







在2011年Storm开源之前,由于Hadoop的火红,整个业界都在喋喋不休地谈论大数据。Hadoop的高吞吐,海量数据处理的能力使得人们可以方便地地处理海量数据。但是,Hadoop的缺点也和它的优点同样鲜明——延迟大,响应缓慢,运维复杂。
有需求也就有创造,在Hadoop基本奠定了大数据霸主地位的时候很多的开源项目都是以弥补Hadoop的实时性为目标而被创造出来。而在这个节骨眼上
Storm横空出世了。
Storm带着流式计算的标签华丽丽滴出场了,其实storm相对来说比hadoop复杂多了.如果你学会storm以后再去看hadoop那是非常简单的,看看它的一些卖点
-
- 分布式系统:可横向拓展,现在的项目不带个分布式特性都不好意思开源。
- 运维简单:Storm的部署的确简单。虽然没有Mongodb的解压即用那么简单,但是它也就是多安装两个依赖库而已。
- 高度容错:模块都是无状态的,随时宕机重启。
- 无数据丢失:Storm创新性提出的ack消息追踪框架和复杂的事务性处理,能够满足很多级别的数据处理需求。不过,越高的数据处理需求,性能下降越严重。
- 多语言:实际上,Storm的多语言更像是临时添加上去似的。因为,你的提交部分还是要使用Java实现.
但是他们没有谁强谁弱,应为侧重的方向不一样,hadoop侧重离线海量数据的分析,而storm需要实时计算分析,比如交通流量的调查,
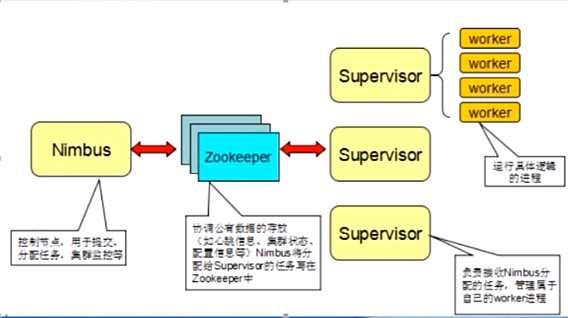
淘宝或者京东购买商品时候的实时推荐等等 都可以通过storm实现.Storm主要分为两种组件Nimbus和Supervisor。
这两种组件都是快速失败的,没有状态。任务状态和心跳信息等都保存在Zookeeper上的,提交的代码资源都在本地机器的硬盘上。
-
- Nimbus负责在集群里面发送代码,分配工作给机器,并且监控状态。全局只有一个。
- Supervisor会监听分配给它那台机器的工作,根据需要启动/关闭工作进程Worker。每一个要运行Storm的机器上都要部署一个,并且,按照机器的配置设定上面分配的槽位数。
- Zookeeper是Storm重点依赖的外部资源。
- Nimbus和Supervisor甚至实际运行的Worker都是把心跳保存在Zookeeper上的。
- Nimbus也是根据Zookeerper上的心跳和任务运行状况,进行调度和任务分配的。Storm提交运行的程序称为Topology。
- Topology处理的最小的消息单位是一个Tuple,也就是一个任意对象的数组。Topology由Spout和Bolt构成。
- Spout是发出Tuple的结点。Bolt可以随意订阅某个Spout或者Bolt发出的Tuple。Spout和Bolt都统称为component。
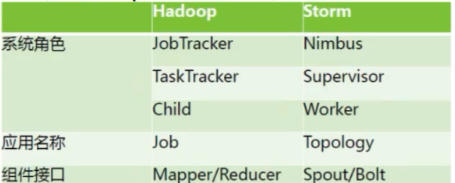
我们来看张经典的Topology的流程图就明白了
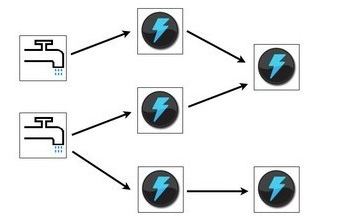
在看张storm的架构图
可能看到这或许你大概知道怎么工作的了,
下面看下我们的hell world
首先引入依赖
<dependency>
<groupId>org.apache.storm</groupId>
<artifactId>storm-core</artifactId>
<version>1.1.0</version>
</dependency>看下我们的Topology
public static void main(String[] args) throws InterruptedException {
//初始化top构造器
TopologyBuilder top=new TopologyBuilder();
//设置spout
top.setSpout("spout",new TestSpout());
//设置bolt
top.setBolt("print-bolt",new TestBoot()).shuffleGrouping("spout");
top.setBolt("write-bolt", new WriteBolt()).shuffleGrouping("print-bolt");
//本地模式
LocalCluster cluster=new LocalCluster();
//提交top图
cluster.submitTopology("tag",new Config(),top.createTopology());
Thread.sleep(10000);
cluster.killTopology("tap");
cluster.shutdown();
}
public class TestSpout extends BaseRichSpout {
private static final long serialVersionUID = 1L;
private SpoutOutputCollector collector;
private static final Map<Integer, String> map = new HashMap<Integer, String>();
static {
map.put(0, "java");
map.put(1, "php");
map.put(2, "groovy");
map.put(3, "python");
map.put(4, "ruby");
}
@Override
public void open(Map conf, TopologyContext context, SpoutOutputCollector collector) {
//对spout进行初始化
this.collector = collector;
System.out.println("++++++++++++++++++++++++++++++");
//System.out.println(this.collector);
}
/**
* <B>方法名称:</B>轮询tuple<BR>
* <B>概要说明:</B><BR>
* @see
*/
@Override
public void nextTuple() {
//随机发送一个单词
final Random r = new Random();
int num = r.nextInt(5);
System.out.println("----------------------------");
try {
Thread.sleep(500);
} catch (InterruptedException e) {
e.printStackTrace();
}
this.collector.emit(new Values(map.get(num)));
}
/**
* <B>方法名称:</B>declarer声明发送数据的field<BR>
* <B>概要说明:</B><BR>
* @see
*/
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
System.out.println("=============================");
//进行声明
declarer.declare(new Fields("print"));
}
}public class TestBoot extends BaseRichBolt {
OutputCollector _collector;
@Override
public void prepare(Map map, TopologyContext topologyContext, OutputCollector outputCollector) {
_collector=outputCollector;
}
@Override
public void execute(Tuple tuple) {
String spout = tuple.getStringByField("print");
System.out.println("1111111111111"+spout);
//发射字段
_collector.emit(new Values(spout));
}
@Override
public void declareOutputFields(OutputFieldsDeclarer outputFieldsDeclarer) {
//这是下游接收者
outputFieldsDeclarer.declare(new Fields("write"));
}
}writeBolt
public class WriteBolt extends BaseRichBolt {
private static final long serialVersionUID = 1L;
private static final Log log = LogFactory.getLog(WriteBolt.class);
private FileWriter writer ;
@Override
public void execute(Tuple input) {
//获取上一个组件所声明的Field
String text = input.getStringByField("write");
System.out.println(text);
try {
if(writer == null){
if(System.getProperty("os.name").equals("Windows 10")){
writer = new FileWriter("D:\\099_test\\" + this);
} else if(System.getProperty("os.name").equals("Windows 8.1")){
writer = new FileWriter("D:\\099_test\\" + this);
} else if(System.getProperty("os.name").equals("Windows 7")){
writer = new FileWriter("D:\\099_test\\" + this);
} else if(System.getProperty("os.name").equals("Linux")){
System.out.println("----:" + System.getProperty("os.name"));
writer = new FileWriter("/usr/local/temp/" + this);
}
}
log.info("【write】: 写入文件");
writer.write(text);
writer.write("\n");
writer.flush();
} catch (Exception e) {
e.printStackTrace();
}
}
@Override
public void declareOutputFields(OutputFieldsDeclarer outputFieldsDeclarer) {
}
@Override
public void prepare(Map map, TopologyContext topologyContext, OutputCollector outputCollector) {
}
}
我们的Topology图的流程是这样的由TestSpout 流向 TestBoot 然后在流向 WriteBolt ,TestBoot负责在控制台打印,WriteBolt 负责往磁盘写入 ,下面使我们的运行结果
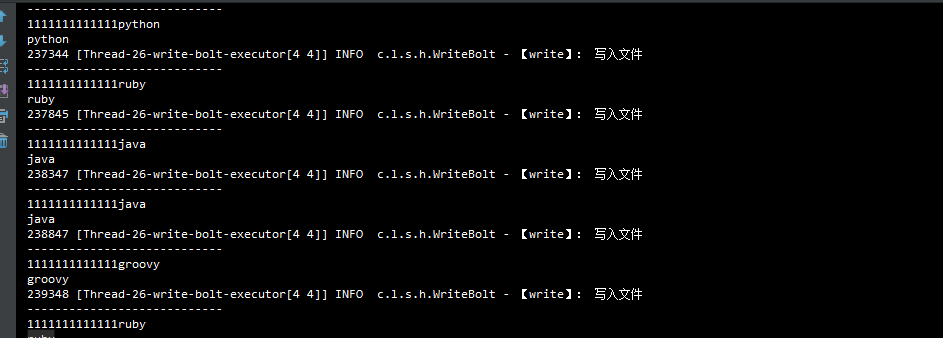
通过Spout随机给TestBoot发送单词,然后经过WriteBolt进行写入到磁盘.并且启动的是本地模式.如果想在服务器上的storm环境中运行Topology 需要改成集群模式
try {
//开启集群模式
StormSubmitter.submitTopology("top1", new Config(), top.createTopology());
} catch (AlreadyAliveException e) {
e.printStackTrace();
} catch (InvalidTopologyException e) {
e.printStackTrace();
} catch (AuthorizationException e) {
e.printStackTrace();
}本文章重点是要让大家对Storm有个初步的认识,希望能帮到大家















 1201
1201











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









