







背景
在数据开发工作中我们总是离不开梳理数据来源和去向,或者表之间的调用关系,为此需要构建数据血缘,但是kettle没有批量导出的功能。
万幸kettle的 .ktr 文件 都是 xml 文件。故可以通过解析 xml 的方式解析 .ktr 文件从而批量导出kettle任务中数据的来源和去向。
工具
VsCode
kettle 9.x 版本转换文件
Python
lxml
java
Druid
分析文件结构
.ktr文件使用 VsCode 打开后可以看到最上一级是一个 <transformation>标签,这代表它是转换文件。
然后是 <info>, <connection> 等标签,这是 .ktr 文件自己的信息,包括名字、参数、使用的共享数据源等
而我们要解析的是 <step> 标签, <step> 标签便是我们平常使用的 表输入, 表输出, 插入/更新等元件。
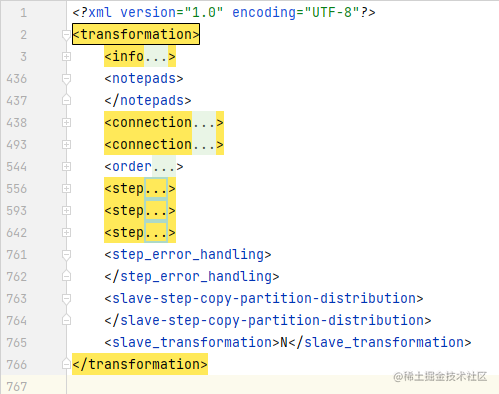
分析 <step> 标签结构
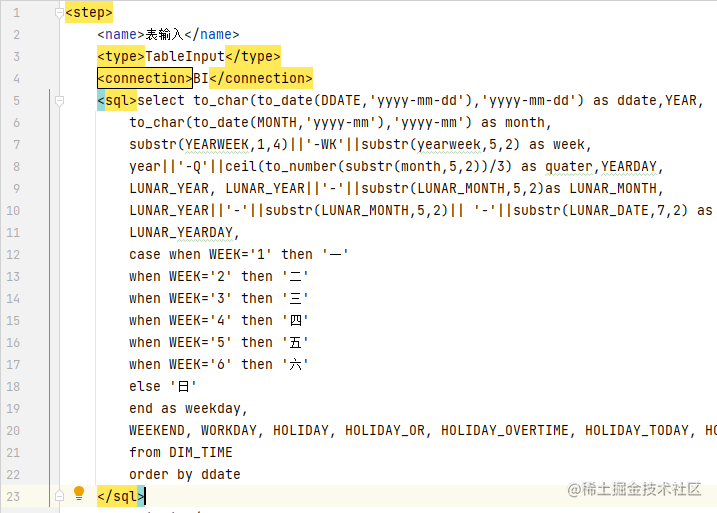
分析 <step> 的子标签
<type> 标签是 <step> 的类型,
<connection> 标签,我们可以用它的值判断连接的数据库,这个标签只要涉及到连接数据库一般都有
<schema> 标签 对应数据库的 schema
<table> 标签 对应数据库的 table
<sql> 标签 对应 表输入 中配置的SQL语句
<lookup> 标签 是在需要正式操作前通过字段判断的内容,可以通过它的子级 <schema> <table> 获取 插入/更新 的目标表
解析.ktr文件代码
from lxml import etree
import os
for root, dirs, files in os.walk("[kettle repo path]", topdown=False):
for name in files:
abs_name = os.path.join(os.path.abspath(root), name)
if not abs_name[-4:] == ".ktr":
continue
print("--ktr name", abs_name)
with open(abs_name, mode="rb") as fr:
xslt_content = fr.read()
ktr = etree.XML(xslt_content)
step = ktr.xpath("/transformation/step")
for i in step:
# element 转 string
string = etree.tostring(i, encoding='utf-8').decode('utf-8')
# print(string)
step_content = etree.XML(string)
type_el = step_content.xpath("/step/type")
connection_el = step_content.xpath("/step/connection")
type_collect = []
for t in type_el:
if t.text is None:
continue
type_collect.append(t.text)
# print(t.text)
type_string = "".join(type_collect)
print("--step type", type_string)
conn_collect = []
for conn in connection_el:
if conn.text is None:
continue
conn_collect.append(conn.text)
# print(conn.text)
conn_string = "".join(conn_collect)
print("--step connection", conn_string)
# 表输入
if "TableInput" == type_string:
sql_el = step_content.xpath("/step/sql")
query_collect = []
for s in sql_el:
if s.text is None:
continue
query_collect.append(s.text)
# print(s.text)
query_string = "".join(query_collect)
print("--step sql", query_string)
# 插入/更新
elif "InsertUpdate" == type_string:
lookup_schema = step_content.xpath("/step/lookup/schema")
lookup_table = step_content.xpath("/step/lookup/table")
schema_collect = []
for s in lookup_schema:
if s.text is None:
continue
schema_collect.append(s.text)
# print(s.text)
schema_string = "".join(schema_collect)
print("--step lookup schema", schema_string)
table_collect = []
for t in lookup_table:
if t.text is None:
continue
table_collect.append(t.text)
# print(t.text)
table_string = "".join(table_collect)
print("--step lookup table", table_string)
# 表输出
elif "TableOutput" == type_string:
output_schema = step_content.xpath("/step/schema")
output_table = step_content.xpath("/step/table")
schema_collect = []
for s in output_schema:
if s.text is None:
continue
schema_collect.append(s.text)
# print(s.text)
schema_string = "".join(schema_collect)
print("--step output schema", schema_string)
table_collect = []
for t in output_table:
if t.text is None:
continue
table_collect.append(t.text)
# print(t.text)
table_string = "".join(table_collect)
print("--step output table", table_string)
print("--step break-----------------------------------------")
print("--file break-----------------------------------------")
解析SQL获取Tabel 代码
解析 .ktr 获得SQL之后可以使用 Druid 解析SQL获取调用的Table
public class App {
public static void main(String[] args) {
String sql = "select * from table_string";
List<SQLStatement> sqlStatements = SQLUtils.parseStatements(sql, JdbcConstants.ORACLE);
List<String> table = new ArrayList<>();
for (SQLStatement stmt : sqlStatements) {
// 访问者模式 从语句对象中获取 table 名称
OracleSchemaStatVisitor visitor = new OracleSchemaStatVisitor();
stmt.accept(visitor);
List<String> result = visitor.getTables()
.keySet()
.stream()
.map(TableStat.Name::getName)
.distinct().toList();
table.addAll(result);
}
table.forEach(System.out::println);
}
}

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











