






一、累加器:分布式共享只写变量
1.1、需求
如下方代码,想要使用foreach来实现reduce的操作,结果发现结果为0
val conf: SparkConf = new SparkConf().setMaster("local[*]").setAppName("wordcount")
val sc: SparkContext = SparkContext.getOrCreate(conf)
val rdd: RDD[Int] = sc.makeRDD(List(1, 2, 3, 4))
// val i: Int = rdd.reduce(_ + _)
// println(i)
// 想要通过foreach实现reduce的操作
var sum = 0
rdd.foreach(
num => {
sum += num
}
)
println("sum = "+sum) //sum = 0
sc.stop()
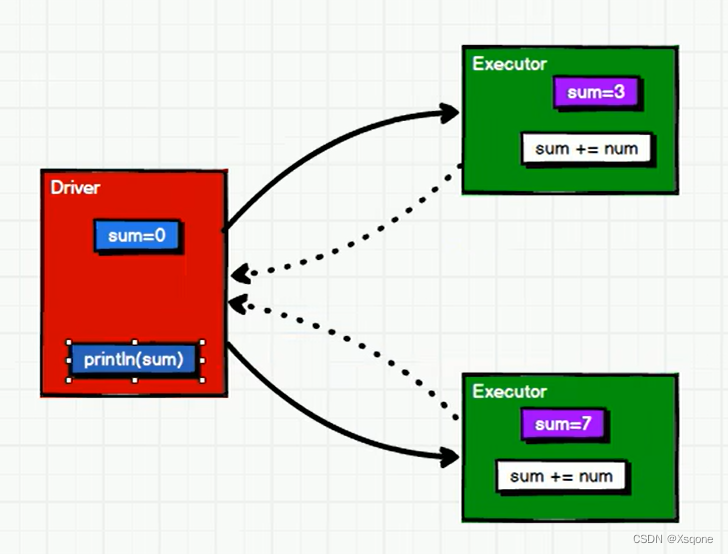
foreach方法执行效果如下,是一个分布式循环,每个分区都会去修改sum值。
在最后应该去返回这个sum值的,但是foreach是没有返回这个操作的,最初的sum是没有进行变化的,所以结果为0。
1.2、实现原理
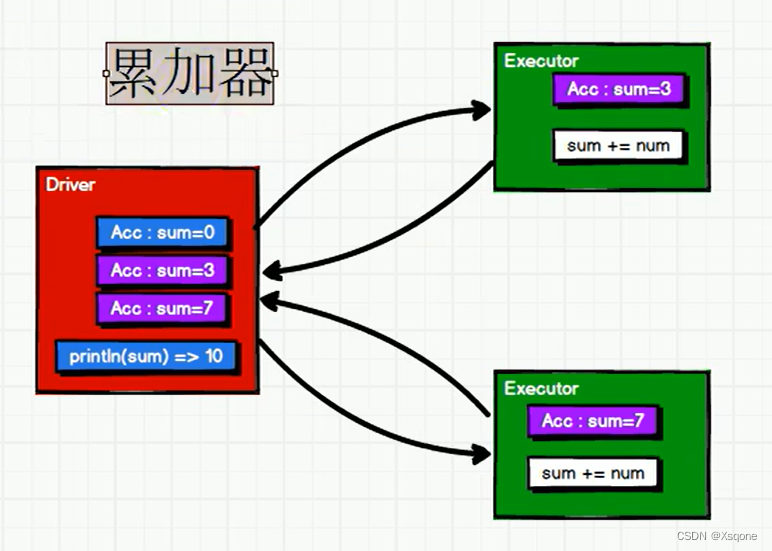
累加器用来把Executor端变量信息聚合到Driver端。在Driver程序中定义的变量,在Executor端的每个Task都会得到这个变量的一份新的副本,每个task更新这些副本的值后,传回Driver端进行merge。
1.3、系统内置累加器
系统内置累加器(SystemAccumulators)是Spark提供的一种特殊类型的变量,它们是只写变量(write-only),只能被Worker节点累加(Accumulate),而Driver节点不能读取它们的值。系统累加器的主要作用是提供一种在分布式环境下进行计数或者计算的方式,尤其是在调试、性能优化和任务监控方面非常有用。
- LongAccumulator:用于计算整数值的累加器。
- DoubleAccumulator:用于计算浮点数值的累加器。
- CollectionAccumulator:用于收集对象的累加器,可以通过集合的方式返回结果。
val conf: SparkConf = new SparkConf().setMaster("local[*]").setAppName("wordcount")
val sc: SparkContext = SparkContext.getOrCreate(conf)
val rdd: RDD[Int] = sc.makeRDD(List(1, 2, 3, 4))
// 获取系统累加器
// Spark默认提供了简单数据聚合的累加器
val sum = sc.longAccumulator("sum")
rdd.foreach(
num =>{
sum.add(num)
}
)
// 获取累加器的值
// 少加: 转换算子中调用累加器,若是没有行动算子的话,那么不会执行
// 多加: 在转换算子中调用累加器,若是没有使用持久化,当多次调用行动算子会将之前的结果进行累加
// 一般情况下,累加器会放置在行动算子中操作。
println(sum.value)
sc.stop()
1.4、自定义累加器
- 自定义累加器在Spark中进行自定义聚合计算的一种方式。
- 自定义累加器需要继承Spark的AccumulatorV2抽象类,该类有四个泛型参数,分别是输入类型、中间类型、输出类型和累加器自身类型。其中,输入类型是指累加器每次接收到的输入数据类型,中间类型是指累加器在进行数据累加时所使用的的中间变量类型,输出类型是指累加器最终输出结果的类型,而累加器自身类型则是指累加器类型本身。
- 自定义累加器需要实现AccumulatorV2中的五个抽象方法:reset、add、merge、value和copy。其中,reset方法用于初始化累加器,add方法用于将输入数据累加到中间变量中,merge方法用于合并不同分区中的中间变量,value方法用于获取累加器的当前值,copy方法用于创建累加器的副本。
object Spark04_Acc {
def main(args: Array[String]): Unit = {
val conf: SparkConf = new SparkConf().setMaster("local[*]").setAppName("wordcount")
val sc: SparkContext = SparkContext.getOrCreate(conf)
val rdd: RDD[String] = sc.makeRDD(List("hello", "spark", "hello"))
// 累加器
// 创建累加器对象
val wcAcc = new MyAccumulator()
// 向Spark进行注册
sc.register(wcAcc,"wordCountAcc")
rdd.foreach(
word => {
// 数据的累加(使用累加器)
wcAcc.add(word)
}
)
// 获取累加器累加的结果
println(wcAcc.value)
sc.stop()
}
/**
* 自定义数据累加器:WordCount
* 1、继承AccumulatorV2,定义泛型
* IN: 累加器输入的数据类型 String
* OUT: 累加器返回的数据类型 mutable.Map[String,Long]
* 2、重写方法
*
*/
class MyAccumulator extends AccumulatorV2[String,mutable.Map[String,Long]]{
private var wcMap = mutable.Map[String,Long]()
// 判断是否为初始状态
override def isZero = {
wcMap.isEmpty
}
//
override def copy() = {
new MyAccumulator()
}
// 重置累加器
override def reset(): Unit = {
wcMap.clear()
}
// 获取累加器需要计算的值
override def add(word: String): Unit = {
val newCnt: Long = wcMap.getOrElse(word, 0L) + 1
wcMap.update(word,newCnt)
}
// Driver合并多个累加器
override def merge(other: AccumulatorV2[String, mutable.Map[String, Long]]): Unit = {
val map1 = this.wcMap
val map2 = other.value
map2.foreach{
case (word,count) => {
val newCount: Long = map1.getOrElse(word,0L) + count
map1.update(word,newCount)
}
}
}
// 累加器结果
override def value = wcMap
}
}
二、广播变量:分布式共享只读变量
2.1、需求
在合并两个Map的时候使用join会导致数据量的集合增长,并且会影响shuffle的性能,不推荐使用,所以使用下方代码进行优化
val conf: SparkConf = new SparkConf().setMaster("local[*]").setAppName("wordcount")
val sc: SparkContext = SparkContext.getOrCreate(conf)
val rdd1: RDD[(String, Int)] = sc.makeRDD(List(("a", 1), ("b", 2), ("c", 3),("d",5)))
val map = mutable.Map(("a", 4), ("b", 5), ("c", 6))
rdd1.map{
case (w,c) => {
val l: Any = map.getOrElse(w, None)
(w,(c,l))
}
}.collect().foreach(println)
sc.stop()
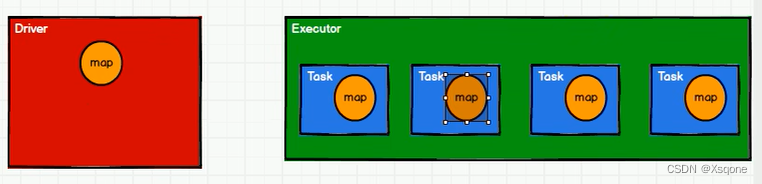
但是若是使用若是使用上方代码去使用的话,有多个任务去调用会发生下图情况:导致这个map在内存中存在冗余
- 闭包数据,都是以Task为单位发送的,每个任务中包含必报数据
- 这样会导致,一个Executor中含有大量重复的数据,并且占用大量的内存。
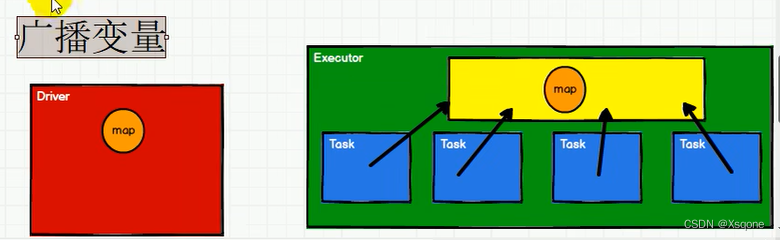
- Executor其实就是一个JVM,所以启动时,也会自动分配内存,就可以使用广播变量
- 将广播变量放到Executor的内存中,让每个Task都可以访问到。
2.2、广播变量实现原理
- 在Driver节点上创建一个对象,这个对象需要在Executor节点上使用。
- 将这个对象序列化成一个字节数组,并将这个字节数组发送给每个Executor节点。
- 每个Executor节点收到字节数组后,将其反序列化为一个对象,并将其存储在内存中,以便在任务知情期间使用。
- 在任务执行期间,Executor节点上的任务可以使用这个广播变量。
2.3、使用广播变量
val conf: SparkConf = new SparkConf().setMaster("local[*]").setAppName("wordcount")
val sc: SparkContext = SparkContext.getOrCreate(conf)
val rdd1: RDD[(String, Int)] = sc.makeRDD(List(("a", 1), ("b", 2), ("c", 3),("d",5)))
// val rdd2: RDD[(String, Int)] = sc.makeRDD(List(("a", 4), ("b", 5), ("c", 6)))
val map = mutable.Map(("a", 4), ("b", 5), ("c", 6))
// 封装广播变量
val bc: Broadcast[mutable.Map[String, Int]] = sc.broadcast(map)
println(bc)
rdd1.map{
case (w,c) => {
// 访问广播变量
val l: Any = bc.value.getOrElse(w, None)
(w,(c,l))
}
}.collect().foreach(println)
sc.stop()
















 1046
1046











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









