







这两天找了一本书讲的python实战,有实战项目,看到了scrapy框架部分的天气预报,决定把自己所学分享出来。
废话不多说,下面开始。
参考资料《Python网络爬虫实战 第2版》
资源链接:https://pan.baidu.com/s/1khiN7c87VTiaoybMOd3Bgg
提取码:chjf
建议使用pycharm
官网链接:http://www.jetbrains.com/pycharm/
目录
scrapy框架的安装
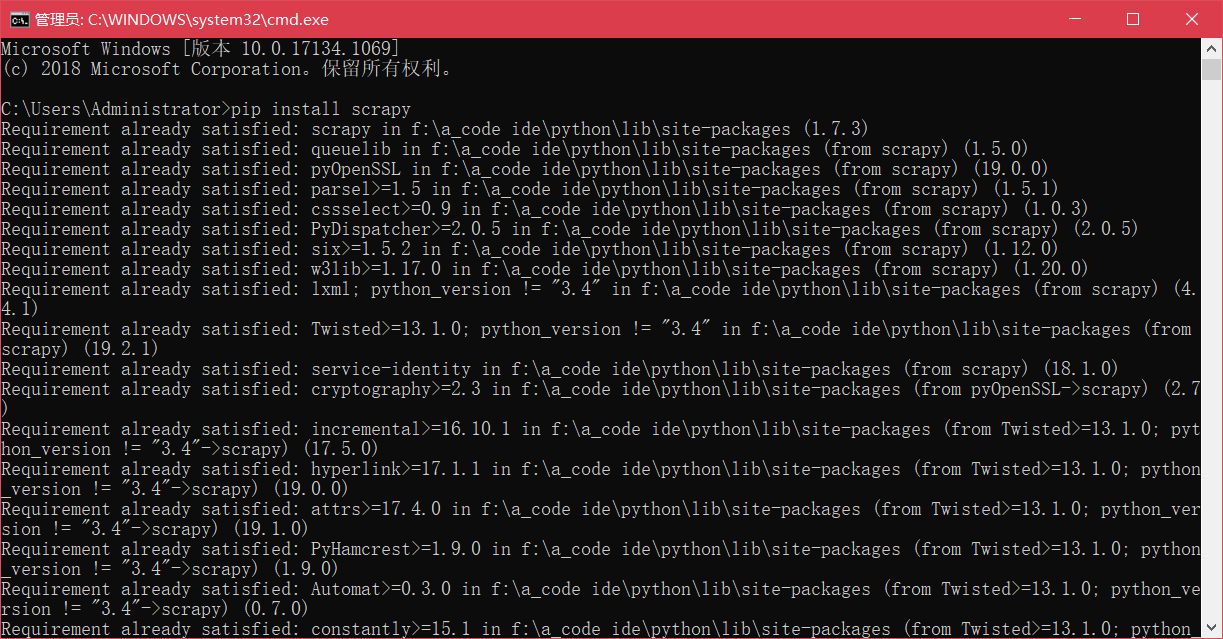
首先是准备工作,我用的Windows系统,所以就只讲Windows系统了,很简单win+R,键入“cmd”打开控制台,安装scrapy,前提是得有python啊,这个肯定都有的吧。cmd里输入下面命令
pip install scrapy
我已经安装过了,没安装的话应该是有好多个进度条的。
 第二种方法就是使用pycharm安装,操作如下
第二种方法就是使用pycharm安装,操作如下
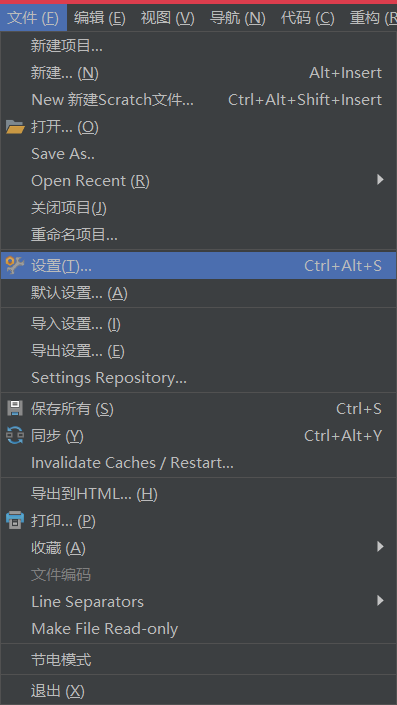
1.打开“文件(Flie)”中的“设置(Settings)”
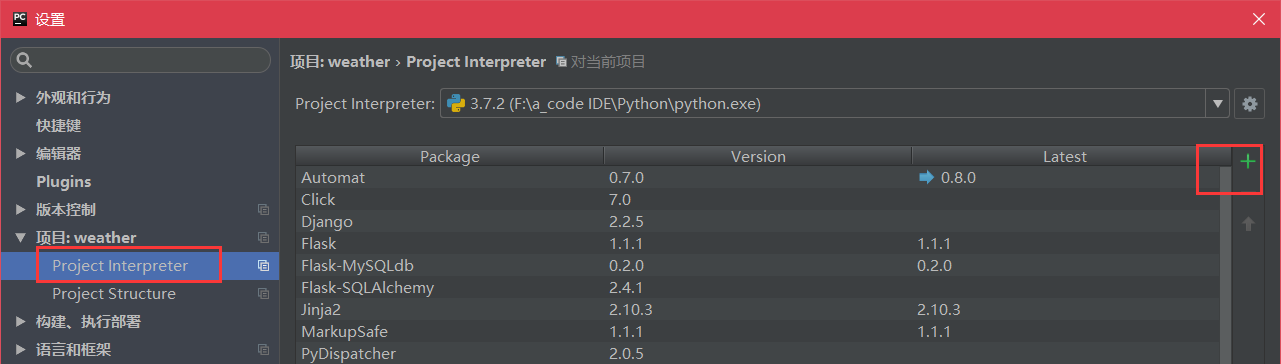
2.点“Project Interpreter”右上角的加号,添加第三方库
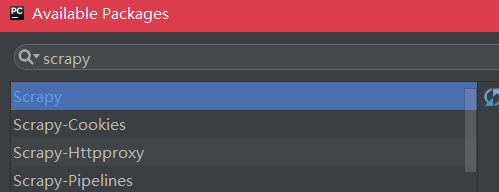 之后点击下面的install package等一会就安装好了。
之后点击下面的install package等一会就安装好了。
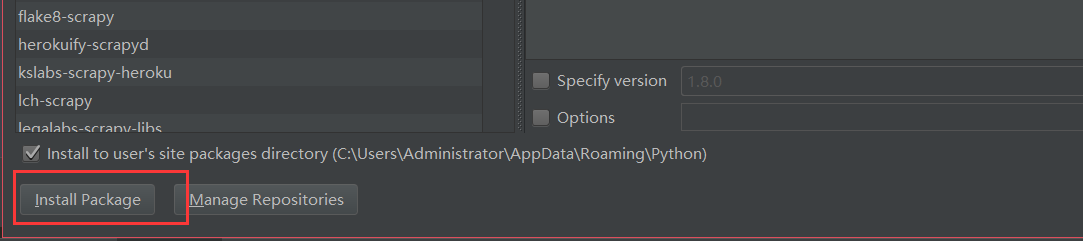
项目的创建
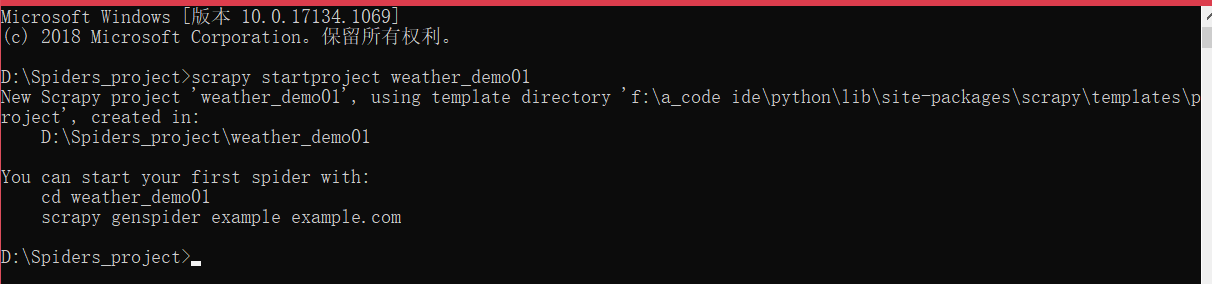
scrapy startproject weather_demo01
创建的项目如下图所示:
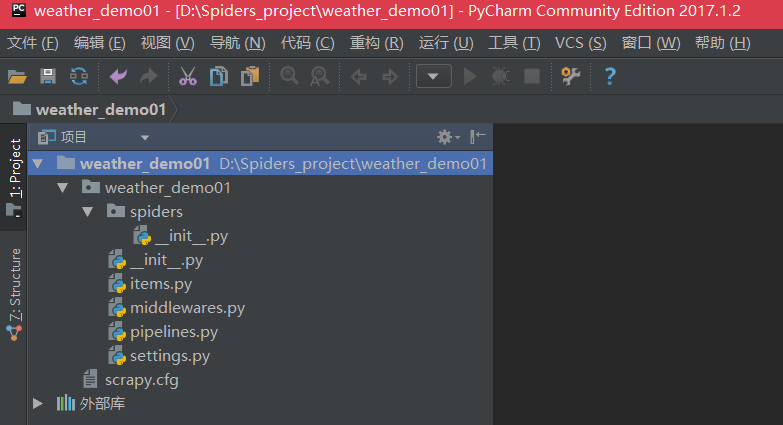
项目中各个文件介绍
书上差不多把所有的文件都介绍了,其实主要用的就几个,我就着重说主要用到的几个了:
settings.py
这个文件主要是说最后是由谁处理爬取的数据的,比如我们定义一个文件a功能是处理爬取的数据,但是运行发现数据没按照自己想要的格式保存下来,就是因为最后settings这个文件里没指明让a来处理。
部分代码如下
# -*- coding: utf-8 -*-
# Scrapy settings for weather_demo01 project
#
# For simplicity, this file contains only settings considered important or
# commonly used. You can find more settings consulting the documentation:
#
# https://docs.scrapy.org/en/latest/topics/settings.html
# https://docs.scrapy.org/en/latest/topics/downloader-middleware.html
# https://docs.scrapy.org/en/latest/topics/spider-middleware.html
BOT_NAME = 'weather_demo01'
SPIDER_MODULES = ['weather_demo01.spiders']
NEWSPIDER_MODULE = 'weather_demo01.spiders'
# Crawl responsibly by identifying yourself (and your website) on the user-agent
#USER_AGENT = 'weather_demo01 (+http://www.yourdomain.com)'
ITEM_PIPELINES = {
}
# Obey robots.txt rules
ROBOTSTXT_OBEY = True
这些值都是项目创立时自动写好的不需要改动。
然后就是ITEM_PIPELINES = {},这个变量是后面需要的,里面写的就是最后用来处理数据的文件,下面会讲
这里提一下ROBOTSTXT_OBEY这个变量的值,有true和false两个值,这个是是否遵守robots协议,robots协议是网站目录中包含一个robots.txt文件,这个文件记录着允许访问哪些目录,哪些不允许访问。下面用淘宝网的做个示范
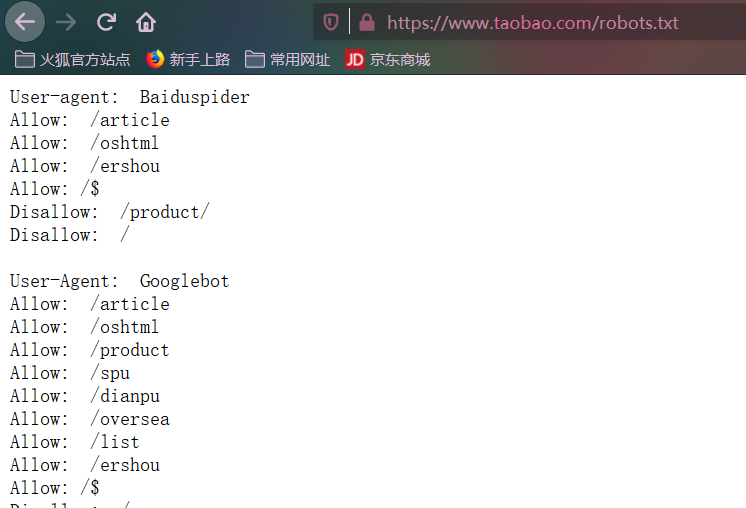
这个文件一般都是隐藏着的,不允许访问的目录肯定是有东西不想让你知道,隐藏就不会知道哪些不让访问,淘宝留着不知道为啥,不过我估计也没人能对淘宝网造成啥伤害。扯远了,上面这个变量的含义主要是说爬虫爬的时候是否遵守robots.txt协议,如果是true,则不会访问disallow列出的目录,如果是false则是无视这个文件了。
items.py
items.py文件的作用是定义爬虫最终需要哪些项(例如天气、风力、温度等等),内容如下:
# -*- coding: utf-8 -*-
# Define here the models for your scraped items
#
# See documentation in:
# https://docs.scrapy.org/en/latest/topics/items.html
import scrapy
class WeatherDemo01Item(scrapy 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 2596
2596











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









