










 本文讲述了作者在将Tesseract-OCR部署到Tomcat后遇到的内存异常问题,通过分析发现是由于OCR配置文件路径问题。博主分享了从本地测试到部署优化的解决方案,包括设置正确路径和推荐将tessdata文件放置在公共目录以避免版本管理和协同开发中的困扰。
本文讲述了作者在将Tesseract-OCR部署到Tomcat后遇到的内存异常问题,通过分析发现是由于OCR配置文件路径问题。博主分享了从本地测试到部署优化的解决方案,包括设置正确路径和推荐将tessdata文件放置在公共目录以避免版本管理和协同开发中的困扰。
由于项目中需要用到简单的图片识别技术,所以就选择了开源的Tesseract-OCR。可是本地在使用官网demo能正常运行,但是部署到tomcat后,就报java.lang.Error: Invalid memory access异常。
尝试百度后,并没有搜到相关记载。在苦思冥想后,总算被我想到一个解决方案。前面5步是调用官网demo的用例,如果你也遇到相同的tomcat部署后异常问题,请从第6步浏览;
1.下载源码包
- tess4j源码包:https://sourceforge.net/projects/tess4j/
- 中文库地址:https://github.com/tesseract-ocr/tessdata/blob/master/chi_sim.traineddata
- 其他语言包地址:https://github.com/tesseract-ocr/tessdata
- tess4j源码包(百度网盘地址):
链接:https://pan.baidu.com/s/1OZa45g0gZ95iYgPb_nUGvw?pwd=juiz
提取码:juiz
2.用idea打开源码包
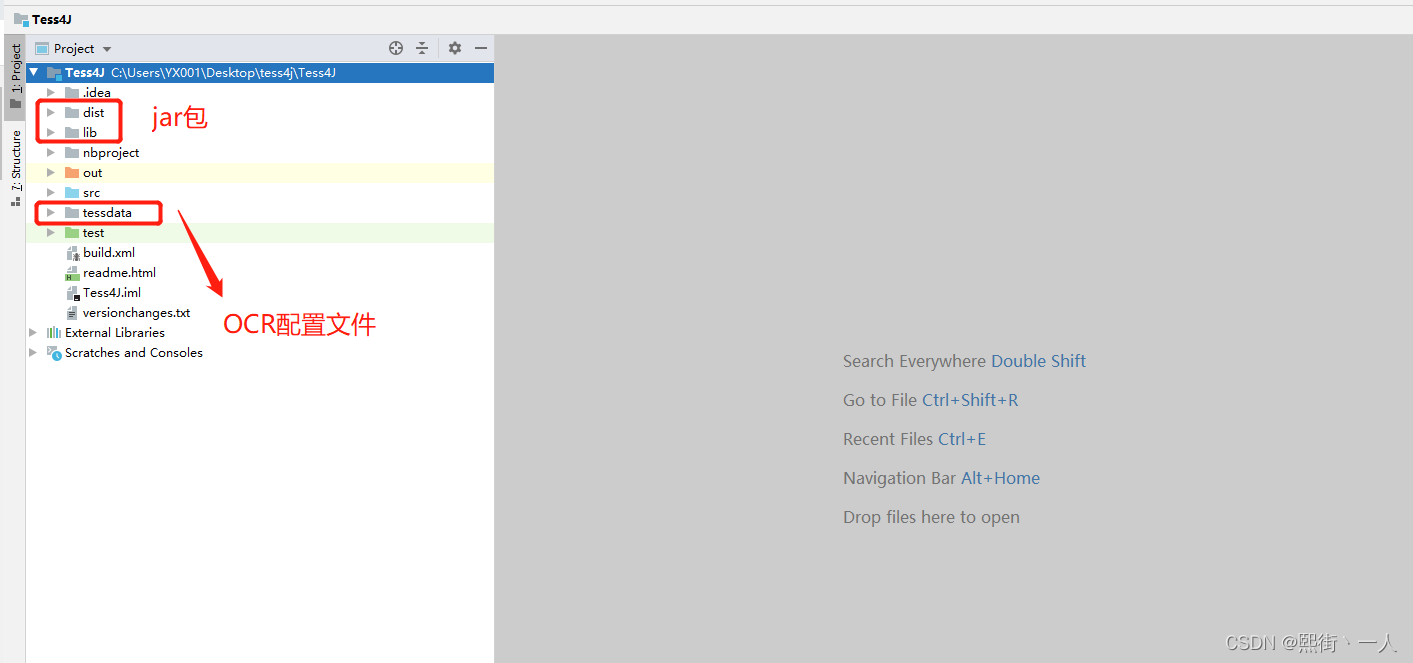
3.导入dist目录和lib目录的jar包
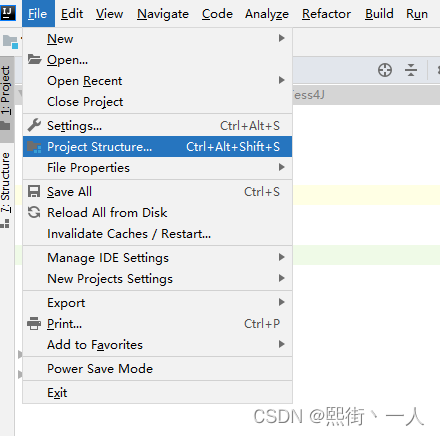
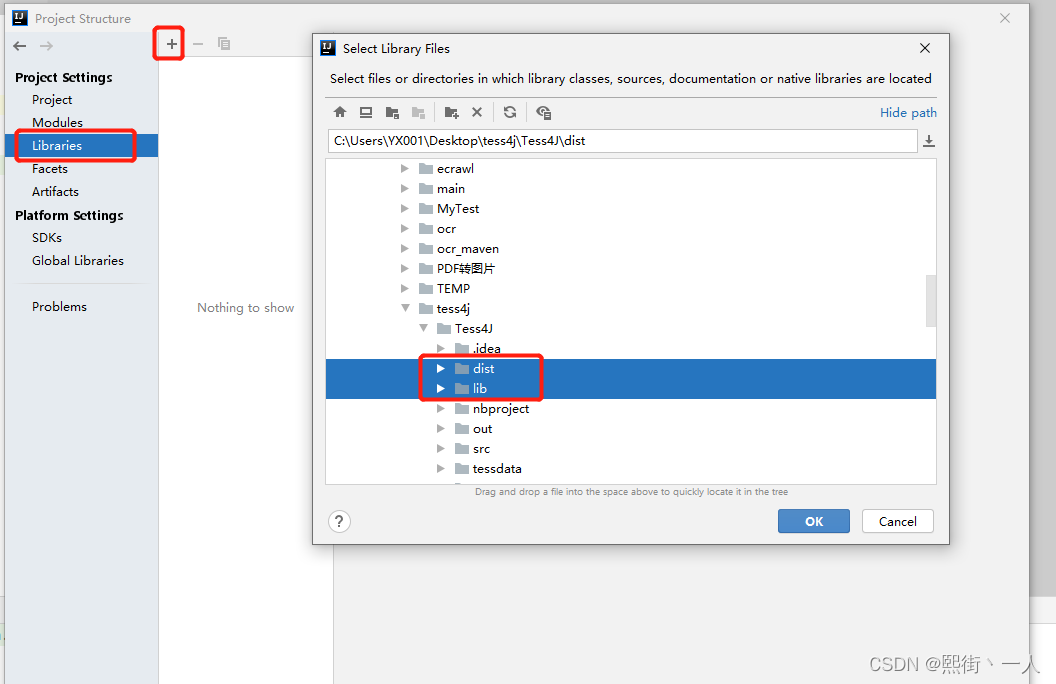
4.编写测试用例调用OCR
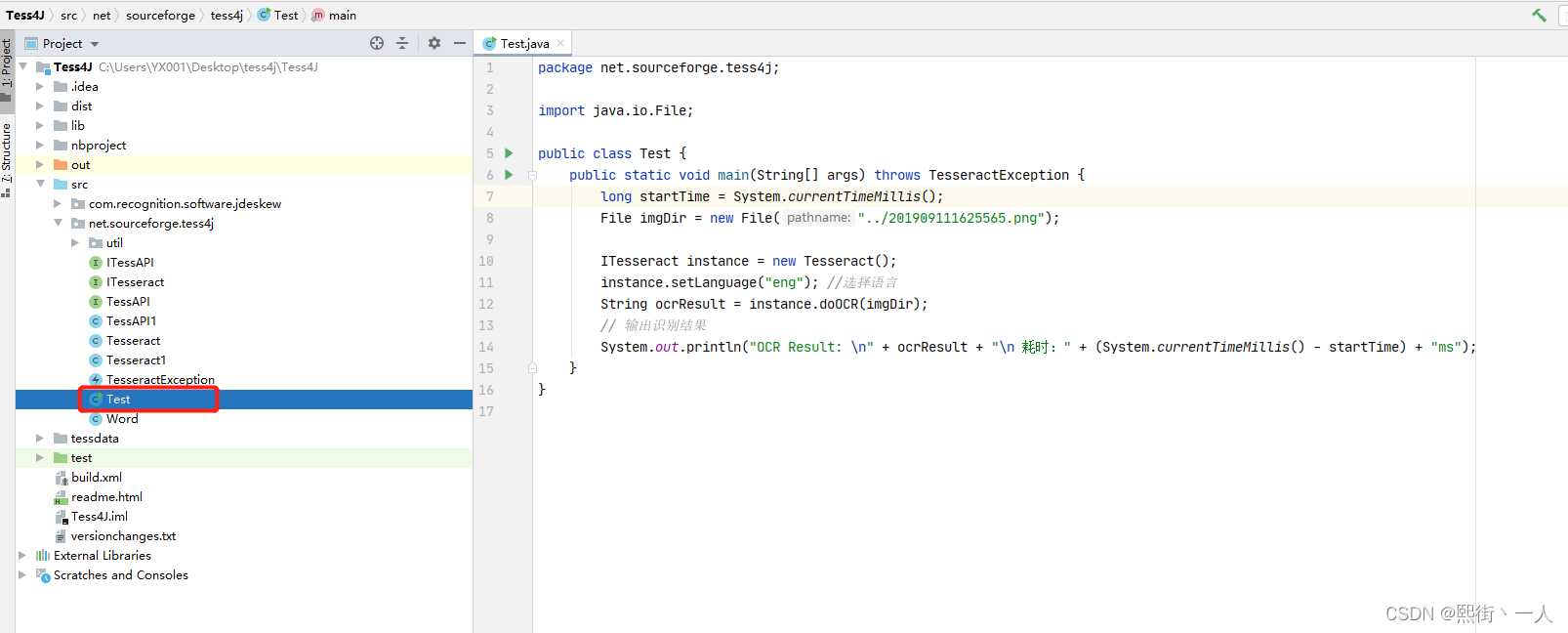
package net.sourceforge.tess4j;
import java.io.File;
public class Test {
public static void main(String[] args) throws TesseractException {
long startTime = System.currentTimeMillis();
File imgDir = new File("C:\Users\YX001\Desktop\tess4j\201909111625565.png");
ITesseract instance = new Tesseract();
instance.setLanguage("eng"); //选择语言
String ocrResult = instance.doOCR(imgDir);
// 输出识别结果
System.out.println("OCR Result: \n" + ocrResult + "\n 耗时:" + (System.currentTimeMillis() - startTime) + "ms");
}
}5.运行结果

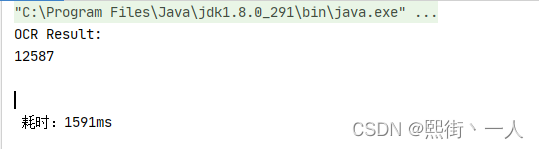
官网demo没问题后,我们开始将Tess4j引入到maven项目里
6.配置pom.xml文件
<dependency>
<groupId>net.sourceforge.tess4j</groupId>
<artifactId>tess4j</artifactId>
<version>3.4.8</version>
</dependency>注意:可能会造成jar包冲突,只需要把pom文件里的注释掉就好。我这里是造成slf4j冲突
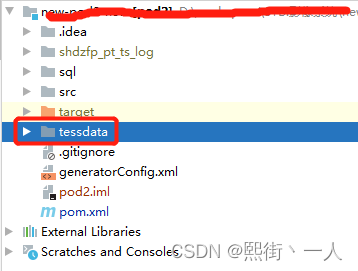
7.将步骤1中的OCR配置文件,存放到项目
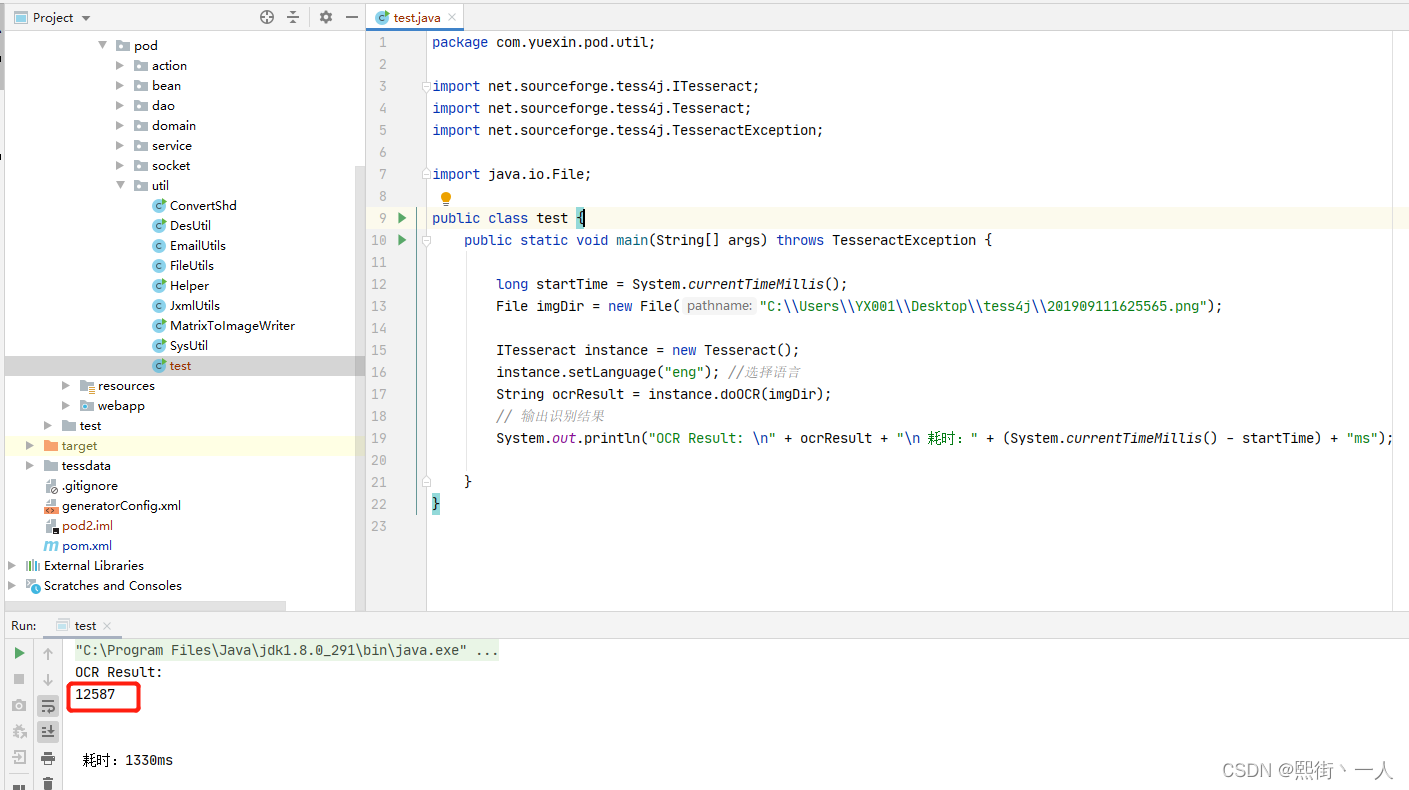
8.将步骤4的测试用例,复制到项目里并运行,结果正常
9.但是将项目部署到tomcat后,运行异常,报错如下:
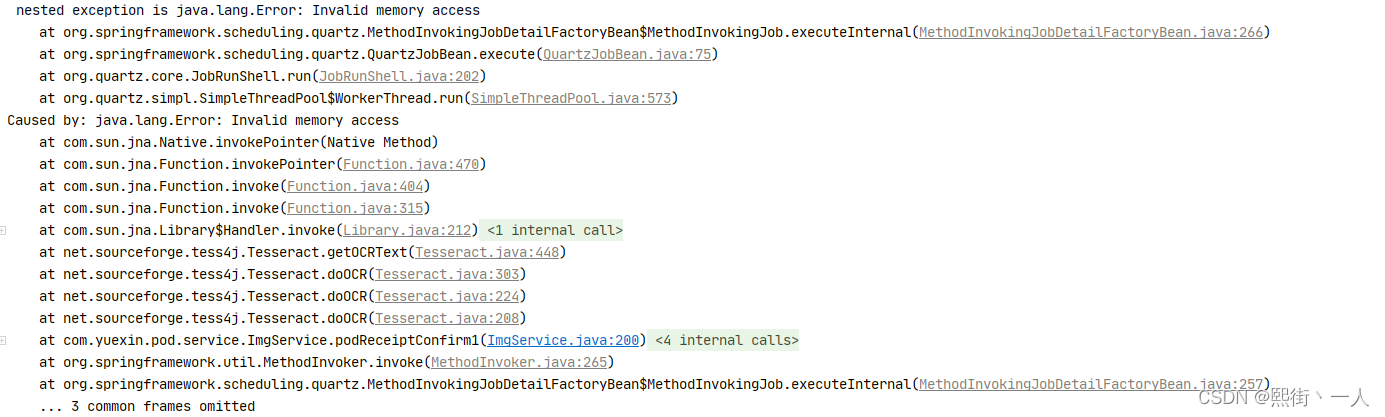
10.分析原因
后面不断的尝试,并查看官网。发现Tess4j读取OCR配置文件的路径是“./tessdata”(虽然我尝试修改过读取路径,但是失败了)。
所以测试用例执行的时候,相对路径“./tessdata”对应的是项目下的tessdata,而部署到tomcat上的相对路径“./tessdata”对应的应该是tomcat的bin目录下的tessdata。程序找不到tessdata配置文件,所以报错了。
于是我将tessdata复制一份到tomcat的bin目录下,并运行。
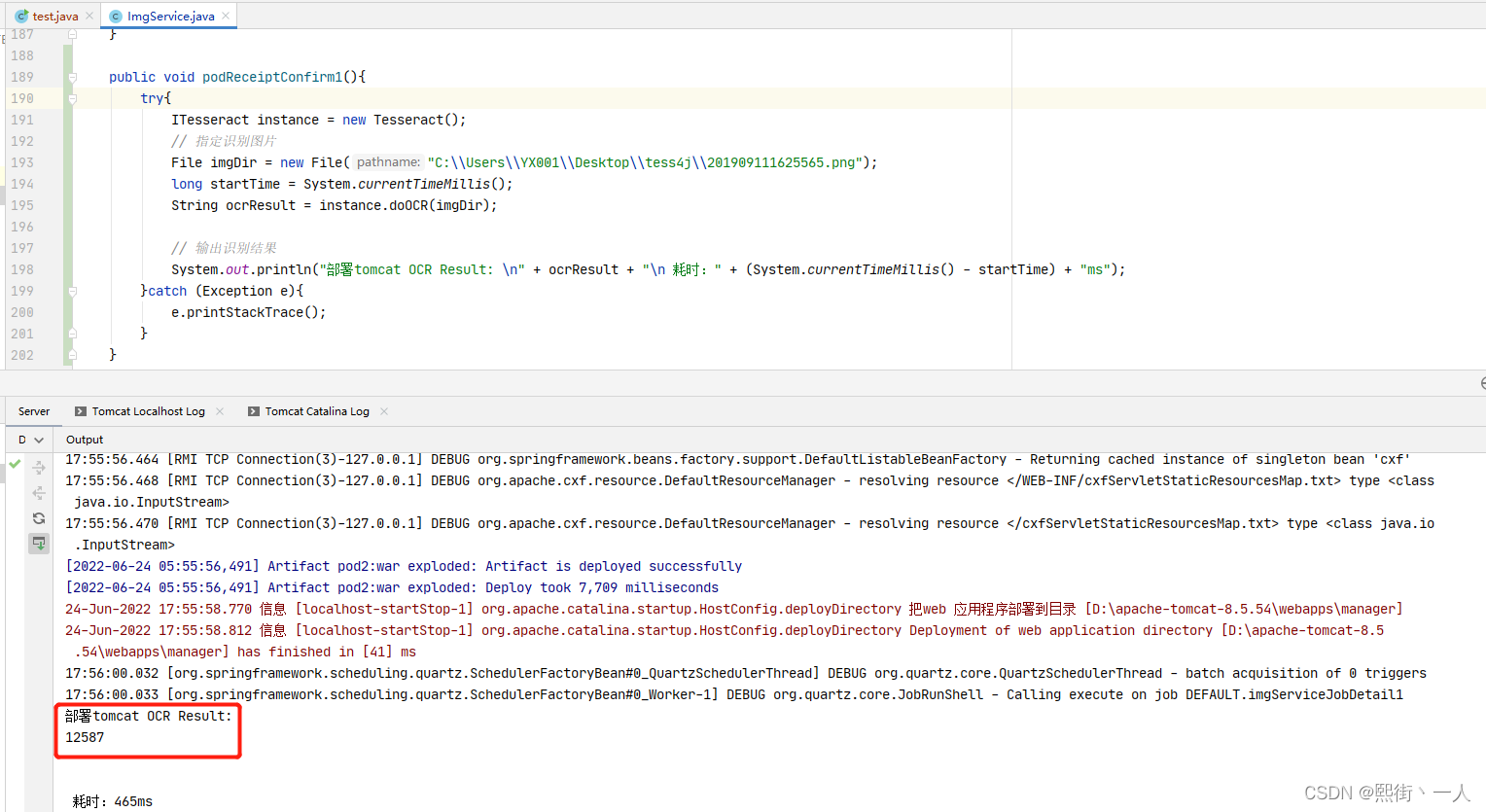
11.优化思路
由于将tessdata文件人工存入tomcat的bin目录上,是比较蠢的行为。
1.测试以及生产的tomcat都需要上传一份tessdata文件。如果经历tomcat版本更替,且并未有人知道要在bin目录里上传tessdata文件,则图片识别会报错。
2.本地多人协同开发,每个人都需要往本地tomcat的bin目录上传tessdata文件,显然也是比较麻烦的事情且容易遗忘的事情,而且提供的报错内容,如果不是跟着本博文思路走,很难解决调。
优化:所以我建议将tessdata文件存放在项目里经常使用的公共目录,比如:模板目录。当调用OCR识别时,先判断相对路径“./”下是否存在tessdata文件,不存在则将公共目录下的tessdata复制过去即可。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









