1) # 第一个文件
sound2 = AudioSegment.from_wav(path2) # 第二个文件
output = sound1.overlay(sound2) # 把sound2叠加到sound1上面
output.export(path3, format="wav") # 保存文件
四、效果展示:
5.1 如下图所示,两个10s的单声道(a、b)混合成一个10s的多声道音频c:

5.2.1 如下图所示,两个10s的单声道音频(a、b)叠加成一个10s的单声道音频c

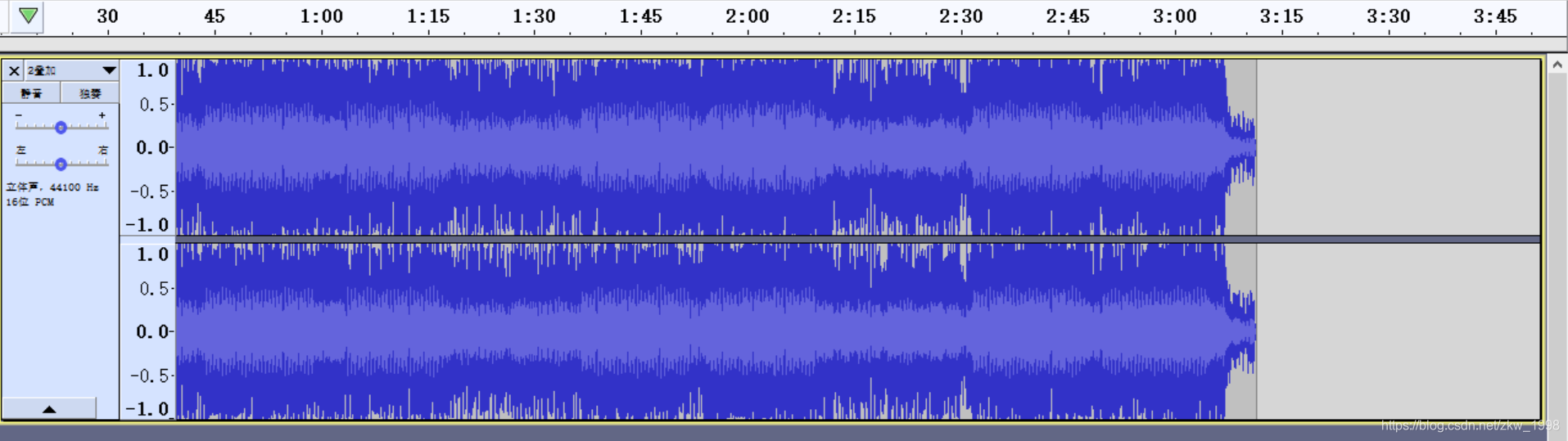
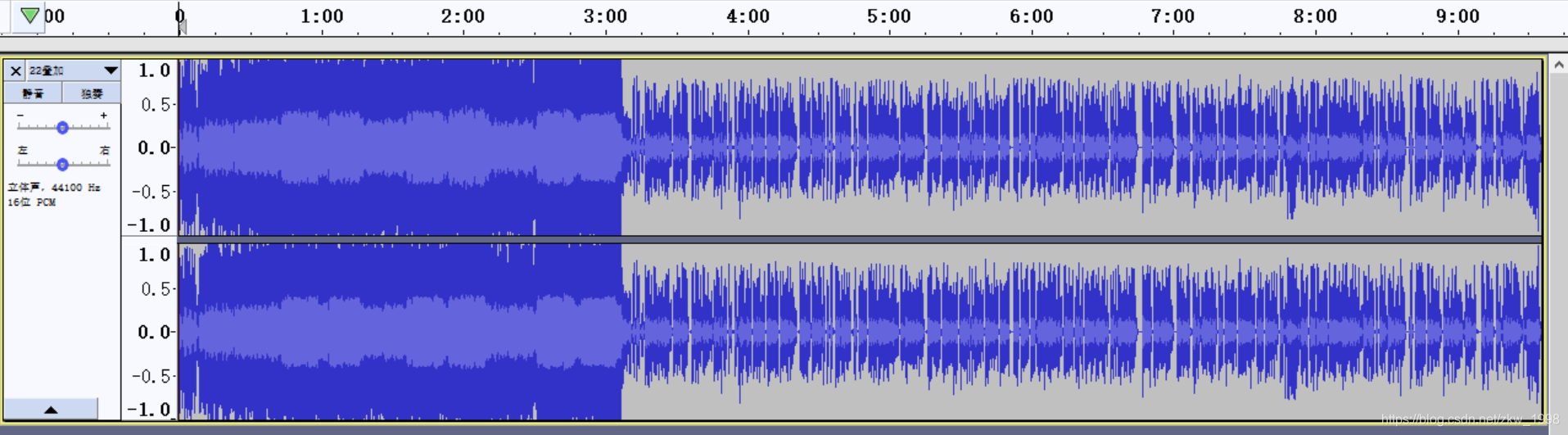
5.2.2 如下图所示,一个3分11s的多声道音频a和一个9分35秒的多声道音频b叠加成一个3分11s/9分35秒的多声道音频c(如果把b叠加在a上,音频c的时间长度就和音频a一样)
5.3 如下图所示,两个10s的音频拼接成一个20s的音频

批处理一定要掌握啊!!!掌握批处理,学习工作无烦恼~
来源:














 776
776











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









