






包装类
- 概念:
(1)基本数据类型所对应的引用数据类型。
(2)Object可统一所有数据,包装类的默认值是null。
(3)包装类中实际上是持有了一个基本类型的属性,作为数据的存储空间(Byte中有一个byte属性),还提供了常用的转型方法,以及常量,既可以存储值,又具备了一系列的转型方法和常用常量,比直接使用基本类型的功能更强大。
(4)包装类型中提供了若干转型的方法,可以让自身类型与其他包装类型、基本类型、字符串相互之间进行转换。 - 转型方法:
(1)8种包装类型中,有6种是数字型(Byte、Short、Integer、Long、Float、Double),继承自java.long.Number父类。
(2)java.long.Number父类为所有子类分别提供了6个转型的方法,将自身类型转换成其他数字型。
byteValue()
shortValue()
integerValue()
longValue()
floatValue()
doubleValue()
(3)parseXXX(String s) 静态转型方法,7种包装类型都有,除了Character,都可以用String进行 包装类。转成基本数据类型
byte b = Byte.parseByte(“123”);
(4)valueOf(基本类型)、valueOf(字符串类型),静态方法,8种类型都有,转成包装类
Byte b1 = Byte.valueOf((byte)10);
Byte b1 = Byte.valueOf(“20”);
- 注意:
- 在使用字串符构建包装类型对象时,要保证类型的兼容,否则产生NumberFormatException。
- JDK5之后,提供自动装箱、拆箱,简化使用包装类型的编程过程。
Byte b4 = 40;//自动装箱,将基本类型直接赋值给包装类型。valueOf方 法
byte b5 = b4;//自动拆箱,将包装类型的值,直接赋给基本类型。byteValue方法 - 自动装箱时,会调用valueOf方法,Byte、Short、Integer、Long,四种整数包装类型都提供了对应的cache缓冲区,将常用的256个数字提前创建对象并保存在数据中,实现复用。即在区间的复用已有对象,在区间外创建新对象。
- 包装类对应
| 基本数据类型 | 包装类型 |
|---|---|
| byte | Byte |
| short | Short |
| int | Integer |
| long | Long |
| float | Float |
| double | Double |
| char | Character |
- 整数缓冲区
- Java预先创建了256个常用的整数包装类型对象。
- 在实际应用中,对已创建的对象进行复用。
String类
- 字符串是常量,创建之后不可改变。
字符串字面值存储在字符串池中,可以共享。
String s = “hello”;产生一个对象,字符串池中存储。
String s = new String(hello);产生两个对象,堆、字符串池各存储一个。 - 常用方法:
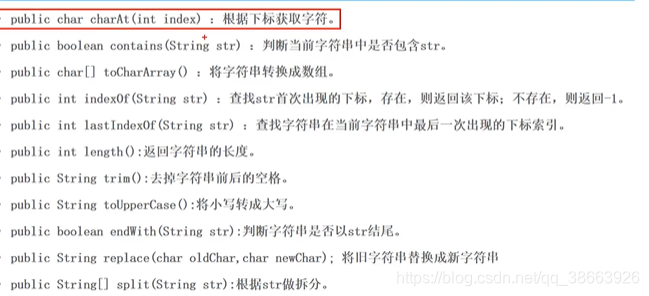
- 可变字符串:
StringBuffer:可变长字符串,JDK1.0提供,运行效率慢,线程安全。
StringBuilder:可变长字符串,JDK5.0提供,运行效率高线程安全。
BigDecimal
位置:java.math包中。
作用:精确计算浮点数。
创建方法:BigDecimal bd = new BigDecimal(“1.0”);
方法:- BigDecimal.add (BigDecimal bd) 加
- BigDecimal.subteact(BigDecimal bd) 减
- BigDecimal.multiply(BigDecimal bd) 乘
- BigDecimal.divide(BigDecimal bd) 除(除不尽的情况下,必须明确俩信息:1.保留几位。2.是否四舍五入。)
- 除法:BigDecimal(BigDecimal bd , int scal , RoundingMode mode)
- 参数scal:指定精确到小数点后几位。
- 参数mode:
指定小数部分的取舍模式,通常采用四舍五入的模式。
取值为BigDecimal.ROUND_HALF_UP。
集合
一、集合
- 概念:对象的容器,存储对象的对象,绝大程度上可代替数组。
- 特点:容器的工具类,定义了对多个对象进行操作的常用方法。
- 位置:java.util.*
二、Collection体系集合
4. Collection父接口:该体系结构的根接口,代表一组对象,称为“集合”,每个对象都是该集合的 “元素”。
(1)List接口的特点:有序、有下标、元素可重复。
(2)Set接口的特点:无序、无下标、元素不可重复。
5. 特点:代表任意一组任意类型的对象,无序、无下标。
6. 方法:
- boolean add(Object obj) //添加一个对象。
- boolean addAll(Collection c) //将一个集合中的所有对象添加到此对象中。
- void clear() //清空此集合中的所有对象。
- boolean contains(Object o) //检查此集合中是否包含o对象。
- boolean equals(Object o) //比较此集合是否与指定对象相等。
- boolean isEmpty() //判断此集合是否为空。
- boolean remove(Object o) //在此集合中移除o对象。
- int size() //返回此集合中的元素个数。
- Object[] toArray() //将此集合转换成数组。
三、List子接口
7. 特点:有序、有下标、元素可重复
8. 继承了父接口提供的共性方法,同时定义了一些独有的与下标相关类的操作方法。
9. 独有方法:
- void add(int index , Object o) //在index位置插入对象。
- boolean addAll(int index , Collection c) //将一个集合中的元素添加到此集合中的index位置。
- Object get(int index) //返回集合中的指定位置的元素。
- List subList(int fromIndex , int toIndex) //返回 fromIndex和toIndex之间的集合元素。
四、List实现类
10. JDK8的ArryLiat,实际初始长度是0。
11. 首次添加元素时,需要实际分配数组空间,执行数组扩容操作。
12. 真正向数组中插入数据,(Lazy懒)用的时候再创建,或再加载,有效的降低无用内存的占用。
五、ArrayList
- 数组结构实现,查询快、增上慢。
- JDK1.2版本,运行效率快、线程不安全。
六、Vector
- 数组结构实现,查询快、增上慢。
- JDK1.0版本,运行效率慢、线程安全。
七、LinkedList
- 链表(链接列表)结构存储,增删快,查询快。
- 栈结构Last In First Out()
八、泛型集合【重点-解决应用问题】
- 概念:参数化类型、类型安全的集合,强制集合元素的类型必须一致。
- 特点:
- 编译时即可检查,而非运行时抛出异常。
- 访问时,不必类型转换(拆箱)。
- 不同泛型之间引用不能相互赋值,泛型不存在多态。
九、泛型:高级类别的知识,熟练应用,需要时间、经验的积累。
- 泛型:约束-规范类型(E = Element / T = Type / K = Key / V = Value)
- 泛型场景
(1)定义泛型
a.实例泛型:
a)类:创建对象时,为类所定义的泛型,进行参数化赋值。
b)接口:实现接口时,为接口所定义的泛型,进行参数化赋值。
b.静态泛型:
a)定义在方法返回值类型前 例:,,<T extends Comparable> ,<T extends Comparable<? super T>>可应用在形参列表、返回值两种场景上,不单单可以规范泛型,还可以语义化返回值。
b)定义在方法的形参列表中:<?>,<? extends Object>,<? super Integer>,不支持&。只能应用于形参列表上,规范泛型。
十、Colletions工具类:
- 概念:集合工具类,定义了除了存取以外的集合常用方法。
- public static <T extends Comparable<? super T>> void sort(List list) //排序,要求:必须实现Comparable,必须可与自身类型比,以及父类类型比
- public static void reverse(List<?> list) //反转、倒置元素
- public static void shuffle(List<?> list) //随机重置顺序
经验:一级目标能看懂、能调用,二级目标能定义、能设计
十一、set子接口:
- 特点:无序,无下标,元素不可重复(当插入新元素时,如果新元素与已有元素进行equals比较, 结果为true时,则拒绝新元素的插入,只能有一个空值(null))。
- 方法:全部都继承自Collection的方法。
十二、for_each循环:
for (数据类型 变量名 : 容器名) {//可遍历集合或数组(常用在无序集合上)
}
十三、Set接口实现类:
- HashSet【重点】:
- 基于HashCode实现元素不重复(先判断哈希码,若一样,则equals比较)。
- 当存入元素的哈希码相同时,会调用equals进行确认,若结果为true则拒绝插入。
- LinkedHashSet【了解】:
- 底层使用LinkedHashMap(链表解构)存储,节点形式单独存储数据,并可以指向下一个节点,通过顺序访问节点,可保留元素插入顺序。
- TreeSet【了解】:
- 基于排列顺序实现元素不重复。
- 实现了SortedSet接口,对集合元素自动排序。
- 元素对象的类型必须实现Comparable接口,覆盖CompareTo方法。
- 通过CompareTo方法返回0判断是否为重复元素。
十四、Map体系集合:
- Map:地图、映射
- 特点:存储一对数据(Key-Value),无序、无下标,键不可重复,值可重复。
- 方法:
- V put(K key , V value) //将对象存入到集合中,关联键值,key重复则覆盖原值
- Object get(Object key) //根据键获取对应的值。
- Set //返回所有key。
- Collection values() //返回包含所有值的Collection集合。
- Set<Map , Entry<K , V>> //键值匹配的Set集合。
- 实现类:
- HashMap算法:拿到任何一个对象,通过hash(key)做运算,key>>>16(除以16),只可能得到0~15之间的一个数组,作为插入数组的下标。
- Hashtable:HashMap的线程安全版本。
- TreeMap:自动对key做排序,根据compareTo的返回值去重。
- Properties:Hashtable 子类,主要用于存储key和value都是字符串的情况,常在读取配置文件之后,保存文件中的键值对。反射、JDBC。
链接: 图示.














 832
832











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









