







实验代码链接:
CSDN:
https://download.csdn.net/download/qq_38649386/12671873
GitHub:
待更新
出处:
《机器学习从入门到入职》:第十章,P345
深度学习卷积神经网络代码-框架keras数据集mnist
实验原理:
待更新
实验结果:
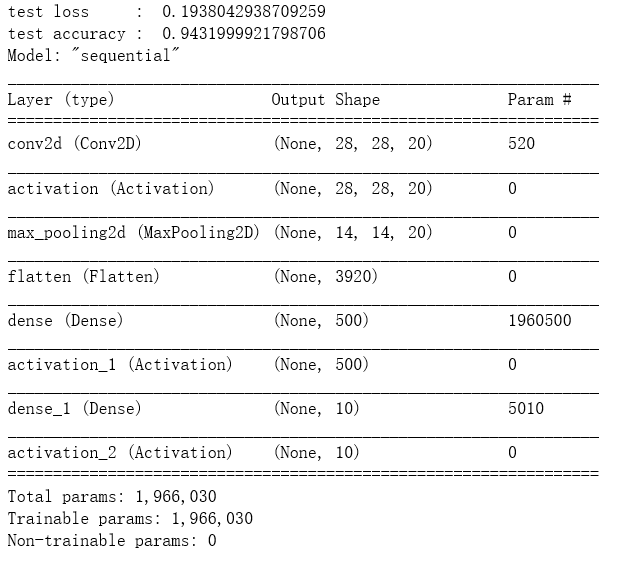

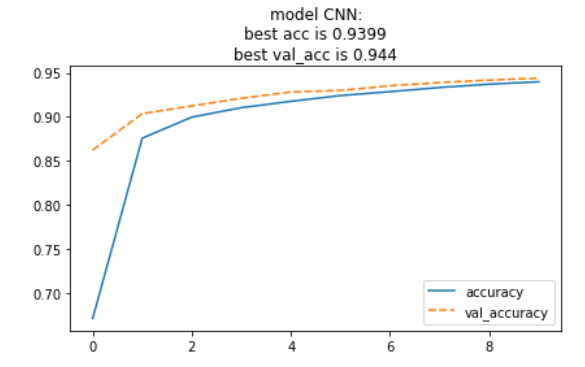
实验结论:
实验问题及解决:
1.model.fit(X_train, y_train, batch_size=BATCH_SIZE, epochs=NB_EPOCH,verbose=VERBOSE, validation_split=VALIDATION_SPLIT, callbacks=[CSV_log]) 函数参数说明
validation_split:
用于在没有提供验证集的时候,按一定比例从训练集中取出一部分作为验证集
verbose:
日志显示
#verbose = 0 为不在标准输出流输出日志信息
#verbose = 1 为输出进度条记录
#verbose = 2 为每个epoch输出一行记录
2.X_train = X_train[:,:,:,np.newaxis]
3.input_shape = (28,28,1)
4.model.add(Conv2D(20, kernel_size=5, padding="same", input_shape=input_shape))
5.model.add(MaxPooling2D(pool_size=(2,2), strides=(2,2), padding='valid'))
6.model.add(Flatten())
7.model.add(Dense(500))
8.哪个位置放激活函数/正则化
9.卷积层/池化层作用














 283
283











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









